RobBERT
v2.0

羅伯特是最先進的荷蘭伯特模式。這是一個大型的荷蘭語通用語言模型,可以在給定數據集上進行微調,以執行任何文本分類,回歸或標記任務。因此,許多研究人員和從業人員成功使用了它來實現各種荷蘭自然語言處理任務的最先進績效,包括:
並且還取得了出色的,近距離的結果:
*請注意,幾項評估使用Robbert-V1,第二個和改進的Robbert-V2在我們測試的所有內容上都優於第一個模型
(還請注意,此列表並不詳盡。如果您將Robbert用於您的應用程序,我們很樂意知道它!請發送一封郵件,或通過發送編輯的拉請請求將其添加到此列表中!)
要使用HuggingFace Transformers使用Robbert模型,請使用pdelobelle/robbert-v2-dutch-base名稱。
有關Robbert的更多深度信息可以在我們的博客文章和論文中找到。
羅伯特(Robbert)使用羅伯塔(Roberta)的建築和預培訓,但使用了荷蘭令牌和培訓數據。羅伯塔(Roberta)是強大的優化英語BERT模型,使其比原始BERT模型更強大。鑑於相同的體系結構,可以輕鬆地使用fineTune Roberta模型的代碼和BERT模型的大多數代碼來輕鬆地進行修正和推斷,例如HuggingFace Transformers Library提供的代碼。
羅伯特可以以兩種不同的方式輕鬆使用,即使用Fairseq Roberta代碼或使用HuggingFace Transformer
默認情況下,羅伯特(Robbert)具有用於培訓的蒙版語言模型。這可以用作填充句子中掩碼的零彈方法。可以在Robbert的Huggingface的推理API上免費測試它。您還可以通過使用Huggingface的Roberta-Runners,通過將模型名稱更改為pdelobelle/robbert-v2-dutch-base ,或使用原始的Fairseq Roberta培訓方案來為自己的任務創建一個新的預測頭。
您可以輕鬆地使用Robbert V2使用?變壓器。使用以下代碼下載基本模型並自行登錄,或使用我們的Finetundundode型號(在我們的項目站點上記錄)。
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )從transformers v2.4.0 (或從源安裝)開始,您可以使用自動口號和汽車模型。然後,您可以將大多數基於BERT的筆記本電腦使用Robbert fineTuning Robbert,以便在您類型的荷蘭語言數據集上。
另外,您也可以使用Roberta Architecte代碼使用Robbert。您可以在此處下載Robbert V2的Fairseq模型:( Robbert-Base,1.5 GB)。使用Robbert的model.pt ,此方法允許您使用Roberta的所有其他功能。
所有實驗在我們的論文中更詳細地描述了我們的GitHub存儲庫中的代碼。
使用荷蘭書評數據集預測評論是正面還是負面。
| 模型 | 準確性 [%] |
|---|---|
| Ulmfit | 93.8 |
| Bertje | 93.0 |
| 羅伯特V2 | 95.1 |
我們通過預測是否應將“ Die”或“ DAT”填充到句子中來衡量模型能夠完成核心分辨率的能力。為此,我們使用了Europarl語料庫。
| 模型 | 準確性 [%] | F1 [%] |
|---|---|---|
| 基線(LSTM) | 75.03 | |
| 姆伯特 | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| 羅伯特V2 | 99.232 | 99.121 |
我們還僅使用10K訓練示例來測量性能。該實驗清楚地表明,當很少有數據可用時,羅伯特的表現要優於其他模型。
| 模型 | 準確性 [%] | F1 [%] |
|---|---|---|
| 姆伯特 | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| 羅伯特V2 | 97.816 | 97.514 |
由於BERT模型是使用屏蔽任務進行預訓練的,因此我們可以使用它來預測“ Die”還是“ DAT”是否可能更有可能。該實驗表明,羅伯特(Robbert)與其他模型有關荷蘭人的更多信息。
| 模型 | 準確性 [%] |
|---|---|
| Zeror | 66.70 |
| 姆伯特 | 90.21 |
| Bertje | 94.94 |
| 羅伯特V2 | 98.75 |
使用矮小的UD數據集。
| 模型 | 準確性 [%] |
|---|---|
| 青蛙 | 91.7 |
| 姆伯特 | 96.5 |
| Bertje | 96.3 |
| 羅伯特V2 | 96.4 |
有趣的是,我們發現,在處理小型數據集時,Robbert V2顯著優於其他模型。
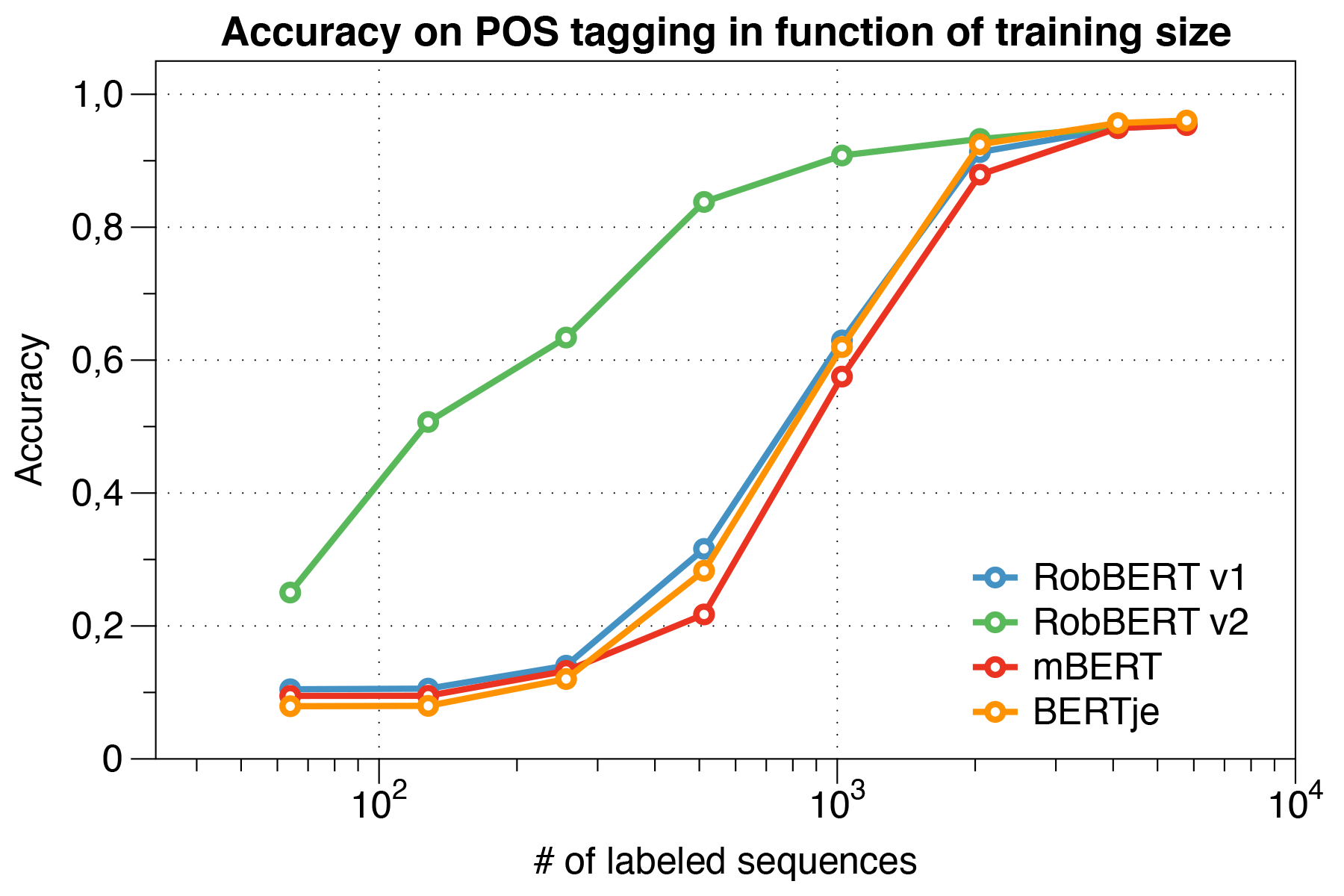
使用Conll 2002評估腳本。
| 模型 | 準確性 [%] |
|---|---|
| 青蛙 | 57.31 |
| 姆伯特 | 90.94 |
| Bert-NL | 89.7 |
| Bertje | 88.3 |
| 羅伯特V2 | 89.08 |
我們使用羅伯塔培訓制度預先培訓羅伯特。我們在奧斯卡語料庫的“荷蘭”部分上預先培訓了我們的模型,這是一種大型多語種語料庫,是通過普通爬網語料庫中語言分類獲得的。該荷蘭語料庫的大量為39GB,有66億個單詞分佈超過1.26億行文本,其中每條線可能包含多個句子,因此使用比同時開發的荷蘭BERT模型的數據更多。
羅伯特(Robbert)與羅伯塔(Roberta)的基本模型分享了其建築,這本身就是對伯特(Bert)的複制和改進。像伯特一樣,它的架構包括12個自我發揮作用層,其中12個頭,可訓練的參數為1.17億。與原始BERT模型的區別是,僅使用MLM任務而不是NSP任務,由Roberta指定的不同的預訓練任務。因此,在預訓練期間,它僅預測在給定句子的某些位置掩蓋了哪些單詞。訓練過程使用ADAM優化器與學習率L_R = 10^-6的多項式衰減,並且升高期為1000迭代,而超參數beta_1 = 0.9和Roberta的默認beta_2 = 0.98。此外,重量衰減為0.1,少量輟學有助於防止模型過度擬合。
羅伯特(Robbert)在每個節點上具有4個NVIDIA P100 GPU的計算群集上訓練,其中節點的數量在保持固定批次大小為8192句子的同時,進行了動態調整。最多使用20個節點(即80 GPU),中位數為5個節點。通過使用梯度積累,可以獨立於可用的GPU數量設置批量大小,以最大程度地利用群集。使用Fairseq庫,對兩個時期進行了訓練的模型,該模型總計超過16K批量,在計算集群上花費了大約三天的時間。在計算集群上的培訓工作之間,2 NVIDIA 1080 TI還涵蓋了Robbert V2的一些參數更新。
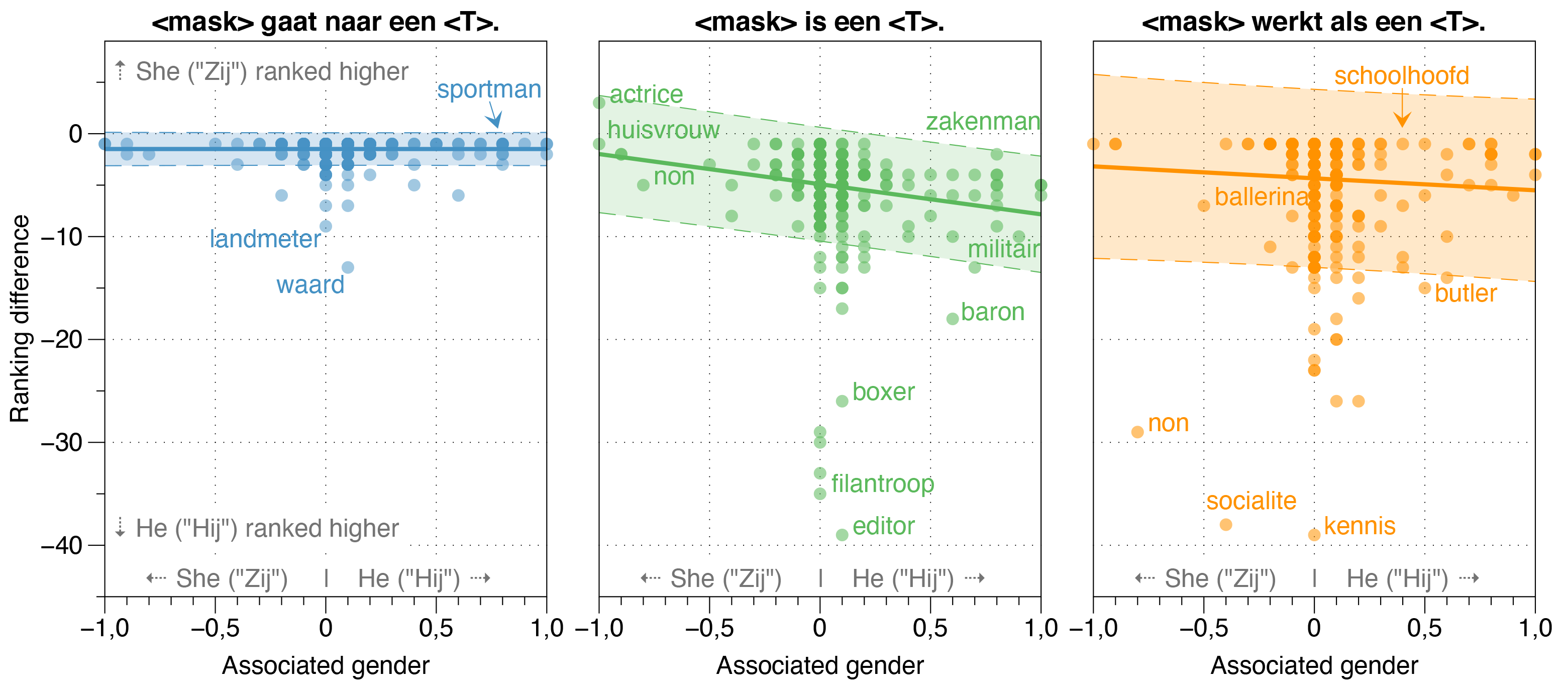
在羅伯特論文中,我們還研究了羅伯特的潛在偏見來源。
我們發現,Zeroshot模型估計HIJ (HE)的可能性高於Zij (SHE),對於大多數職業,在漂白模板句子中,無論其實際性別性別比率如何。
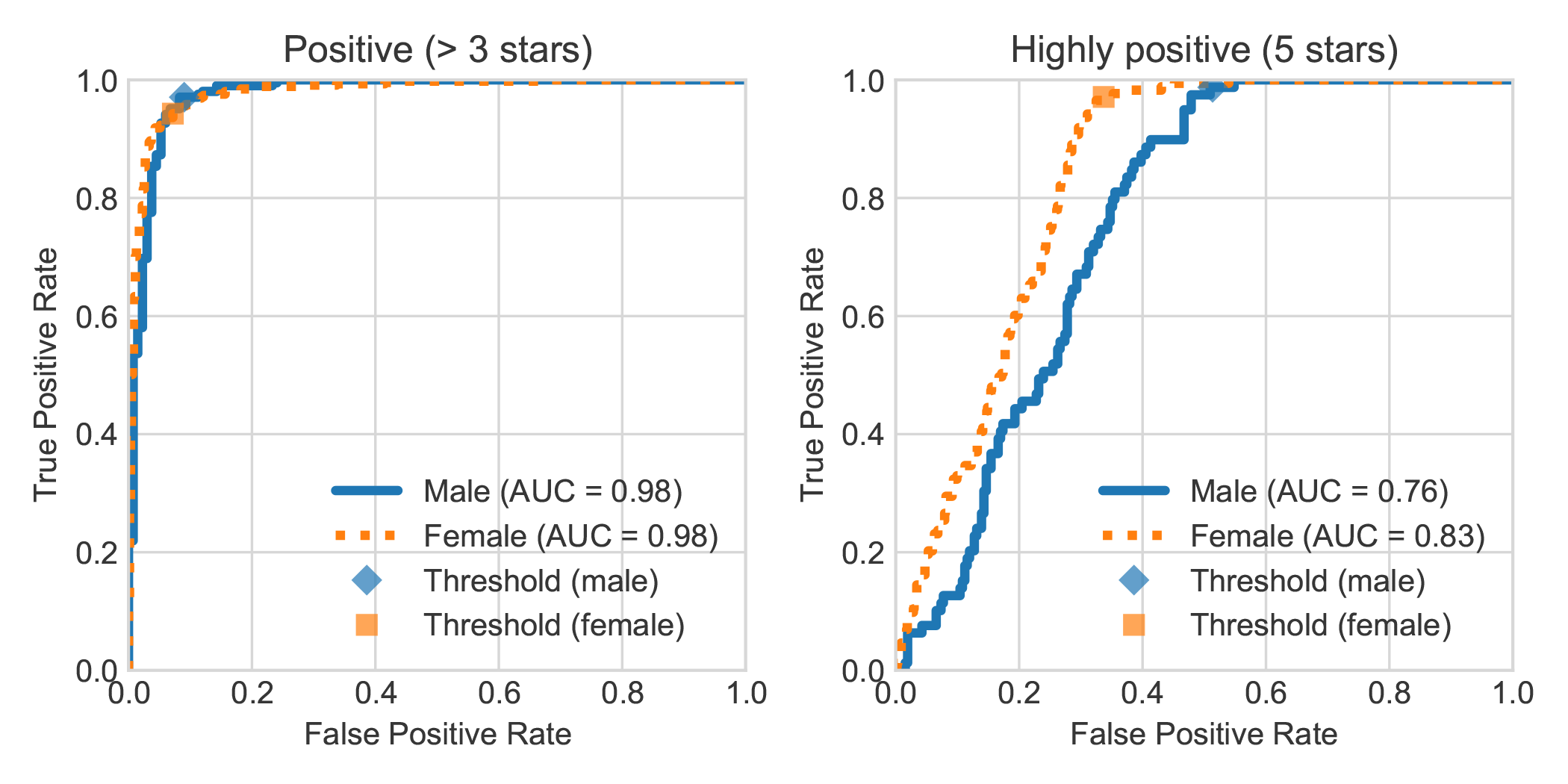
通過以審查作者的陳述性別來增強DBRB荷蘭書籍情緒分析數據集,我們發現,女性所寫的高度正面評論通常被羅伯特(Robbert)更準確地檢測到比男性所寫的正面評論。
您可以通過遵循以下步驟來複製論文中完成的實驗。您可以安裝所需的依賴項。 txt或pipenv:
pip install -r requirements.txt從unignts.txt文件中安裝依賴項。 txtpip install pipenv PIPENV pipenv install )。在本節中,我們描述瞭如何使用我們提供的腳本進行微調模型,該腳本應該足夠通用,可以重複使用其他所需的文本分類任務。
data/raw/DBRDsrc/preprocess_dbrd.py來準備數據集。src/split_dbrd_training.sh 。notebooks/finetune_dbrd.ipynb進行填充模型。 我們對荷蘭歐洲語料庫進行微調。您可以首先下載以下方式:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
作為理智檢查,現在您應該在data/raw/europarl文件夾中擁有以下文件:
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
然後,您可以使用以下腳本運行預處理,該腳本填充了Europarl語料庫的第一個過程,以刪除句子而無需任何死亡或DAT 。之後,它將翻轉代詞,並將兩個句子與<sep>令牌一起加入。
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
注意:您可以使用watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences監視第一個預處理步驟的進度。這將需要一段時間,但是當然不需要使用所有輸入。畢竟,這就是為什麼您要使用預訓練的語言模型的原因。您可以隨時終止Python腳本,第二步只會使用這些腳本。
大多數伯特(Bert)的模特都以其名稱伯特(Bert)一詞(例如羅伯塔(Roberta),阿爾伯特(Albert),卡梅蒙德(Camembert)以及許多其他許多人)。因此,我們使用蒙版語言模型查詢了新訓練的模型,以使用各種提示來命名<mask> bert ,並一直稱為Robbert。鑑於羅伯特是一個非常荷蘭語的名字(因此顯然是荷蘭語模型) ,我們認為這確實很合適,而且與羅伯塔(Roberta)的根架構(即其根源建築)具有很高的相似性。
由於“ Rob”是表示印章的荷蘭語單詞,因此我們決定畫一封印章,並像從芝麻街的貝特(Bert)打扮成羅伯特(Robbert)徽標一樣。
該項目由Pieter Delobelle,Thomas Winters和Bettina Berendt創建。
我們感謝Liesbeth Allein,因為她在Die-Dat Disampuation上的工作,為他們的Transformer Package,Facebook的Facebeel for Fairseq套餐以及我們可以使用的所有工作的所有人。
我們在MIT下發布模型和此代碼。
如果您想引用我們的論文或模型,則可以使用以下Bibtex代碼:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


