pykaldi
v0.2.2
Pykaldi เป็นเลเยอร์การเขียนสคริปต์ Python สำหรับชุดเครื่องมือการรู้จำเสียงพูด Kaldi มันให้ wrappers python ชั้นหนึ่งที่ใช้งานง่ายและมีค่าต่ำสำหรับรหัส C ++ ในไลบรารี Kaldi และ OpenFST คุณสามารถใช้ Pykaldi เพื่อเขียนรหัส Python สำหรับสิ่งต่าง ๆ ที่อาจต้องเขียนโค้ด C ++ เช่นการเรียกฟังก์ชั่น kaldi ระดับต่ำการจัดการ Kaldi และ OpenFST วัตถุในรหัสหรือใช้เครื่องมือ Kaldi ใหม่
คุณสามารถนึกถึง Kaldi เป็นกล่องเลโก้ขนาดใหญ่ที่คุณสามารถผสมและจับคู่เพื่อสร้างโซลูชันการจดจำคำพูดที่กำหนดเอง วิธีที่ดีที่สุดในการนึกถึง Pykaldi คืออาหารเสริมเพื่อนสนิทถ้าคุณจะไป Kaldi ในความเป็นจริง Pykaldi นั้นดีที่สุดเมื่อใช้ร่วมกับ Kaldi ด้วยเหตุนี้การทำซ้ำฟังก์ชันการทำงานของเครื่องมือบรรทัดคำสั่งมากมายสคริปต์ยูทิลิตี้และสูตรระดับเชลล์ที่จัดทำโดย Kaldi เป็นเป้าหมายที่ไม่ใช่เป้าหมายสำหรับโครงการ Pykaldi
เช่นเดียวกับ Kaldi Pykaldi มีวัตถุประสงค์หลักสำหรับนักวิจัยและผู้เชี่ยวชาญด้านการรู้จำการพูด มันเต็มไปด้วยสารพัดที่จะต้องสร้างซอฟต์แวร์ Python โดยใช้ประโยชน์จากการรวบรวมยูทิลิตี้อัลกอริทึมและโครงสร้างข้อมูลที่จัดทำโดย Kaldi และ OpenFST ไลบรารี
หากคุณไม่คุ้นเคยกับการจดจำคำพูดที่ใช้ FST หรือไม่สนใจที่จะเข้าถึงความกล้าของ Kaldi และ OpenFST ใน Python แต่ต้องการใช้ระบบ Kaldi ที่ผ่านการฝึกอบรมมาก่อนซึ่งเป็นส่วนหนึ่งของแอปพลิเคชัน Python ของคุณ Pykaldi รวมโมดูลที่มุ่งเน้นแอปพลิเคชันระดับสูงจำนวนมากเช่น asr alignment และ segmentation ที่ควรเข้าถึงได้โดยโปรแกรมเมอร์ Python ส่วนใหญ่
หากคุณสนใจที่จะใช้ Pykaldi สำหรับการวิจัยหรือสร้างแอปพลิเคชัน ASR ขั้นสูงคุณก็โชคดี Pykaldi มาพร้อมกับทุกสิ่งที่คุณต้องการอ่านเขียนตรวจสอบจัดการหรือมองเห็นวัตถุ Kaldi และ OpenFst ใน Python มันมี wrappers Python สำหรับฟังก์ชั่นและวิธีการส่วนใหญ่ที่เป็นส่วนหนึ่งของ API สาธารณะของ Kaldi และ OpenFst C ++ หากคุณต้องการอ่าน/เขียนไฟล์ที่ผลิต/บริโภคโดยเครื่องมือ Kaldi ลองดู I/O และยูทิลิตี้ตารางในแพ็คเกจ util หากคุณต้องการทำงานร่วมกับเมทริกซ์และเวกเตอร์ Kaldi เช่นแปลงเป็น Numpy ndarrays และในทางกลับกันลองดูแพ็คเกจ matrix หากคุณต้องการใช้ Kaldi สำหรับการแยกและการแปลงคุณลักษณะให้ตรวจสอบ feat , ivector และ transform Packages หากคุณต้องการทำงานกับ lattices หรือโครงสร้าง FST อื่น ๆ ที่ผลิต/บริโภคโดยเครื่องมือ Kaldi ลองดูแพ็คเกจ fstext , lat และ kws หากคุณต้องการการเข้าถึงแบบจำลองส่วนผสมแบบเกาส์ระดับต่ำรุ่นมาร์คอฟที่ซ่อนอยู่หรือต้นไม้ตัดสินใจออกเสียงใน Kaldi ลองดู gmm , sgmm2 , hmm และแพ็คเกจ tree หากคุณต้องการการเข้าถึงรุ่นเครือข่าย Kaldi Neural ระดับต่ำให้ตรวจสอบแพ็คเกจ nnet3 , cudamatrix และ chain หากคุณต้องการใช้ตัวถอดรหัสและยูทิลิตี้การสร้างแบบจำลองภาษาใน Kaldi ลองดู decoder , lm , rnnlm , tfrnnlm และแพ็คเกจ online2
ผู้อ่านที่สนใจที่ต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Kaldi และ Pykaldi อาจพบว่าแหล่งข้อมูลต่อไปนี้มีประโยชน์:
เนื่องจากการจดจำคำพูดอัตโนมัติ (ASR) ใน Python นั้นไม่ต้องสงสัยเลยว่า "แอพนักฆ่า" สำหรับ Pykaldi เราจะไปดูสถานการณ์ ASR สองสามสถานการณ์เพื่อให้ได้รับความรู้สึกของ Pykaldi API เราควรทราบว่า Pykaldi ไม่ได้ให้บริการสาธารณูปโภคระดับสูงสำหรับการฝึกอบรมแบบจำลอง ASR ดังนั้นคุณต้องฝึกอบรมโมเดลของคุณโดยใช้สูตรอาหาร Kaldi หรือใช้รุ่นที่ผ่านการฝึกอบรมมาก่อนออนไลน์ เหตุผลที่เป็นเช่นนี้เป็นเพียงเพราะไม่มี API การฝึกอบรม ASR ระดับสูงในห้องสมุด Kaldi C ++ โมเดล Kaldi ASR ได้รับการฝึกฝนโดยใช้สูตรระดับเชลล์ที่ซับซ้อนซึ่งจัดการทุกอย่างตั้งแต่การเตรียมข้อมูลไปจนถึงการประสานงานของ Executables Myriad Kaldi ที่ใช้ในการฝึกอบรม นี่คือการออกแบบและไม่น่าจะเปลี่ยนแปลงในอนาคต Pykaldi ให้ wrappers สำหรับยูทิลิตี้การฝึกอบรม ASR ระดับต่ำในห้องสมุด Kaldi C ++ แต่สิ่งเหล่านี้ไม่ได้มีประโยชน์จริง ๆ เว้นแต่คุณต้องการสร้างท่อฝึกอบรม ASR ใน Python จากการสร้างขั้นพื้นฐานซึ่งไม่ใช่เรื่องง่าย ดำเนินการต่อด้วยการเปรียบเทียบเลโก้งานนี้คล้ายกับการสร้างการเข้าถึงรถบรรทุกที่เต็มไปด้วยเลโก้ที่คุณอาจต้องการ หากคุณบ้าพอที่จะลองโปรดอย่าปล่อยให้ย่อหน้านี้ทำให้คุณท้อแท้ ก่อนที่เราจะเริ่มสร้าง Pykaldi เราคิดว่านั่นเป็นงานของ Mad Man ด้วย
โมดูล Pykaldi asr รวมถึงคลาสที่ใช้งานง่ายและใช้งานได้ง่ายเพื่อให้ตายง่ายในการรวบรวมระบบ ASR ใน Python การเพิกเฉยต่อรหัสหม้อไอน้ำที่จำเป็นสำหรับการตั้งค่าสิ่งต่าง ๆ การทำ ASR กับ Pykaldi อาจเป็นเรื่องง่ายเหมือนตัวอย่างของโค้ดต่อไปนี้:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) ในตัวอย่างที่ง่ายขึ้นนี้เราจะยกตัวอย่างการจำแนกตัวอักษรสมมุติฐาน SomeRecognizer ด้วยเส้นทางสำหรับโมเดล final.mdl , กราฟการถอดรหัส HCLG.fst และคำว่าตารางสัญลักษณ์ words.txt วัตถุ opts มีตัวเลือกการกำหนดค่าสำหรับผู้จำแนก จากนั้นเรายกตัวอย่างตัวอ่านตาราง Pykaldi SequentialMatrixReader สำหรับการอ่านเมทริกซ์คุณสมบัติที่เก็บไว้ใน Kaldi Archive feats.ark ในที่สุดเราก็วนซ้ำเมทริกซ์คุณลักษณะและถอดรหัสทีละรายการ ที่นี่เราเพียงแค่พิมพ์สมมติฐาน ASR ที่ดีที่สุดสำหรับแต่ละคำพูดดังนั้นเราจึงสนใจเฉพาะรายการ "text" ของพจนานุกรมเอาท์พุท out โปรดทราบว่าพจนานุกรมเอาท์พุทมีรายการที่มีประโยชน์อื่น ๆ เช่นการจัดตำแหน่งระดับเฟรมของสมมติฐานที่ดีที่สุดและตาข่ายถ่วงน้ำหนักซึ่งเป็นตัวแทนของสมมติฐานที่น่าจะเป็นไปได้มากที่สุด เป็นที่ยอมรับกันว่าท่อ ASR ทั้งหมดจะง่ายเหมือนตัวอย่างนี้ แต่พวกเขามักจะมีโครงสร้างโดยรวมเหมือนกัน ในส่วนต่อไปนี้เราจะเห็นว่าเราสามารถปรับรหัสที่ให้ไว้ข้างต้นเพื่อใช้ท่อ ASR ที่ซับซ้อนมากขึ้นได้อย่างไร
นี่เป็นสถานการณ์ที่พบบ่อยที่สุด เราต้องการทำ ASR แบบออฟไลน์โดยใช้โมเดล Kaldi ที่ผ่านการฝึกอบรมมาแล้วเช่น Aspire Chain Models ที่นี่เราใช้คำว่า "โมเดล" อย่างหลวม ๆ เพื่ออ้างถึงทุกสิ่งที่เราต้องรวบรวมระบบ ASR ในตัวอย่างที่เฉพาะเจาะจงนี้เราจะต้องการ:
โปรดทราบว่าคุณสามารถใช้รหัสตัวอย่างนี้เพื่อถอดรหัสด้วยโมเดล Aspire Chain
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] ความแตกต่างพื้นฐานระหว่างตัวอย่างนี้และตัวอย่างสั้น ๆ จากส่วนสุดท้ายคือสำหรับคำพูดแต่ละครั้งเรากำลังอ่านข้อมูลเสียงดิบจากดิสก์และการคำนวณเมทริกซ์คุณลักษณะสองตัวที่บินได้ทันทีแทนที่จะอ่านเมทริกซ์คุณสมบัติที่ผ่านการคำนวณล่วงหน้าเพียงครั้งเดียวจากดิสก์ ไฟล์สคริปต์ wav.scp มีรายการไฟล์ WAV ที่สอดคล้องกับคำพูดที่เราต้องการถอดรหัส เมทริกซ์คุณสมบัติเพิ่มเติมที่เรากำลังแยกประกอบด้วย i-vectors ออนไลน์ที่ใช้โดยโมเดลอะคูสติกเครือข่ายประสาทเพื่อดำเนินการปรับช่องและการปรับลำโพง แผนที่ spk2utt แบบลำโพงใช้สำหรับสะสมสถิติแยกต่างหากสำหรับผู้พูดแต่ละคนในการสกัด I-Vector ออนไลน์ อาจเป็นการแมปข้อมูลประจำตัวอย่างง่ายหากข้อมูลลำโพงไม่สามารถใช้ได้ เราบรรจุคุณสมบัติ MFCC และ i-vectors ไว้ใน tuple และส่งผ่าน tuple นี้ไปยังผู้จดจำสำหรับการถอดรหัส ผู้จำแนกเครือข่ายประสาทใน Pykaldi รู้วิธีจัดการกับคุณสมบัติ I-Vector เพิ่มเติมเมื่อมีอยู่ ไฟล์โมเดล final.mdl มีทั้งโมเดลการเปลี่ยนแปลงและโมเดลอะคูสติกเครือข่ายประสาท กระบวนการ NnetLatticeFasterRecognizer มีเมทริกซ์โดยการคำนวณความน่าจะเป็นบันทึกโทรศัพท์ครั้งแรกโดยใช้โมเดลอะคูสติกเครือข่ายประสาทจากนั้นทำแผนที่การเปลี่ยนความน่าจะเป็นของบันทึกการเปลี่ยนแปลงโดยใช้ HCLG.fst การเปลี่ยนแปลง หลังจากถอดรหัสเราบันทึกตาข่ายที่สร้างขึ้นโดยผู้จดจำไปยังคลังเก็บของ Kaldi สำหรับการประมวลผลในอนาคต
ตัวอย่างนี้ยังแสดงให้เห็นถึงกลไก I/O ที่ทรงพลังที่จัดทำโดย Kaldi แทนที่จะใช้ท่อส่งสารสกัดในรหัสเรากำหนดให้เป็นตัวระบุการอ่าน kaldi และคำนวณเมทริกซ์คุณสมบัติเพียงแค่การสร้างอินสแตนซ์ของผู้อ่านตาราง Pykaldi และวนซ้ำพวกเขา นี่ไม่ได้เป็นเพียงวิธีที่ง่ายที่สุด แต่ยังเป็นวิธีการคำนวณที่เร็วที่สุดด้วย pykaldi เนื่องจากการสกัดฟีเจอร์ไปป์ไลน์ทำงานแบบขนานโดยระบบปฏิบัติการ ในทำนองเดียวกันเราใช้ตัวระบุการเขียน Kaldi เพื่อสร้างอินสแตนซ์นักเขียนตาราง Pykaldi ซึ่งเขียนผลงานขัดออกไปยังคลังเก็บ Kaldi ที่บีบอัด โปรดทราบว่าเพื่อให้สิ่งเหล่านี้ทำงานได้เราจำเป็นต้องมี compute-mfcc-feats , ivector-extract-online2 และ gzip เพื่ออยู่บน PATH ของเรา
สิ่งนี้คล้ายกับสถานการณ์ก่อนหน้า แต่แทนที่จะเป็นโมเดลอะคูสติก Kaldi เราใช้โมเดลอะคูสติก Pytorch หลังจากคำนวณคุณสมบัติก่อนหน้านี้เราจะแปลงเป็นเทนเซอร์ Pytorch ทำผ่านไปข้างหน้าโดยใช้โมดูลเครือข่าย Neural Module Pytorch Outputting Logelie-Likelies และในที่สุดก็แปลงความน่าจะเป็นบันทึกเหล่านั้นกลับมาเป็นเมทริกซ์ Pykaldi สำหรับการถอดรหัส Recognizer ใช้โมเดลการเปลี่ยนแปลงเพื่อแมปรหัสโทรศัพท์โดยอัตโนมัติไปยัง ID Transition โดยอัตโนมัติป้ายอินพุตบนกราฟการถอดรหัส Kaldi ทั่วไป
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]ส่วนนี้เป็นตัวยึดตำแหน่ง ตรวจสอบสคริปต์นี้ในระหว่างนี้
การช่วยเหลือ Lattice เป็นเทคนิคมาตรฐานสำหรับการใช้แบบจำลองภาษา N-GRAM ขนาดใหญ่หรือโมเดลภาษาเครือข่ายประสาทที่เกิดขึ้นซ้ำ (RNNLMS) ใน ASR ในตัวอย่างนี้เราช่วยให้ขัดแตะโดยใช้ kaldi rnnlm ก่อนอื่นเราจะสร้างอินสแตนซ์ Rescorer โดยการจัดหาเส้นทางสำหรับโมเดล จากนั้นเราใช้เครื่องอ่านตารางเพื่อทำซ้ำผ่านขัดแตะที่เราต้องการช่วยชีวิตและในที่สุดเราก็ใช้นักเขียนตารางเพื่อเขียน lattices ที่ได้รับการช่วยเหลือกลับไปที่ดิสก์
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) สังเกตชื่อไฟล์เพิ่มเติมที่เราใช้ในการคำนวณคำที่ฝังอยู่จากคุณสมบัติของคำและคุณลักษณะที่ฝังอยู่ทันที นอกจากนี้ยังมีหมายเหตุคือตัวระบุการอ่าน/เขียนที่เราใช้ในการคลายการบีบอัด/บีบอัดคลังเก็บของขัดแตะอย่างโปร่งใส เพื่อให้สิ่งเหล่านี้ทำงานได้เราจำเป็นต้องมี rnnlm-get-word-embedding , gunzip และ gzip เพื่ออยู่บน PATH ของเรา
Pykaldi ตั้งเป้าหมายที่จะเชื่อมช่องว่างระหว่าง Kaldi และสิ่งดีๆทั้งหมดที่ Python มีให้ มันเป็นมากกว่าคอลเลกชันของการผูกเข้าสู่ห้องสมุด Kaldi มันเป็นเลเยอร์สคริปต์ที่ให้การสนับสนุนชั้นหนึ่งสำหรับประเภท Kaldi และ OpenFst ที่จำเป็นใน Python เวกเตอร์ Pykaldi และเมทริกซ์ถูกรวมเข้ากับ numpy อย่างแน่นหนา พวกเขาสามารถแปลงเป็นอาร์เรย์ numpy ได้อย่างราบรื่นและในทางกลับกันโดยไม่ต้องคัดลอกบัฟเฟอร์หน่วยความจำพื้นฐาน ประเภทของ Pykaldi FST รวมถึง Kaldi Style Style เป็นพลเมืองชั้นหนึ่งใน Python API สำหรับผู้ใช้ที่ต้องเผชิญกับประเภทและการดำเนินงานของ FST นั้นเกือบทั้งหมดกำหนดไว้ใน Python เลียนแบบ API ที่เปิดเผยโดย PyWrapfst ซึ่งเป็น wrapper Python อย่างเป็นทางการสำหรับ OpenFST
Pykaldi ควบคุมพลังของ CLIF ในการห่อไลบรารี Kaldi และ OpenFST C ++ โดยใช้คำอธิบาย API อย่างง่าย โมดูลส่วนขยาย cpython ที่สร้างโดย CLIF สามารถนำเข้าใน Python เพื่อโต้ตอบกับ Kaldi และ OpenFST ในขณะที่ CLIF นั้นยอดเยี่ยมสำหรับการเปิดเผย C ++ API ที่มีอยู่ใน Python, wrappers ไม่ได้เปิดเผย API "pythonic" ที่ใช้งานง่ายจาก Python Pykaldi กล่าวถึงสิ่งนี้โดยการขยาย wrappers clif ดิบใน Python (และบางครั้งใน C ++) เพื่อให้ API "pythonic" มากขึ้น รูปด้านล่างแสดงให้เห็นว่า Pykaldi เหมาะกับระบบนิเวศ Kaldi
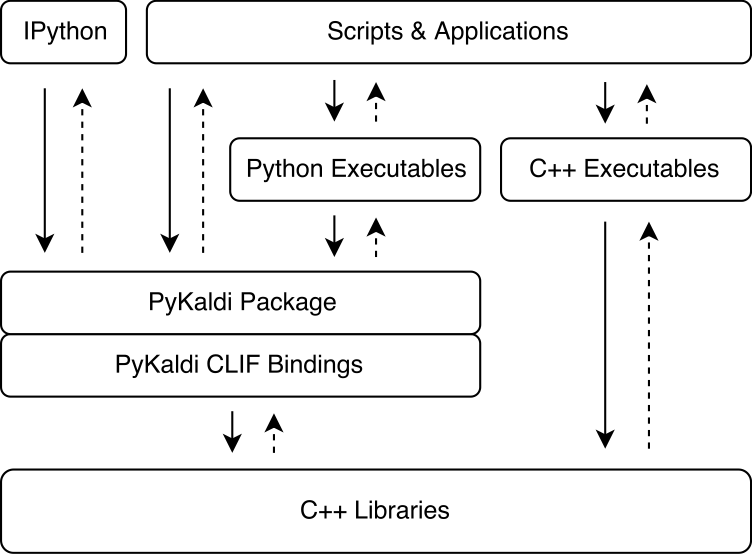
Pykaldi มีการออกแบบแบบแยกส่วนซึ่งทำให้ง่ายต่อการบำรุงรักษาและขยาย ไฟล์ต้นฉบับถูกจัดระเบียบในแผนผังไดเรกทอรีที่เป็นแบบจำลองของแผนผังแหล่งกำเนิด Kaldi แต่ละไดเรกทอรีกำหนดแพคเกจย่อยและมีเฉพาะรหัสห่อหุ้มที่เขียนขึ้นสำหรับไลบรารี Kaldi ที่เกี่ยวข้อง รหัสห่อหุ้มประกอบด้วย:
คำอธิบาย Clif C ++ API กำหนดประเภทและฟังก์ชั่นที่จะห่อและ Python API ของพวกเขา
ส่วนหัว C ++ ที่กำหนดรหัส shims สำหรับรหัส kaldi ที่ไม่สอดคล้องกับสไตล์ Google C ++ ที่คาดว่าจะเกิดขึ้นโดย CLIF
โมดูล Python จัดกลุ่มโมดูลส่วนขยายที่เกี่ยวข้องที่สร้างขึ้นด้วย CLIF และขยาย Wrappers Clif ดิบเพื่อให้ API "pythonic" มากขึ้น
คุณสามารถอ่านเพิ่มเติมเกี่ยวกับการออกแบบและรายละเอียดทางเทคนิคของ Pykaldi ในกระดาษของเรา
ตารางต่อไปนี้แสดงสถานะของแต่ละแพ็คเกจ Pykaldi (ขณะนี้เราไม่ได้วางแผนที่จะเพิ่มการสนับสนุนสำหรับ NNET, NNET2 และออนไลน์) ตามมิติต่อไปนี้:
| บรรจุุภัณฑ์ | ห่อ? | Pythonic? | เอกสาร? | ทดสอบ? |
|---|---|---|---|---|
| ฐาน | ||||
| โซ่ | ||||
| Cudamatrix | ||||
| ตัวถอดรหัส | ||||
| ความสำเร็จ | ||||
| fstext | ||||
| GMM | ||||
| อืม | ||||
| ไม้เลื้อย | ||||
| KWS | ||||
| ละทิ้ง | ||||
| LM | ||||
| เมทริกซ์ | ||||
| nnet3 | ||||
| ออนไลน์ 2 | ||||
| rnnlm | ||||
| SGMM2 | ||||
| tfrnnlm | ||||
| เปลี่ยนรูป | ||||
| ต้นไม้ | ||||
| ใช้ |
หากคุณใช้ linux หรือ macOS ที่ค่อนข้างล่าสุดเช่น Ubuntu> = 16.04, centos> = 7 หรือ macOS> = 10.13 คุณควรติดตั้ง pykaldi โดยไม่มีปัญหามากเกินไป มิฉะนั้นคุณอาจต้องปรับแต่งสคริปต์การติดตั้ง
ตอนนี้คุณสามารถดาวน์โหลดแพ็คเกจ WHL อย่างเป็นทางการได้จากหน้า GitHub Release ของเรา เรามีแพ็คเกจ WHL สำหรับ Python 3.7, 3.8, ... , 3.11 บน Linux และมีการสร้าง (ทดลอง) ไม่กี่รายการสำหรับ Mac M1/M2
หากคุณตัดสินใจใช้แพ็คเกจ WHL คุณสามารถข้ามส่วนถัดไปและตรงไปที่ "เริ่มต้นโครงการใหม่ด้วยแพ็คเกจ Pykaldi WHL" เพื่อตั้งค่าโครงการของคุณ โปรดทราบว่าคุณยังต้องรวบรวม Kaldi รุ่นที่เข้ากันได้กับ Pykaldi
ในการติดตั้งและสร้าง Pykaldi จากแหล่งที่มาให้ทำตามขั้นตอนที่ระบุไว้ด้านล่าง
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldiแม้ว่าจะไม่จำเป็น แต่เราขอแนะนำให้ติดตั้ง pykaldi และการพึ่งพา python ทั้งหมดภายในสภาพแวดล้อม Python ที่แยกได้ใหม่ หากคุณไม่ต้องการสร้างสภาพแวดล้อม Python ใหม่คุณสามารถข้ามขั้นตอนที่เหลือของขั้นตอนนี้ได้
คุณสามารถใช้เครื่องมือใด ๆ ที่คุณต้องการในการสร้างสภาพแวดล้อม Python ใหม่ ที่นี่เราใช้ virtualenv แต่คุณสามารถใช้เครื่องมืออื่นเช่น conda ถ้าคุณต้องการ ตรวจสอบให้แน่ใจว่าคุณเปิดใช้งานสภาพแวดล้อม Python ใหม่ก่อนที่จะดำเนินการต่อไปกับส่วนที่เหลือของการติดตั้ง
virtualenv env
source env/bin/activateการรันคำสั่งด้านล่างจะติดตั้งแพ็คเกจระบบที่จำเป็นสำหรับการสร้าง pykaldi จากแหล่งที่มา
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "การรันคำสั่งด้านล่างจะติดตั้งแพ็คเกจ Python ที่จำเป็นสำหรับการสร้าง Pykaldi จากแหล่งที่มา
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommendedนอกเหนือจากแพ็คเกจที่ระบุไว้ข้างต้นแล้วเรายังต้องมีการติดตั้งที่เข้ากันได้กับ Pykaldi ของซอฟต์แวร์ต่อไปนี้:
Google Protobuf แนะนำ v3.5.0 ทั้งไลบรารี C ++ และแพ็คเกจ Python จะต้องติดตั้ง
Pykaldi เข้ากันได้กับ Clif เพื่อปรับปรุงการพัฒนา Pykaldi เราได้ทำการเปลี่ยนแปลง CLIF Codebase เราหวังว่าจะได้รับการเปลี่ยนแปลงเหล่านี้เมื่อเวลาผ่านไป การเปลี่ยนแปลงเหล่านี้อยู่ในสาขา Pykaldi:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi คุณสามารถใช้สคริปต์ในไดเรกทอรี tools เพื่อติดตั้งหรืออัปเดตซอฟต์แวร์เหล่านี้ในเครื่อง ตรวจสอบให้แน่ใจว่าคุณตรวจสอบผลลัพธ์ของสคริปต์เหล่านี้ หากคุณไม่เห็น Done installing {protobuf,CLIF,Kaldi} พิมพ์ในตอนท้ายนั่นหมายความว่าการติดตั้งล้มเหลวด้วยเหตุผลบางอย่าง
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..หมายเหตุหากคุณกำลังรวบรวม Kaldi บน Apple Silicion และ ./install_kaldi.sh ติดอยู่ที่จุดเริ่มต้นการรวบรวม SCTK คุณอาจต้องลบ -march = ดั้งเดิมจากเครื่องมือ/kaldi/เครื่องมือ/makefile เช่นการปลดมันในบรรทัดนี้เช่นนี้:
SCTK_CXFLAGS = -w # -march=native หากมีการติดตั้ง Kaldi ภายในไดเรกทอรี tools และการพึ่งพา Python ทั้งหมด (numpy, pyparsing, pyclif, protobuf) จะถูกติดตั้งในสภาพแวดล้อม python ที่ใช้งานอยู่คุณสามารถติดตั้ง pykaldi ด้วยคำสั่งต่อไปนี้
python setup.py installเมื่อติดตั้งแล้วคุณสามารถเรียกใช้การทดสอบ Pykaldi ด้วยคำสั่งต่อไปนี้
python setup.py testจากนั้นคุณสามารถสร้างแพ็คเกจ WHL ได้ แพ็คเกจ WHL ทำให้ง่ายต่อการติดตั้ง Pykaldi ในสภาพแวดล้อมโครงการใหม่สำหรับโครงการพูดของคุณ
python setup.py bdist_wheelไฟล์ WHL นั้นสามารถพบได้ในโฟลเดอร์ "DIST" ชื่อไฟล์ WHL ขึ้นอยู่กับเวอร์ชัน Pykaldi รุ่น Python และสถาปัตยกรรมของคุณ สำหรับ Python 3.9 Build บน X86_64 ด้วย Pykaldi 0.2.2 มันอาจดูเหมือน: dist/pykaldi-0.2.2.2.2-cp39-cp39-linux_x86_64.whl
สร้างโฟลเดอร์โครงการใหม่เช่น:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRสร้างและเปิดใช้งานสภาพแวดล้อมเสมือนจริงที่มีรุ่น Python เดียวกันกับแพ็คเกจ WHL เช่น Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateติดตั้ง numpy และ pykaldi ลงในสภาพแวดล้อม myasr ของคุณ:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl คัดลอก pykaldi/tools/install_kaldi.sh ไปยังโครงการ MYASR ของคุณ ใช้สคริปต์ install_kaldi.sh เพื่อติดตั้งรุ่น Kaldi ที่เข้ากันได้กับ Pykaldi สำหรับโครงการของคุณ:
./install_kaldi.shคัดลอก pykaldi/tools/path.sh ไปยังโครงการของคุณ Path.sh ใช้เพื่อทำให้ Pykaldi ค้นหาห้องสมุด Kaldi และไบนารีในโฟลเดอร์ Kaldi Source Path.sh ด้วย:
. path.shขอแสดงความยินดีคุณพร้อมที่จะใช้ Pykaldi ในโครงการของคุณ!
หมายเหตุ: เมื่อใดก็ตามที่คุณเปิดเชลล์ใหม่คุณต้องจัดหาสภาพแวดล้อมของโครงการและ path.sh:
. myasr_env/bin/activate
. path.shหมายเหตุ: น่าเสียดายที่แพ็คเกจ Pykaldi Conda ล้าสมัย หากคุณต้องการรักษาไว้โปรดติดต่อเรา
ในการติดตั้ง Pykaldi ด้วยการสนับสนุน CUDA:
conda install -c pykaldi pykaldiในการติดตั้ง pykaldi โดยไม่สนับสนุน CUDA (CPU เท่านั้น):
conda install -c pykaldi pykaldi-cpuโปรดทราบว่าแพ็คเกจ Pykaldi Conda ไม่ได้ให้การดำเนินการของ Kaldi หากคุณต้องการใช้ Executables Kaldi พร้อมกับ Pykaldi เช่นเป็นส่วนหนึ่งของตัวระบุการอ่าน/เขียนคุณต้องติดตั้ง Kaldi แยกกัน
หมายเหตุ: คำแนะนำนักเทียบท่าด้านล่างอาจล้าสมัย หากคุณต้องการรักษาภาพนักเทียบท่าสำหรับ Pykaldi โปรดติดต่อเรา
หากคุณต้องการใช้ Pykaldi ภายในคอนเทนเนอร์ Docker ให้ทำตามคำแนะนำในโฟลเดอร์ docker
โดยค่าเริ่มต้นคำสั่ง Pykaldi Install ใช้โปรเซสเซอร์ (ตรรกะ) ที่มีอยู่ทั้งหมดเพื่อเร่งกระบวนการสร้าง หากขนาดของหน่วยความจำระบบค่อนข้างเล็กเมื่อเทียบกับจำนวนโปรเซสเซอร์งานการรวบรวม/เชื่อมโยงแบบขนานอาจจบลงด้วยการทำให้หน่วยความจำระบบหมดแรงและส่งผลให้เกิดการแลกเปลี่ยน คุณสามารถ จำกัด จำนวนงานคู่ขนานที่ใช้สำหรับการสร้าง Pykaldi ดังนี้:
MAKE_NUM_JOBS=2 python setup.py installเราไม่รู้ว่าสิ่งที่จำเป็นในการสร้าง Pykaldi บน Windows มันอาจจะต้องมีการเปลี่ยนแปลงมากมายในระบบการสร้าง
ในขณะนี้ Pykaldi ไม่สามารถใช้งานได้กับที่เก็บ Kaldi ต้นน้ำ คุณต้องสร้างมันกับ Kaldi Fork ของเรา
หากคุณมีการติดตั้ง Kaldi ที่เข้ากันได้แล้วในระบบของคุณคุณไม่จำเป็นต้องติดตั้งใหม่ภายในไดเรกทอรี pykaldi/tools แต่คุณสามารถตั้งค่าตัวแปรสภาพแวดล้อมต่อไปนี้ก่อนที่จะเรียกใช้คำสั่งการติดตั้ง Pykaldi
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >ในขณะนี้ Pykaldi ไม่สามารถใช้งานได้กับที่เก็บ CLIF ต้นน้ำ คุณต้องสร้างมันโดยใช้ CLIF Fork ของเรา
หากคุณมีการติดตั้ง CLIF ที่เข้ากันได้แล้วในระบบของคุณคุณไม่จำเป็นต้องติดตั้งใหม่ภายในไดเรกทอรี pykaldi/tools แต่คุณสามารถตั้งค่าตัวแปรสภาพแวดล้อมต่อไปนี้ก่อนที่จะเรียกใช้คำสั่งการติดตั้ง Pykaldi
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > ในขณะที่ความจำเป็นในการอัปเดต Protobuf และ CLIF ไม่ควรเกิดขึ้นบ่อยนัก แต่คุณอาจต้องการหรือจำเป็นต้องอัปเดตการติดตั้ง Kaldi ที่ใช้สำหรับการสร้าง Pykaldi เรียกใช้สคริปต์การติดตั้งที่เกี่ยวข้องในไดเรกทอรี tools ควรอัปเดตการติดตั้งที่มีอยู่ หากไม่ได้ผลโปรดเปิดปัญหา
แพ็คเกจ Pykaldi tfrnnlm ถูกสร้างขึ้นโดยอัตโนมัติพร้อมกับส่วนที่เหลือของ Pykaldi หากห้องสมุด kaldi-tensorflow-rnnlm สามารถพบได้ในห้องสมุด Kaldi หลังจากสร้าง kaldi ไปที่ KALDI_DIR/src/tfrnnlm/ ไดเรกทอรีและทำตามคำแนะนำที่ให้ไว้ใน makefile ตรวจสอบให้แน่ใจว่าลิงค์สัญลักษณ์สำหรับไลบรารี kaldi-tensorflow-rnnlm จะถูกเพิ่มลงใน KALDI_DIR/src/lib/ ไดเรกทอรี
Shennong - กล่องเครื่องมือสำหรับการสกัดคุณสมบัติการพูดเช่น MFCC, PLP ฯลฯ โดยใช้ Pykaldi
Kaldi Model Server - เซิร์ฟเวอร์โมเดล Kaldi แบบเธรดสำหรับการถอดรหัสสด สามารถถอดรหัสคำพูดโดยตรงจากไมโครโฟนของคุณด้วยโมเดลที่เข้ากันได้กับ NNET3 ตัวอย่างรุ่นสำหรับภาษาอังกฤษและภาษาเยอรมันมีให้บริการ ใช้ตัวถอดรหัส Pykaldi Online2
MeetingBot-ตัวอย่างของเว็บแอปพลิเคชันสำหรับการถอดความและการสรุปที่ใช้ประโยชน์จากแบ็กเอนด์ Pykaldi/Kaldi-Model-Model-Model-Model เพื่อแสดงผล ASR ในเบราว์เซอร์
Subtitle2GO - การสร้างคำบรรยายอัตโนมัติสำหรับไฟล์สื่อใด ๆ ใช้ Pykaldi สำหรับ ASR กับตัวถอดรหัสแบทช์
หากคุณมีโครงการโอเพ่นซอร์สสุดเจ๋งที่ใช้ Pykaldi ที่คุณต้องการแสดงที่นี่โปรดแจ้งให้เราทราบ!
หากคุณใช้ Pykaldi เพื่อการวิจัยโปรดอ้างอิงบทความของเราดังนี้:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
เราขอขอบคุณการมีส่วนร่วมทั้งหมด! หากคุณพบข้อผิดพลาดอย่าลังเลที่จะเปิดปัญหาหรือคำขอดึง หากคุณต้องการขอหรือเพิ่มคุณสมบัติใหม่โปรดเปิดปัญหาสำหรับการสนทนา


