pykaldi
v0.2.2
Pykaldi는 Kaldi Specive 인식 툴킷을위한 Python 스크립팅 레이어입니다. Kaldi 및 OpenFST 라이브러리의 C ++ 코드를위한 사용하기 쉬운 저온 머리, 일류 파이썬 포장지를 제공합니다. Pykaldi를 사용하여 저수준 Kaldi 기능을 호출하거나 코드에서 Kaldi 및 OpenFST 객체 조작 및 새로운 Kaldi 도구 구현과 같은 C ++ 코드를 작성 해야하는 것에 대한 Python 코드를 작성할 수 있습니다.
Kaldi를 맞춤형 음성 인식 솔루션을 구축하기 위해 혼합하고 일치시킬 수있는 큰 레고 상자로 생각할 수 있습니다. Pykaldi를 생각하는 가장 좋은 방법은 Kaldi에게 보충제, 조수입니다. 실제로, Pykaldi는 Kaldi와 함께 사용될 때 최고입니다. 이를 위해, Kaldi가 제공하는 무수한 명령 줄 도구, 유틸리티 스크립트 및 쉘 레벨 레시피의 기능을 복제하는 것은 Pykaldi 프로젝트의 비 목표입니다.
Kaldi와 마찬가지로 Pykaldi는 주로 음성 인식 연구원 및 전문가를위한 것입니다. Kaldi 및 OpenFST 라이브러리가 제공하는 광대 한 유틸리티, 알고리즘 및 데이터 구조를 활용하여 Python 소프트웨어를 구축 해야하는 제품은 케이크로 가득 차 있습니다.
FST 기반 음성 인식에 익숙하지 않거나 Python에서 Kaldi 및 OpenFST의 내장에 대한 접근에 관심이 없지만 Python 응용 프로그램의 일부로 미리 훈련 된 Kaldi 시스템을 실행하려는 경우 프렛을하지 마십시오. Pykaldi에는 대부분의 Python 프로그래머가 액세스 할 수있는 asr , alignment 및 segmentation 와 같은 다수의 고급 응용 프로그램 지향 모듈이 포함되어 있습니다.
연구에 Pykaldi를 사용하거나 고급 ASR 응용 프로그램을 구축하는 데 관심이 있다면 운이 좋을 것입니다. Pykaldi는 Python에서 Kaldi 및 OpenFST 객체를 읽고, 쓰기, 검사, 조작 또는 시각화하는 데 필요한 모든 것을 제공합니다. 여기에는 Kaldi의 공개 API 및 OpenFST C ++ 라이브러리의 일부인 대부분의 기능 및 메소드에 대한 Python 래퍼가 포함됩니다. Kaldi Tools에서 제작/소비 한 파일을 읽고 쓰려면 util 패키지에서 I/O 및 테이블 유틸리티를 확인하십시오. Kaldi 행렬 및 벡터로 작업하려면 예를 들어 Numpy Ndarrays로 변환하고 그 반대로 matrix 패키지를 확인하십시오. 기능 추출 및 변환에 Kaldi를 사용하려면 feat , ivector 및 transform 패키지를 확인하십시오. Kaldi Tools에서 생산/소비 한 격자 또는 기타 FST 구조로 작업하려면 fstext , lat 및 kws 패키지를 확인하십시오. Kaldi의 가우스 혼합 모델, 숨겨진 Markov 모델 또는 음성 결정 트리에 대한 저수준 액세스를 원한다면 gmm , sgmm2 , hmm 및 tree 패키지를 확인하십시오. Kaldi Neural Network 모델에 대한 저수준 액세스를 원한다면 nnet3 , cudamatrix 및 chain 패키지를 확인하십시오. Kaldi에서 디코더 및 언어 모델링 유틸리티를 사용하려면 decoder , lm , rnnlm , tfrnnlm 및 online2 패키지를 확인하십시오.
Kaldi와 Pykaldi에 대해 더 많이 배우고 싶은 관심있는 독자는 다음과 같은 자료가 유용 할 수 있습니다.
파이썬의 자동 음성 인식 (ASR)은 의심 할 여지없이 Pykaldi의 "킬러 앱"이므로 Pykaldi API에 대한 느낌을 얻기 위해 몇 가지 ASR 시나리오를 살펴볼 것입니다. Pykaldi는 ASR 모델을 교육하기위한 고급 유틸리티를 제공하지 않으므로 Kaldi 레시피를 사용하여 모델을 훈련 시키거나 온라인으로 제공되는 미리 훈련 된 모델을 사용해야합니다. 이것이 그 이유는 단순히 Kaldi C ++ 라이브러리에 높은 수준의 ASR 교육 API가 없기 때문입니다. Kaldi ASR 모델은 데이터 준비부터 교육에 사용되는 무수한 Kaldi 실행 파일의 오케스트레이션에 이르기까지 모든 것을 처리하는 복잡한 쉘 레벨 레시피를 사용하여 교육을받습니다. 이것은 디자인에 의한 것이며 앞으로 변화 할 가능성은 거의 없습니다. Pykaldi는 Kaldi C ++ 라이브러리의 저수준 ASR 교육 유틸리티에 래퍼를 제공하지만 기본 빌딩 블록에서 Python에서 ASR 교육 파이프 라인을 구축하려고하지 않는 한 실제로는 유용하지 않습니다. 레고 비유를 계속 하면서이 작업은 필요한 레고로 가득 찬 트럭에 대한 접근성을 구축하는 것과 유사합니다. 그래도 시도하기에 충분히 미쳤다면,이 단락이 당신을 방해하지 않도록하십시오. 우리가 Pykaldi를 만들기 전에, 우리는 그것이 미친 사람의 임무라고 생각했습니다.
Pykaldi asr 모듈에는 사용하기 쉬운 고급 클래스가 포함되어있어 Python에서 ASR 시스템을 구성하기가 간단하게 사용됩니다. Pykaldi로 ASR을 수행하는 데 필요한 보일러 플레이트 코드를 무시하면 다음과 같은 코드 스 니펫만큼 간단 할 수 있습니다.
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) 이 단순화 된 예에서, 먼저 모델 final.mdl , 디코딩 그래프 HCLG.fst 및 Symbol Table words.txt 의 경로와 함께 가상의 인식 SomeRecognizer 인식하는 사람을 인스턴스화합니다. opts 객체에는 인식기의 구성 옵션이 포함되어 있습니다. 그런 다음 Kaldi Archive feats.ark 에 저장된 기능 행렬을 읽기 위해 Pykaldi 테이블 리더 SequentialMatrixReader 인스턴스화합니다. 마지막으로, 우리는 기능 행렬을 반복하여 하나씩 해독합니다. 여기서 우리는 단순히 발화에 대한 최상의 ASR 가설을 인쇄하고 있으므로 출력 out 의 "text" 항목에만 관심이 있습니다. 출력 사전에는 최고의 가설의 프레임 레벨 정렬 및 가설을 나타내는 가중 격자와 같은 다른 유용한 항목이 포함되어 있습니다. 물론, 모든 ASR 파이프 라인 이이 예만큼 간단한 것은 아니지만 종종 동일한 전체 구조를 갖습니다. 다음 섹션에서는보다 복잡한 ASR 파이프 라인을 구현하기 위해 위의 코드를 조정하는 방법을 살펴 봅니다.
이것이 가장 일반적인 시나리오입니다. 우리는 Aspire 체인 모델과 같은 미리 훈련 된 Kaldi 모델을 사용하여 오프라인 ASR을 수행하려고합니다. 여기서 우리는 "모델"이라는 용어를 느슨하게 사용하여 ASR 시스템을 구성하는 데 필요한 모든 것을 참조합니다. 이 구체적인 예에서는 다음과 같습니다.
이 예제 코드를 사용하여 Aspire 체인 모델로 해독 할 수 있습니다.
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] 이 예제와 마지막 섹션의 짧은 스 니펫의 근본적인 차이점은 각 발화에 대해 디스크에서 원시 오디오 데이터를 읽고 디스크에서 단일 미리 컴퓨팅 된 피처 매트릭스를 읽는 대신 두 개의 피처 행렬을 계산한다는 것입니다. 스크립트 파일 wav.scp 에는 디코딩하려는 발언에 해당하는 WAV 파일 목록이 포함되어 있습니다. 우리가 추출하는 추가 기능 매트릭스에는 신경망 음향 모델에서 채널 및 스피커 적응을 수행하는 온라인 i 벡터가 포함되어 있습니다. 스피커-터너 런스 맵 spk2utt 온라인 I- 벡터 추출에서 각 스피커의 별도 통계를 축적하는 데 사용됩니다. 스피커 정보를 사용할 수없는 경우 간단한 ID 매핑이 될 수 있습니다. 우리는 MFCC 기능과 I- 벡터를 튜플에 포장 하고이 튜플을 디코딩을 위해 인식 자에게 전달합니다. Pykaldi의 신경망 인식자는 추가 I- 벡터 기능을 사용할 수있을 때 처리하는 방법을 알고 있습니다. 모델 파일 final.mdl 에는 전환 모델과 신경망 음향 모델이 모두 포함되어 있습니다. NnetLatticeFasterRecognizer 프로세스는 신경망 음향 모델을 사용하여 첫 번째 전화 로그-크게 컴퓨팅을 계산 한 다음 전이 모델을 사용하여 로그-크게 전환으로 맵핑하고 최종적으로 전이 로그-리클 류를 디코딩 그래프 HCLG.fst 로 디코딩하는 Word ID를 사용하여 Word Lakeli를 사용하여 Word ID를 사용하여 전이를 디코딩하는 행렬을 특징으로합니다. 디코딩 후, 우리는 인식 자에 의해 생성 된 격자를 향후 처리를 위해 Kaldi 아카이브에 저장합니다.
이 예제는 또한 Kaldi가 제공하는 강력한 I/O 메커니즘을 보여줍니다. 코드에서 기능 추출 파이프 라인을 구현하는 대신 Kaldi가 Pykaldi 테이블 리더를 인스턴스화하고 반복하여 Kaldi가 지정자를 읽고 단순히 기능 행렬을 계산합니다. 기능 추출 파이프 라인이 운영 체제와 병렬로 실행되기 때문에 Pykaldi와 함께 가장 간단 할뿐만 아니라 Pykaldi를 사용하는 가장 빠른 방법이기도합니다. 마찬가지로, 우리는 Kaldi Writ 이것들이 작동하려면 compute-mfcc-feats , ivector-extract-online2 및 gzip 우리의 PATH 에 있어야합니다.
이것은 이전 시나리오와 유사하지만 Kaldi 음향 모델 대신 Pytorch 음향 모델을 사용합니다. 이전과 같은 기능을 계산 한 후, 우리는이를 Pytorch 텐서로 변환하고 Pytorch Neural Network 모듈을 사용하여 전방 패스를 수행하고 전화 로그-일성을 출력 한 후 최종적으로 해수를 해독하기 위해 Pykaldi 매트릭스로 변환합니다. 인식기는 전환 모델을 사용하여 전형적인 Kaldi 디코딩 그래프의 입력 레이블 인 전환 ID에 전화 ID를 자동으로 매핑합니다.
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]이 섹션은 자리 표시 자입니다. 그 동안이 스크립트를 확인하십시오.
Lattice Rescoring은 ASR에서 대형 N- 그램 언어 모델 또는 RNNLM (RNNLM)을 사용하는 표준 기술입니다. 이 예에서는 Kaldi Rnnlm을 사용하여 격자를 구제합니다. 우리는 먼저 모델의 경로를 제공하여 구조기를 인스턴스화합니다. 그런 다음 테이블 리더를 사용하여 우리가 구조하려는 격자를 반복하고 마지막으로 테이블 라이터를 사용하여 구조 된 격자를 디스크로 다시 작성합니다.
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) 우리가 단어 기능에서 단어 임베딩을 계산하는 데 사용한 확장 된 파일 이름과 즉시 기능 임베드를 계산하는 데 주목하십시오. 또한 격자 아카이브를 투명하게 압축 해제/압축하는 데 사용한 읽기/쓰기 개별 자도 주목할 만합니다. 이것들이 작동하기 위해서는 rnnlm-get-word-embedding , gunzip 및 gzip 우리의 PATH 에있게되기 위해서는 필요합니다.
Pykaldi는 Kaldi와 Python이 제공하는 모든 좋은 것들 사이의 격차를 해소하는 것을 목표로합니다. Kaldi 라이브러리에 바인딩 모음 이상입니다. 파이썬에서 필수 Kaldi 및 OpenFST 유형에 대한 일등석 지원을 제공하는 스크립팅 레이어입니다. Pykaldi 벡터 및 매트릭스 유형은 Numpy와 밀접하게 통합됩니다. 기본 메모리 버퍼를 복사하지 않고도 Numpy Array로 완벽하게 변환 할 수 있으며 그 반대도 마찬가지입니다. Kaldi Style Lattices를 포함한 Pykaldi FST 유형은 Python의 일등석 시민입니다. FST 유형 및 작업에 직면 한 사용자의 API는 거의 전적으로 OpenFST의 공식 Python Wapper 인 PywRapfst에 의해 노출 된 API를 모방하는 Python에서 거의 전적으로 정의됩니다.
Pykaldi는 간단한 API 설명을 사용하여 Kaldi 및 OpenFST C ++ 라이브러리를 포장하기 위해 CLIF의 힘을 활용합니다. CLIF에 의해 생성 된 CPYTHON 확장 모듈은 Kaldi 및 OpenFST와 상호 작용하기 위해 Python으로 가져올 수 있습니다. CLIF는 Python에서 기존 C ++ API를 노출시키는 데 적합하지만 포장지는 항상 Python에서 사용하기 쉬운 "Pythonic"API를 노출시키는 것은 아닙니다. Pykaldi는 Python (및 때로는 C ++)으로 Raw Clif 래퍼를 확장하여 더 "Pythonic"API를 제공하여이를 해결합니다. 아래 그림은 Kaldi 생태계에서 Pykaldi가 적합한 위치를 보여줍니다.
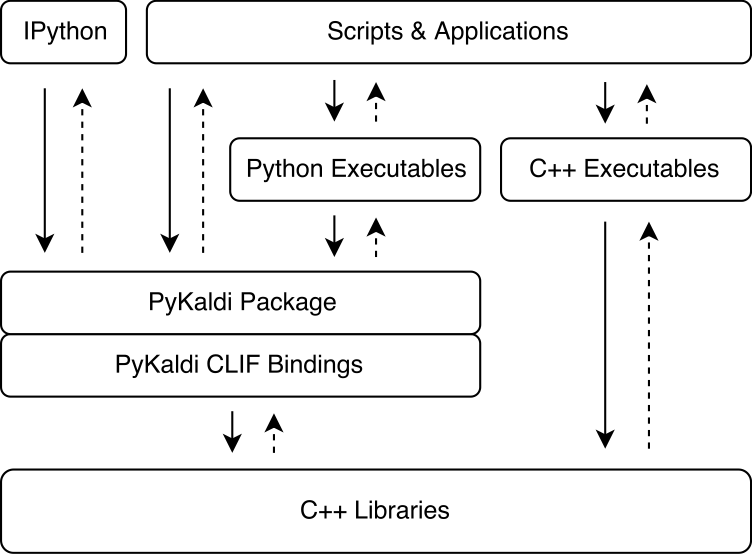
Pykaldi는 모듈 식 설계를 통해 유지 관리를 쉽게하고 확장 할 수 있습니다. 소스 파일은 Kaldi 소스 트리의 복제본 인 디렉토리 트리에서 구성됩니다. 각 디렉토리는 서브 포장을 정의하고 관련 Kaldi 라이브러리에 작성된 래퍼 코드 만 포함됩니다. 래퍼 코드는 다음으로 구성됩니다.
CLIF C ++ API 설명을 래핑 할 유형 및 함수를 정의하고 Python API,
Clif가 기대하는 Google C ++ 스타일을 준수하지 않는 Kaldi 코드 용 Shims를 정의하는 C ++ 헤더
Python 모듈은 CLIF와 함께 생성 된 관련 확장 모듈을 그룹화하고 RAW CLIF 래퍼를 확장하여보다 "Pythonic"API를 제공합니다.
우리 논문에서 Pykaldi의 디자인 및 기술적 인 세부 사항에 대한 자세한 내용을 읽을 수 있습니다.
다음 표는 각 Pykaldi 패키지의 상태를 보여줍니다 (현재 NNET, NNET2 및 Online에 대한 지원을 추가 할 계획이 없음).
| 패키지 | 포장? | Pythonic? | 선적 서류 비치? | 테스트? |
|---|---|---|---|---|
| 베이스 | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| 체인 | ✔ | ✔ | ✔ ✔ ✔ | |
| Cudamatrix | ✔ | ✔ | ✔ | |
| 디코더 | ✔ | ✔ | ✔ ✔ ✔ | |
| 위업 | ✔ | ✔ | ✔ ✔ ✔ | |
| fstext | ✔ | ✔ | ✔ ✔ ✔ | |
| GMM | ✔ | ✔ | ✔ ✔ | ✔ |
| 흠 | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| ivector | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔ ✔ ✔ | |
| LAT | ✔ | ✔ | ✔ ✔ ✔ | |
| LM | ✔ | ✔ | ✔ ✔ ✔ | |
| 행렬 | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| NNET3 | ✔ | ✔ | ✔ | |
| 온라인 2 | ✔ | ✔ | ✔ ✔ ✔ | |
| rnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| sgmm2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| 변환 | ✔ | ✔ | ✔ | |
| 나무 | ✔ | ✔ | ||
| 유도 | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
Ubuntu> = 16.04, Centos> = 7 또는 MacOS> = 10.13과 같은 비교적 최근의 Linux 또는 MacOS를 사용하는 경우 너무 많은 문제없이 Pykaldi를 설치할 수 있어야합니다. 그렇지 않으면 설치 스크립트를 조정해야 할 것입니다.
이제 GitHub 릴리스 페이지에서 공식 WHL 패키지를 다운로드 할 수 있습니다. Linux에서는 Python 3.7, 3.8, ..., 3.11에 대한 WHL 패키지가 있으며 Mac M1/M2의 일부 (실험) 빌드가 있습니다.
WHL 패키지를 사용하기로 결정한 경우 다음 섹션을 건너 뛰고 프로젝트를 설정하기 위해 "Pykaldi WHL 패키지로 새 프로젝트 시작"으로 바로 이동할 수 있습니다. Kaldi의 Pykaldi 호환 버전을 컴파일해야합니다.
소스에서 Pykaldi를 설치하고 구축하려면 아래에 주어진 단계를 따르십시오.
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldi필요하지는 않지만 새로운 분리 된 파이썬 환경에 Pykaldi 및 모든 파이썬 의존성을 설치하는 것이 좋습니다. 새로운 파이썬 환경을 만들고 싶지 않다면이 단계의 나머지 부분을 건너 뛸 수 있습니다.
새로운 파이썬 환경을 만드는 데 원하는 도구를 사용할 수 있습니다. 여기서는 virtualenv 사용하지만 원하는 경우 conda 와 같은 다른 도구를 사용할 수 있습니다. 나머지 설치를 계속하기 전에 새로운 파이썬 환경을 활성화해야합니다.
virtualenv env
source env/bin/activate아래 명령을 실행하면 소스에서 Pykaldi를 구축하는 데 필요한 시스템 패키지를 설치합니다.
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "아래 명령을 실행하면 소스에서 Pykaldi를 구축하는 데 필요한 Python 패키지가 설치됩니다.
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommended위에 나열된 패키지 외에도 다음 소프트웨어의 Pykaldi 호환 설치가 필요합니다.
Google Protobuf, 권장 v3.5.0. C ++ 라이브러리와 파이썬 패키지를 모두 설치해야합니다.
Clif의 Pykaldi 호환 포크. Pykaldi 개발을 간소화하기 위해 Clif Codebase를 변경했습니다. 우리는 시간이 지남에 따라 이러한 변화를 업스트림하기를 바라고 있습니다. 이러한 변경 사항은 Pykaldi 지점에 있습니다.
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi tools 디렉토리의 스크립트를 사용하여 이러한 소프트웨어를 로컬로 설치하거나 업데이트 할 수 있습니다. 이 스크립트의 출력을 확인하십시오. Done installing {protobuf,CLIF,Kaldi} 경우에는 설치가 실패했음을 의미합니다.
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..Apple Silicion에서 Kaldi를 컴파일하고 ./install_kaldi.sh가 SCTK를 시작할 때 바로 붙어있는 경우, 도구/kaldi/tools/makefile에서 -march = aviation을 제거해야 할 수도 있습니다.
SCTK_CXFLAGS = -w # -march=native Kaldi가 tools 디렉토리 내부에 설치되고 모든 Python 종속성 (Numpy, Pyparsing, Pyclif, Protobuf)이 활성 Python 환경에 설치되면 다음 명령으로 Pykaldi를 설치할 수 있습니다.
python setup.py install설치되면 다음 명령으로 Pykaldi 테스트를 실행할 수 있습니다.
python setup.py test그런 다음 WHL 패키지를 만들 수도 있습니다. WHL 패키지를 사용하면 Pykaldi를 스피치 프로젝트를위한 새로운 프로젝트 환경에 쉽게 설치할 수 있습니다.
python setup.py bdist_wheel그런 다음 WHL 파일은 "Dist"폴더에서 찾을 수 있습니다. WHL 파일 이름은 Pykaldi 버전, 파이썬 버전 및 아키텍처에 따라 다릅니다. 파이썬 3.9의 경우 Pykaldi 0.2.2로 x86_64에 빌드하면 다음과 같습니다. Dist/Pykaldi-0.2.2-CP39-CP39-linux_x86_64.whl
예를 들어 새 프로젝트 폴더를 만듭니다.
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRWHL 패키지와 동일한 Python 버전 (예 : Python 2.9)으로 가상 환경을 생성하고 활성화하십시오.
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateNumpy 및 Pykaldi를 MyASR 환경에 설치하십시오.
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl pykaldi/tools/install_kaldi.sh를 MyASR 프로젝트에 복사하십시오. install_kaldi.sh 스크립트를 사용하여 프로젝트에 Pykaldi 호환 Kaldi 버전을 설치하십시오.
./install_kaldi.shPykaldi/Tools/Path.sh를 프로젝트에 복사하십시오. Path.sh는 Pykaldi가 Kaldi 폴더에서 Kaldi 라이브러리와 바이너리를 찾는 데 사용됩니다. Source Path.sh with :
. path.sh축하합니다. 프로젝트에서 Pykaldi를 사용할 준비가되었습니다!
참고 : 새 쉘을 열 때마다 프로젝트 환경과 PATH.SH : Sh :
. myasr_env/bin/activate
. path.sh참고 : 불행히도, Pykaldi Conda 패키지는 구식입니다. 당신이 그것을 유지하려면, 우리와 연락하십시오.
CUDA 지원으로 Pykaldi를 설치하려면 :
conda install -c pykaldi pykaldiCUDA 지원없이 Pykaldi를 설치하려면 (CPU 만 해당) :
conda install -c pykaldi pykaldi-cpuPykaldi Conda 패키지는 Kaldi 실행 파일을 제공하지 않습니다. Pykaldi와 함께 Kaldi 실행 파일을 사용하려면 Read/Write Specifire의 일부로 Kaldi를 별도로 설치해야합니다.
참고 : 아래의 도커 지침은 구식 일 수 있습니다. Pykaldi의 Docker 이미지를 유지하려면 저희와 연락하십시오.
Docker 컨테이너 내부에서 Pykaldi를 사용하려면 docker 폴더의 지침을 따르십시오.
기본적으로 Pykaldi 설치 명령은 사용 가능한 모든 (논리) 프로세서를 사용하여 빌드 프로세스를 가속화합니다. 프로세서 수와 비교하여 시스템 메모리의 크기가 비교적 작은 경우 병렬 컴파일/연결 작업이 시스템 메모리를 소진하여 스왑을 초래할 수 있습니다. Pykaldi를 건설하는 데 사용되는 병렬 작업의 수를 다음과 같이 제한 할 수 있습니다.
MAKE_NUM_JOBS=2 python setup.py installWindows에 Pykaldi를 만드는 데 필요한 것이 무엇인지 전혀 모릅니다. 아마도 빌드 시스템을 많이 변경해야 할 것입니다.
현재 Pykaldi는 업스트림 Kaldi 저장소와 호환되지 않습니다. Kaldi Fork에 대항하여 구축해야합니다.
시스템에 이미 호환 된 Kaldi 설치가있는 경우 pykaldi/tools 디렉토리에 새 제품을 설치할 필요가 없습니다. 대신 Pykaldi 설치 명령을 실행하기 전에 다음 환경 변수를 간단히 설정할 수 있습니다.
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >현재 Pykaldi는 업스트림 CLIF 저장소와 호환되지 않습니다. Clif Fork를 사용하여 구축해야합니다.
시스템에 이미 호환 가능한 CLIF 설치가있는 경우 pykaldi/tools 디렉토리에 새 제품을 설치할 필요가 없습니다. 대신 Pykaldi 설치 명령을 실행하기 전에 다음 환경 변수를 간단히 설정할 수 있습니다.
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > Protobuf와 Clif를 업데이트 할 필요성은 자주 나타나지 않아야하지만 Pykaldi 구축에 사용되는 Kaldi 설치를 업데이트하거나 업데이트해야 할 수도 있습니다. tools 디렉토리에서 관련 설치 스크립트를 다시 시작하면 기존 설치를 업데이트해야합니다. 이것이 작동하지 않으면 문제를여십시오.
Pykaldi tfrnnlm 패키지는 kaldi-tensorflow-rnnlm 라이브러리가 Kaldi 라이브러리에서 찾을 수있는 경우 나머지 Pykaldi와 함께 자동으로 구축됩니다. Kaldi를 구축 한 후 KALDI_DIR/src/tfrnnlm/ directory로 이동하여 Makefile에 주어진 지침을 따르십시오. kaldi-tensorflow-rnnlm 라이브러리의 기호 링크가 KALDI_DIR/src/lib/ Directory에 추가되어 있는지 확인하십시오.
SHENNONG- 음성 기능을위한 도구 상자, MFCC, PLP 등과 같은 추출.
Kaldi Model Server- 라이브 디코딩을위한 스레드 Kaldi 모델 서버. NNET3 호환 모델로 마이크에서 음성을 직접 디코딩 할 수 있습니다. 영어와 독일어의 예제를 사용할 수 있습니다. Pykaldi Online2 디코더를 사용합니다.
MeetingBot- 프라우저에 ASR 출력을 표시하기 위해 Pykaldi/Kaldi-Model-Server 백엔드를 사용하는 전사 및 요약을위한 웹 응용 프로그램의 예.
Subtitle2go- 모든 미디어 파일의 자동 자막 생성. 배치 디코더와 함께 ASR 용 Pykaldi를 사용합니다.
여기에서 보여주고 싶은 Pykaldi를 사용하는 멋진 오픈 소스 프로젝트가 있으면 알려주십시오!
연구에 Pykaldi를 사용하는 경우 다음과 같이 우리의 논문을 인용하십시오.
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
우리는 모든 기여에 감사드립니다! 버그를 찾으면 문제 나 풀 요청을 자유롭게 열어주십시오. 새로운 기능을 요청하거나 추가하려면 토론을위한 문제를 열어주십시오.


