RobBERT
v2.0

Robbert هو نموذج بيرت الهولندي الحديث. إنه نموذج اللغة الهولندي العام الكبير الذي تم تدريبه مسبقًا يمكن ضبطه على مجموعة بيانات معينة لإجراء أي تصنيف نص أو مهمة تراجع أو مهمة رمزية. على هذا النحو ، تم استخدامه بنجاح من قبل العديد من الباحثين والممارسين لتحقيق أداء أحدث من أجل مجموعة واسعة من مهام معالجة اللغة الطبيعية الهولندية ، بما في ذلك:
وحققت أيضًا نتائج رائعة ، قريبة من السوتا لـ:
* لاحظ أن العديد من التقييمات تستخدم Robbert-V1 ، وأن Robbert-V2 الثاني والمحسن يتفوق على هذا النموذج الأول على كل ما قمنا باختباره
(لاحظ أيضًا أن هذه القائمة ليست شاملة. إذا استخدمت Robbert لتطبيقك ، يسعدنا أن نعرفها! أرسل إلينا بريدًا ، أو أضفها بنفسك إلى هذه القائمة عن طريق إرسال طلب سحب باستخدام التحرير!)
لاستخدام نموذج Robbert باستخدام محولات HuggingFace ، استخدم اسم pdelobelle/robbert-v2-dutch-base .
يمكن العثور على المزيد من المعلومات المتعمقة حول Robbert في منشور المدونة لدينا وفي ورقتنا.
يستخدم Robbert الهندسة المعمارية Roberta والتدريب المسبق ولكن مع Tokenizer الهولندي وبيانات التدريب. روبرتا هو طراز Bert الإنجليزي المحسن بقوة ، مما يجعله أكثر قوة من نموذج Bert الأصلي. بالنظر إلى نفس الهندسة المعمارية ، يمكن بسهولة استنتاج Robbert واستنتاجها باستخدام رمز إلى نماذج Finetune Roberta ومعظم التعليمات البرمجية المستخدمة في نماذج BERT ، على سبيل المثال مقدمة من مكتبة Huggingface Transformers.
يمكن بسهولة استخدام Robbert بطريقتين مختلفتين ، أي إما باستخدام كود Fairseq Roberta أو باستخدام محولات Huggingface
بشكل افتراضي ، لدى Robbert رأس نموذج اللغة المقنعة المستخدم في التدريب. يمكن استخدام هذا كوسيلة صفرية لملء الأقنعة في الجمل. يمكن اختباره مجانًا على API المستضافة من Robbert من Luggingface. يمكنك أيضًا إنشاء رأس تنبؤ جديد لمهمتك الخاصة باستخدام أي من Roberta Runners في Huggingface ، أو أجهزة الكمبيوتر المحمولة الخاصة بهم من خلال تغيير اسم النموذج إلى pdelobelle/robbert-v2-dutch-base ، أو استخدام أنظمة تدريب Fairseq Roberta الأصلية.
يمكنك بسهولة تنزيل Robbert V2 باستخدام؟ محولات. استخدم الكود التالي لتنزيل النموذج الأساسي و Finetune It بنفسك ، أو استخدم أحد طرزنا المحرقة (الموثقة على موقع المشروع لدينا).
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) بدءًا من transformers v2.4.0 (أو التثبيت من المصدر) ، يمكنك استخدام Autotokenizer و Automodel. يمكنك بعد ذلك استخدام معظم أجهزة الكمبيوتر المحمولة المستندة إلى Bert في Huggingface للتأثير على Robbert على نوع مجموعة بيانات اللغة الهولندية.
بدلاً من ذلك ، يمكنك أيضًا استخدام Robbert باستخدام رمز Architecture Roberta. يمكنك تنزيل نموذج FairSeq من Robbert V2 هنا: (Robbert-Base ، 1.5 GB). باستخدام نموذج Robbert's model.pt ، تتيح لك هذه الطريقة استخدام جميع الوظائف الأخرى لروبرتا.
يتم وصف جميع التجارب بمزيد من التفصيل في ورقتنا ، مع الكود في مستودع GitHub الخاص بنا.
التنبؤ بما إذا كانت المراجعة إيجابية أو سلبية باستخدام مجموعة بيانات مراجعة الكتب الهولندية.
| نموذج | دقة [٪] |
|---|---|
| Ulmfit | 93.8 |
| بيرتي | 93.0 |
| روببرت V2 | 95.1 |
قمنا بقياس مدى قدرة النماذج على القيام بدقة Coreference من خلال التنبؤ بما إذا كان ينبغي ملء "DIE" أو "DAT" في جملة. لهذا ، استخدمنا مجموعة Europarl.
| نموذج | دقة [٪] | F1 [٪] |
|---|---|---|
| خط الأساس (LSTM) | 75.03 | |
| Mbert | 98.285 | 98.033 |
| بيرتي | 98.268 | 98.014 |
| روببرت V2 | 99.232 | 99.121 |
قمنا أيضًا بقياس الأداء باستخدام أمثلة تدريب 10K فقط. توضح هذه التجربة بوضوح أن Robbert يتفوق على النماذج الأخرى عندما يكون هناك القليل من البيانات المتاحة.
| نموذج | دقة [٪] | F1 [٪] |
|---|---|---|
| Mbert | 92.157 | 90.898 |
| بيرتي | 93.096 | 91.279 |
| روببرت V2 | 97.816 | 97.514 |
نظرًا لأن نماذج BERT تدربت مسبقًا باستخدام مهمة إخفاء الكلمات ، يمكننا استخدام هذا للتنبؤ بما إذا كان "Die" أو "DAT" أكثر احتمالًا. توضح هذه التجربة أن Robbert قد استوعب المزيد من المعلومات حول الهولنديين أكثر من النماذج الأخرى.
| نموذج | دقة [٪] |
|---|---|
| زيرور | 66.70 |
| Mbert | 90.21 |
| بيرتي | 94.94 |
| روببرت V2 | 98.75 |
باستخدام مجموعة بيانات UD Lassy.
| نموذج | دقة [٪] |
|---|---|
| ضفدع | 91.7 |
| Mbert | 96.5 |
| بيرتي | 96.3 |
| روببرت V2 | 96.4 |
ومن المثير للاهتمام ، وجدنا أنه عند التعامل مع مجموعات البيانات الصغيرة ، يتفوق Robbert V2 بشكل كبير على النماذج الأخرى.
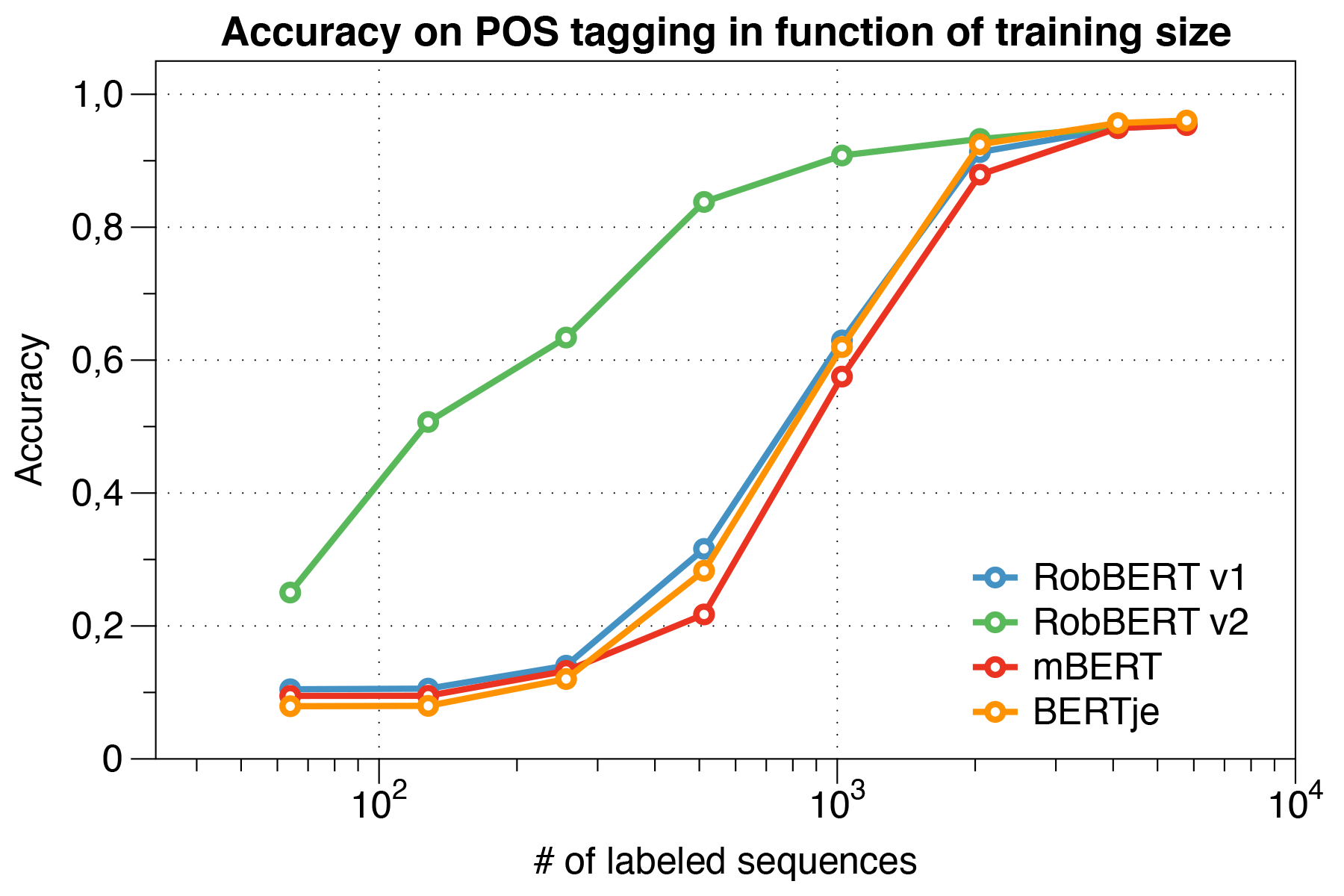
باستخدام البرنامج النصي لتقييم CONLL 2002.
| نموذج | دقة [٪] |
|---|---|
| ضفدع | 57.31 |
| Mbert | 90.94 |
| Bert-NL | 89.7 |
| بيرتي | 88.3 |
| روببرت V2 | 89.08 |
قمنا بتدريب Robbert مسبقًا باستخدام نظام تدريب Roberta. قمنا بتدريب نموذجنا مسبقًا على القسم الهولندي من جسم أوسكار ، وهو مجموعة كبيرة متعددة اللغات تم الحصول عليها من خلال تصنيف اللغة في مجموعة الزحف المشتركة. هذا المجموعة الهولندية كبيرة 39 جيجابايت ، مع 6.6 مليار كلمة منتشرة أكثر من 126 مليون سطر من النص ، حيث يمكن أن يحتوي كل سطر على جمل متعددة ، وبالتالي باستخدام بيانات أكثر من نماذج Bert الهولندية التي تم تطويرها بشكل متزامن.
تشارك Robbert الهندسة المعمارية مع نموذج Roberta الأساسي ، والذي هو في حد ذاته عبارة عن تكرار وتحسين على Bert. مثل Bert ، تتكون الهندسة المعمارية من 12 طبقة من التصلب الذاتي مع 12 رأسًا مع 117 متر معلمة قابلة للتدريب. يرجع أحد الاختلافات في نموذج BERT الأصلي إلى مهمة ما قبل التدريب المختلفة التي حددها Roberta ، باستخدام مهمة MLM فقط وليس مهمة NSP. أثناء التدريب المسبق ، فإنه يتنبأ فقط بالكلمات التي يتم إخفاءها في مواقع معينة من الجمل المعطاة. تستخدم عملية التدريب محسّن آدم مع تحلل متعدد الحدود لمعدل التعلم L_R = 10^-6 وفترة زيادة قدرها 1000 تكرار ، مع أجهزة PHINPARAMETERS BETA_1 = 0.9 وروبرتا الافتراضية Beta_2 = 0.98. بالإضافة إلى ذلك ، يساعد تسوس الوزن البالغ 0.1 وتسرب صغير قدره 0.1 على منع النموذج من التورط.
تم تدريب Robbert على مجموعة الحوسبة مع 4 NVIDIA P100 GPU لكل عقدة ، حيث تم تعديل عدد العقد ديناميكيًا مع الحفاظ على حجم دفعة ثابتة قدرها 8192 جملة. تم استخدام 20 عقدًا على الأكثر (أي 80 وحدة معالجة الرسومات) ، وكان الوسيط 5 عقد. باستخدام تراكم التدرج ، يمكن ضبط حجم الدُفعة بشكل مستقل عن عدد وحدات معالجة الرسومات المتاحة ، من أجل استخدام الكتلة بشكل أقصى. باستخدام مكتبة Fairseq ، تم تدريب النموذج على عصرين ، وهو ما يساوي أكثر من 16 ألف دفعات في المجموع ، والتي استغرقت حوالي ثلاثة أيام على مجموعة الحوسبة. بين الوظائف التدريبية على مجموعة الحوسبة ، غطت 2 Nvidia 1080 TI أيضًا بعض تحديثات المعلمات لـ Robbert V2.
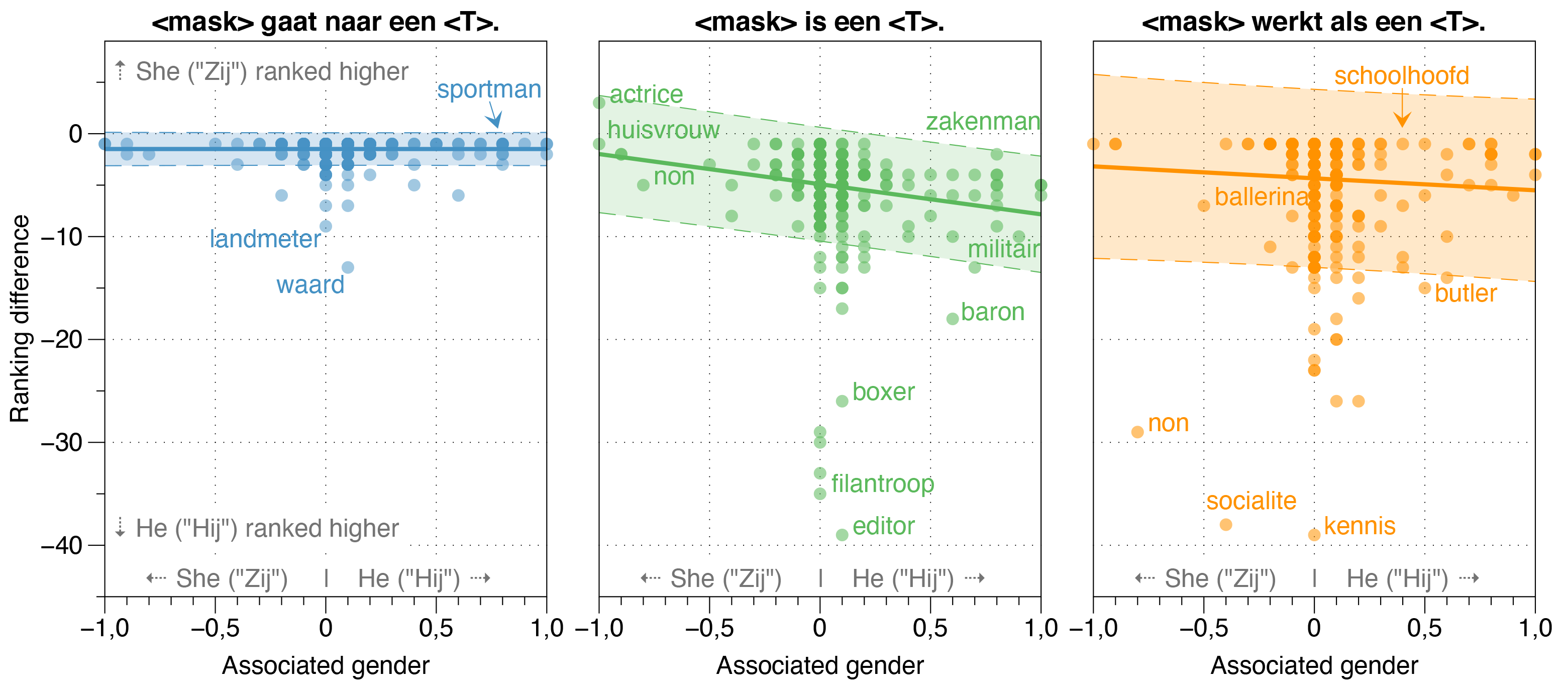
في ورقة Robbert ، حققنا أيضًا في مصادر التحيز المحتملة في Robbert.
لقد وجدنا أن نموذج Zeroshot يقدر احتمال أن يكون HIJ (HE) أعلى من Zij (SHE) لمعظم المهن في جمل القالب المبيضة ، بغض النظر عن نسبة جنس الوظائف الفعلية في الواقع.
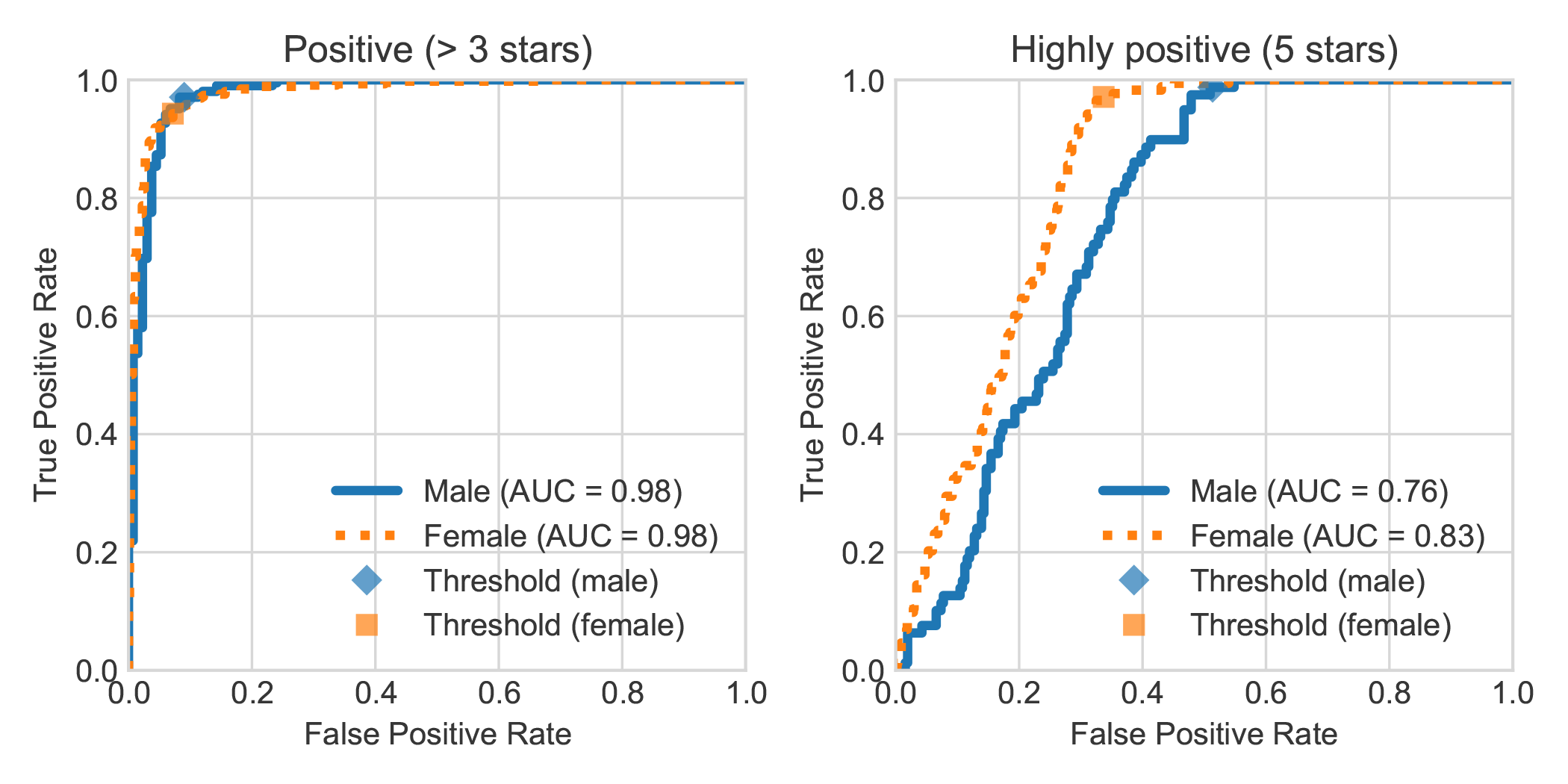
من خلال زيادة مجموعة بيانات DBRB Dutch Book Sentiment Analysis مع الجنس المعلن لمؤلف المراجعة ، وجدنا أن المراجعات الإيجابية للغاية التي كتبتها النساء تم اكتشافها بشكل عام بشكل أكثر دقة من قبل Robbert على أنها إيجابية من تلك التي كتبها الرجال.
يمكنك تكرار التجارب التي أجريت في ورقتنا باتباع الخطوات التالية. يمكنك تثبيت التبعيات المطلوبة إما المتطلبات. txt أو pipenv:
pip install -r requirements.txtpip install pipenv في المحطة الخاصة بك) عن طريق تشغيل pipenv install .في هذا القسم ، نصف كيفية استخدام البرامج النصية التي نقدمها لنماذج ضبطها ، والتي يجب أن تكون عامة بما يكفي لإعادة استخدام مهام التصنيف النصية الأخرى المطلوبة.
data/raw/DBRDsrc/preprocess_dbrd.py لإعداد مجموعة البيانات.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb إلى Finetune النموذج. نحن نتحمل نموذجنا على مجموعة Europarl الهولندية. يمكنك تنزيله أولاً مع:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
كتحقق من العقل ، يجب عليك الآن الحصول على الملفات التالية في مجلد data/raw/europarl :
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
بعد ذلك ، يمكنك تشغيل المعالجة المسبقة باستخدام البرنامج النصي التالي ، والذي يملأ أول معالجة Europarl Corpus لإزالة الجمل دون أي يموت أو DAT . بعد ذلك ، سوف يقلب الضمير وينضم إلى كلتا الجملتين مع رمز <sep> .
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
ملاحظة: يمكنك مراقبة التقدم المحرز في أول خطوة معالجة مسبقة مع watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences . سيستغرق هذا بعض الوقت ، ولكن ليس هناك حاجة بالتأكيد لاستخدام جميع المدخلات. هذا هو السبب في كل شيء تريد استخدام نموذج لغة تم تدريبه مسبقًا. يمكنك إنهاء البرنامج النصي Python في أي وقت وستستخدم الخطوة الثانية هذه.
معظم الطرز التي تشبه بيرت لديها كلمة بيرت باسمها (على سبيل المثال روبرتا ، ألبرت ، كاممبرت ، والعديد من الآخرين). على هذا النحو ، لقد استفسرنا عن نموذجنا المدربين حديثًا باستخدام نموذج لغته المقنعة لتسمية نفسه <scks> Bert باستخدام جميع أنواع المطالبات ، وتسمى نفسها باستمرار Robbert. كنا نظن أنه كان مناسبًا تمامًا ، نظرًا لأن Robbert هو اسم هولندي للغاية (وبالتالي من الواضح أنه نموذج لغة هولندي) ، بالإضافة إلى ذلك ، له تشابه كبير مع بنية الجذر ، وهو روبرتا.
نظرًا لأن "Rob" عبارة عن كلمات هولندية للدلالة على ختم ، فقد قررنا رسم ختم وارتداء ملابسه مثل Bert من Sesame Street لشعار Robbert.
تم إنشاء هذا المشروع بواسطة Pieter Delobelle و Thomas Winters و Bettina Berendt.
نحن ممتنون لـ Liesbeth Allein ، على عملها على عدم التغذية المميتة ، وعانقهم على حزمة المحولات الخاصة بهم ، و Facebook لحزمة FairSeq الخاصة بهم وجميع الأشخاص الآخرين الذين يمكننا استخدام عملهم.
نصدر نماذجنا وهذا الرمز ضمن معهد ماساتشوستس للتكنولوجيا.
إذا كنت ترغب في الاستشهاد بالورق أو النموذج الخاص بنا ، فيمكنك استخدام رمز Bibtex التالي:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


