pykaldi
v0.2.2
Pykaldi é uma camada de script de Python para o kit de ferramentas de reconhecimento de fala Kaldi. Ele fornece invólucros de python de primeira classe e de primeira classe de primeira classe para o código C ++ nas bibliotecas Kaldi e OpenFST. Você pode usar o Pykaldi para escrever código Python para coisas que, de outra forma, exigiriam o código C ++, como chamar funções kaldi de baixo nível, manipular objetos kaldi e openfst no código ou implementar novas ferramentas kaldi.
Você pode pensar em Kaldi como uma grande caixa de Legos que pode misturar e combinar para criar soluções de reconhecimento de fala personalizadas. A melhor maneira de pensar em Pykaldi é como um suplemento, um companheiro, se você quiser, para Kaldi. De fato, Pykaldi está no seu melhor quando é usado ao lado de Kaldi. Para esse fim, a replicação da funcionalidade das inúmeras ferramentas da linha de comando, scripts de utilidade e receitas em nível de conchas fornecidas por Kaldi é um não-objetivo para o projeto Pykaldi.
Como Kaldi, Pykaldi destina -se principalmente a pesquisadores e profissionais de reconhecimento de fala. É uma jam repleta de guloseimas que seria necessário criar software Python, aproveitando a vasta coleção de utilitários, algoritmos e estruturas de dados fornecidas pelas bibliotecas Kaldi e OpenFST.
Se você não estiver familiarizado com o reconhecimento de fala baseado em FST ou não tem interesse em ter acesso às entranhas de Kaldi e OpenFST em Python, mas apenas deseja executar um sistema Kaldi pré-treinado como parte do seu aplicativo Python, não se preocupe. O Pykaldi inclui vários módulos de alto nível orientados a aplicativos, como asr , alignment e segmentation , que devem ser acessíveis à maioria dos programadores Python.
Se você estiver interessado em usar o Pykaldi para pesquisar ou criar aplicativos ASR avançados, você está com sorte. Pykaldi vem com tudo o que você precisa ler, escrever, inspecionar, manipular ou visualizar objetos kaldi e openfst no Python. Inclui invólucros de Python para a maioria das funções e métodos que fazem parte das APIs públicas das bibliotecas Kaldi e OpenFST C ++. Se você deseja ler/gravar arquivos que são produzidos/consumidos pelas ferramentas kaldi, consulte os utilitários de E/S e tabela no pacote util . Se você deseja trabalhar com matrizes e vetores Kaldi, por exemplo, converta -as em Numpy Ndarrays e vice -versa, confira o pacote matrix . Se você deseja usar o Kaldi para extração e transformação de recursos, consulte os pacotes de feat , ivector e transform . Se você deseja trabalhar com treliças ou outras estruturas FST produzidas/consumidas pelas ferramentas kaldi, consulte os pacotes fstext , lat e kws . Se você deseja acesso a modelos de mistura gaussiana de baixo nível, modelos de Markov ocultos ou árvores de decisão fonética em Kaldi, confira os pacotes gmm , sgmm2 , hmm e tree . Se você deseja acesso de baixo nível aos modelos de rede neural kaldi, confira os pacotes nnet3 , cudamatrix e chain . Se você deseja usar os utilitários de decodificadores e modelagem de idiomas em Kaldi, consulte os pacotes decoder , lm , rnnlm , tfrnnlm e online2 .
Os leitores interessados que gostariam de aprender mais sobre Kaldi e Pykaldi podem achar os seguintes recursos úteis:
Como o reconhecimento automático de fala (ASR) em Python é sem dúvida o "aplicativo assassino" para Pykaldi, examinaremos alguns cenários do ASR para ter uma idéia da API de Pykaldi. Devemos observar que o Pykaldi não fornece nenhum utilitário de alto nível para o treinamento de modelos ASR, portanto, você precisa treinar seus modelos usando receitas kaldi ou usar modelos pré-treinados disponíveis on-line. A razão pela qual é isso é simplesmente porque não há API de treinamento de ASR de alto nível nas bibliotecas Kaldi C ++. Os modelos Kaldi ASR são treinados usando receitas complexas no nível da concha que lidam com tudo, desde a preparação de dados até a orquestração de inúmeros executáveis kaldi usados no treinamento. Isso é por design e improvável que mude no futuro. Pykaldi fornece invólucros para as concessionárias de treinamento de ASR de baixo nível nas bibliotecas Kaldi C ++, mas essas não são realmente úteis, a menos que você queira criar um pipeline de treinamento ASR em Python a partir de blocos básicos de construção, o que não é uma tarefa fácil. Continuando com a analogia do Lego, essa tarefa é semelhante a construir esse acesso a um caminhão cheio de Legos que você pode precisar. Se você é louco o suficiente para tentar, por favor, não deixe este parágrafo desencorajá -lo. Antes de começarmos a construir Pykaldi, pensamos que era uma tarefa louca também.
O módulo Pykaldi asr inclui uma série de classes de alto nível fácil de usar para simplificar a montagem de sistemas ASR em Python. Ignorando o código de caldeira necessário para configurar as coisas, fazer ASR com Pykaldi pode ser tão simples quanto o seguinte trecho de código:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) Neste exemplo simplificado, primeiro instanciamos um reconhecedor hipotético SomeRecognizer com os caminhos para o modelo final.mdl , o gráfico de decodificação HCLG.fst e o símbolo tabela words.txt . O objeto opts contém as opções de configuração para o reconhecedor. Em seguida, instanciamos um leitor de tabela de Pykaldi SequentialMatrixReader para ler as matrizes de recursos armazenadas no Kaldi Archive feats.ark . Finalmente, iteramos sobre as matrizes de características e as decodificamos uma a uma. Aqui estamos simplesmente imprimindo a melhor hipótese do ASR para cada enunciada, por isso estamos interessados apenas na entrada do "text" do dicionário de out . Lembre -se de que o dicionário de saída contém um monte de outras entradas úteis, como o alinhamento do nível do quadro da melhor hipótese e uma rede ponderada representando as hipóteses mais prováveis. É certo que nem todos os pipelines ASR serão tão simples como este exemplo, mas geralmente terão a mesma estrutura geral. Nas seções a seguir, veremos como podemos adaptar o código fornecido acima para implementar pipelines ASR mais complicados.
Este é o cenário mais comum. Queremos fazer ASR offline usando modelos Kaldi pré-treinados, como modelos de cadeia de aspiros. Aqui estamos usando o termo "modelos" livremente para nos referir a tudo o que se precisaria de montar um sistema ASR. Neste exemplo específico, vamos precisar:
Observe que você pode usar este código de exemplo para decodificar com os modelos de cadeia de aspiros.
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] A diferença fundamental entre este exemplo e o trecho curto da última seção é que, para cada enunciado, estamos lendo os dados de áudio bruto do disco e calculando duas matrizes de recursos em tempo real, em vez de ler uma única matriz de recurso pré -computada do disco. O arquivo de script wav.scp contém uma lista de arquivos WAV correspondentes aos enunciados que queremos decodificar. A matriz de recursos adicionais que estamos extraindo contém vetores I on-line usados pelo modelo acústico de rede neural para executar a adaptação de canal e alto-falante. O mapa do alto-falante a suprimento spk2utt é usado para acumular estatísticas separadas para cada orador na extração on-line do vetor I. Pode ser um simples mapeamento de identidade se as informações do alto -falante não estiverem disponíveis. Nós embalamos os recursos do MFCC e os vetores I em uma tupla e passamos essa tupla para o reconhecimento para a decodificação. Os reconhecedores de rede neural em Pykaldi sabem como lidar com os recursos adicionais do vetor I quando estão disponíveis. O arquivo de modelo final.mdl contém o modelo de transição e o modelo acústico de rede neural. Os processos NnetLatticeFasterRecognizer apresentam matrizes pela primeira computação do telefone, usando o modelo acústico de rede neural e, em seguida, mapeando-as para transição de log-liquidização usando o modelo de transição e, finalmente, a transição de trânsito HCLG.fst Após a decodificação, salvamos a treliça gerada pelo reconhecedor de um arquivo kaldi para processamento futuro.
Este exemplo também ilustra os poderosos mecanismos de E/S fornecidos por Kaldi. Em vez de implementar os pipelines de extração de recursos no código, os definimos como Kaldi lê especificadores e calculamos as matrizes de recursos simplesmente instantando os leitores da tabela de Pykaldi e iterando sobre eles. Esta não é apenas a maneira mais simples, mas também a maneira mais rápida de calcular os recursos com Pykaldi, pois o pipeline de extração de recursos é executado em paralelo pelo sistema operacional. Da mesma forma, usamos um especificador de gravação kaldi para instanciar um escritor de tabela de Pykaldi que grava redes de saída em um arquivo kaldi compactado. Observe que, para que eles funcionem, precisamos compute-mfcc-feats , ivector-extract-online2 e gzip para estar em nosso PATH .
Isso é semelhante ao cenário anterior, mas, em vez de um modelo acústico de Kaldi, usamos um modelo acústico de pytorch. Depois de calcular os recursos como antes, convertemos-os em um tensor de pytorch, fazemos o passe para a frente usando um módulo de rede neural pytorch que saindo de tons de televisão por telefone e finalmente convertemos essas probabilidades de log em uma matriz de Pykaldi para decodificar. O reconhecedor usa o modelo de transição para mapear automaticamente os IDs de telefone para transição IDs, os rótulos de entrada em um gráfico de decodificação kaldi típico.
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]Esta seção é um espaço reservado. Enquanto isso, confira este script.
O resgate de treliça é uma técnica padrão para usar grandes modelos de idiomas N-Gram ou modelos de linguagem de rede neural recorrente (RNNLMs) no ASR. Neste exemplo, resgatamos redes usando um kaldi rnnlm. Primeiro instanciamos um resgatador, fornecendo os caminhos para os modelos. Em seguida, usamos um leitor de tabela para iterar sobre as treliças que queremos resgatar e, finalmente, usamos um escritor de tabela para escrever treliças resgatadas de volta ao disco.
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) Observe o nome do arquivo estendido que usamos para calcular a palavra incorporação dos recursos da palavra e as incorporações de recurso em tempo real. Também são dignos de nota os especificadores de leitura/gravação que usamos para descomprimir/comprimir transparentemente os arquivos da rede. Para que eles funcionem, precisamos rnnlm-get-word-embedding , gunzip e gzip para estar em nosso PATH .
Pykaldi pretende preencher a lacuna entre Kaldi e todas as coisas legais que Python tem a oferecer. É mais do que uma coleção de ligações nas bibliotecas kaldi. É uma camada de script que fornece suporte de primeira classe para os tipos essenciais de kaldi e openfst no python. Os tipos de vetor e matriz de Pykaldi são fortemente integrados com Numpy. Eles podem ser convertidos perfeitamente em matrizes Numpy e vice -versa sem copiar os buffers de memória subjacentes. Os tipos de Pykaldi FST, incluindo as treliças do estilo Kaldi, são cidadãos de primeira classe em Python. A API para o usuário que enfrenta os tipos e operações FST é quase totalmente definida em Python imitando a API exposta pelo Pywrapfst, o invólucro oficial do Python para o OpenFST.
Pykaldi aproveita o poder do Clif para embrulhar as bibliotecas Kaldi e OpenFST C ++ usando descrições de API simples. Os módulos de extensão do CPYTHON gerados pelo CLIF podem ser importados no Python para interagir com Kaldi e Openfst. Embora o CLIF seja ótimo para expor a API C ++ existente em Python, os Wrappers nem sempre expõem uma API "Pitônica" que é fácil de usar no Python. Pykaldi aborda isso, estendendo os invólucros crus do clif em Python (e às vezes em C ++) para fornecer uma API mais "pitônica". A figura abaixo ilustra onde Pykaldi se encaixa no ecossistema de Kaldi.
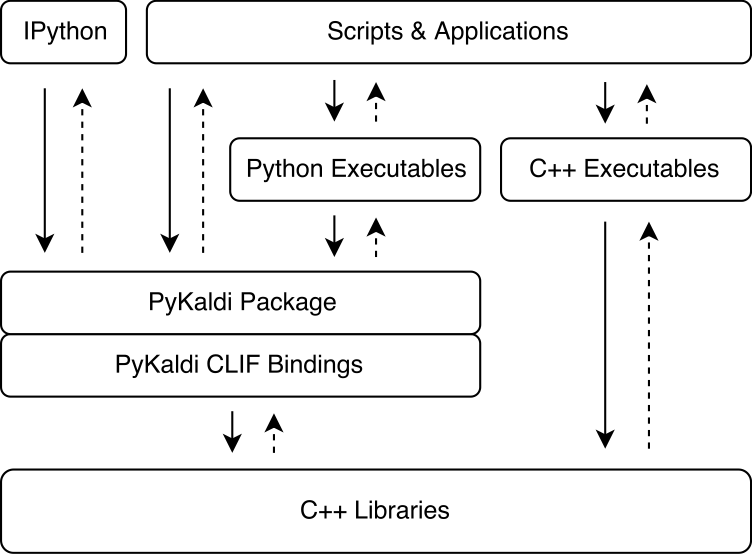
Pykaldi tem um design modular que facilita a manutenção e a extensão. Os arquivos de origem são organizados em uma árvore de diretório que é uma réplica da árvore de origem kaldi. Cada diretório define uma subpackagem e contém apenas o código do wrapper escrito para a biblioteca Kaldi associada. O código do invólucro consiste em:
Descrições da API do CLIF C ++ Definindo os tipos e funções a serem embrulhados e sua API Python,
Cabeçalhos C ++ Definindo os calços para o código kaldi que não é compatível com o estilo do Google C ++ esperado pelo clif,
Os módulos de Python agrupando módulos de extensão relacionados gerados com CLIF e estendendo os invólucros de clif bruto para fornecer uma API mais "pitônica".
Você pode ler mais sobre o design e detalhes técnicos de Pykaldi em nosso artigo.
A tabela a seguir mostra o status de cada pacote Pykaldi (atualmente não planejamos adicionar suporte à NNET, NNET2 e online) nas seguintes dimensões:
| Pacote | Envolto? | Pitônico? | Documentação? | Testes? |
|---|---|---|---|---|
| base | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| corrente | ✔ | ✔ | ✔ ✔ ✔ | |
| Cudamatrix | ✔ | ✔ | ✔ | |
| decodificador | ✔ | ✔ | ✔ ✔ ✔ | |
| façanha | ✔ | ✔ | ✔ ✔ ✔ | |
| FSTEXT | ✔ | ✔ | ✔ ✔ ✔ | |
| GMM | ✔ | ✔ | ✔ ✔ | ✔ |
| hum | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| IVECTOR | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔ ✔ ✔ | |
| Lat | ✔ | ✔ | ✔ ✔ ✔ | |
| LM | ✔ | ✔ | ✔ ✔ ✔ | |
| matriz | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| Nnet3 | ✔ | ✔ | ✔ | |
| online2 | ✔ | ✔ | ✔ ✔ ✔ | |
| rnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| sgmm2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| transformar | ✔ | ✔ | ✔ | |
| árvore | ✔ | ✔ | ||
| util | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
Se você estiver usando um Linux ou MacOS relativamente recente, como o Ubuntu> = 16.04, Centos> = 7 ou MacOS> = 10.13, poderá instalar Pykaldi sem muitos problemas. Caso contrário, você provavelmente precisará ajustar os scripts de instalação.
Agora você pode baixar pacotes WHL oficiais da nossa página de lançamento do GitHub. Temos pacotes WHL para Python 3.7, 3.8, ..., 3.11 no Linux e algumas compilações (experimentais) para Mac M1/M2.
Se você decidir usar um pacote WHL, poderá pular as próximas seções e seguir direto para "iniciar um novo projeto com um pacote Pykaldi WHL" para configurar seu projeto. Observe que você ainda precisa compilar uma versão compatível com Pykaldi do kaldi.
Para instalar e construir Pykaldi a partir da fonte, siga as etapas abaixo.
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldiEmbora não seja necessário, recomendamos a instalação de Pykaldi e todas as suas dependências do Python dentro de um novo ambiente Python isolado. Se você não deseja criar um novo ambiente Python, poderá pular o restante desta etapa.
Você pode usar qualquer ferramenta que desejar para criar um novo ambiente Python. Aqui usamos virtualenv , mas você pode usar outra ferramenta como conda , se preferir. Certifique -se de ativar o novo ambiente Python antes de continuar com o restante da instalação.
virtualenv env
source env/bin/activateA execução dos comandos abaixo instalará os pacotes do sistema necessários para a construção de Pykaldi a partir da fonte.
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "A execução dos comandos abaixo instalará os pacotes Python necessários para a construção de Pykaldi a partir da fonte.
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommendedAlém dos pacotes listados acima, também precisamos de instalações compatíveis com Pykaldi do seguinte software:
Google Protobuf, recomendado v3.5.0. A biblioteca C ++ e o pacote Python devem ser instalados.
Fork compatível com Pykaldi de Clif. Para otimizar o desenvolvimento de Pykaldi, fizemos algumas alterações na base de código CLIF. Esperamos montar essas mudanças ao longo do tempo. Essas mudanças estão na filial de Pykaldi:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi Você pode usar os scripts no diretório tools para instalar ou atualizar esses software localmente. Verifique a saída desses scripts. Se você não achar Done installing {protobuf,CLIF,Kaldi} impressa no final, isso significa que a instalação falhou por algum motivo.
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..Observe que, se você estiver compilando Kaldi na Apple Silicion e ./install_kaldi.sh fica preso no início compilando sctk, pode ser necessário remover -march = nativo de ferramentas/kaldi/ferramentas/makefile, por exemplo, desconfiando nessa linha como esta:
SCTK_CXFLAGS = -w # -march=native Se o kaldi estiver instalado dentro do diretório tools e todas as dependências do Python (Numpy, Pyparsing, Pyclif, Protobuf) estiverem instaladas no ambiente ativo do Python, você poderá instalar Pykaldi com o seguinte comando.
python setup.py installDepois de instalado, você pode executar testes de Pykaldi com o seguinte comando.
python setup.py testVocê também pode criar um pacote WHL. O pacote WHL facilita a instalação do Pykaldi em um novo ambiente de projeto para o seu projeto de fala.
python setup.py bdist_wheelO arquivo WHL pode ser encontrado na pasta "Dist". O nome do arquivo WHL depende da versão Pykaldi, da sua versão Python e da sua arquitetura. Para um Python 3.9 construir em x86_64 com pykaldi 0.2.2 pode parecer: dist/pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl
Crie uma nova pasta de projetos, por exemplo:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRCrie e ative um ambiente virtual com a mesma versão Python que o pacote WHL, por exemplo, para Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateInstale Numpy e Pykaldi em seu ambiente Myasr:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl Copie Pykaldi/Ferramentas/Install_kaldi.sh para o seu projeto Myasr. Use o script install_kaldi.sh para instalar uma versão kaldi compatível com Pykaldi para o seu projeto:
./install_kaldi.shCopie Pykaldi/Tools/Path.sh para o seu projeto. Path.sh é usado para fazer Pykaldi encontrar as bibliotecas e binários Kaldi na pasta Kaldi. Fonte Path.sh com:
. path.shParabéns, você está pronto para usar Pykaldi em seu projeto!
Nota: Sempre que você abrir um novo shell, você precisa obter o ambiente do projeto e o caminho.sh:
. myasr_env/bin/activate
. path.shNOTA: Infelizmente, os pacotes Pykaldi condata estão desatualizados. Se você deseja mantê -lo, entre em contato conosco.
Para instalar Pykaldi com suporte CUDA:
conda install -c pykaldi pykaldiPara instalar Pykaldi sem suporte ao CUDA (apenas CPU):
conda install -c pykaldi pykaldi-cpuObserve que o pacote Pykaldi condata não fornece executáveis kaldi. Se você deseja usar os executáveis da Kaldi junto com Pykaldi, por exemplo, como parte dos especificadores de leitura/gravação, precisa instalar o kaldi separadamente.
Nota: As instruções do Docker abaixo podem estar desatualizadas. Se você deseja manter uma imagem do Docker para Pykaldi, entre em contato conosco.
Se você deseja usar Pykaldi dentro de um recipiente do Docker, siga as instruções na pasta docker .
Por padrão, o comando de instalação do Pykaldi usa todos os processadores disponíveis (lógicos) para acelerar o processo de construção. Se o tamanho da memória do sistema for relativamente pequeno em comparação com o número de processadores, os trabalhos de compilação/vinculação paralelos poderão acabar esgotando a memória do sistema e resultar em troca. Você pode limitar o número de trabalhos paralelos usados para construir Pykaldi da seguinte maneira:
MAKE_NUM_JOBS=2 python setup.py installNão temos idéia do que é necessário para construir Pykaldi no Windows. Provavelmente exigiria muitas alterações no sistema de construção.
No momento, Pykaldi não é compatível com o repositório Kaldi a montante. Você precisa construí -lo contra o nosso garfo kaldi.
Se você já possui uma instalação compatível com kaldi no seu sistema, não precisa instalar um novo dentro do diretório pykaldi/tools . Em vez disso, você pode simplesmente definir a seguinte variável de ambiente antes de executar o comando de instalação do Pykaldi.
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >No momento, Pykaldi não é compatível com o repositório CLIF a montante. Você precisa construí -lo usando nosso garfo clif.
Se você já possui uma instalação compatível com CLIF no seu sistema, não precisa instalar um novo dentro do diretório pykaldi/tools . Em vez disso, você pode simplesmente definir as seguintes variáveis de ambiente antes de executar o comando de instalação do Pykaldi.
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > Embora a necessidade de atualizar o Protobuf e o CLIF não deva surgir com muita frequência, você pode querer ou precisar atualizar a instalação kaldi usada para a construção de Pykaldi. Remover o script de instalação relevante no diretório tools deve atualizar a instalação existente. Se isso não funcionar, abra um problema.
O pacote pykaldi tfrnnlm é construído automaticamente junto com o restante de Pykaldi se a biblioteca kaldi-tensorflow-rnnlm puder ser encontrada entre as bibliotecas kaldi. Depois de construir kaldi, acesse KALDI_DIR/src/tfrnnlm/ diretório e siga as instruções fornecidas no Makefile. Verifique se o link simbólico da biblioteca kaldi-tensorflow-rnnlm é adicionado ao diretório KALDI_DIR/src/lib/ .
SHENNONG - Uma caixa de ferramentas para extração de recursos de fala, como MFCC, PLP etc. usando Pykaldi.
Kaldi Model Server - um servidor de modelos Kaldi roscado para decodificação ao vivo. Pode decodificar diretamente a fala do seu microfone com um modelo compatível com NNET3. Exemplo de modelos para inglês e alemão estão disponíveis. Usa o decodificador Pykaldi Online2.
MeetingBot-Exemplo de um aplicativo da Web para atender à transcrição e resumo que utiliza um back-end de Pykaldi/Kaldi-Model-Server para exibir a saída ASR no navegador.
Subtitle2GO - Geração automática de legenda para qualquer arquivo de mídia. Usa Pykaldi para ASR com um decodificador em lote.
Se você tem um projeto legal de código aberto que utiliza Pykaldi que gostaria de mostrar aqui, informe -nos!
Se você usa Pykaldi para pesquisa, cite nosso artigo da seguinte maneira:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
Agradecemos todas as contribuições! Se você encontrar um bug, fique à vontade para abrir um problema ou uma solicitação de tração. Se você deseja solicitar ou adicionar um novo recurso, abra um problema para discussão.


