RobBERT
v2.0

Robbert es el modelo de Bert holandés de última generación. Es un gran modelo de lenguaje holandés general previamente entrenado que se puede ajustar en un conjunto de datos determinado para realizar cualquier tarea de clasificación de texto, regresión o etiqueta de token. Como tal, muchos investigadores y profesionales lo han utilizado con éxito para lograr un desempeño de última generación para una amplia gama de tareas de procesamiento del lenguaje natural holandés, que incluyen:
y también logró resultados sobresalientes y cercanos a Sota para:
* Tenga en cuenta que varias evaluaciones usan Robbert-V1, y que el segundo y mejorado Robbert-V2 supera a este primer modelo en todo lo que probamos
(Tenga en cuenta que esta lista no es exhaustiva. Si usó Robbert para su solicitud, ¡nos complace saberlo! ¡Envíenos un correo o agréguelo usted mismo a esta lista enviando una solicitud de extracción con la edición!)
Para usar el modelo Robbert utilizando los transformadores Huggingface, use el nombre pdelobelle/robbert-v2-dutch-base .
Se puede encontrar información más detallada sobre Robbert en nuestra publicación de blog y en nuestro artículo.
Robbert utiliza la arquitectura de Roberta y el pre-entrenamiento, pero con un tokenizador holandés y datos de capacitación. Roberta es el modelo de Bert inglés sólido optimizado, lo que lo hace aún más poderoso que el modelo Bert original. Dada esta misma arquitectura, Robbert puede ser fácilmente fingido e inferenciado utilizando el código para Finetune Roberta y la mayoría del código utilizado para los modelos BERT, por ejemplo, según lo proporcionado por Huggingface Transformers Library.
Robbert se puede usar fácilmente de dos maneras diferentes, a saber, utilizando el código Fairseq Roberta o usando Huggingface Transformers
Por defecto, Robbert tiene el cabezal de modelo de lenguaje enmascarado utilizado en la capacitación. Esto se puede usar como una forma de disparo cero para llenar las máscaras en las oraciones. Se puede probar de forma gratuita en la API de inferencia alojada de Robbert de Huggingface. También puede crear un nuevo cabezal de predicción para su propia tarea utilizando cualquiera de los corredores de Roberta de Huggingface, sus cuadernos ajustados cambiando el nombre del modelo a pdelobelle/robbert-v2-dutch-base , o utilizar los regímenes de entrenamiento originales de Fairseq Roberta.
¿Puede descargar fácilmente Robbert V2 usando? Transformadores. Use el siguiente código para descargar el modelo base y finetune usted mismo, o use uno de nuestros modelos Finetuned (documentado en nuestro sitio del proyecto).
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) Comenzando con transformers v2.4.0 (o instalando desde la fuente), puede usar AutoTokenizer y Automodel. Luego puede usar la mayoría de los cuadernos con sede en Bert de Huggingface para Finetuning Robbert en su tipo de conjunto de datos de idiomas holandeses.
Alternativamente, también puede usar Robbert utilizando el código de arquitectura de Roberta. Puede descargar el modelo FairSeq de Robbert V2 aquí: (Robbert-Base, 1.5 GB). Utilizando Robbert's model.pt , este método le permite usar todas las demás funcionalidades de Roberta.
Todos los experimentos se describen con más detalle en nuestro documento, con el código en nuestro repositorio de GitHub.
Predecir si una revisión es positiva o negativa utilizando el conjunto de datos de revisiones de libros holandeses.
| Modelo | Exactitud [%] |
|---|---|
| Ulmfit | 93.8 |
| Bertje | 93.0 |
| Robbert V2 | 95.1 |
Medimos qué tan bien los modelos pueden hacer una resolución de coreferencia al predecir si "morir" o "dat" debe llenarse en una oración. Para esto, utilizamos el Corpus Europarl.
| Modelo | Exactitud [%] | F1 [%] |
|---|---|---|
| Línea de base (LSTM) | 75.03 | |
| mbert | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| Robbert V2 | 99.232 | 99.121 |
También medimos el rendimiento utilizando solo 10k ejemplos de entrenamiento. Este experimento ilustra claramente que Robbert supera a otros modelos cuando hay pocos datos disponibles.
| Modelo | Exactitud [%] | F1 [%] |
|---|---|---|
| mbert | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| Robbert V2 | 97.816 | 97.514 |
Dado que los modelos BERT se entrenan previamente utilizando la tarea de enmascaramiento de palabras, podemos usar esto para predecir si "morir" o "dat" es más probable. Este experimento muestra que Robbert ha internalizado más información sobre holandés que otros modelos.
| Modelo | Exactitud [%] |
|---|---|
| Zeror | 66.70 |
| mbert | 90.21 |
| Bertje | 94.94 |
| Robbert V2 | 98.75 |
Usando el conjunto de datos UD Lassy.
| Modelo | Exactitud [%] |
|---|---|
| Rana | 91.7 |
| mbert | 96.5 |
| Bertje | 96.3 |
| Robbert V2 | 96.4 |
Curiosamente, descubrimos que cuando se trata de pequeños conjuntos de datos , Robbert V2 supera significativamente a otros modelos.
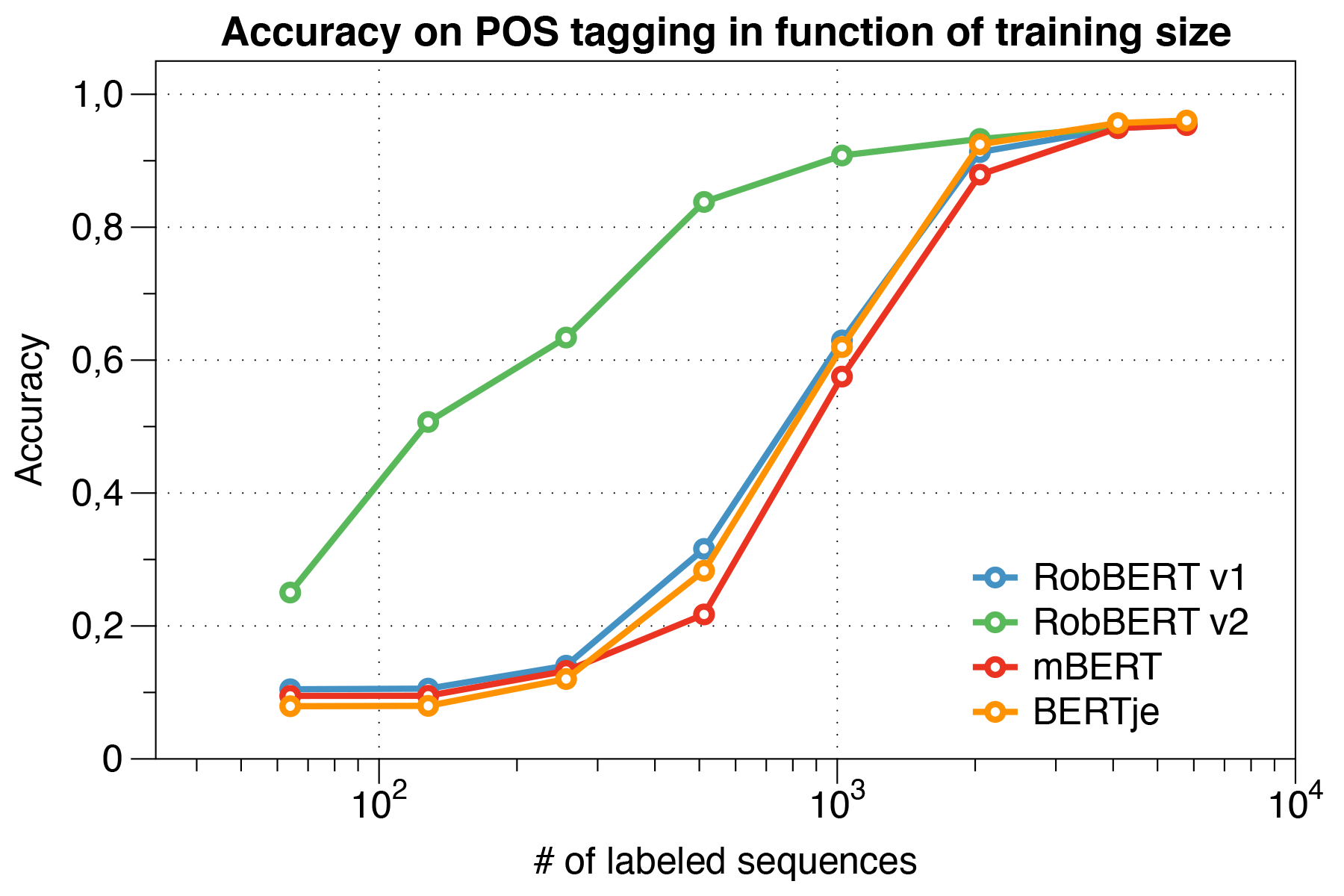
Utilizando el script de evaluación de Conll 2002.
| Modelo | Exactitud [%] |
|---|---|
| Rana | 57.31 |
| mbert | 90.94 |
| Bert-nl | 89.7 |
| Bertje | 88.3 |
| Robbert V2 | 89.08 |
Pre-capacitamos Robbert usando el régimen de entrenamiento de Roberta. Pre-capacitamos nuestro modelo en la sección holandesa del Corpus Oscar, un gran corpus multilingüe que se obtuvo por clasificación de idiomas en el Corpus de Crawl Common. Este corpus holandés es de 39 GB grande, con 6.600 millones de palabras repartidas en 126 millones de líneas de texto, donde cada línea podría contener múltiples oraciones, utilizando así más datos que los modelos Bert holandeses desarrollados simultáneamente.
Robbert comparte su arquitectura con el modelo base de Roberta, que es una replicación y una mejora sobre Bert. Al igual que Bert, su arquitectura consta de 12 capas de autoatimiento con 12 cabezas con 117m parámetros capacitables. Una diferencia con el modelo Bert original se debe a la diferente tarea de pre-entrenamiento especificada por Roberta, utilizando solo la tarea MLM y no la tarea NSP. Durante la capacitación previa, solo predice qué palabras están enmascaradas en ciertas posiciones de oraciones dadas. El proceso de entrenamiento utiliza el Optimizador de Adam con desintegración polinomial de la tasa de aprendizaje l_r = 10^-6 y un período de aumento de 1000 iteraciones, con hiperparametros beta_1 = 0.9 y el valor predeterminado de Roberta Beta_2 = 0.98. Además, una descomposición de peso de 0.1 y un pequeño abandono de 0.1 ayuda a evitar que el modelo se sobreajuste.
Robbert fue entrenado en un clúster informático con 4 GPU P100 NVIDIA por nodo, donde el número de nodos se ajustó dinámicamente mientras mantenía un tamaño de lote fijo de 8192 oraciones. En la mayoría de los 20 nodos se usaron (es decir, 80 GPU), y la mediana era de 5 nodos. Al usar la acumulación de gradiente, el tamaño del lote podría establecerse independientemente del número de GPU disponibles, para utilizar al máximo el clúster. Utilizando la biblioteca Fairseq, el modelo entrenó para dos épocas, lo que equivale a más de 16k lotes en total, que tomó aproximadamente tres días en el clúster informático. Entre los trabajos de capacitación en el clúster informático, 2 Nvidia 1080 TI también cubrieron algunas actualizaciones de parámetros para Robbert V2.
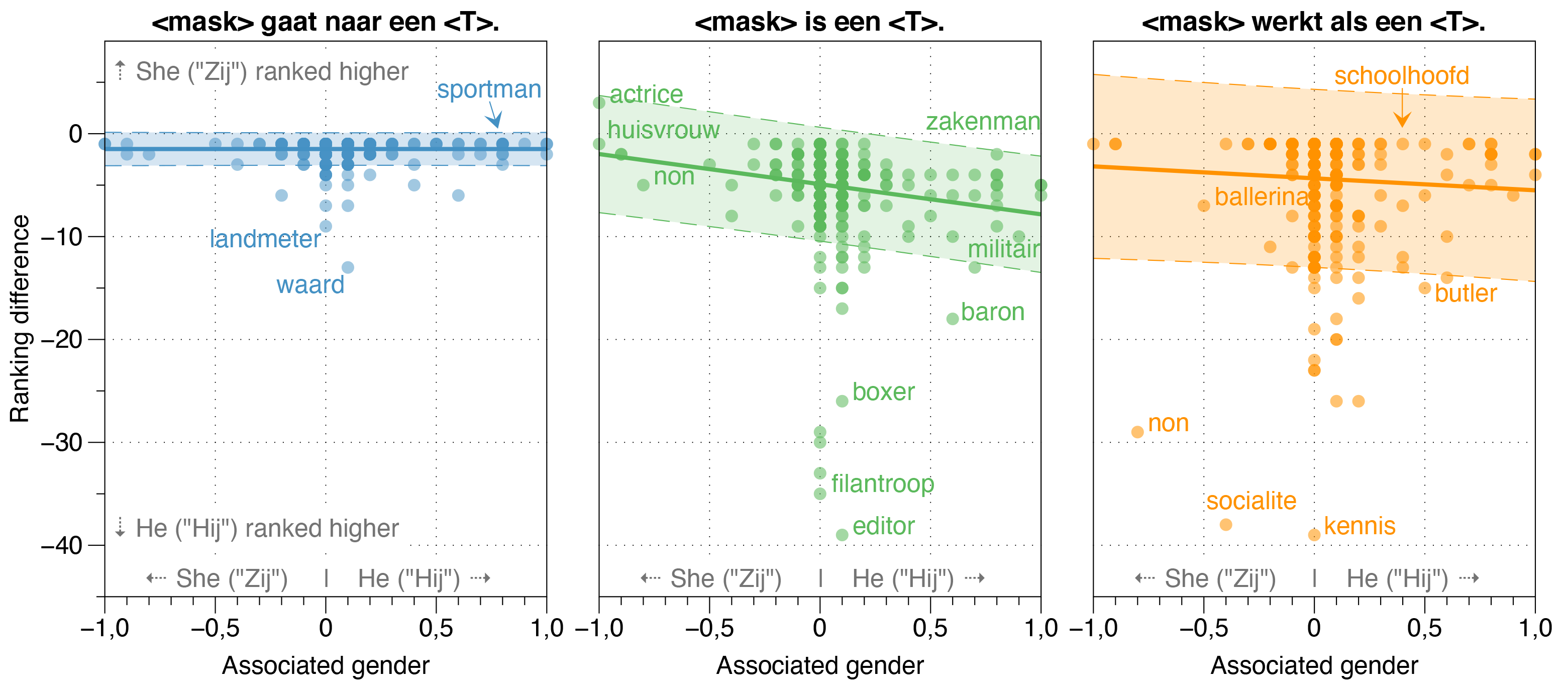
En el documento de Robbert, también investigamos posibles fuentes de sesgo en Robbert.
Descubrimos que el modelo de Zeroshot estima que la probabilidad de Hij (él) es más alta que Zij (ella) para la mayoría de las ocupaciones en oraciones de plantilla blanqueadas, independientemente de su relación de género de trabajo real en realidad.
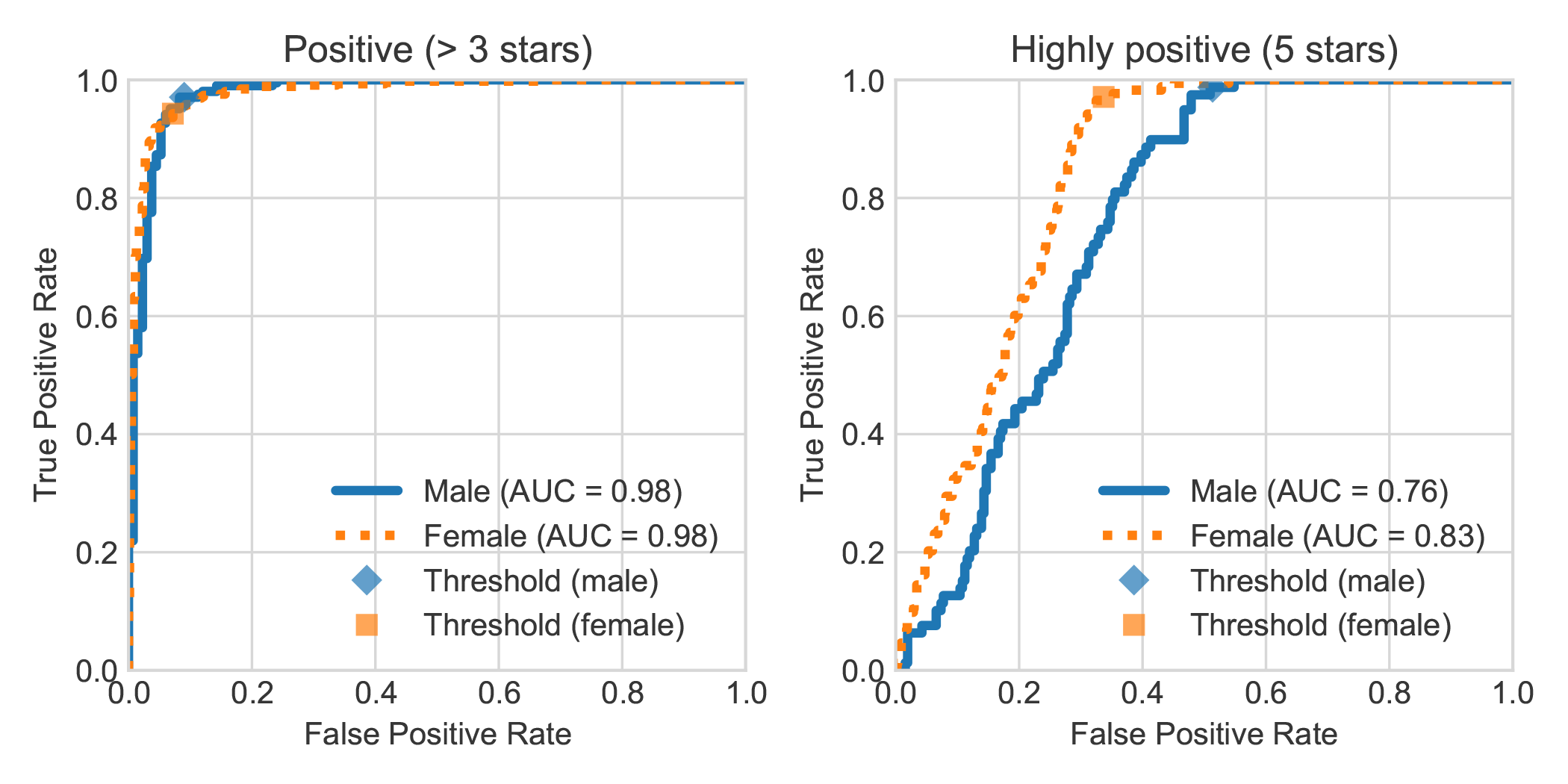
Al aumentar el conjunto de datos de análisis de sentimientos del libro holandés DBRB con el género declarado del autor de la revisión, encontramos que las revisiones altamente positivas escritas por las mujeres generalmente fueron detectadas con mayor precisión por Robbert como positivas que las escritas por los hombres.
Puede replicar los experimentos realizados en nuestro artículo siguiendo los siguientes pasos. Puede instalar las dependencias requeridas, ya sea requisitos.txt o pipenv:
pip install -r requirements.txtpip install pipenv en su terminal) ejecutando pipenv install .En esta sección describimos cómo usar los scripts que proporcionamos para ajustar los modelos, que deberían ser lo suficientemente generales como para reutilizar otras tareas de clasificación textual deseadas.
data/raw/DBRDsrc/preprocess_dbrd.py para preparar el conjunto de datos.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb para Finetune el modelo. Atinamos nuestro modelo en el Corpus Europarl holandés. Puedes descargarlo primero con:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
Como verificación de cordura, ahora debe tener los siguientes archivos en su carpeta data/raw/europarl :
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
Luego puede ejecutar el preprocesamiento con el siguiente script, que llena el primer proceso del Europarl Corpus para eliminar las oraciones sin ningún dado o DAT . Posteriormente, volteará el pronombre y unirá ambas oraciones junto con un token <sep> .
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
Nota: Puede monitorear el progreso del primer paso de preprocesamiento con watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences . Esto llevará un tiempo, pero ciertamente no es necesario usar todas las entradas. Después de todo, esta es la razón por la que desea utilizar un modelo de lenguaje previamente capacitado. Puede finalizar el script de Python en cualquier momento y el segundo paso solo los usará.
La mayoría de los modelos tipo Bert tienen la palabra Bert en su nombre (por ejemplo, Roberta, Albert, Camembert y muchos, muchos otros). Como tal, consultamos nuestro modelo recién entrenado utilizando su modelo de lenguaje enmascarado para nombrarse <mask> Bert usando todo tipo de indicaciones, y se llamó constantemente Robbert. Pensamos que era realmente apropiado, dado que Robbert es un nombre muy holandés (y por lo tanto, claramente un modelo de lenguaje holandés) , y además tiene una alta similitud con su arquitectura raíz, a saber, Roberta.
Dado que "Rob" son palabras holandesas para denotar un sello, decidimos dibujar un sello y vestirlo como Bert de Sesame Street para el logotipo de Robbert.
Este proyecto es creado por Pieter Delobelle, Thomas Winters y Bettina Berendt.
Estamos agradecidos con Liesbeth Allein, por su trabajo en desambiguación de di-diatante, Huggingface por su paquete Transformer, Facebook por su paquete Fairseq y todas las demás personas cuyo trabajo podríamos usar.
Lanzamos nuestros modelos y este código en MIT.
Si desea citar nuestro documento o modelo, puede usar el siguiente código Bibtex:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


