pykaldi
v0.2.2
Pykaldi adalah lapisan scripting Python untuk toolkit pengenalan suara Kaldi. Ini menyediakan pembungkus python kelas satu yang mudah digunakan untuk kode C ++ di Kaldi dan Perpustakaan OpenFST. Anda dapat menggunakan Pykaldi untuk menulis kode Python untuk hal-hal yang seharusnya memerlukan penulisan kode C ++ seperti memanggil fungsi Kaldi tingkat rendah, memanipulasi objek Kaldi dan OpenFST dalam kode atau mengimplementasikan alat Kaldi baru.
Anda dapat menganggap Kaldi sebagai sekotak besar Lego yang dapat Anda campur dan cocok untuk membangun solusi pengenalan ucapan khusus. Cara terbaik untuk memikirkan Pykaldi adalah sebagai suplemen, sahabat karib jika Anda mau, ke Kaldi. Bahkan, Pykaldi adalah yang terbaik ketika digunakan bersama Kaldi. Untuk itu, mereplikasi fungsionalitas berbagai alat baris perintah, skrip utilitas, dan resep tingkat shell yang disediakan oleh Kaldi adalah non-gol untuk proyek Pykaldi.
Seperti Kaldi, Pykaldi terutama ditujukan untuk peneliti dan profesional pengenalan suara. Kemacetan penuh dengan barang -barang yang perlu dibutuhkan orang untuk membangun perangkat lunak Python yang mengambil keuntungan dari kumpulan utilitas, algoritma, dan struktur data yang luas yang disediakan oleh Kaldi dan Perpustakaan OpenFST.
Jika Anda tidak terbiasa dengan pengenalan ucapan berbasis FST atau tidak tertarik memiliki akses ke nyali Kaldi dan OpenFST di Python, tetapi hanya ingin menjalankan sistem Kaldi yang sudah terlatih sebagai bagian dari aplikasi Python Anda, jangan fret. Pykaldi mencakup sejumlah modul berorientasi aplikasi tingkat tinggi, seperti asr , alignment dan segmentation , yang harus dapat diakses oleh sebagian besar programmer Python.
Jika Anda tertarik menggunakan Pykaldi untuk penelitian atau membangun aplikasi ASR canggih, Anda beruntung. Pykaldi hadir dengan semua yang perlu Anda baca, tulis, periksa, memanipulasi, atau memvisualisasikan objek Kaldi dan OpenFST di Python. Ini termasuk pembungkus python untuk sebagian besar fungsi dan metode yang merupakan bagian dari API publik Kaldi dan perpustakaan OpenFST C ++. Jika Anda ingin membaca/menulis file yang diproduksi/dikonsumsi oleh Kaldi Tools, lihat I/O dan Table Utilities di Paket util . Jika Anda ingin bekerja dengan matriks dan vektor Kaldi, misalnya mengubahnya menjadi ndarrays dan sebaliknya, lihat paket matrix . Jika Anda ingin menggunakan Kaldi untuk ekstraksi dan transformasi fitur, lihat paket feat , ivector dan transform . Jika Anda ingin bekerja dengan kisi atau struktur FST lainnya yang diproduksi/dikonsumsi oleh Kaldi Tools, lihat paket fstext , lat dan kws . Jika Anda ingin akses tingkat rendah ke model campuran Gaussian, model Markov tersembunyi atau pohon keputusan fonetis di Kaldi, lihat paket gmm , sgmm2 , hmm , dan tree . Jika Anda ingin akses tingkat rendah ke model jaringan saraf Kaldi, lihat paket nnet3 , cudamatrix dan chain . Jika Anda ingin menggunakan decoder dan utilitas pemodelan bahasa di Kaldi, lihat paket decoder , lm , rnnlm , tfrnnlm dan online2 .
Pembaca yang tertarik yang ingin mempelajari lebih lanjut tentang Kaldi dan Pykaldi mungkin menemukan sumber daya berikut berguna:
Karena Automatic Speech Recognition (ASR) di Python tidak diragukan lagi adalah "aplikasi pembunuh" untuk Pykaldi, kami akan membahas beberapa skenario ASR untuk merasakan Pykaldi API. Kita harus mencatat bahwa Pykaldi tidak memberikan utilitas tingkat tinggi untuk melatih model ASR, jadi Anda perlu melatih model Anda menggunakan resep Kaldi atau menggunakan model pra-terlatih yang tersedia secara online. Alasan mengapa hal ini hanya karena tidak ada API pelatihan ASR tingkat tinggi di perpustakaan Kaldi C ++. Model Kaldi ASR dilatih menggunakan resep-resep tingkat shell yang kompleks yang menangani segala sesuatu mulai dari persiapan data hingga orkestrasi Myriad Kaldi Executable yang digunakan dalam pelatihan. Ini dengan desain dan tidak mungkin berubah di masa depan. Pykaldi memang menyediakan pembungkus untuk utilitas pelatihan ASR tingkat rendah di perpustakaan Kaldi C ++ tetapi itu tidak terlalu berguna kecuali Anda ingin membangun pipa pelatihan ASR di Python dari blok bangunan dasar, yang bukan tugas yang mudah. Melanjutkan dengan analogi Lego, tugas ini mirip dengan membangun akses yang diberikan ke truk yang penuh dengan Lego yang mungkin Anda butuhkan. Jika Anda cukup gila untuk mencoba, tolong jangan biarkan paragraf ini mengecilkan hati Anda. Sebelum kami mulai membangun Pykaldi, kami pikir itu adalah tugas orang gila juga.
Modul Pykaldi asr mencakup sejumlah kelas tingkat tinggi yang mudah digunakan untuk membuatnya mati sederhana untuk mengumpulkan sistem ASR di Python. Mengabaikan kode boilerplate yang diperlukan untuk menyiapkan segalanya, melakukan ASR dengan Pykaldi bisa sesederhana cuplikan kode berikut:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) Dalam contoh yang disederhanakan ini, kami pertama -tama instantiate SomeRecognizer hipotetis dengan jalur untuk model final.mdl , grafik decoding HCLG.fst dan simbol tabel words.txt . Objek opts berisi opsi konfigurasi untuk pengenal. Kemudian, kami instantiate pembaca tabel Pykaldi SequentialMatrixReader untuk membaca matriks fitur yang disimpan dalam feats.ark arsip Kaldi. Akhirnya, kami mengulangi matriks fitur dan memecahkan kode satu per satu. Di sini kami hanya mencetak hipotesis ASR terbaik untuk setiap ucapan sehingga kami hanya tertarik pada entri "text" dari kamus out . Perlu diingat bahwa kamus output berisi banyak entri berguna lainnya, seperti penyelarasan level bingkai dari hipotesis terbaik dan kisi tertimbang yang mewakili hipotesis yang paling mungkin. Diakui, tidak semua pipa ASR akan sesederhana contoh ini, tetapi mereka akan sering memiliki struktur keseluruhan yang sama. Pada bagian berikut, kita akan melihat bagaimana kita dapat mengadaptasi kode yang diberikan di atas untuk mengimplementasikan pipa ASR yang lebih rumit.
Ini adalah skenario yang paling umum. Kami ingin melakukan ASR offline menggunakan model Kaldi pra-terlatih, seperti model rantai Aspire. Di sini kita menggunakan istilah "model" secara longgar untuk merujuk pada semua yang dibutuhkan orang untuk menyusun sistem ASR. Dalam contoh khusus ini, kita akan membutuhkan:
Perhatikan bahwa Anda dapat menggunakan kode contoh ini untuk memecahkan kode dengan model rantai Aspire.
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] Perbedaan mendasar antara contoh ini dan cuplikan pendek dari bagian terakhir adalah bahwa untuk setiap ucapan kami membaca data audio mentah dari disk dan menghitung dua matriks fitur dengan cepat alih -alih membaca satu matriks fitur prakompute tunggal dari disk. File skrip wav.scp berisi daftar file WAV yang sesuai dengan ucapan yang ingin kami decode. Matriks fitur tambahan yang kami ekstrak berisi vektor I online yang digunakan oleh model akustik jaringan saraf untuk melakukan adaptasi saluran dan speaker. Peta speaker-to-recionance spk2utt digunakan untuk mengakumulasi statistik terpisah untuk setiap pembicara dalam ekstraksi vektor i-online. Ini bisa menjadi pemetaan identitas sederhana jika informasi speaker tidak tersedia. Kami mengemas fitur MFCC dan vektor-i ke dalam tuple dan meneruskan tuple ini ke pengenal untuk decoding. Pengenalan jaringan saraf di Pykaldi tahu cara menangani fitur Vektor I tambahan saat tersedia. File model final.mdl berisi model transisi dan model akustik jaringan saraf. The NnetLatticeFasterRecognizer processes feature matrices by first computing phone log-likelihoods using the neural network acoustic model, then mapping those to transition log-likelihoods using the transition model and finally decoding transition log-likelihoods into word sequences using the decoding graph HCLG.fst , which has transition IDs on its input labels and word IDs on its output labels. Setelah decoding, kami menyimpan kisi yang dihasilkan oleh pengenal ke arsip Kaldi untuk pemrosesan di masa depan.
Contoh ini juga menggambarkan mekanisme I/O yang kuat yang disediakan oleh Kaldi. Alih -alih mengimplementasikan pipa ekstraksi fitur dalam kode, kami mendefinisikannya sebagai Kaldi membaca penentu dan menghitung matriks fitur hanya dengan instantiating pembaca tabel Pykaldi dan mengulanginya. Ini bukan hanya cara paling sederhana tetapi juga cara terkecil dari fitur komputasi dengan Pykaldi karena pipa ekstraksi fitur dijalankan secara paralel oleh sistem operasi. Demikian pula, kami menggunakan Kaldi Write Specifier untuk membuat instantiate penulis tabel Pykaldi yang menulis kisi output ke arsip Kaldi terkompresi. Perhatikan bahwa agar ini berfungsi, kita perlu compute-mfcc-feats , ivector-extract-online2 dan gzip untuk berada di PATH kita.
Ini mirip dengan skenario sebelumnya, tetapi alih -alih model akustik Kaldi, kami menggunakan model akustik Pytorch. Setelah menghitung fitur seperti sebelumnya, kami mengonversinya menjadi tentorch tensor, lakukan forward pass menggunakan modul jaringan saraf pytorch yang menghasilkan log-likelihoods ponsel dan akhirnya mengonversi log-kemungkinan log tersebut kembali menjadi matriks Pykaldi untuk decoding. Pengukur menggunakan model transisi untuk secara otomatis memetakan ID telepon untuk transisi, label input pada grafik decoding khas Kaldi.
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]Bagian ini adalah placeholder. Lihat skrip ini sementara itu.
Penyebaran kisi adalah teknik standar untuk menggunakan model bahasa N-gram besar atau model bahasa jaringan saraf berulang (RNNLM) di ASR. Dalam contoh ini, kami menukar kisi menggunakan Kaldi Rnnlm. Kami pertama -tama instantiate seorang penyelamat dengan menyediakan jalur untuk model. Kemudian kami menggunakan Table Reader untuk mengulangi kisi -kisi yang ingin kami rawat kembali dan akhirnya kami menggunakan tabel penulis untuk menulis kisi yang disambungkan kembali ke disk.
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) Perhatikan nama file yang diperpanjang yang kami gunakan untuk menghitung kata embeddings dari fitur kata dan embeddings fitur dengan cepat. Yang juga perlu diperhatikan adalah penentu baca/tulis yang kami gunakan untuk secara transparan mendekompres/mengompres arsip kisi. Agar ini berfungsi, kita membutuhkan rnnlm-get-word-embedding , gunzip dan gzip untuk berada di PATH kita.
Pykaldi bertujuan untuk menjembatani kesenjangan antara Kaldi dan semua hal menyenangkan yang ditawarkan Python. Ini lebih dari sekadar kumpulan binding ke perpustakaan Kaldi. Ini adalah lapisan skrip yang memberikan dukungan kelas satu untuk tipe esensial Kaldi dan OpenFST di Python. Jenis vektor dan matriks Pykaldi terintegrasi erat dengan numpy. Mereka dapat dikonversi dengan mulus ke array yang tidak bagus dan sebaliknya tanpa menyalin buffer memori yang mendasarinya. Jenis FST Pykaldi, termasuk kisi gaya Kaldi, adalah warga negara kelas satu di Python. API untuk pengguna yang menghadapi tipe dan operasi FST hampir seluruhnya didefinisikan dalam Python meniru API yang diekspos oleh PywRapFST, pembungkus Python resmi untuk OpenFST.
Pykaldi memanfaatkan kekuatan clif untuk membungkus perpustakaan Kaldi dan OpenFST C ++ menggunakan deskripsi API sederhana. Modul ekstensi cpython yang dihasilkan oleh CLIF dapat diimpor dalam Python untuk berinteraksi dengan Kaldi dan OpenFST. Sementara CLIF sangat bagus untuk mengekspos C ++ API yang ada di Python, pembungkus tidak selalu mengekspos API "Pythonic" yang mudah digunakan dari Python. Pykaldi membahas hal ini dengan memperluas pembungkus clif mentah di Python (dan kadang -kadang di C ++) untuk memberikan API yang lebih "Pythonic". Gambar di bawah ini menggambarkan di mana Pykaldi cocok di ekosistem Kaldi.
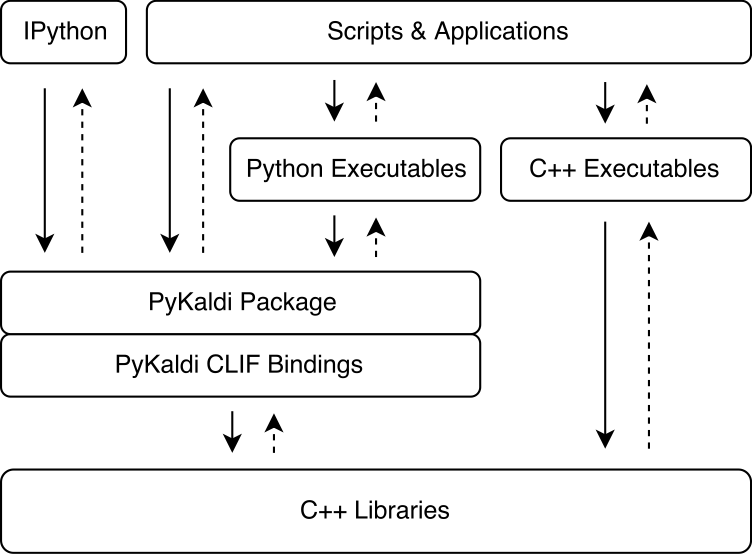
Pykaldi memiliki desain modular yang membuatnya mudah untuk dipelihara dan diperluas. File sumber disusun dalam pohon direktori yang merupakan replika pohon sumber Kaldi. Setiap direktori mendefinisikan subpackage dan hanya berisi kode pembungkus yang ditulis untuk perpustakaan Kaldi yang terkait. Kode pembungkus terdiri dari:
CLIF C ++ API Deskripsi Menentukan jenis dan fungsi yang akan dibungkus dan API Python mereka,
Header C ++ yang mendefinisikan shims untuk kode Kaldi yang tidak sesuai dengan gaya Google C ++ yang diharapkan oleh CLIF,
Modul Python Mengelompokkan modul ekstensi terkait yang dihasilkan dengan CLIF dan memperluas pembungkus CLIF mentah untuk memberikan API yang lebih "Pythonic".
Anda dapat membaca lebih lanjut tentang desain dan detail teknis Pykaldi dalam makalah kami.
Tabel berikut menunjukkan status setiap paket Pykaldi (saat ini kami tidak berencana untuk menambahkan dukungan untuk NNET, NNET2 dan online) di sepanjang dimensi berikut:
| Kemasan | Dibungkus? | Pythonic? | Dokumentasi? | Tes? |
|---|---|---|---|---|
| basis | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| rantai | ✔ | ✔ | ✔ ✔ ✔ | |
| cudamatrix | ✔ | ✔ | ✔ | |
| decoder | ✔ | ✔ | ✔ ✔ ✔ | |
| prestasi | ✔ | ✔ | ✔ ✔ ✔ | |
| fstext | ✔ | ✔ | ✔ ✔ ✔ | |
| GMM | ✔ | ✔ | ✔ ✔ | ✔ |
| Hmm | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| Ivektor | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔ ✔ ✔ | |
| Lat | ✔ | ✔ | ✔ ✔ ✔ | |
| LM | ✔ | ✔ | ✔ ✔ ✔ | |
| matriks | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| nnet3 | ✔ | ✔ | ✔ | |
| online2 | ✔ | ✔ | ✔ ✔ ✔ | |
| rnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| sgmm2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| mengubah | ✔ | ✔ | ✔ | |
| pohon | ✔ | ✔ | ||
| util | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
Jika Anda menggunakan Linux atau MacOS yang relatif baru, seperti Ubuntu> = 16.04, Centos> = 7 atau MacOS> = 10.13, Anda harus dapat menginstal Pykaldi tanpa terlalu banyak masalah. Jika tidak, Anda mungkin perlu mengubah skrip instalasi.
Anda sekarang dapat mengunduh paket WHL resmi dari halaman rilis GitHub kami. Kami memiliki paket WHL untuk Python 3.7, 3.8, ..., 3.11 di Linux dan beberapa (eksperimental) dibangun untuk Mac M1/M2.
Jika Anda memutuskan untuk menggunakan paket WHL maka Anda dapat melewatkan bagian berikutnya dan langsung menuju "memulai proyek baru dengan paket WHL Pykaldi" untuk mengatur proyek Anda. Perhatikan bahwa Anda masih perlu mengkompilasi versi Kaldi yang kompatibel dengan Pykaldi.
Untuk menginstal dan membangun Pykaldi dari sumber, ikuti langkah -langkah yang diberikan di bawah ini.
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldiMeskipun tidak diperlukan, kami merekomendasikan untuk memasang Pykaldi dan semua dependensi ular python di dalam lingkungan Python yang baru terisolasi. Jika Anda tidak ingin membuat lingkungan Python baru, Anda dapat melewatkan sisa langkah ini.
Anda dapat menggunakan alat apa pun yang Anda suka untuk membuat lingkungan Python baru. Di sini kami menggunakan virtualenv , tetapi Anda dapat menggunakan alat lain seperti conda jika Anda lebih suka itu. Pastikan Anda mengaktifkan lingkungan Python baru sebelum melanjutkan dengan sisa instalasi.
virtualenv env
source env/bin/activateMenjalankan perintah di bawah ini akan menginstal paket sistem yang diperlukan untuk membangun Pykaldi dari sumber.
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "Menjalankan perintah di bawah ini akan menginstal paket Python yang diperlukan untuk membangun Pykaldi dari sumber.
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommendedSelain paket yang terdaftar di atas, kami juga memerlukan instalasi kompatibel Pykaldi dari perangkat lunak berikut:
Google Protobuf, V3.5.0 yang direkomendasikan. Baik perpustakaan C ++ dan paket Python harus diinstal.
Pykaldi Compatible Fork of Clif. Untuk merampingkan pengembangan Pykaldi, kami membuat beberapa perubahan pada basis kode CLIF. Kami berharap untuk menghapus perubahan ini dari waktu ke waktu. Perubahan ini ada di cabang Pykaldi:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi Anda dapat menggunakan skrip di direktori tools untuk menginstal atau memperbarui perangkat lunak ini secara lokal. Pastikan Anda memeriksa output skrip ini. Jika Anda tidak melihat Done installing {protobuf,CLIF,Kaldi} dicetak di bagian paling akhir, itu berarti bahwa instalasi telah gagal karena beberapa alasan.
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..Catatan, jika Anda mengkompilasi Kaldi pada Silicion Apple dan ./install_kaldi.sh terjebak tepat di awal menyusun sctk, Anda mungkin perlu menghapus -march = asli dari alat/Kaldi/alat/makefile, misalnya dengan tidak mencatatnya di baris ini seperti ini:
SCTK_CXFLAGS = -w # -march=native Jika Kaldi dipasang di dalam direktori tools dan semua dependensi Python (numpy, pyparsing, pyclif, protobuf) dipasang di lingkungan Python yang aktif, Anda dapat menginstal Pykaldi dengan perintah berikut.
python setup.py installSetelah diinstal, Anda dapat menjalankan tes Pykaldi dengan perintah berikut.
python setup.py testAnda kemudian dapat juga membuat paket WHL. Paket WHL memudahkan untuk menginstal Pykaldi ke lingkungan proyek baru untuk proyek bicara Anda.
python setup.py bdist_wheelFile WHL kemudian dapat ditemukan di folder "Dist". Nama file WHL tergantung pada versi Pykaldi, versi Python Anda dan arsitektur Anda. Untuk Python 3.9 Build di X86_64 dengan Pykaldi 0.2.2 mungkin terlihat seperti: Dist/Pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl
Buat folder proyek baru, misalnya:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRBuat dan aktifkan lingkungan virtual dengan versi python yang sama dengan paket WHL, misalnya untuk Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateInstal Numpy dan Pykaldi ke dalam lingkungan myasr Anda:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl Salin pykaldi/tools/install_kaldi.sh ke proyek myasr Anda. Gunakan skrip install_kaldi.sh untuk menginstal versi Kaldi yang kompatibel dengan Pykaldi untuk proyek Anda:
./install_kaldi.shSalin Pykaldi/Tools/Path.sh ke proyek Anda. Path.sh digunakan untuk membuat Pykaldi menemukan perpustakaan dan binari Kaldi di folder Kaldi. Sumber Path.sh dengan:
. path.shSelamat, Anda siap menggunakan Pykaldi dalam proyek Anda!
Catatan: Kapan pun Anda membuka shell baru, Anda perlu mencari lingkungan dan path proyek.
. myasr_env/bin/activate
. path.shCatatan: Sayangnya, paket Pykaldi Conda sudah ketinggalan zaman. Jika Anda ingin mempertahankannya, silakan menghubungi kami.
Untuk menginstal Pykaldi dengan dukungan CUDA:
conda install -c pykaldi pykaldiUntuk menginstal Pykaldi tanpa dukungan CUDA (hanya CPU):
conda install -c pykaldi pykaldi-cpuPerhatikan bahwa paket Pykaldi Conda tidak menyediakan Kaldi Executables. Jika Anda ingin menggunakan Kaldi Executables bersama dengan Pykaldi, misalnya sebagai bagian dari penata baca/tulis, Anda perlu menginstal Kaldi secara terpisah.
Catatan: Instruksi Docker di bawah ini mungkin sudah ketinggalan zaman. Jika Anda ingin mempertahankan gambar Docker untuk Pykaldi, silakan hubungi kami.
Jika Anda ingin menggunakan Pykaldi di dalam wadah Docker, ikuti instruksi di folder docker .
Secara default, perintah Install Pykaldi menggunakan semua prosesor (logis) yang tersedia untuk mempercepat proses pembuatan. Jika ukuran memori sistem relatif kecil dibandingkan dengan jumlah prosesor, pekerjaan kompilasi/penghubung paralel mungkin akhirnya melelahkan memori sistem dan mengakibatkan bertukar. Anda dapat membatasi jumlah pekerjaan paralel yang digunakan untuk membangun Pykaldi sebagai berikut:
MAKE_NUM_JOBS=2 python setup.py installKami tidak tahu apa yang diperlukan untuk membangun Pykaldi di Windows. Mungkin membutuhkan banyak perubahan pada sistem pembangunan.
Saat ini, Pykaldi tidak kompatibel dengan repositori Kaldi hulu. Anda perlu membangunnya melawan Kaldi Fork kami.
Jika Anda sudah memiliki instalasi Kaldi yang kompatibel di sistem Anda, Anda tidak perlu menginstal yang baru di dalam direktori pykaldi/tools . Sebagai gantinya, Anda cukup mengatur variabel lingkungan berikut sebelum menjalankan perintah instalasi Pykaldi.
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >Saat ini, Pykaldi tidak kompatibel dengan repositori CLIF hulu. Anda perlu membangunnya menggunakan clif fork kami.
Jika Anda sudah memiliki instalasi CLIF yang kompatibel pada sistem Anda, Anda tidak perlu menginstal yang baru di dalam direktori pykaldi/tools . Sebagai gantinya, Anda cukup mengatur variabel lingkungan berikut sebelum menjalankan perintah instalasi Pykaldi.
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > Sementara kebutuhan untuk memperbarui protobuf dan clif tidak boleh muncul terlalu sering, Anda mungkin ingin atau perlu memperbarui instalasi Kaldi yang digunakan untuk membangun Pykaldi. Mengulangi skrip instalasi yang relevan di direktori tools harus memperbarui instalasi yang ada. Jika ini tidak berhasil, buka masalah.
Paket Pykaldi tfrnnlm dibangun secara otomatis bersama dengan Pykaldi lainnya jika perpustakaan kaldi-tensorflow-rnnlm dapat ditemukan di antara perpustakaan Kaldi. Setelah membangun Kaldi, kunjungi KALDI_DIR/src/tfrnnlm/ direktori dan ikuti instruksi yang diberikan di Makefile. Pastikan tautan simbolis untuk perpustakaan kaldi-tensorflow-rnnlm ditambahkan ke direktori KALDI_DIR/src/lib/ .
Shennong - Kotak alat untuk ekstraksi fitur ucapan, seperti MFCC, PLP dll. Menggunakan Pykaldi.
Kaldi Model Server - Server model Kaldi berulir untuk decoding langsung. Dapat secara langsung memecahkan kode ucapan dari mikrofon Anda dengan model yang kompatibel dengan NNET3. Contoh model untuk bahasa Inggris dan Jerman tersedia. Menggunakan dekoder Pykaldi Online2.
MeetingBot-Contoh aplikasi web untuk memenuhi transkripsi dan ringkasan yang memanfaatkan backend Pykaldi/Kaldi-Model-Server untuk menampilkan output ASR di browser.
Subtitle2go - Pembuatan subtitle otomatis untuk file media apa pun. Menggunakan Pykaldi untuk ASR dengan decoder batch.
Jika Anda memiliki proyek open source keren yang memanfaatkan Pykaldi yang ingin Anda tampilkan di sini, beri tahu kami!
Jika Anda menggunakan Pykaldi untuk penelitian, silakan kutip makalah kami sebagai berikut:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
Kami menghargai semua kontribusi! Jika Anda menemukan bug, jangan ragu untuk membuka masalah atau permintaan tarik. Jika Anda ingin meminta atau menambahkan fitur baru, silakan buka masalah untuk diskusi.


