pykaldi
v0.2.2
Pykaldiは、Kaldi音声認識ツールキットのPythonスクリプト層です。 KaldiおよびOpenFstライブラリのC ++コードの使いやすい、低オーバーヘッドのファーストクラスのPythonラッパーを提供します。 Pykaldiを使用して、低レベルのKaldi関数の呼び出し、Kaldiの操作、CodeのOpenFstオブジェクトの操作、新しいKaldiツールの実装など、C ++コードを作成する必要があるもののPythonコードを作成できます。
カルディは、カスタム音声認識ソリューションを構築するためにミックスして一致させることができるレゴの大きな箱と考えることができます。 Pykaldiを考える最良の方法は、サプリメントとして、もしあなたがそうするならば、カルディへの相棒です。実際、PykaldiはKaldiと一緒に使用されると最高の状態です。そのために、Kaldiが提供する無数のコマンドラインツール、ユーティリティスクリプト、シェルレベルのレシピの機能を複製することは、Pykaldiプロジェクトの非ゴールです。
Kaldiと同様に、Pykaldiは主に音声認識研究者や専門家を対象としています。 KaldiおよびOpenFstライブラリが提供するユーティリティ、アルゴリズム、データ構造の膨大なコレクションを利用して、Pythonソフトウェアを構築するために必要なGoodiesが詰め込まれています。
FSTベースの音声認識に慣れていない場合、またはPythonでKaldiとOpenFstの内臓にアクセスすることに興味がないが、Pythonアプリケーションの一部として事前に訓練されたKaldiシステムを実行したい場合は、心配しないでください。 Pykaldiには、ほとんどのPythonプログラマーがアクセスできるはずのasr 、 alignment 、 segmentationなど、多くの高レベルアプリケーション指向モジュールが含まれています。
Pykaldiを研究に使用したり、高度なASRアプリケーションを構築したりすることに興味がある場合は、幸運です。 Pykaldiには、PythonのKaldiとOpenFstオブジェクトを読み、書き込み、検査、操作、または視覚化するために必要なすべてが付属しています。これには、KaldiおよびOpenFst C ++ライブラリのパブリックAPIの一部であるほとんどの機能と方法のPythonラッパーが含まれています。 Kaldiツールによって生成/消費されるファイルを読み取り/書きたい場合は、 utilパッケージのI/Oおよびテーブルユーティリティをチェックしてください。 Kaldi MatricesとVectorsを使用したい場合は、たとえばNumpy ndarraysに変換し、その逆にmatrixパッケージをチェックしてください。機能の抽出と変換にKaldiを使用する場合は、 feat 、 ivector 、 transformパッケージをご覧ください。 Kaldiツールによって生成/消費されたラティスまたはその他のFST構造を使用したい場合は、 fstext 、 lat 、 kwsパッケージをご覧ください。 Kaldiのガウス混合モデル、隠されたマルコフモデル、または音声決定ツリーへの低レベルのアクセスが必要な場合は、 gmm 、 sgmm2 、 hmm 、およびtreeパッケージをご覧ください。 Kaldi Neural Networkモデルへの低レベルのアクセスが必要な場合は、 nnet3 、 cudamatrix 、およびchainパッケージをご覧ください。 Kaldiでデコーダーと言語モデリングユーティリティを使用する場合は、 decoder 、 lm 、 rnnlm 、 tfrnnlmおよびonline2パッケージをご覧ください。
KaldiとPykaldiについてもっと知りたい興味のある読者は、次のリソースが役立つと思うかもしれません。
Pythonの自動音声認識(ASR)は間違いなくPykaldiの「キラーアプリ」であるため、Pykaldi APIの感触を得るためにいくつかのASRシナリオを調べます。 PykaldiはASRモデルをトレーニングするための高レベルのユーティリティを提供していないため、Kaldiレシピを使用してモデルをトレーニングするか、オンラインで入手可能な事前に訓練されたモデルを使用する必要があります。これがそうである理由は、単にKaldi C ++ライブラリに高レベルのASRトレーニングAPIがないためです。 Kaldi ASRモデルは、データの準備からトレーニングで使用される無数のKaldi実行可能ファイルのオーケストレーションまで、すべてを処理する複雑なシェルレベルのレシピを使用してトレーニングされています。これは設計によるものであり、将来的に変化する可能性は低いです。 Pykaldiは、Kaldi C ++ライブラリの低レベルASRトレーニングユーティリティのラッパーを提供しますが、基本的なビルディングブロックからPythonでASRトレーニングパイプラインを構築したくない限り、それらは本当に役に立ちません。 LEGOの類推を続けて、このタスクは、あなたが必要とするかもしれないレゴでいっぱいのトラックへのアクセスを与えられることに似ています。あなたが試してみるのに十分なほどクレイジーであれば、この段落にあなたを落胆させないでください。 Pykaldiの建設を開始する前に、それもMad Manの仕事だと思いました。
Pykaldi asrモジュールには、PythonでASRシステムを組み立てるのが簡単に死んでいるため、使いやすい高レベルのクラスが多数含まれています。物事を設定するために必要なボイラープレートコードを無視すると、PykaldiでASRを実行することは、次のコードのスニペットと同じくらい簡単です。
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ])この単純化された例では、最初にモデルfinal.mdl 、デコードグラフHCLG.fst 、およびシンボルテーブルwords.txtのパスを使用して、仮想認識者SomeRecognizerをインスタンス化します。 optsオブジェクトには、認識器の構成オプションが含まれています。次に、Kaldi Archive feats.arkに保存されている機能マトリックスを読み取るために、Pykaldi Table Reader SequentialMatrixReaderをインスタンス化します。最後に、機能マトリックスを反復し、1つずつデコードします。ここでは、各発話に最適なASR仮説を印刷するだけなので、出力辞書の"text" outにのみ興味があります。出力辞書には、最適な仮説のフレームレベルのアラインメントや、最も可能性の高い仮説を表す加重格子など、他の多くの有用なエントリが含まれていることに注意してください。確かに、すべてのASRパイプラインがこの例ほど単純であるわけではありませんが、それらはしばしば同じ全体的な構造を持っています。次のセクションでは、より複雑なASRパイプラインを実装するために上記のコードをどのように適応させるかを確認します。
これが最も一般的なシナリオです。 Aspireチェーンモデルなどの事前に訓練されたKaldiモデルを使用して、オフラインASRを実行したいと考えています。ここでは、「モデル」という用語を大まかに使用して、ASRシステムをまとめるために必要なすべてを参照しています。この具体的な例では、次のことが必要になります。
このサンプルコードを使用して、Aspireチェーンモデルでデコードできることに注意してください。
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ]この例と最後のセクションからの短いスニペットの根本的な違いは、各発言について、ディスクからの生のオーディオデータを読み取り、ディスクから単一の事前計算された特徴マトリックスを読み取る代わりに、その場で2つの機能マトリックスを計算していることです。スクリプトファイルwav.scpには、デコードする発言に対応するWAVファイルのリストが含まれています。抽出している追加の特徴マトリックスには、ニューラルネットワークアコースティックモデルがチャネルとスピーカーの適応を実行するために使用するオンラインIベクターが含まれています。スピーカーからスターのマップspk2utt 、オンラインのI-ベクトル抽出で各スピーカーの個別の統計を蓄積するために使用されます。スピーカー情報が利用できない場合は、簡単なIDマッピングになる可能性があります。 MFCC機能とivectorsをタプルに詰め込み、デコードのためにこのタプルを認識者に渡します。 Pykaldiのニューラルネットワーク認識者は、利用可能なときに追加のIベクトル機能を処理する方法を知っています。モデルファイルfinal.mdlは、遷移モデルとニューラルネットワークアコースティックモデルの両方が含まれています。 NnetLatticeFasterRecognizerプロセスは、ニューラルネットワークアコースティックモデルを使用して最初の携帯電話ログリケリフッドを計算することにより行列を機能させ、次にそれらをマッピングして、遷移モデルを使用してログリケリを遷移させ、最終的に遷移するログリケリをデコードするログリケリを単語シーケンスにデコードするグラフHCLG.fstを使用して単語シーケンスにデコードします。デコード後、将来の処理のために認識者によって生成された格子をKaldiアーカイブに保存します。
この例は、Kaldiが提供する強力なI/Oメカニズムも示しています。特徴抽出パイプラインをコードに実装する代わりに、それらをKaldiの読み取り指数として定義し、Pykaldiテーブルリーダーをインスタンス化してそれらを繰り返すだけで機能マトリックスを計算します。これは最も単純なものであるだけでなく、機能抽出パイプラインがオペレーティングシステムによって並行して実行されるため、Pykaldiを使用した最速のコンピューティング機能でもあります。同様に、Kaldi Write仕様を使用して、圧縮されたKaldiアーカイブに出力格子を書き込むPykaldi Table Writerをインスタンス化します。これらが機能するには、 compute-mfcc-feats 、 ivector-extract-online2 、およびgzip私たちのPATHにいる必要があることに注意してください。
これは以前のシナリオに似ていますが、Kaldi音響モデルの代わりに、Pytorch Acoustic Modelを使用します。以前と同じように機能を計算した後、それらをPytorchテンソルに変換し、Pytorch Neural Networkモジュールを使用してフォワードパスを実行し、電話ログの視線を出力し、最後にそれらの対数尤度をPykaldi Matrixに戻します。承認者は、遷移モデルを使用して、電話IDを自動的にマッピングして、典型的なKaldiデコードグラフで入力ラベルを遷移させます。
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]このセクションはプレースホルダーです。その間にこのスクリプトをチェックしてください。
Lattice Rescoringは、ASRで大規模なN-GRAM言語モデルまたは再発性ニューラルネットワーク言語モデル(RNNLM)を使用するための標準的な手法です。この例では、Kaldi rnnlmを使用して格子をscoporeします。最初に、モデルのパスを提供することにより、レスカーを即座にインスタンス化します。次に、テーブルリーダーを使用して、レスコアをしたい格子を反復し、最後にテーブルライターを使用して、救助された格子をディスクに書き戻します。
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat )単語の特徴とその場での機能の埋め込みから埋め込みという単語を計算するために使用した拡張されたファイル名に注意してください。また、格子アーカイブを透過的に減圧/圧縮するために使用した読み取り/書き込み指定器も注目しています。これらが機能するには、 rnnlm-get-word-embedding 、 gunzip 、 gzip私たちのPATHを進む必要があります。
Pykaldiは、KaldiとPythonが提供するすべての素晴らしいものとの間のギャップを埋めることを目指しています。 Kaldiライブラリへのバインディングのコレクション以上のものです。これは、PythonのEssential KaldiとOpenFstタイプのファーストクラスのサポートを提供するスクリプト層です。 Pykaldi VectorおよびMatrixタイプは、Numpyと密接に統合されています。それらは、下にあるメモリバッファーをコピーせずに、シームレスにnumpyアレイに変換することができ、その逆も同様です。 Kaldiスタイルの格子を含むPykaldi FSTタイプは、Pythonのファーストクラスの市民です。 FSTタイプと操作に直面しているユーザーのAPIは、OpenFSTの公式PythonラッパーであるPyWrapfstによって公開されたAPIを模倣するPythonでほぼ完全に定義されています。
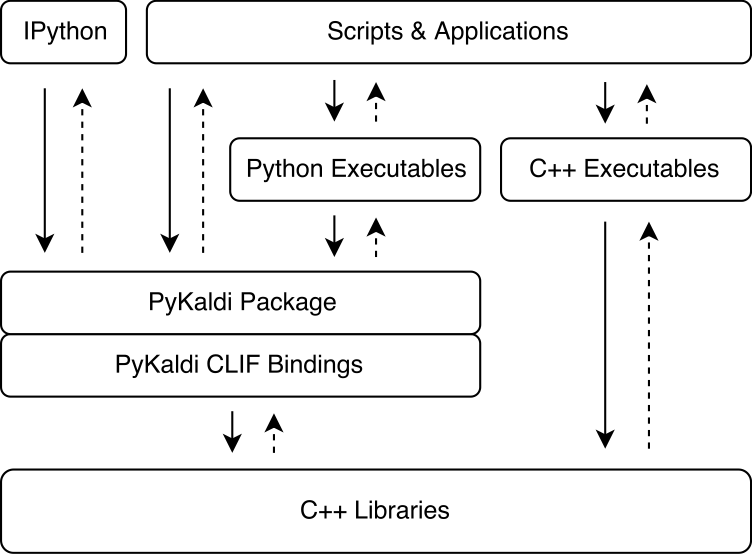
Pykaldiは、単純なAPI説明を使用して、KaldiとOpenfst C ++ライブラリをラップするClifの力を活用しています。 CLIFによって生成されたCPYTHON拡張モジュールをPythonにインポートして、KaldiおよびOpenFstと対話できます。 ClifはPythonで既存のC ++ APIを公開するのに最適ですが、ラッパーはPythonから使いやすい「Pythonic」APIを常に露出するとは限りません。 Pykaldiは、Python(およびC ++)に生のClifラッパーを拡張して、より「Pythonic」APIを提供することにより、これに対処します。下の図は、PykaldiがKaldiエコシステムのどこにあるかを示しています。
Pykaldiには、メンテナンスと拡張が容易になるモジュール設計があります。ソースファイルは、Kaldiソースツリーのレプリカであるディレクトリツリーに編成されています。各ディレクトリはサブパッケージを定義し、関連するKaldiライブラリ用に記述されたラッパーコードのみが含まれています。ラッパーコードは次のとおりです。
clif c ++ api説明包装するタイプと関数とそのpython apiを定義する、
Clifが期待するGoogle C ++スタイルに準拠していないKaldiコードのシムを定義するC ++ヘッダー、
Pythonモジュールは、CLIFで生成された関連する拡張モジュールをグループ化し、生のCLIFラッパーを拡張して、より「Pythonic」APIを提供します。
私たちの論文で、Pykaldiのデザインと技術的な詳細の詳細を読むことができます。
次の表は、次の次の次元に沿って、各Pykaldiパッケージのステータス(現在はNNET、NNET2、およびオンラインのサポートを追加する予定はありません)を示しています。
| パッケージ | 包まれていますか? | Pythonic? | ドキュメント? | テスト? |
|---|---|---|---|---|
| ベース | ✔ | ✔ | ✔✔✔ | ✔ |
| 鎖 | ✔ | ✔ | ✔✔✔ | |
| Cudamatrix | ✔ | ✔ | ✔ | |
| デコーダ | ✔ | ✔ | ✔✔✔ | |
| 偉業 | ✔ | ✔ | ✔✔✔ | |
| fstext | ✔ | ✔ | ✔✔✔ | |
| gmm | ✔ | ✔ | ✔✔ | ✔ |
| ふーむ | ✔ | ✔ | ✔✔✔ | ✔ |
| アイベクトル | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔✔✔ | |
| ラット | ✔ | ✔ | ✔✔✔ | |
| lm | ✔ | ✔ | ✔✔✔ | |
| マトリックス | ✔ | ✔ | ✔✔✔ | ✔ |
| NNET3 | ✔ | ✔ | ✔ | |
| オンライン2 | ✔ | ✔ | ✔✔✔ | |
| rnnlm | ✔ | ✔ | ✔✔✔ | |
| SGMM2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔✔✔ | |
| 変身 | ✔ | ✔ | ✔ | |
| 木 | ✔ | ✔ | ||
| 活動 | ✔ | ✔ | ✔✔✔ | ✔ |
ubuntu> = 16.04、centos> = 7、またはmacos> = 10.13などの比較的最近のLinuxまたはmacosを使用している場合、あまり問題なくPykaldiをインストールできるはずです。それ以外の場合は、インストールスクリプトを調整する必要がある可能性があります。
GitHubリリースページから公式WHLパッケージをダウンロードできるようになりました。 Python 3.7、3.8、...、Linuxの3.11のWHLパッケージと、Mac M1/M2用のいくつかの(実験的)ビルドがあります。
WHLパッケージを使用する場合は、次のセクションをスキップして、「Pykaldi WHLパッケージを使用して新しいプロジェクトを開始する」ためにプロジェクトをセットアップすることができます。 KaldiのPykaldi互換バージョンをコンパイルする必要があることに注意してください。
ソースからPykaldiをインストールして構築するには、以下の手順に従ってください。
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldi必須ではありませんが、新しい孤立したPython環境内にPykaldiとそのすべてのPython依存関係をインストールすることをお勧めします。新しいPython環境を作成したくない場合は、このステップの残りをスキップできます。
新しいPython環境を作成するために、好きなツールを使用できます。ここではvirtualenvを使用しますが、それを好む場合は、 condaのような別のツールを使用できます。残りのインストールを続行する前に、新しいPython環境をアクティブにしてください。
virtualenv env
source env/bin/activate以下のコマンドを実行すると、Pykaldiをソースから構築するために必要なシステムパッケージがインストールされます。
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "以下のコマンドを実行すると、Pykaldiをソースから構築するために必要なPythonパッケージがインストールされます。
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommended上記のパッケージに加えて、次のソフトウェアのPykaldi互換性のあるインストールも必要です。
Google Protobuf、推奨v3.5.0。 C ++ライブラリとPythonパッケージの両方をインストールする必要があります。
クリフのピカルディ互換フォーク。 Pykaldi開発を合理化するために、Clif CodeBaseにいくつかの変更を加えました。これらの変更は、時間の経過とともに上流になることを望んでいます。これらの変更は、Pykaldiブランチにあります。
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi tools Directoryのスクリプトを使用して、これらのソフトウェアをローカルにインストールまたは更新できます。これらのスクリプトの出力を確認してください。 Done installing {protobuf,CLIF,Kaldi}いない場合、何らかの理由でインストールが失敗したことを意味します。
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..注意してください、あなたがApple SilicionでKaldiをコンパイルし、./install_kaldi.shがSCTKを編集する最初のコンパイルで立ち往生している場合、例えば、このようなラインでそれを容認することにより、Tools/kaldi/tools/makefileから-march = native =ネイティブを削除する必要があるかもしれません。
SCTK_CXFLAGS = -w # -march=native Kaldiがtools Directory内にインストールされ、すべてのPython依存関係(Numpy、Pyparsing、Pyclif、Protobuf)がアクティブなPython環境にインストールされている場合、次のコマンドでPykaldiをインストールできます。
python setup.py installインストールしたら、次のコマンドでPykaldiテストを実行できます。
python setup.py testその後、WHLパッケージを作成することもできます。 WHLパッケージを使用すると、スピーチプロジェクトのためにPykaldiを新しいプロジェクト環境に簡単にインストールできます。
python setup.py bdist_wheelWHLファイルは、「DIST」フォルダーにあります。 WHLファイル名は、Pykaldiバージョン、Pythonバージョン、アーキテクチャに依存します。 Pykaldi 0.2.2を使用してx86_64にビルドするPython 3.9の場合:dist/pykaldi-0.2.2-cp39-cp39-linux_x86_64.whlのように見える場合があります
たとえば、新しいプロジェクトフォルダーを作成します。
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRPython 2.9の場合、WHLパッケージと同じPythonバージョンを使用して仮想環境を作成およびアクティブにします。
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activatenumpyとpykaldiをmyasr環境にインストールします。
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl pykaldi/tools/install_kaldi.shをmyASRプロジェクトにコピーします。 install_kaldi.shスクリプトを使用して、プロジェクト用にpykaldi互換性のあるKaldiバージョンをインストールします。
./install_kaldi.shPykaldi/Tools/Path.shをプロジェクトにコピーします。 Path.shは、PykaldiにKaldiフォルダーのKaldiライブラリとバイナリを見つけさせるために使用されます。ソースパス。
. path.shおめでとうございます、あなたはあなたのプロジェクトでPykaldiを使用する準備ができています!
注:新しいシェルを開くときはいつでも、プロジェクト環境とpath.shを調達する必要があります。
. myasr_env/bin/activate
. path.sh注:残念ながら、Pykaldi Condaパッケージは時代遅れです。あなたがそれを維持したいなら、私たちに連絡してください。
CUDAサポートでPykaldiをインストールするには:
conda install -c pykaldi pykaldiCUDAサポートなしでPykaldiをインストールするには(CPUのみ):
conda install -c pykaldi pykaldi-cpuPykaldi CondaパッケージはKaldi実行可能ファイルを提供していないことに注意してください。 Pykaldiと一緒にKaldi実行可能ファイルを使用したい場合は、読み取り/書き込み指定器の一部として、Kaldiを個別にインストールする必要があります。
注:以下のDockerの指示は時代遅れになる場合があります。 PykaldiのDocker画像を維持したい場合は、ご連絡ください。
Dockerコンテナ内でPykaldiを使用したい場合は、 dockerフォルダーの指示に従ってください。
デフォルトでは、Pykaldi Installコマンドは、利用可能なすべての(論理)プロセッサを使用してビルドプロセスを加速します。プロセッサの数と比較してシステムメモリのサイズが比較的小さい場合、並列コンピレーション/リンクジョブは、システムメモリを使い果たしてスワッピングする可能性があります。次のように、Pykaldiの構築に使用される並列ジョブの数を制限できます。
MAKE_NUM_JOBS=2 python setup.py installWindowsでPykaldiを構築するために何が必要かわからない。おそらく、ビルドシステムに多くの変更が必要です。
現時点では、Pykaldiは上流のKaldiリポジトリと互換性がありません。 Kaldi Forkに対してそれを構築する必要があります。
システムに互換性のあるKaldiインストールが既にある場合は、 pykaldi/toolsディレクトリ内に新しいインストールをインストールする必要はありません。代わりに、Pykaldiインストールコマンドを実行する前に、次の環境変数を単に設定できます。
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >現時点では、Pykaldiは上流のCLIFリポジトリと互換性がありません。 CLIFフォークを使用して構築する必要があります。
システムに互換性のあるCLIFインストールが既にある場合は、 pykaldi/toolsディレクトリ内に新しいインストールをインストールする必要はありません。代わりに、Pykaldiインストールコマンドを実行する前に、次の環境変数を設定するだけです。
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > ProtobufとClifを更新する必要性はあまり頻繁に登場しないはずですが、Pykaldiの構築に使用されるKaldiのインストールを必要とするか、更新する必要があるかもしれません。 toolsディレクトリの関連するインストールスクリプトを再実行すると、既存のインストールを更新する必要があります。これが機能しない場合は、問題を開いてください。
kaldi-tensorflow-rnnlmライブラリがKaldiライブラリの中にある場合、Pykaldi tfrnnlmパッケージはPykaldiの残りの部分とともに自動的に構築されます。 Kaldiを構築した後、 KALDI_DIR/src/tfrnnlm/ディレクトリにアクセスして、MakeFileで与えられた指示に従ってください。 kaldi-tensorflow-rnnlmライブラリのシンボリックリンクがKALDI_DIR/src/lib/ディレクトリに追加されていることを確認してください。
Shennong- Pykaldiを使用したMFCC、PLPなどの音声機能抽出用のツールボックス。
Kaldi Model Server-ライブデコード用のスレッドKaldiモデルサーバー。 NNET3互換モデルを使用して、マイクから音声を直接デコードできます。英語とドイツ語の例モデルが利用可能です。 Pykaldi Online2デコーダーを使用します。
MeetingBot-Pykaldi/Kaldi-Model-Serverバックエンドを使用してブラウザにASR出力を表示する転写と要約を満たすためのWebアプリケーションの例。
subtitle2go-メディアファイルの自動サブタイトル生成。バッチデコーダーを使用してASRにPykaldiを使用します。
ここで紹介したいPykaldiを利用するクールなオープンソースプロジェクトがある場合は、お知らせください!
Pykaldiを調査に使用する場合は、次のように論文を引用してください。
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
すべての貢献に感謝します!バグが見つかった場合は、お気軽に問題やプルリクエストを開いてください。新しい機能をリクエストまたは追加したい場合は、議論のために問題を開いてください。


