pykaldi
v0.2.2
Pykaldi ist eine Python -Skriptschicht für das Kaldi -Spracherkennungs -Toolkit. Es bietet einfach zu bedienende, erstklassige Python-Wrapper für den C ++-Code in Kaldi und OpenFST-Bibliotheken. Sie können Pykaldi verwenden, um Python-Code für Dinge zu schreiben, für die sonst das Schreiben von C ++-Code wie Kaldi-Funktionen auf niedrigem Niveau, die Manipulation von Kaldi und OpenFST-Objekten in Code oder die Implementierung neuer Kaldi-Tools erforderlich wäre.
Sie können sich Kaldi als eine große Schachtel Legos vorstellen, die Sie mischen und anpassen können, um benutzerdefinierte Spracherkennungslösungen zu erstellen. Der beste Weg, um Pykaldi zu denken, ist als Ergänzung, ein Kumpel, wenn Sie so wollen, zu Kaldi. Tatsächlich ist Pykaldi am besten, wenn es neben Kaldi verwendet wird. Zu diesem Zweck ist die Replikation der Funktionalität unzähliger Befehlszeilen-Tools, Versorgungsskripte und von Kaldi bereitgestellten Rezepten auf Shell-Ebene ein Nichtgänger für das Pykaldi-Projekt.
Pykaldi ist wie Kaldi in erster Linie für Forscher und Fachkräfte von Spracherkennung bestimmt. Es ist voll mit Leckereien, die man müsste, um die Python -Software zu erstellen, die die enorme Sammlung von Dienstprogrammen, Algorithmen und Datenstrukturen von Kaldi und OpenFST -Bibliotheken ausnutzt.
Wenn Sie mit der FST-basierten Spracherkennung nicht vertraut sind oder kein Interesse daran haben, Zugang zu den Eingeweiden von Kaldi und OpenFST in Python zu haben, sondern nur ein vorgebildetes Kaldi-System als Teil Ihrer Python-Anwendung ausführen möchten, ärgern Sie sich nicht. Pykaldi umfasst eine Reihe von anwendungsorientierten hochrangigen Modulen wie asr , alignment und segmentation , die den meisten Python-Programmierern zugänglich sein sollten.
Wenn Sie daran interessiert sind, Pykaldi für die Forschung oder den Aufbau fortschrittlicher ASR -Anwendungen zu verwenden, haben Sie Glück. Pykaldi kommt mit allem, was Sie benötigen, um Kaldi und OpenFST -Objekte in Python zu lesen, zu schreiben, zu inspizieren, zu manipulieren oder zu visualisieren. Es enthält Python -Wrapper für die meisten Funktionen und Methoden, die Teil der öffentlichen APIs von Kaldi und OpenFST -C ++ -Bibliotheken sind. Wenn Sie Dateien lesen/schreiben möchten, die von Kaldi -Tools produziert/konsumiert werden, lesen Sie die E/A- und Tabellen -Dienstprogramme im util -Paket. Wenn Sie mit Kaldi -Matrizen und Vektoren zusammenarbeiten möchten, wandeln Sie sie z. B. in Numpy NDarrays um und umgekehrt, finden Sie das matrix -Paket. Wenn Sie KALDI für die Feature -Extraktion und -Transformation verwenden möchten, lesen Sie die Pakete von feat , ivector und transform . Wenn Sie mit Gitter oder anderen FST -Strukturen arbeiten möchten, die von Kaldi -Tools erzeugt/konsumiert werden, lesen Sie die Pakete fstext , lat und kws . Wenn Sie auf niedrigem Niveau Zugang zu Gaußschen Mischmodellen, versteckten Markov-Modellen oder phonetischen Entscheidungsbäumen in Kaldi wünschen, lesen Sie die Pakete gmm , sgmm2 , hmm und tree . Wenn Sie auf niedrigem Niveau Zugriff auf Kaldi-Modelle für neuronale Netzwerke möchten, lesen Sie die Pakete nnet3 , cudamatrix und chain . Wenn Sie die Decoder- und Sprachmodellierungs -Dienstprogramme in Kaldi verwenden möchten, lesen Sie die Pakete decoder , lm , rnnlm , tfrnnlm und online2 .
Interessierte Leser, die mehr über Kaldi und Pykaldi erfahren möchten, können die folgenden Ressourcen nützlich finden:
Da die automatische Spracherkennung (ASR) in Python zweifellos die "Killer -App" für Pykaldi ist, werden wir ein paar ASR -Szenarien durchgehen, um ein Gefühl für die Pykaldi -API zu bekommen. Wir sollten beachten, dass Pykaldi keine hochrangigen Versorgungsunternehmen für Schulungs-ASR-Modelle bereitstellt. Sie müssen Ihre Modelle daher mit Kaldi-Rezepten trainieren oder online verfügbare Modelle verwenden. Der Grund, warum dies so ist, dass es in Kaldi C ++-Bibliotheken keine ASR-Trainings-API auf hoher Ebene gibt. Kaldi-ASR-Modelle werden unter Verwendung komplexer Rezepte auf Shell-Ebene geschult, die alles von der Datenvorbereitung bis zur Orchestrierung von unzähligen Kaldi-ausführbaren Kaldi-ausführbaren Ausführungen verarbeiten. Dies ist entworfen und es ist unwahrscheinlich, dass sie sich in Zukunft nicht ändern wird. Pykaldi stellt Wrapper für die Low-Level-ASR-Trainingsversorgungsunternehmen in Kaldi C ++-Bibliotheken zur Verfügung. Diese sind jedoch nicht wirklich nützlich, es sei denn, Sie möchten eine ASR-Trainingspipeline in Python aus grundlegenden Bausteinen erstellen, was keine leichte Aufgabe ist. Mit der LEGO -Analogie ist diese Aufgabe mit dem Aufbau dieses gegebenen Zugangs zu einem LKW voller Legos vergleichbar. Wenn Sie jedoch verrückt genug sind, um es zu versuchen, lassen Sie sich von diesem Absatz nicht entmutigen. Bevor wir anfingen, Pykaldi zu bauen, dachten wir, das sei auch die Aufgabe eines verrückten Mannes.
Das Pykaldi- asr -Modul enthält eine Reihe benutzerfreundlicher, hochrangiger Klassen, um es einfach zu machen, ASR-Systeme in Python zusammenzustellen. Das Ignorieren des Boilerplate -Code, der für die Einrichtung der Dinge benötigt wird, kann ASR mit Pykaldi so einfach sein wie der folgende Codeausschnitt:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) In diesem vereinfachten Beispiel instanziieren wir zuerst einen hypothetischen Erkenner SomeRecognizer mit den Pfaden für das Modell final.mdl , das Decodierungsgraf HCLG.fst und das Symbol words.txt . Das opts -Objekt enthält die Konfigurationsoptionen für den Erkenner. Anschließend instanziieren wir einen Pykaldi -Tabellenleser SequentialMatrixReader für das Lesen der Feature -Matrizen, die im Kaldi Archive feats.ark gespeichert sind. Schließlich iterieren wir die Feature -Matrizen und dekodieren sie einzeln. Hier drucken wir einfach die beste ASR -Hypothese für jede Äußerung, sodass wir nur an dem "text" -Intertrag des out ausgerichtet sind. Denken Sie daran, dass das Ausgabewörterbuch eine Reihe anderer nützlicher Einträge enthält, wie die Ausrichtung der Rahmenebene der besten Hypothese und ein gewichtetes Gitter, das die wahrscheinlichsten Hypothesen darstellt. Zugegeben, nicht alle ASR -Pipelines sind so einfach wie dieses Beispiel, aber sie haben oft die gleiche Gesamtstruktur. In den folgenden Abschnitten werden wir sehen, wie wir den oben angegebenen Code anpassen können, um kompliziertere ASR -Pipelines zu implementieren.
Dies ist das häufigste Szenario. Wir möchten ASR offline verwenden, indem wir vorgeborene Kaldi-Modelle wie Aspire-Kettenmodelle verwenden. Hier verwenden wir den Begriff "Modelle" lose, um sich auf alles zu beziehen, was man braucht, um ein ASR -System zusammenzustellen. In diesem speziellen Beispiel werden wir brauchen:
Beachten Sie, dass Sie diesen Beispielcode verwenden können, um mit Aspire -Kettenmodellen zu dekodieren.
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] Der grundlegende Unterschied zwischen diesem Beispiel und dem kurzen Ausschnitt aus dem letzten Abschnitt besteht darin, dass wir für jede Äußerung die RAW -Audiodaten aus der Festplatte lesen und zwei Feature -Matrizen im Fliegen berechnen, anstatt eine einzelne vorbereitete Merkmalsmatrix von der Festplatte zu lesen. Die Skriptdatei wav.scp enthält eine Liste von WAV -Dateien, die den Äußerungen entsprechen, die wir dekodieren möchten. Die zusätzliche Feature-Matrix, die wir extrahieren, enthält Online-I-Vektoren, die vom akustischen Modell des neuronalen Netzwerks zur Durchführung von Kanal- und Lautsprecheranpassungen verwendet werden. Die Lautsprecher-zum-Schnitt-Karte spk2utt wird verwendet, um separate Statistiken für jeden Lautsprecher in der Online-I-Vektor-Extraktion zu sammeln. Es kann eine einfache Identitätszuordnung sein, wenn die Lautsprecherinformationen nicht verfügbar sind. Wir packen die MFCC-Funktionen und die I-Vektoren in ein Tupel und geben dieses Tupel zum Dekodieren an den Erkenntnis. Die Erkenntnisse des neuronalen Netzwerks in Pykaldi wissen, wie man mit den zusätzlichen I-Vektor-Funktionen umgeht, wenn sie verfügbar sind. Die Modelldatei final.mdl enthält sowohl das Übergangsmodell als auch das akustische Netzwerkmodell. Die NnetLatticeFasterRecognizer -Prozesse haben Matrizen mit dem Akustikmodell für Telefonprotokoll-Likelihoods zuerst mit dem akustischen Modell des neuronalen Netzwerks und dem Zuordnen der Übergangsprotokoll-Likelihoods mithilfe des Übergangsmodells und schließlich dekodieren von Übergangsprotokoll-Likelihoods mit den Decoding-Graph- HCLG.fst , die auf den Übergangs-Log-Likelihoods auf den Eingabetiden auf den Eingabetiden und mit den Word-IDs auf dem Labeln der Grapheins und der Word-IDs auf dem Labeln und der Words-IDS-IDS-Labeln entschlüsseln. Nach dem Dekodieren speichern wir das vom Erkenntnis erzeugte Gitter in einem Kaldi -Archiv für die zukünftige Verarbeitung.
Dieses Beispiel zeigt auch die leistungsstarken E/A -Mechanismen von Kaldi. Anstatt die Feature -Extraktionspipelines in Code zu implementieren, definieren wir sie als Kaldi -Lesespezifizierer und berechnen die Feature -Matrizen einfach, indem sie die Leser von Pykaldi -Tabellen und Iteration über sie instanziieren. Dies ist nicht nur die einfachste, sondern auch die schnellste Art, Funktionen mit Pykaldi zu berechnen, da die Feature -Extraktionspipeline vom Betriebssystem parallel ausgeführt wird. In ähnlicher Weise verwenden wir einen Kaldi -Schreibspezifizierer, um einen Pykaldi -Tabellenautor zu instanziieren, der Ausgabegitter in ein komprimiertes Kaldi -Archiv schreibt. Beachten Sie, dass wir für die Funktionsweise compute-mfcc-feats , ivector-extract-online2 und gzip benötigen, um auf unserem PATH zu sein.
Dies ähnelt dem vorherigen Szenario, aber anstelle eines Kaldi -Akustikmodells verwenden wir ein Pytorch -Akustikmodell. Nachdem wir die Funktionen wie zuvor berechnet haben, konvertieren wir sie in einen Pytorch-Tensor, führen Sie den Vorwärtspass mit einem Pytorch-Netzwerkmodul aus, das Telefon-Protokoll-Likelihoods ausgibt und schließlich diese Log-Likelihoods zurück in eine Pykaldi-Matrix für Decoding umwandelt. Der Erkenntnis verwendet das Übergangsmodell, um Telefon -IDs automatisch zu Übergangs -IDs zu kartieren.
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]Dieser Abschnitt ist ein Platzhalter. Schauen Sie sich dieses Skript in der Zwischenzeit an.
Die Rescaring von Gitter ist eine Standardtechnik zur Verwendung großer N-Gramm-Sprachmodelle oder rezidivierender neuronaler Netzwerksprachmodelle (RNNLMs) in ASR. In diesem Beispiel werden Gitter mit einem Kaldi RNNLM erörtert. Wir instanziieren zuerst einen Retter, indem wir die Pfade für die Modelle bereitstellen. Dann verwenden wir einen Tischleser, um über die Gitter zu iterieren, die wir erneuern möchten, und schließlich verwenden wir einen Tischschreiber, um erdete Lattices zurück auf die Festplatte zu schreiben.
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) Beachten Sie den erweiterten Dateinamen, mit dem wir das Wort einbetteten, aus den Wortmerkmalen und den Einbettungsdings im laufenden Fliegen. Bemerkenswert sind auch die Lese-/Schreibspezifizierer, mit denen wir die Gitterarchive transparent entkomprimieren/komprimieren. Damit diese funktionieren, brauchen wir rnnlm-get-word-embedding , gunzip und gzip um auf unserem PATH zu sein.
Pykaldi zielt darauf ab, die Kluft zwischen Kaldi und all den schönen Dingen zu schließen, die Python zu bieten hat. Es ist mehr als eine Sammlung von Bindungen in Kaldi -Bibliotheken. Es handelt sich um eine Skriptschicht, die erstklassige Unterstützung für essentielle Kaldi- und OpenFST -Typen in Python bietet. Pykaldi -Vektor- und Matrixtypen sind eng in Numpy integriert. Sie können nahtlos in Numpy -Arrays umgewandelt werden und umgekehrt, ohne die zugrunde liegenden Speicherpuffer zu kopieren. Pykaldi -FST -Typen, einschließlich Gitter im Kaldi -Stil, sind erstklassige Bürger in Python. Die API für den Benutzer, der FST -Typen und -Operationen ausgesetzt ist, ist in Python fast vollständig definiert, in dem die API von PyWrapfst, dem offiziellen Python -Wrapper für OpenFST, ausgesetzt ist.
Pykaldi nutzt die Kraft von CLIF, um Kaldi und OpenFST -C ++ -Bibliotheken mit einfachen API -Beschreibungen einzuwickeln. Die von CLIF erzeugten CPython -Erweiterungsmodule können in Python importiert werden, um mit Kaldi und OpenFST zu interagieren. Während CLIF ideal für die Enthüllung der vorhandenen C ++ - API in Python ist, enthüllen die Wrapper nicht immer eine "pythonische" API, die von Python einfach zu bedienen ist. Pykaldi spricht dies an, indem es die rohen Clif -Wrapper in Python (und manchmal in C ++) erweitert, um eine "pythonischer" -API zu liefern. Die folgende Abbildung zeigt, wo Pykaldi in das Kaldi -Ökosystem passt.
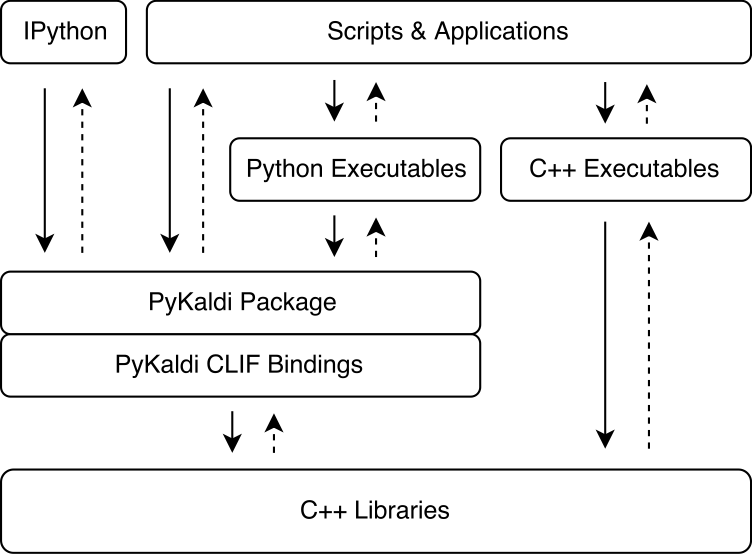
Pykaldi hat ein modulares Design, das es einfach macht, aufrechtzuerhalten und zu erweitern. Quelldateien werden in einem Verzeichnisbaum organisiert, der eine Nachbildung des Kaldi -Quellbaums ist. Jedes Verzeichnis definiert ein Unterpackung und enthält nur den für die zugehörigen Kaldi -Bibliothek geschriebenen Wrapper -Code. Der Wrapper -Code besteht aus:
CLIF C ++ API -Beschreibungen, die die zugewickelten Typen und Funktionen und ihre Python -API definieren.
C ++ - Header, die die SHIMS für Kaldi -Code definieren, die nicht mit dem von CLIF erwarteten Google C ++ - Stil entspricht,
Python -Module gruppieren verwandte Erweiterungsmodule, die mit CLIF erzeugt wurden, und erweitern die rohen Clif -Wrapper, um eine "pythonischer" -API zu liefern.
Weitere Informationen zum Design und den technischen Details von Pykaldi in unserer Zeitung finden Sie in unserer Zeitung.
Die folgende Tabelle zeigt den Status jedes Pykaldi -Pakets (wir planen derzeit nicht, Unterstützung für NNET, Nnet2 und Online) entlang der folgenden Abmessungen zu unterstützen:
| Paket | Verpackt? | Pythonisch? | Dokumentation? | Tests? |
|---|---|---|---|---|
| Base | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| Kette | ✔ | ✔ | ✔ ✔ ✔ | |
| Cudamatrix | ✔ | ✔ | ✔ | |
| Decoder | ✔ | ✔ | ✔ ✔ ✔ | |
| feat | ✔ | ✔ | ✔ ✔ ✔ | |
| fStext | ✔ | ✔ | ✔ ✔ ✔ | |
| GMM | ✔ | ✔ | ✔ ✔ | ✔ |
| Hmm | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| Ifektor | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔ ✔ ✔ | |
| Lat | ✔ | ✔ | ✔ ✔ ✔ | |
| lm | ✔ | ✔ | ✔ ✔ ✔ | |
| Matrix | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| Nnet3 | ✔ | ✔ | ✔ | |
| Online2 | ✔ | ✔ | ✔ ✔ ✔ | |
| rnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| SGMM2 | ✔ | ✔ | ||
| tFrnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| verwandeln | ✔ | ✔ | ✔ | |
| Baum | ✔ | ✔ | ||
| Util | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
Wenn Sie ein relativ neues Linux oder MacOS verwenden, wie Ubuntu> = 16.04, CentOS> = 7 oder macOS> = 10.13, sollten Sie in der Lage sein, Pykaldi ohne zu viel Mühe zu installieren. Andernfalls müssen Sie die Installationsskripte wahrscheinlich optimieren.
Sie können jetzt offizielle WHL -Pakete von unserer GitHub -Release -Seite herunterladen. Wir haben WHL -Pakete für Python 3.7, 3.8, ..., 3.11 unter Linux und einige (experimentelle) Builds für Mac M1/M2.
Wenn Sie sich für ein WHL -Paket entscheiden, können Sie die nächsten Abschnitte überspringen und direkt zum Starten eines neuen Projekts mit einem Pykaldi -WHL -Paket gehen, um Ihr Projekt einzurichten. Beachten Sie, dass Sie noch eine Pykaldi-kompatible Version von Kaldi kompilieren müssen.
Befolgen Sie die unten angegebenen Schritte, um Pykaldi aus der Quelle zu installieren und zu bauen.
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldiObwohl dies nicht erforderlich ist, empfehlen wir, Pykaldi und alle seine Python -Abhängigkeiten in einer neuen isolierten Python -Umgebung zu installieren. Wenn Sie keine neue Python -Umgebung erstellen möchten, können Sie den Rest dieses Schritts überspringen.
Sie können jedes Tool verwenden, das Sie möchten, um eine neue Python -Umgebung zu erstellen. Hier verwenden wir virtualenv , aber Sie können ein anderes Tool wie conda verwenden, wenn Sie dies bevorzugen. Stellen Sie sicher, dass Sie die neue Python -Umgebung aktivieren, bevor Sie den Rest der Installation fortsetzen.
virtualenv env
source env/bin/activateDurch Ausführen der folgenden Befehle werden die Systempakete installiert, die zum Erstellen von Pykaldi aus der Quelle benötigt werden.
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "Durch Ausführen der folgenden Befehle werden die Python -Pakete installiert, die für den Bau von Pykaldi aus der Quelle benötigt werden.
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommendedZusätzlich zu oben aufgeführten Paketen benötigen wir auch Pykaldi -kompatible Installationen der folgenden Software:
Google Protobuf, empfohlen V3.5.0. Sowohl die C ++ - Bibliothek als auch das Python -Paket müssen installiert werden.
Pykaldi kompatible Gabel von Clif. Um die Entwicklung von Pykaldi zu optimieren, haben wir einige Änderungen an der CLIF -Codebasis vorgenommen. Wir hoffen, diese Veränderungen im Laufe der Zeit zu verbreiten. Diese Veränderungen befinden sich im Pykaldi -Zweig:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi Sie können die Skripte im tools -Verzeichnis verwenden, um diese Software lokal zu installieren oder zu aktualisieren. Stellen Sie sicher, dass Sie die Ausgabe dieser Skripte überprüfen. Wenn Sie nicht Done installing {protobuf,CLIF,Kaldi} am Ende sehen, bedeutet dies, dass die Installation aus irgendeinem Grund fehlgeschlagen ist.
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..Beachten Sie, wenn Sie Kaldi auf Apple Silicion und ./install_kaldi.sh kompilieren, bleibt Sie am Anfang an den SCTK -Kompilieren. Möglicherweise müssen Sie -march = nativ aus Tools/Kaldi/Tools/Makefile entfernen, z.
SCTK_CXFLAGS = -w # -march=native Wenn Kaldi im tools -Verzeichnis installiert ist und alle Python -Abhängigkeiten (Numpy, Pyparsing, Pyclif, Protobuf) in der aktiven Python -Umgebung installiert sind, können Sie Pykaldi mit dem folgenden Befehl installieren.
python setup.py installNach der Installation können Sie Pykaldi -Tests mit dem folgenden Befehl ausführen.
python setup.py testSie können dann auch ein WHL -Paket erstellen. Das WHL -Paket erleichtert es einfach, Pykaldi in eine neue Projektumgebung für Ihr Sprachprojekt zu installieren.
python setup.py bdist_wheelDie WHL -Datei kann dann im Ordner "dist" gefunden werden. Der WHL -Dateiname hängt von der Pykaldi -Version, Ihrer Python -Version und Ihrer Architektur ab. Für einen Python 3.9 bauen Sie auf x86_64 mit Pykaldi 0.2.2 auf: Dist/Pykaldi-0.2.2-CP39-CP39-linux_x86_64.whl
Erstellen Sie zum Beispiel einen neuen Projektordner:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRErstellen und aktivieren Sie eine virtuelle Umgebung mit derselben Python -Version wie das WHL -Paket, z. B. für Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateInstallieren Sie Numpy und Pykaldi in Ihrer Myasr -Umgebung:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl Kopieren Sie Pykaldi/Tools/install_kaldi.sh in Ihr Myasr -Projekt. Verwenden Sie das Skript install_kaldi.sh, um eine Pykaldi -kompatible Kaldi -Version für Ihr Projekt zu installieren:
./install_kaldi.shKopieren Sie Pykaldi/Tools/Path.sh in Ihr Projekt. Path.sh wird verwendet, damit Pykaldi die Kaldi -Bibliotheken und Binärdateien im Kaldi -Ordner finden kann. Source Path.sh mit:
. path.shHerzlichen Glückwunsch, Sie sind bereit, Pykaldi in Ihrem Projekt zu verwenden!
Hinweis: Immer wenn Sie eine neue Shell öffnen, müssen Sie die Projektumgebung und den Pfad beziehen.
. myasr_env/bin/activate
. path.shHinweis: Leider sind die Pykaldi Conda -Pakete veraltet. Wenn Sie es beibehalten möchten, setzen Sie sich bitte mit uns in Verbindung.
So installieren Sie Pykaldi mit CUDA -Unterstützung:
conda install -c pykaldi pykaldiSo installieren Sie Pykaldi ohne CUDA -Unterstützung (nur CPU):
conda install -c pykaldi pykaldi-cpuBeachten Sie, dass das Pykaldi Conda -Paket Kaldi -Executables nicht zur Verfügung stellt. Wenn Sie Kaldi Executables zusammen mit Pykaldi, z. B. als Teil von Lese-/Schreibspezifikatoren, verwenden möchten, müssen Sie Kaldi separat installieren.
HINWEIS: Die folgenden Docker -Anweisungen können veraltet sein. Wenn Sie ein Docker -Image für Pykaldi beibehalten möchten, setzen Sie sich bitte mit uns in Verbindung.
Wenn Sie Pykaldi in einem Docker -Container verwenden möchten, befolgen Sie die Anweisungen im docker -Ordner.
Standardmäßig verwendet der Befehl Pykaldi Install alle verfügbaren (logischen) Prozessoren, um den Build -Prozess zu beschleunigen. Wenn die Größe des Systemspeichers im Vergleich zur Anzahl der Prozessoren relativ gering ist, erschöpft die Parallelkompilierungs-/Verknüpfungsjobs möglicherweise den Systemspeicher und führt zum Austausch. Sie können die Anzahl der parallelen Jobs einschränken, die für den Aufbau von Pykaldi wie folgt verwendet werden:
MAKE_NUM_JOBS=2 python setup.py installWir haben keine Ahnung, was benötigt wird, um Pykaldi unter Windows zu erstellen. Es würde wahrscheinlich viele Änderungen am Build -System erfordern.
Im Moment ist Pykaldi nicht mit dem stromaufwärts gelegenen Kaldi -Repository kompatibel. Sie müssen es gegen unsere Kaldi -Gabel bauen.
Wenn Sie bereits über eine kompatible Kaldi -Installation in Ihrem System verfügen, müssen Sie im Verzeichnis pykaldi/tools keine neue installieren. Stattdessen können Sie einfach die folgende Umgebungsvariable festlegen, bevor Sie den Befehl pykaldi installation ausführen.
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >Im Moment ist Pykaldi nicht mit dem stromaufwärts gelegenen Clif -Repository kompatibel. Sie müssen es mit unserer Clif -Gabel bauen.
Wenn Sie bereits über eine kompatible CLIF -Installation auf Ihrem System verfügen, müssen Sie im Verzeichnis pykaldi/tools keine neue installieren. Stattdessen können Sie einfach die folgenden Umgebungsvariablen festlegen, bevor Sie den Befehl pykaldi installation ausführen.
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > Während die Notwendigkeit, Protobuf und CLIF zu aktualisieren, nicht sehr oft auftreten sollten, möchten oder müssen Sie die Kaldi -Installation möglicherweise zum Aufbau von Pykaldi aktualisieren. Das erneute Anlagen des relevanten Installationsskripts im tools -Verzeichnis sollte die vorhandene Installation aktualisieren. Wenn dies nicht funktioniert, öffnen Sie bitte ein Problem.
Das Pykaldi tfrnnlm Paket wird automatisch zusammen mit dem Rest von Pykaldi erstellt, wenn kaldi-tensorflow-rnnlm Bibliothek unter Kaldi-Bibliotheken zu finden ist. Gehen Sie nach dem Bau von Kaldi zu KALDI_DIR/src/tfrnnlm/ Verzeichnis und befolgen Sie die im Makefile angegebenen Anweisungen. Stellen Sie sicher, dass der symbolische Link für die kaldi-tensorflow-rnnlm Bibliothek in das KALDI_DIR/src/lib/ Verzeichnis hinzugefügt wird.
Shennong - Eine Toolbox für Sprachfunktionen Extraktion wie MFCC, PLP usw. unter Verwendung von Pykaldi.
KALDI -Modellserver - Ein Thread -Kaldi -Modellserver für Live -Dekodierung. Kann Sprache direkt aus Ihrem Mikrofon mit einem Nnet3 -kompatiblen Modell dekodieren. Beispielmodelle für Englisch und Deutsch sind verfügbar. Verwendet den Pykaldi Online2 Decoder.
MeetingBot-Beispiel für eine Webanwendung zur Erfüllung der Transkription und Zusammenfassung, die ein Backend von Pykaldi/Kaldi-Model-Server verwendet, um die ASR-Ausgabe im Browser anzuzeigen.
Untertitel2GO - Automatische Untertitelgenerierung für jede Mediendatei. Verwendet Pykaldi für ASR mit einem Batch -Decoder.
Wenn Sie ein cooles Open -Source -Projekt haben, das Pykaldi verwendet, das Sie hier präsentieren möchten, lassen Sie es uns wissen!
Wenn Sie Pykaldi für die Forschung verwenden, zitieren Sie bitte unsere Arbeit wie folgt:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
Wir schätzen alle Beiträge! Wenn Sie einen Fehler finden, können Sie ein Problem oder eine Pull -Anfrage öffnen. Wenn Sie eine neue Funktion anfordern oder hinzufügen möchten, öffnen Sie bitte ein Problem zur Diskussion.


