pykaldi
v0.2.2
Pykaldi - это слой сценариев Python для инструментария распознавания речи Kaldi. Он обеспечивает простые в использовании, низкопользовые, первоклассные обертки Python для кода C ++ в библиотеках Kaldi и OpenFST. Вы можете использовать Pykaldi для написания кода Python для вещей, которые в противном случае потребовали бы написания кода C ++, таких как вызов функций Kaldi низкого уровня, манипулирование объектами Kaldi и OpenFST в коде или реализации новых инструментов Kaldi.
Вы можете думать о Калди как о большой коробке Legos, которую вы можете смешать и сопоставить для создания пользовательских решений для распознавания речи. Лучший способ подумать о Пикальди - это добавка, абокулатный, если хотите, для Кальди. На самом деле, Пикальди в лучшем виде, когда он используется вместе с Кальди. С этой целью воспроизведение функциональности инструментов командной строки множества, сценариев утилиты и рецептов уровня оболочки, предоставленных Kaldi, является нецеливым для проекта Pykaldi.
Как и Кальди, Пикальди в основном предназначен для исследователей и профессионалов распознавания речи. Именно варенье, наполненное вкусностями, нужно было бы создать программное обеспечение Python, используя преимущества обширной коллекции коммунальных услуг, алгоритмов и структур данных, предоставленных библиотеками Kaldi и OpenFST.
Если вы не знакомы с распознаванием речи на основе FST или не заинтересованы в том, чтобы получить доступ к кишкам Kaldi и OpenFST в Python, но хотите запустить предварительно обученную систему Кальди как часть вашего приложения Python, не беспокойтесь. Pykaldi включает в себя ряд высокоуровневых модулей, ориентированных на приложения, таких как asr , alignment и segmentation , которые должны быть доступны для большинства программистов Python.
Если вы заинтересованы в использовании Pykaldi для исследования или создания расширенных приложений ASR, вам повезло. Pykaldi поставляется со всем, что вам нужно читать, писать, осматривать, манипулировать или визуализировать объекты Kaldi и OpenFST в Python. Он включает в себя обертки Python для большинства функций и методов, которые являются частью публичных API библиотек Kaldi и OpenFST C ++. Если вы хотите прочитать/записать файлы, которые производятся/потребляются инструментами Kaldi, посетите утилиты ввода -вывода и таблицы в пакете util . Если вы хотите поработать с матрицами и векторами Kaldi, например, преобразуйте их в Numpy Ndarrays и наоборот, ознакомьтесь с пакетом matrix . Если вы хотите использовать Kaldi для извлечения и преобразования функций, ознакомьтесь с пакетами feat , ivector и transform . Если вы хотите работать с решетчатыми или другими структурами FST, производимыми/потребляемыми инструментами Kaldi, ознакомьтесь с пакетами fstext , lat и kws . Если вам нужен доступ к низкоуровневым моделям смесей гауссов, скрытые модели Маркова или деревья фонетических решений в Кальди, ознакомьтесь с пакетами gmm , sgmm2 , hmm и tree . Если вам нужен доступ к низкоуровневым моделям нейронной сети Kaldi, ознакомьтесь с nnet3 , cudamatrix и chain Packages. Если вы хотите использовать утилиты для моделирования декодеров и языка в Кальди, ознакомьтесь decoder , lm , rnnlm , tfrnnlm и online2 .
Заинтересованные читатели, которые хотели бы узнать больше о Калди и Пикальди, могут найти следующие ресурсы полезными:
Поскольку автоматическое распознавание речи (ASR) в Python, несомненно, является «приложением -убийцей» для Pykaldi, мы рассмотрим несколько сценариев ASR, чтобы почувствовать API Pykaldi. Следует отметить, что Pykaldi не предоставляет никаких высокоуровневых утилит для обучения моделей ASR, поэтому вам необходимо обучать свои модели, используя рецепты Kaldi или использовать предварительно обученные модели, доступные в Интернете. Причина, по которой это так, заключается в том, что в библиотеках Kaldi C ++ нет высокоуровневого обучения ASR. Модели Kaldi ASR обучаются с использованием сложных рецептов на уровне оболочки, которые обрабатывают все, от подготовки данных до оркестровки исполняемых файлов Myriad Kaldi, используемых при обучении. Это по дизайну и вряд ли изменится в будущем. Pykaldi обеспечивает обертки для обучающих утилит для ASR низкого уровня в библиотеках Kaldi C ++, но они не очень полезны, если вы не хотите создать тренировочный трубопровод ASR в Python из основных строительных блоков, что не является легкой задачей. Продолжая аналогию LEGO, эта задача сродни созданию этого данного доступа к грузовику, полному LEGO, вам может понадобиться. Если вы достаточно сумасшедшие, чтобы попробовать, пожалуйста, не позволяйте этому абзацу вам отговорить. Прежде чем мы начали строить Пикальди, мы подумали, что это тоже задача Безумного человека.
Модуль Pykaldi asr включает в себя ряд простых в использовании классов высокого уровня, чтобы сделать его мертвым для составления систем ASR в Python. Игнорирование кода шаблона, необходимого для настройки вещей, выполнение ASR с Pykaldi может быть таким же простым, как следующий фрагмент кода:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) В этом упрощенном примере мы сначала создаем гипотетическое распознавание SomeRecognizer с путями для модели final.mdl , графы декодирования HCLG.fst и таблицы символов words.txt . Объект opts содержит параметры конфигурации для распознавателя. Затем мы создаем экземпляр для чтения читателя таблицы Pykaldi SequentialMatrixReader для чтения матриц функций, хранящихся в Archive feats.ark Kaldi. Наконец, мы повторяем матрицы функций и декодируем их один за другим. Здесь мы просто печатаем лучшую гипотезу ASR для каждого высказывания, поэтому мы заинтересованы только в "text" out выходного словаря. Имейте в виду, что выходной словарь содержит множество других полезных записей, таких как выравнивание уровня кадров наилучшей гипотезы и взвешенная решетка, представляющая наиболее вероятные гипотезы. По общему признанию, не все трубопроводы ASR будут такими же простыми, как этот пример, но они часто будут иметь одинаковую общую структуру. В следующих разделах мы увидим, как мы можем адаптировать приведенный выше код для реализации более сложных трубопроводов ASR.
Это самый распространенный сценарий. Мы хотим сделать в автономном режиме ASR, используя предварительно обученные модели Kaldi, такие как модели Aspire Chain. Здесь мы используем термин «модели» свободно, чтобы ссылаться на все, что нужно было бы собрать систему ASR. В этом конкретном примере нам понадобится:
Обратите внимание, что вы можете использовать этот пример кода для декодирования с помощью моделей Aspire Chain.
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] Основное различие между этим примером и коротким фрагментом из последнего раздела заключается в том, что для каждого высказывания мы читаем необработанные аудиодатики с диска и вычисляем две матрицы функций на лету вместо того, чтобы читать одну предварительно вычисленную матрицу признаков с диска. Файл сценария wav.scp содержит список файлов WAV, соответствующих высказываниям, которые мы хотим декодировать. Дополнительная матрица функций, которую мы извлекаем, содержит онлайн-векторы, которые используются акустической моделью нейронной сети для выполнения адаптации канала и динамиков. Карта динамика к ущербе spk2utt используется для накопления отдельной статистики для каждого динамика в онлайн-экстракции I-вектора. Это может быть простое отображение личных данных, если информация о динамике недоступна. Мы упаковываем функции MFCC и I-векторы в кортеж и передаем этот кортеж до распознателя для декодирования. Позначения нейронной сети в Пикальди знают, как справиться с дополнительными функциями I-вектора, когда они доступны. Файл модели final.mdl содержит как переходную модель, так и акустическую модель нейронной сети. Процессы NnetLatticeFasterRecognizer оснащены матрицами с помощью первой вычислительной логарифмической точки зрения телефона, используя акустическую модель нейронной сети, а затем отображая те, которые с логарифмическими, используя модель перехода, и, наконец, декодируя логарифмические переходные логарифмы на свои последовательности слова, используя график декодирующего графа HCLG.fst , которые имеют переходные идентификаторы на своих идентификаторах ввода и словесные идентификаторы. После декодирования мы сохраняем решетку, создаваемую распознавателем в архив Калди для будущей обработки.
Этот пример также иллюстрирует мощные механизмы ввода/вывода, предоставленные Калди. Вместо того, чтобы внедрить трубопроводы извлечения функций в коде, мы определяем их как спецификаторы Kaldi Read и вычисляем матрицы функций, просто создавая считываемые читатели таблицы Pykaldi и итерацию над ними. Это не только самый простой, но и самый быстрый способ вычислительной функции с Pykaldi, так как конвейер извлечения функций работает параллельно операционной системой. Точно так же мы используем спецификатор записи Kaldi для создания писателя таблицы Pykaldi, который пишет выходные решетки в сжатый архив Калди. Обратите внимание, что для этого нам нужно, compute-mfcc-feats , ivector-extract-online2 и gzip чтобы быть на нашем PATH .
Это похоже на предыдущий сценарий, но вместо акустической модели Калди мы используем акустическую модель питор. После вычисления функций, как и прежде, мы конвертируем их в тензор Pytorch, выполняем переход вперед, используя нейронную сетевую модуль Pytorch, выводящую логарифмическую колоду телефона и, наконец, конвертируйте эти логарифмические правдоподобия обратно в матрицу пикальди для декодирования. Позначатель использует модель перехода для автоматического отображения идентификаторов телефона с идентификаторами перехода, этикетки ввода на типичном графике декодирования Кальди.
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]Этот раздел является заполнителем. Проверьте этот сценарий тем временем.
Резервирование решетки-это стандартный метод использования крупных моделей N-грамма или рецидивирующих моделей языка нейронной сети (RNNLMS) в ASR. В этом примере мы спасаем решетки, используя Kaldi Rnnlm. Сначала мы создаем экземпляр спасателя, предоставляя пути для моделей. Затем мы используем считыватель таблицы для итерации над решетчатыми, которые мы хотим спасти, и, наконец, мы используем автора таблицы, чтобы написать спасенные решетки обратно на диск.
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) Обратите внимание на расширенное имя файла, которое мы использовали для вычисления слова «Встроены» из словных функций и встроенных функций на лету. Также следует отметить, что спецификаторы чтения/записи, которые мы использовали для прозрачного декомпрессии/сжатия архивов решетки. Чтобы они работали, нам нужно, чтобы rnnlm-get-word-embedding , gunzip и gzip были на нашем PATH .
Pykaldi стремится преодолеть разрыв между Кальди и всеми приятными вещами, которые может предложить Python. Это больше, чем набор привязков в библиотеках Калди. Это слой сценариев, обеспечивающий первое классовое поддержку Essential Kaldi и OpenFST в Python. Вектор пикальди и типы матрицы тесно интегрированы с Numpy. Они могут быть беспрепятственно преобразованы в массивы Numpy и наоборот, не копируя базовые буферы памяти. Типы Pykaldi FST, в том числе латиции в стиле Калди, являются первоклассными гражданами в Python. API для пользователя, обращенного к типам и операциям FST, почти полностью определяется в Python, имитирующем API, открытый Pywrapfst, официальной оберткой Python для OpenFST.
Pykaldi использует силу CLIF, чтобы обернуть библиотеки Kaldi и OpenFST C ++, используя простые описания API. Модули расширения CPYTHON, сгенерированные CLIF, могут быть импортированы в Python для взаимодействия с Kaldi и OpenFST. В то время как CLIF отлично подходит для разоблачения существующего API C ++ в Python, обертки не всегда подвергают «Pythonic» API, который легко использовать с Python. Pykaldi обращается к этому, расширяя необработанные обертки CLIF в Python (а иногда и в C ++), чтобы обеспечить более «Pythonic» API. Ниже показано, где Пикальди вписывается в экосистему Калди.
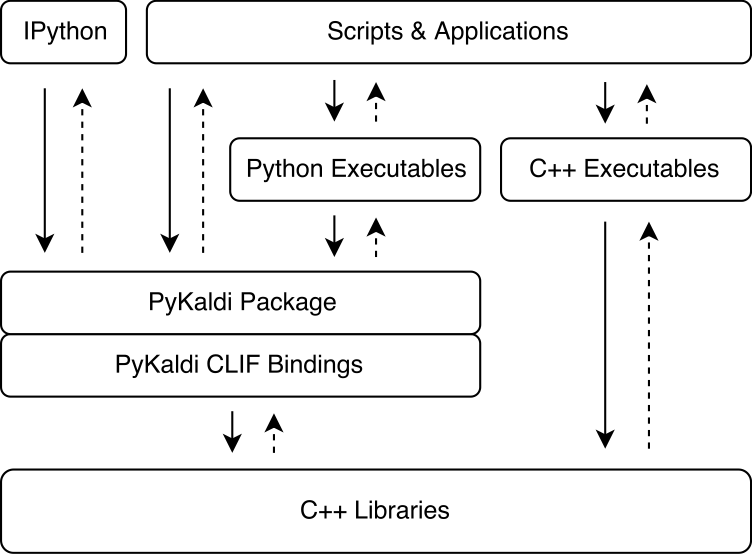
У Pykaldi есть модульный дизайн, который позволяет легко поддерживать и расширять. Исходные файлы организованы в дереве каталогов, которое является копией дерева источника Калди. Каждый каталог определяет подпакукцию и содержит только код обертки, записанный для ассоциированной библиотеки Калди. Код обертки состоит из:
CLIF C ++ API Описания, определяющие типы и функции, которые должны быть обернуты, и их Python API,
Заголовки C ++ определяют прокладки для кода Калди, который не соответствует стилю Google C ++, ожидаемому CLIF,
Модули Python, группирующие вместе связанные модули расширения, сгенерированные с помощью CLIF, и расширяющие обертки CLIF, чтобы обеспечить более «Pythonic» API.
Вы можете прочитать больше о дизайне и технических деталях Pykaldi в нашей статье.
В следующей таблице показан статус каждого пакета Pykaldi (в настоящее время мы не планируем добавлять поддержку NNET, NNET2 и онлайн) в соответствии с следующими измерениями:
| Упаковка | Завернут? | Питоник? | Документация? | Тесты? |
|---|---|---|---|---|
| база | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| цепь | ✔ | ✔ | ✔ ✔ ✔ | |
| Cudamatrix | ✔ | ✔ | ✔ | |
| декодер | ✔ | ✔ | ✔ ✔ ✔ | |
| подвиг | ✔ | ✔ | ✔ ✔ ✔ | |
| fstext | ✔ | ✔ | ✔ ✔ ✔ | |
| Гмм | ✔ | ✔ | ✔ ✔ | ✔ |
| хм | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| прозрачный | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔ ✔ ✔ | |
| лат | ✔ | ✔ | ✔ ✔ ✔ | |
| лм | ✔ | ✔ | ✔ ✔ ✔ | |
| матрица | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| nnet3 | ✔ | ✔ | ✔ | |
| онлайн2 | ✔ | ✔ | ✔ ✔ ✔ | |
| rnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| SGMM2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| преобразование | ✔ | ✔ | ✔ | |
| дерево | ✔ | ✔ | ||
| утилит | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
Если вы используете относительно недавние Linux или MacOS, такие как Ubuntu> = 16,04, centOS> = 7 или macOS> = 10.13, вы сможете установить Pykaldi без особых проблем. В противном случае вам, вероятно, потребуется настроить сценарии установки.
Теперь вы можете загрузить официальные пакеты WHL с нашей страницы выпуска GitHub. У нас есть пакеты WHL для Python 3.7, 3.8, ..., 3.11 на Linux и несколько (экспериментальных) сборки для Mac M1/M2.
Если вы решите использовать пакет WHL, вы можете пропустить следующие разделы и отправиться прямо к «Запуск нового проекта с пакетом Pykaldi WHL», чтобы настроить ваш проект. Обратите внимание, что вам все еще нужно скомпилировать, совместимую с Пикальди версию Кальди.
Чтобы установить и построить пикальди из источника, выполните шаги, приведенные ниже.
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldiХотя это не требуется, мы рекомендуем установить Pykaldi и все его зависимости Python в новой изолированной среде Python. Если вы не хотите создавать новую среду Python, вы можете пропустить оставшуюся часть этого шага.
Вы можете использовать любой инструмент, который вам нравится для создания новой среды Python. Здесь мы используем virtualenv , но вы можете использовать другой инструмент, такой как conda если вы предпочитаете это. Убедитесь, что вы активируете новую среду Python, прежде чем продолжить остальную часть установки.
virtualenv env
source env/bin/activateЗапуск приведенных ниже команд установит системы системных пакетов, необходимых для строительства Pykaldi из Source.
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "Запуск приведенных ниже команд установит пакеты Python, необходимые для строительства Pykaldi из Source.
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommendedВ дополнение к приведенным выше пакетам, нам также нужны совместимые с Pykaldi установки следующего программного обеспечения:
Google Protobuf, рекомендуется v3.5.0. Как библиотека C ++, так и пакет Python должны быть установлены.
Пикальди совместимая вилка Клифа. Чтобы упростить разработку Pykaldi, мы внесли некоторые изменения в кодовую базу CLIF. Мы надеемся со временем вверх по течению. Эти изменения в филиале Pykaldi:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi Вы можете использовать сценарии в каталоге tools для установки или обновления этого программного обеспечения локально. Убедитесь, что вы проверяете вывод этих сценариев. Если вы не видите Done installing {protobuf,CLIF,Kaldi} напечатанные в самом конце, это означает, что установка по какой -то причине не удалась.
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..Обратите внимание, что если вы компилируете Kaldi на яблочном кремнеоне и ./install_kaldi.sh застряли прямо в начале компиляции SCTK, вам, возможно, придется удалить -march = уроженец из инструментов/калди/инструментов/makefile, например, раскрыв его в этой линии, как это:
SCTK_CXFLAGS = -w # -march=native Если Kaldi установлен в каталоге tools , и все зависимости от питона (Numpy, Pyparsing, Pyclif, Protobuf) установлены в среде Active Python, вы можете установить Pykaldi со следующей командой.
python setup.py installПосле установки вы можете запустить тесты Pykaldi со следующей командой.
python setup.py testЗатем вы также можете создать пакет WHL. Пакет WHL позволяет легко установить Pykaldi в новую среду проекта для вашего речевого проекта.
python setup.py bdist_wheelЗатем файл WHL можно найти в папке "DIST". Имя файла WHL зависит от версии Pykaldi, вашей версии Python и вашей архитектуры. Для Python 3.9 построить на x86_64 с Pykaldi 0.2.2 это может выглядеть как: dist/pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl
Например, создайте новую папку проекта:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRСоздайте и активируйте виртуальную среду с той же версией Python, что и пакет WHL, например для Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateУстановите Numpy и Pykaldi в вашу среду MyASR:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl Скопируйте Pykaldi/Tools/install_kaldi.sh в ваш проект MyASR. Используйте сценарий install_kaldi.sh, чтобы установить совместимую версию Kaldi Pykaldi для вашего проекта:
./install_kaldi.shСкопируйте Pykaldi/Tools/path.sh в ваш проект. PATH.SH используется, чтобы заставить Пикальди найти библиотеки Калди и двоичные файлы в папке Кальди. Исходный путь.sh с:
. path.shПоздравляю, вы готовы использовать Pykaldi в своем проекте!
Примечание: в любое время, когда вы открываете новую оболочку, вам нужно найти проектную среду и Path.sh:
. myasr_env/bin/activate
. path.shПримечание. К сожалению, пакеты Pykaldi Conda устарели. Если вы хотите сохранить его, свяжитесь с нами.
Чтобы установить Pykaldi с поддержкой CUDA:
conda install -c pykaldi pykaldiЧтобы установить Pykaldi без поддержки CUDA (только процессор):
conda install -c pykaldi pykaldi-cpuОбратите внимание, что пакет Pykaldi Conda не предоставляет исполняемые файлы Kaldi. Если вы хотите использовать исполнители Kaldi вместе с Pykaldi, например, как часть спецификаторов чтения/записи, вам необходимо установить Kaldi отдельно.
Примечание: приведенные ниже инструкции Docker могут быть устаревшими. Если вы хотите сохранить изображение Docker для Pykaldi, пожалуйста, свяжитесь с нами.
Если вы хотите использовать Pykaldi в контейнере Docker, следуйте инструкциям в папке docker .
По умолчанию команда установки Pykaldi использует все доступные (логические) процессоры для ускорения процесса сборки. Если размер системной памяти относительно невелик по сравнению с количеством процессоров, параллельные задания/связывание заданий могут в конечном итоге исчерпывать системную память и привести к обмену. Вы можете ограничить количество параллельных заданий, используемых для строительства Pykaldi следующим образом:
MAKE_NUM_JOBS=2 python setup.py installМы понятия не имеем, что нужно для построения пикальди в Windows. Вероятно, потребуется много изменений в системе сборки.
На данный момент Пикальди не совместим с репозиторием Kaldi вверх по течению. Вы должны построить его против нашей вилки Калди.
Если у вас уже есть совместимая установка Kaldi в вашей системе, вам не нужно устанавливать новый в каталог pykaldi/tools . Вместо этого вы можете просто установить следующую переменную среды, прежде чем запустить команду установки Pykaldi.
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >На данный момент Пикальди не совместим с репозиторием CLIF вверх по течению. Вы должны построить его, используя нашу вилку Clif.
Если у вас уже есть совместимая установка CLIF в вашей системе, вам не нужно устанавливать новый в каталог pykaldi/tools . Вместо этого вы можете просто установить следующие переменные среды, прежде чем запустить команду установки Pykaldi.
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > Хотя необходимость обновления ProtoBuf и CLIF не должна появляться очень часто, вы можете захотеть или необходимо обновлять установку Kaldi, используемую для построения Pykaldi. Объяснив соответствующий сценарий установки в каталоге tools должен обновить существующую установку. Если это не работает, откройте проблему.
Пакет Pykaldi tfrnnlm создан автоматически вместе с остальной частью Pykaldi, если библиотека kaldi-tensorflow-rnnlm может быть найдена среди библиотек Калди. После строительства Кальди перейдите в KALDI_DIR/src/tfrnnlm/ каталог и следуйте инструкциям, приведенным в Makefile. Убедитесь, что символическая связь для библиотеки kaldi-tensorflow-rnnlm добавлена в каталог KALDI_DIR/src/lib/ .
Shennong - набор инструментов для извлечения речевых функций, таких как MFCC, PLP и т. Д. Использование Pykaldi.
Сервер модели Kaldi - поточный сервер модели Kaldi для декодирования в прямом эфире. Может непосредственно декодировать речь из вашего микрофона с помощью NNET3, совместимой с моделью. Примеры модели для английского и немецкого языка доступны. Использует декодер Pykaldi Online2.
MeetingBot-Пример веб-приложения для соблюдения транскрипции и суммирования, в котором используется бэкэнд-сервер-сервер Pykaldi/Kaldi-Model для отображения вывода ASR в браузере.
Subtitle2go - Автоматическое генерация субтитров для любого медиа -файла. Использует Pykaldi для ASR с партийным декодером.
Если у вас есть крутой проект с открытым исходным кодом, который использует Pykaldi, который вы хотели бы продемонстрировать здесь, дайте нам знать!
Если вы используете Pykaldi для исследования, пожалуйста, укажите нашу статью следующим образом:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
Мы ценим все вклад! Если вы найдете ошибку, не стесняйтесь открыть проблему или запрос на тягу. Если вы хотите запросить или добавить новую функцию, откройте проблему для обсуждения.


