pykaldi
v0.2.2
Pykaldi est une couche de script Python pour la boîte à outils de reconnaissance de la parole Kaldi. Il fournit des emballages Python de première classe faciles à utiliser et de première classe pour le code C ++ dans les bibliothèques Kaldi et OpenFST. Vous pouvez utiliser Pykaldi pour écrire du code Python pour des choses qui nécessiteraient autrement la rédaction du code C ++ tel que l'appel des fonctions Kaldi de bas niveau, la manipulation d'objets Kaldi et OpenFST dans le code ou implémentant de nouveaux outils Kaldi.
Vous pouvez considérer Kaldi comme une grande boîte de legos que vous pouvez mélanger et assortir pour créer des solutions de reconnaissance vocale personnalisées. La meilleure façon de penser à Pykaldi est comme un supplément, un acolyte si vous voulez, à Kaldi. En fait, Pykaldi est à son meilleur lorsqu'il est utilisé aux côtés de Kaldi. À cette fin, reproduire les fonctionnalités de myriades d'outils de ligne de commande, de scripts utilitaires et de recettes au niveau de la coquille fournies par Kaldi est un non-Goal pour le projet Pykaldi.
Comme Kaldi, Pykaldi est principalement destiné aux chercheurs et aux professionnels de la reconnaissance vocale. Il est emballé avec des goodies dont il faudrait créer des logiciels Python en profitant de la vaste collection de services publics, algorithmes et structures de données fournies par les bibliothèques Kaldi et OpenFST.
Si vous n'êtes pas familier avec la reconnaissance vocale basée sur FST ou si vous n'avez aucun intérêt à avoir accès aux tripes de Kaldi et OpenFST dans Python, mais que vous voulez seulement exécuter un système Kaldi pré-formé dans le cadre de votre application Python, ne vous inquiétez pas. Pykaldi comprend un certain nombre de modules axés sur les applications de haut niveau, tels que asr , alignment et segmentation , qui devraient être accessibles à la plupart des programmeurs Python.
Si vous êtes intéressé à utiliser Pykaldi pour la recherche ou la création d'applications ASR avancées, vous avez de la chance. Pykaldi est livré avec tout ce dont vous avez besoin pour lire, écrire, inspecter, manipuler ou visualiser les objets Kaldi et OpenFst dans Python. Il comprend des emballages Python pour la plupart des fonctions et méthodes qui font partie des API publiques des bibliothèques Kaldi et OpenFST C ++. Si vous souhaitez lire / écrire des fichiers qui sont produits / consommés par les outils Kaldi, consultez les utilitaires d'E / S et de table dans le package util . Si vous voulez travailler avec les matrices et les vecteurs Kaldi, par exemple, convertissez-les en Numpy Ndarray et vice versa, consultez le package matrix . Si vous souhaitez utiliser Kaldi pour l'extraction et la transformation des fonctionnalités, consultez les packages feat , ivector et transform . Si vous souhaitez travailler avec des réseaux ou d'autres structures FST produites / consommées par les outils Kaldi, consultez les packages fstext , lat et kws . Si vous voulez un accès de bas niveau aux modèles de mélange gaussien, aux modèles de Markov cachés ou aux arbres de décision phonétique à Kaldi, consultez les forfaits gmm , sgmm2 , hmm et tree . Si vous souhaitez un accès de bas niveau aux modèles de réseau neuronal Kaldi, consultez les packages nnet3 , cudamatrix et chain . Si vous souhaitez utiliser les décodeurs et les utilitaires de modélisation des langues à Kaldi, consultez les packages decoder , lm , rnnlm , tfrnnlm et online2 .
Les lecteurs intéressés qui souhaitent en savoir plus sur Kaldi et Pykaldi pourraient trouver les ressources suivantes utiles:
Étant donné que la reconnaissance automatique de la parole (ASR) dans Python est sans aucun doute «l'application Killer» de Pykaldi, nous passerons en revue quelques scénarios ASR pour avoir une idée de l'API Pykaldi. Nous devons noter que Pykaldi ne fournit aucun service public de haut niveau pour former des modèles ASR, vous devez donc former vos modèles en utilisant des recettes Kaldi ou utiliser des modèles pré-formés disponibles en ligne. La raison pour laquelle cela en est ainsi est simplement parce qu'il n'y a pas d'API de formation ASR de haut niveau dans les bibliothèques Kaldi C ++. Les modèles Kaldi ASR sont formés à l'aide de recettes complexes au niveau de la coque qui gèrent tout, de la préparation des données à l'orchestration des myriades exécutables Kaldi utilisés dans la formation. C'est par conception et peu susceptible de changer à l'avenir. Pykaldi fournit des emballages pour les utilitaires de formation ASR de bas niveau dans les bibliothèques Kaldi C ++, mais celles-ci ne sont pas vraiment utiles à moins que vous ne vouliez construire un pipeline de formation ASR à Python à partir de blocs de construction de base, ce qui n'est pas une tâche facile. Poursuivant avec l'analogie LEGO, cette tâche s'apparente à la construction de cet accès donné à un camion plein de legos dont vous pourriez avoir besoin. Si vous êtes assez fou pour essayer, ne laissez pas ce paragraphe vous décourager. Avant de commencer à construire Pykaldi, nous avons pensé que c'était aussi la tâche d'un fou.
Le module Pykaldi asr comprend un certain nombre de classes de haut niveau faciles à utiliser pour les rendre morts simples à assembler des systèmes ASR dans Python. Ignorer le code de la plaque de chauffeur nécessaire pour configurer les choses, faire ASR avec Pykaldi peut être aussi simple que l'extrait de code suivant:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) Dans cet exemple simplifié, nous instancions d'abord un reconnaissance hypothétique SomeRecognizer avec les chemins pour le modèle final.mdl , le graphique de décodage HCLG.fst et les words.txt de table de symbole.txt. L'objet opts contient les options de configuration du reconnaissance. Ensuite, nous instancions un lecteur de table Pykaldi SequentialMatrixReader pour lire les matrices de fonctions stockées dans les Kaldi Archive feats.ark . Enfin, nous itons sur les matrices de fonctionnalité et les décodons une par une. Ici, nous imprimons simplement la meilleure hypothèse ASR pour chaque énoncé, nous ne sommes donc intéressés que par l'entrée "text" du dictionnaire de sortie out Gardez à l'esprit que le dictionnaire de sortie contient un tas d'autres entrées utiles, telles que l'alignement au niveau du cadre de la meilleure hypothèse et un réseau pondéré représentant les hypothèses les plus probables. Certes, tous les pipelines ASR ne seront pas aussi simples que cet exemple, mais ils auront souvent la même structure globale. Dans les sections suivantes, nous verrons comment nous pouvons adapter le code donné ci-dessus pour implémenter des pipelines ASR plus compliqués.
C'est le scénario le plus courant. Nous voulons faire ASR hors ligne en utilisant des modèles Kaldi pré-formés, tels que les modèles de chaîne Aspire. Ici, nous utilisons le terme "modèles" de manière lâche pour faire référence à tout ce qu'il aurait besoin pour assembler un système ASR. Dans cet exemple spécifique, nous allons avoir besoin:
Notez que vous pouvez utiliser cet exemple de code pour décoder avec des modèles de chaîne Aspire.
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] La différence fondamentale entre cet exemple et l'extrait court de la dernière section est que pour chaque énoncé, nous lisons les données audio brutes du disque et calculant deux matrices de fonctionnalités à la volée au lieu de lire une seule matrice de fonction précomputée du disque. Le fichier de script wav.scp contient une liste de fichiers WAV correspondant aux énoncés que nous voulons décoder. La matrice de fonctionnalités supplémentaires que nous extraissons contient des vecteurs I en ligne qui sont utilisés par le modèle acoustique du réseau neuronal pour effectuer une adaptation des canaux et des haut-parleurs. La carte du haut-parleur à l'obstacle spk2utt est utilisée pour accumuler des statistiques distinctes pour chaque haut-parleur dans l'extraction en ligne en I-Vector. Il peut s'agir d'une cartographie d'identité simple si les informations du haut-parleur ne sont pas disponibles. Nous emballons les fonctionnalités MFCC et les Vectors I dans un tuple et passons ce tuple au reconnaissance du décodage. Les reconnaissances du réseau neuronal à Pykaldi savent comment gérer les fonctionnalités de vecteur I supplémentaires lorsqu'ils sont disponibles. Le fichier de modèle final.mdl contient à la fois le modèle de transition et le modèle acoustique du réseau neuronal. Les processus NnetLatticeFasterRecognizer présentent des matrices en informatique en informatique par téléphone, en utilisant le modèle acoustique du réseau neuronal, puis en mappant ceux-ci pour transmettre des journaux de journal en utilisant le modèle de transition et enfin décodant le journal de transition Log- HCLG.fst sur ses séquences de mots et des identifiants de mots sur ses labels de production. Après le décodage, nous sauvons le réseau généré par le reconnaissance dans une archive Kaldi pour un traitement futur.
Cet exemple illustre également les puissants mécanismes d'E / S fournis par Kaldi. Au lieu d'implémenter les pipelines d'extraction de fonctionnalités dans le code, nous les définissons comme des spécificateurs de lecture de Kaldi et calculons les matrices de fonctionnalité simplement en instanciant des lecteurs de table Pykaldi et en itérant sur eux. Ce n'est pas seulement le moyen le plus simple mais aussi le moyen le plus rapide de calculer les fonctionnalités avec Pykaldi, car le pipeline d'extraction de fonctionnalités est exécuté en parallèle par le système d'exploitation. De même, nous utilisons un spécificateur Kaldi Write pour instancier un écrivain de table Pykaldi qui écrit des réseaux de sortie dans une archive Kaldi compressée. Notez que pour ces fonctionnalités, nous avons besoin compute-mfcc-feats , ivector-extract-online2 et gzip pour être sur notre PATH .
Ceci est similaire au scénario précédent, mais au lieu d'un modèle acoustique Kaldi, nous utilisons un modèle acoustique pytorche. Après avoir calculé les fonctionnalités comme précédemment, nous les convertissons en un tenseur de pytorche, faisons le passage vers l'avant à l'aide d'un module de réseau neuronal Pytorch en diffusant le journal du téléphone et enfin convertir ces journaux de journal dans une matrice de pykaldi pour le décodage. Le Reconnaître utilise le modèle de transition pour cartographier automatiquement les ID de téléphone pour la transition des ID, les étiquettes d'entrée sur un graphique de décodage Kaldi typique.
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]Cette section est un espace réservé. Consultez ce script en attendant.
Le sauvetage en réseau est une technique standard pour utiliser de grands modèles de langage N-gram ou des modèles de langage de réseau neuronal récurrent (RNNLM) dans ASR. Dans cet exemple, nous attaquons les réseaux à l'aide d'un Kaldi RNNLM. Nous instancions d'abord un sauteur en fournissant les chemins des modèles. Ensuite, nous utilisons un lecteur de table pour parcourir les réseaux que nous voulons sauver et finalement nous utilisons un rédacteur de table pour réécrire les réseaux sauvés au disque.
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) Remarquez le nom de fichier étendu que nous avons utilisé pour calculer le mot incorporé à partir des fonctionnalités du mot et de la fonctionnalité intégrée à la volée. Il convient également de noter les spécificateurs de lecture / écriture que nous avons utilisés pour décompresser / compresser de manière transparente les archives du réseau. Pour que ceux-ci fonctionnent, nous avons besoin de rnnlm-get-word-embedding , gunzip et gzip pour être sur notre PATH .
Pykaldi vise à combler l'écart entre Kaldi et toutes les belles choses que Python a à offrir. C'est plus qu'une collection de liaisons dans les bibliothèques Kaldi. Il s'agit d'une couche de script fournissant une prise en charge de première classe pour les types essentiels de Kaldi et OpenFST dans Python. Le vecteur Pykaldi et les types de matrice sont étroitement intégrés à Numpy. Ils peuvent être convertis en toute transparence en tableaux Numpy et vice versa sans copier les tampons de mémoire sous-jacents. Les types de pykaldi fst, y compris les réseaux de style Kaldi, sont des citoyens de première classe à Python. L'API pour l'utilisateur fait face aux types et opérations FST est presque entièrement définie dans Python imitant l'API exposée par PyWrapfst, l'emballage Python officiel pour OpenFST.
Pykaldi exploite la puissance de CLIF pour envelopper les bibliothèques Kaldi et OpenFST C ++ en utilisant des descriptions d'API simples. Les modules d'extension cpython générés par CLIF peuvent être importés dans Python pour interagir avec Kaldi et OpenFST. Bien que CLIF soit idéal pour exposer l'API C ++ existante dans Python, les emballages n'exposent pas toujours une API "pythonique" facile à utiliser à partir de Python. Pykaldi aborde cela en étendant les emballages Clif bruts dans Python (et parfois en C ++) pour fournir une API plus "pythonique". Ci-dessous, la figure illustre où Pykaldi s'intègre dans l'écosystème Kaldi.
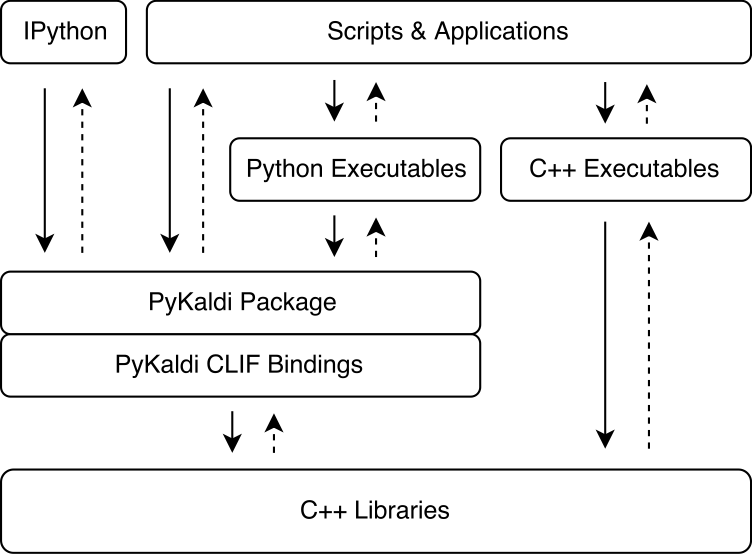
Pykaldi a une conception modulaire qui facilite le maintien et l'extension. Les fichiers source sont organisés dans une arborescence d'annuaire qui est une réplique de l'arborescence source Kaldi. Chaque répertoire définit un sous-package et ne contient que le code wrapper écrit pour la bibliothèque Kaldi associée. Le code de l'emballage se compose de:
Descriptions d'API Clif C ++ définissant les types et fonctions à emballer et leur API Python,
En-têtes C ++ définissant les cales du code Kaldi qui ne se conforme pas au style Google C ++ attendu par CLIF,
Les modules Python regroupant des modules d'extension connexes générés avec CLIF et étendant les emballages CLIF bruts pour fournir une API plus "pythonique".
Vous pouvez en savoir plus sur la conception et les détails techniques de Pykaldi dans notre article.
Le tableau suivant montre l'état de chaque package Pykaldi (nous ne prévoyons actuellement pas d'ajouter la prise en charge de NNET, NNET2 et en ligne) dans les dimensions suivantes:
| Emballer | Enveloppé? | Pythonique? | Documentation? | Tests? |
|---|---|---|---|---|
| base | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| chaîne | ✔ | ✔ | ✔ ✔ ✔ | |
| cudamatrix | ✔ | ✔ | ✔ | |
| décodeur | ✔ | ✔ | ✔ ✔ ✔ | |
| exploit | ✔ | ✔ | ✔ ✔ ✔ | |
| fstext | ✔ | ✔ | ✔ ✔ ✔ | |
| gmm | ✔ | ✔ | ✔ ✔ | ✔ |
| Hmm | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| ivector | ✔ | ✔ | ||
| kws | ✔ | ✔ | ✔ ✔ ✔ | |
| lat | ✔ | ✔ | ✔ ✔ ✔ | |
| LM | ✔ | ✔ | ✔ ✔ ✔ | |
| matrice | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| NNET3 | ✔ | ✔ | ✔ | |
| en ligne2 | ✔ | ✔ | ✔ ✔ ✔ | |
| rnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| sgmm2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| transformer | ✔ | ✔ | ✔ | |
| arbre | ✔ | ✔ | ||
| user | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
Si vous utilisez un Linux ou MacOS relativement récent, comme Ubuntu> = 16.04, Centos> = 7 ou MacOS> = 10.13, vous devriez pouvoir installer Pykaldi sans trop de problèmes. Sinon, vous devrez probablement modifier les scripts d'installation.
Vous pouvez maintenant télécharger des packages WHL officiels à partir de notre page de version GitHub. Nous avons des packages WHL pour Python 3.7, 3.8, ..., 3.11 sur Linux et quelques builds (expérimentaux) pour Mac M1 / M2.
Si vous décidez d'utiliser un package WHL, vous pouvez ignorer les sections suivantes et vous diriger directement vers "Démarrage d'un nouveau projet avec un package Pykaldi WHL" pour configurer votre projet. Notez que vous devez toujours compiler une version compatible Pykaldi de Kaldi.
Pour installer et construire Pykaldi à partir de la source, suivez les étapes ci-dessous.
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldiBien qu'il ne soit pas nécessaire, nous vous recommandons d'installer Pykaldi et toutes ses dépendances Python dans un nouvel environnement python isolé. Si vous ne voulez pas créer un nouvel environnement Python, vous pouvez ignorer le reste de cette étape.
Vous pouvez utiliser n'importe quel outil que vous aimez pour créer un nouvel environnement Python. Ici, nous utilisons virtualenv , mais vous pouvez utiliser un autre outil comme conda si vous préférez cela. Assurez-vous d'activer le nouvel environnement Python avant de continuer avec le reste de l'installation.
virtualenv env
source env/bin/activateL'exécution des commandes ci-dessous installera les packages système nécessaires à la construction de pykaldi à partir de la source.
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "L'exécution des commandes ci-dessous installera les packages Python nécessaires à la construction de pykaldi à partir de la source.
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommendedEn plus des packages répertoriés ci-dessus, nous avons également besoin d'installations compatibles Pykaldi du logiciel suivant:
Google Protobuf, recommandé v3.5.0. La bibliothèque C ++ et le package Python doivent être installés.
Pykaldi Fork compatible de Clif. Pour rationaliser le développement de Pykaldi, nous avons apporté quelques modifications à la base de code CLIF. Nous espérons en amont ces changements au fil du temps. Ces changements se trouvent dans la branche de Pykaldi:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi Vous pouvez utiliser les scripts dans le répertoire tools pour installer ou mettre à jour ces logiciels localement. Assurez-vous de vérifier la sortie de ces scripts. Si vous ne voyez pas Done installing {protobuf,CLIF,Kaldi} imprimé à la toute fin, cela signifie que l'installation a échoué pour une raison quelconque.
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..Remarque, si vous compiliez Kaldi sur Apple Silicion et ./install_kaldi.sh se bloque juste au début de la compilation de SCTK, vous devrez peut-être supprimer -March = natif de Tools / Kaldi / Tools / MakeFile, par exemple en ne passant dans cette ligne comme ceci:
SCTK_CXFLAGS = -w # -march=native Si Kaldi est installé dans le répertoire tools et que toutes les dépendances Python (Numpy, Pyparsing, Pyclif, Protobuf) sont installées dans l'environnement Python actif, vous pouvez installer Pykaldi avec la commande suivante.
python setup.py installUne fois installé, vous pouvez exécuter des tests Pykaldi avec la commande suivante.
python setup.py testVous pouvez ensuite également créer un package WHL. Le package WHL facilite l'installation de Pykaldi dans un nouvel environnement de projet pour votre projet de parole.
python setup.py bdist_wheelLe fichier WHL peut ensuite être trouvé dans le dossier "DIST". Le nom de fichier WHL dépend de la version Pykaldi, de votre version Python et de votre architecture. Pour un Python 3.9 Build sur x86_64 avec Pykaldi 0.2.2, il peut ressembler à: Dist / Pykaldi-0.2.2-CP39-CP39-LINUX_X86_64.WHL
Créez un nouveau dossier de projet, par exemple:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRCréer et activer un environnement virtuel avec la même version Python que le package WHL, par exemple pour Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateInstallez Numpy et Pykaldi dans votre environnement Myasr:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl Copiez Pykaldi / Tools / Install_kaldi.sh sur votre projet Myasr. Utilisez le script install_kaldi.sh pour installer une version Kaldi compatible Pykaldi pour votre projet:
./install_kaldi.shCopiez Pykaldi / Tools / Path.sh à votre projet. Path.sh est utilisé pour faire trouver Pykaldi les bibliothèques et les binaires Kaldi dans le dossier Kaldi. Source Path.sh avec:
. path.shFélicitations, vous êtes prêt à utiliser Pykaldi dans votre projet!
Remarque: Chaque fois que vous ouvrez un nouveau shell, vous devez vous procurer l'environnement du projet et Path.sh:
. myasr_env/bin/activate
. path.shRemarque: malheureusement, les packages Pykaldi Conda sont dépassés. Si vous souhaitez le maintenir, veuillez nous contacter.
Pour installer Pykaldi avec le support CUDA:
conda install -c pykaldi pykaldiPour installer Pykaldi sans support CUDA (CPU uniquement):
conda install -c pykaldi pykaldi-cpuNotez que le package Pykaldi Conda ne fournit pas de exécutables Kaldi. Si vous souhaitez utiliser des exécutables Kaldi avec Pykaldi, par exemple dans le cadre de spécificateurs de lecture / écriture, vous devez installer Kaldi séparément.
Remarque: Les instructions Docker ci-dessous peuvent être obsolètes. Si vous souhaitez maintenir une image Docker pour Pykaldi, veuillez nous contacter.
Si vous souhaitez utiliser Pykaldi dans un conteneur Docker, suivez les instructions dans le dossier docker .
Par défaut, la commande Pykaldi Install utilise tous les processeurs disponibles (logiques) pour accélérer le processus de construction. Si la taille de la mémoire système est relativement faible par rapport au nombre de processeurs, les travaux de compilation / liaison parallèles peuvent finir par épuiser la mémoire du système et entraîner un échange. Vous pouvez limiter le nombre de travaux parallèles utilisés pour construire Pykaldi comme suit:
MAKE_NUM_JOBS=2 python setup.py installNous n'avons aucune idée de ce qui est nécessaire pour construire Pykaldi sur Windows. Cela nécessiterait probablement de nombreux changements dans le système de construction.
Pour le moment, Pykaldi n'est pas compatible avec le référentiel Kaldi en amont. Vous devez le construire contre notre fourche Kaldi.
Si vous avez déjà une installation Kaldi compatible sur votre système, vous n'avez pas besoin d'installer un nouveau dans le répertoire pykaldi/tools . Au lieu de cela, vous pouvez simplement définir la variable d'environnement suivante avant d'exécuter la commande d'installation de Pykaldi.
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >Pour le moment, Pykaldi n'est pas compatible avec le référentiel CLIF en amont. Vous devez le construire en utilisant notre fourche CLIF.
Si vous avez déjà une installation CLIF compatible sur votre système, vous n'avez pas besoin d'en installer une nouvelle dans le répertoire pykaldi/tools . Au lieu de cela, vous pouvez simplement définir les variables d'environnement suivantes avant d'exécuter la commande d'installation de Pykaldi.
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > Bien que la nécessité de mettre à jour Protobuf et CLIF ne devrait pas apparaître très souvent, vous voudrez peut-être ou avoir besoin de mettre à jour l'installation de Kaldi utilisée pour construire Pykaldi. Le relâchement du script d'installation pertinent dans le répertoire tools doit mettre à jour l'installation existante. Si cela ne fonctionne pas, veuillez ouvrir un problème.
Le package Pykaldi tfrnnlm est construit automatiquement avec le reste de la bibliothèque Pykaldi si kaldi-tensorflow-rnnlm peut être trouvé parmi les bibliothèques Kaldi. Après avoir construit Kaldi, allez à KALDI_DIR/src/tfrnnlm/ répertoire et suivez les instructions données dans le Makefile. Assurez-vous que le lien symbolique pour la bibliothèque kaldi-tensorflow-rnnlm est ajouté au répertoire KALDI_DIR/src/lib/ .
Shennong - Une boîte à outils pour l'extraction des caractéristiques de la parole, comme MFCC, PLP, etc. en utilisant Pykaldi.
Kaldi Model Server - Un serveur de modèle Kaldi Threadd pour le décodage en direct. Peut décoder directement la parole de votre microphone avec un modèle compatible NNET3. Des exemples de modèles d'anglais et d'allemand sont disponibles. Utilise le décodeur Pykaldi Online2.
MeetingBot - Exemple d'une application Web pour la transcription et le résumé qui utilisent un backend Pykaldi / Kaldi-Model-Server pour afficher la sortie ASR dans le navigateur.
Subtitle2Go - Génération automatique des sous-titres pour tout fichier multimédia. Utilise Pykaldi pour ASR avec un décodeur de lots.
Si vous avez un projet open source cool qui utilise Pykaldi que vous souhaitez présenter ici, faites-le nous savoir!
Si vous utilisez Pykaldi pour la recherche, veuillez citer notre article comme suit:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
Nous apprécions toutes les contributions! Si vous trouvez un bogue, n'hésitez pas à ouvrir un problème ou une demande de traction. Si vous souhaitez demander ou ajouter une nouvelle fonctionnalité, veuillez ouvrir un problème pour la discussion.


