RobBERT
v2.0

Robbert est le modèle de Bert néerlandais de pointe. Il s'agit d'un grand modèle de langage néerlandais général pré-formé qui peut être affiné sur un ensemble de données donné pour effectuer toute tâche de classification, de régression ou de token de texte. En tant que tel, il a été utilisé avec succès par de nombreux chercheurs et praticiens pour obtenir des performances de pointe pour un large éventail de tâches de traitement du langage naturel néerlandais, notamment:
et a également obtenu des résultats proches en Sota exceptionnels pour:
* Notez que plusieurs évaluations utilisent Robbert-V1, et que le deuxième et amélioré Robbert-V2 surpasse ce premier modèle sur tout ce que nous avons testé
(Notez également que cette liste n'est pas exhaustive. Si vous avez utilisé Robbert pour votre application, nous sommes heureux de le savoir! Envoyez-nous un courrier ou ajoutez-le vous-même à cette liste en envoyant une demande de traction avec le montage!)
Pour utiliser le modèle Robbert à l'aide de Transformers HuggingFace, utilisez le nom pdelobelle/robbert-v2-dutch-base .
Des informations plus approfondies sur Robbert peuvent être trouvées dans notre article de blog et dans notre article.
Robbert utilise l'architecture Roberta et la pré-formation mais avec un tokenzer néerlandais et des données de formation. Roberta est le modèle BERT anglais à optimisation robuste, ce qui le rend encore plus puissant que le modèle Bert d'origine. Compte tenu de cette même architecture, Robbert peut facilement être finetuné et déduit en utilisant du code pour les modèles Finetune Roberta et la plupart du code utilisé pour les modèles Bert, par exemple, comme fourni par la bibliothèque de transformateurs HuggingFace.
Robbert peut facilement être utilisé de deux manières différentes, à savoir l'utilisation du code Fairseq Roberta, soit en utilisant des transformateurs HuggingFace
Par défaut, Robbert a la tête de modèle de langue masquée utilisée dans la formation. Cela peut être utilisé comme un moyen zéro pour remplir des masques en phrases. Il peut être testé gratuitement sur l'API inférieure hébergée de Robbert de Huggingface. Vous pouvez également créer un nouveau chef de prédiction pour votre propre tâche en utilisant l'un des Roberta-Runners de HuggingFace, leurs cahiers de réglage fin en modifiant le nom du modèle en bases de pdelobelle/robbert-v2-dutch-base , ou utiliser les régimes de formation d'origine Fairseq Roberta.
Vous pouvez facilement télécharger Robbert V2 en utilisant? Transformateurs. Utilisez le code suivant pour télécharger le modèle de base et Finetune It vous-même, ou utiliser l'un de nos modèles à finet (documenté sur notre site de projet).
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) En commençant par transformers v2.4.0 (ou en installation à partir de la source), vous pouvez utiliser Autotokenzer et Automodel. Vous pouvez ensuite utiliser la plupart des ordinateurs portables basés sur BertFace pour Finetuning Robbert sur votre type d'ensemble de données de langage néerlandais.
Alternativement, vous pouvez également utiliser Robbert en utilisant le code d'architecture Roberta. Vous pouvez télécharger le modèle Fairseq de Robbert V2 ici: (Robbert-base, 1,5 Go). À l'aide de Robbert's model.pt , cette méthode vous permet d'utiliser toutes les autres fonctionnalités de Roberta.
Toutes les expériences sont décrites plus en détail dans notre article, avec le code dans notre référentiel GitHub.
Prédire si une revue est positive ou négative à l'aide de l'ensemble de données des critiques de livres néerlandais.
| Modèle | Précision [%] |
|---|---|
| Ulmfit | 93.8 |
| Bertje | 93.0 |
| Robbert V2 | 95.1 |
Nous avons mesuré dans quelle mesure les modèles sont capables de faire une résolution de coréférence en prédisant si "mourir" ou "dat" doit être rempli en phrase. Pour cela, nous avons utilisé le corpus Europarl.
| Modèle | Précision [%] | F1 [%] |
|---|---|---|
| Baseline (LSTM) | 75.03 | |
| Mbert | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| Robbert V2 | 99.232 | 99.121 |
Nous avons également mesuré les performances en utilisant seulement 10 000 exemples de formation. Cette expérience illustre clairement que Robbert surpasse les autres modèles lorsqu'il y a peu de données disponibles.
| Modèle | Précision [%] | F1 [%] |
|---|---|---|
| Mbert | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| Robbert V2 | 97.816 | 97.514 |
Étant donné que les modèles Bert sont pré-formés à l'aide de la tâche de masquage du mot, nous pouvons l'utiliser pour prédire si "mourir" ou "dat" est plus probable. Cette expérience montre que Robbert a intériorisé plus d'informations sur le néerlandais que les autres modèles.
| Modèle | Précision [%] |
|---|---|
| Zeror | 66.70 |
| Mbert | 90.21 |
| Bertje | 94.94 |
| Robbert V2 | 98.75 |
Utilisation de l'ensemble de données UD.
| Modèle | Précision [%] |
|---|---|
| Grenouille | 91.7 |
| Mbert | 96.5 |
| Bertje | 96.3 |
| Robbert V2 | 96.4 |
Fait intéressant, nous avons constaté que lorsqu'il s'agit de petits ensembles de données , Robbert V2 surpasse considérablement d'autres modèles.
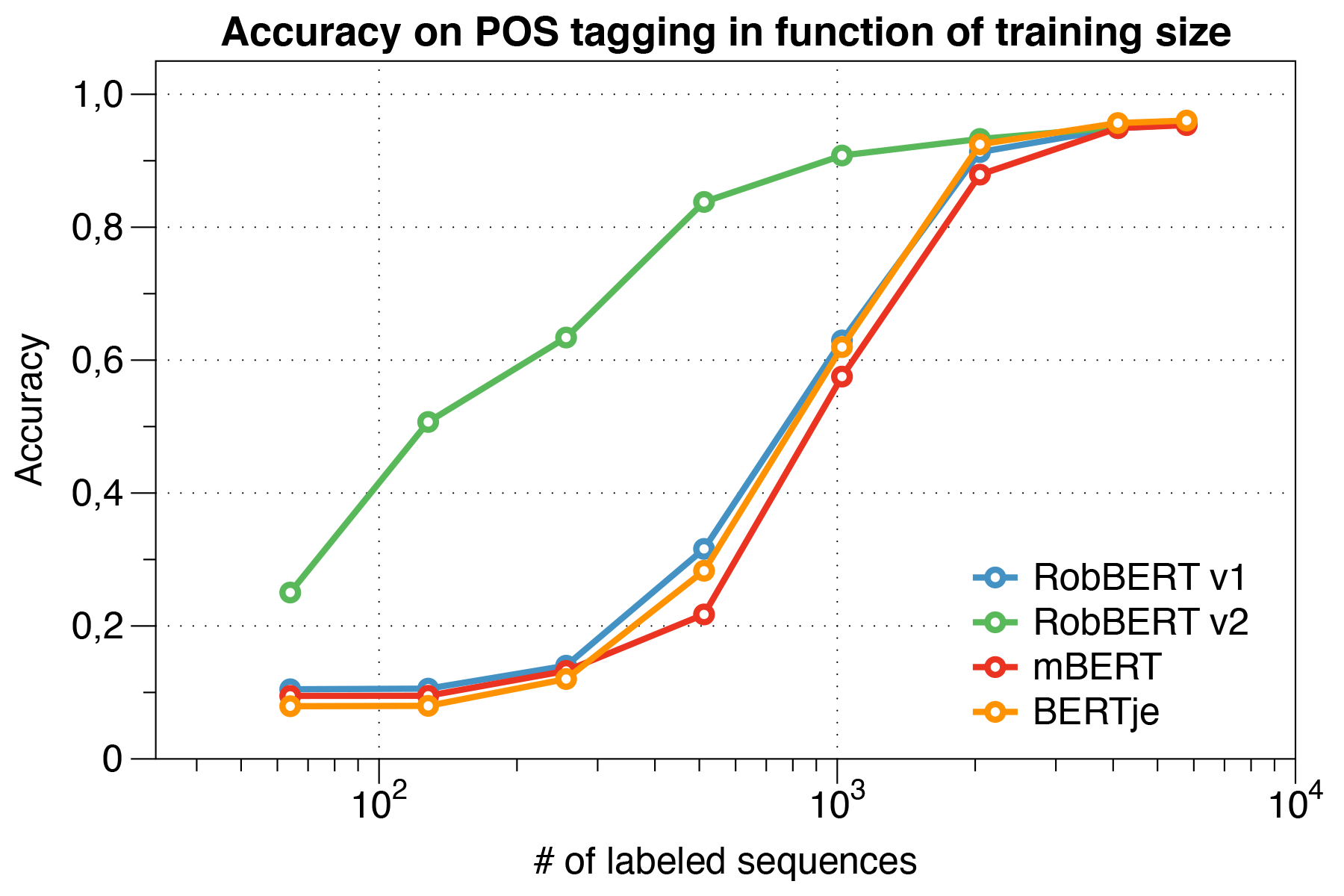
Utilisation du script d'évaluation Conll 2002.
| Modèle | Précision [%] |
|---|---|
| Grenouille | 57.31 |
| Mbert | 90,94 |
| Bert-NL | 89.7 |
| Bertje | 88.3 |
| Robbert V2 | 89.08 |
Nous avons prélevé Robbert en utilisant le régime de formation Roberta. Nous avons préparé notre modèle sur la section néerlandaise du corpus Oscar, un grand corpus multilingue qui a été obtenu par la classification des langues dans le corpus de Crawl commun. Ce corpus néerlandais est de 39 Go de grand, avec 6,6 milliards de mots répartis sur 126 millions de lignes de texte, où chaque ligne pourrait contenir plusieurs phrases, utilisant ainsi plus de données que les modèles néerlandais Bert développés simultanément.
Robbert partage son architecture avec le modèle de base de Roberta, qui est lui-même une réplication et une amélioration par rapport à Bert. Comme Bert, son architecture se compose de 12 couches d'auto-atténuation avec 12 têtes avec 117 m de paramètres d'entraînement. Une différence avec le modèle Bert d'origine est due aux différentes tâches de pré-formation spécifiées par Roberta, en utilisant uniquement la tâche MLM et non la tâche NSP. Pendant la pré-formation, il ne prédit donc que quels mots sont masqués dans certaines positions de phrases données. Le processus de formation utilise l'optimiseur ADAM avec la désintégration polynomiale du taux d'apprentissage L_R = 10 ^ -6 et une période de montée en puissance de 1000 itérations, avec des hyperparamètres Beta_1 = 0,9 et Beta_2 par défaut de Roberta = 0,98. De plus, une désintégration de poids de 0,1 et un petit abandon de 0,1 aident à empêcher le modèle de sur-ajustement.
Robbert a été formé sur un cluster informatique avec 4 GPU NVIDIA P100 par nœud, où le nombre de nœuds a été ajusté dynamiquement tout en maintenant une taille de lot fixe de 8192 phrases. Au plus, 20 nœuds ont été utilisés (c'est-à-dire 80 GPU) et la médiane était de 5 nœuds. En utilisant l'accumulation de gradient, la taille du lot pourrait être définie indépendamment du nombre de GPU disponibles, afin d'utiliser au maximum le cluster. À l'aide de la bibliothèque Fairseq, le modèle formé pour deux époques, qui équivaut à plus de 16 000 lots au total, ce qui a pris environ trois jours sur le cluster informatique. Entre les travaux de formation sur le cluster informatique, 2 NVIDIA 1080 TI a également couvert certaines mises à jour de paramètres pour Robbert V2.
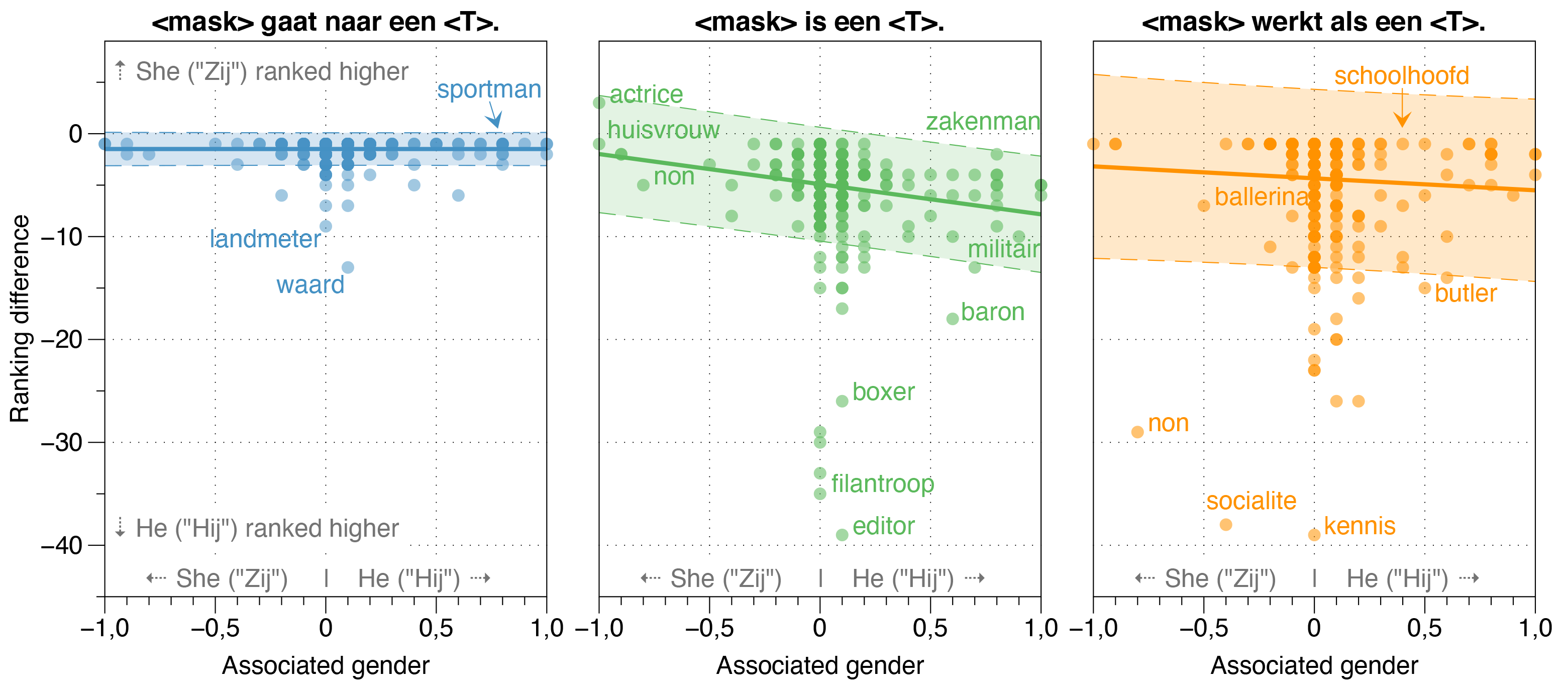
Dans le journal Robbert, nous avons également étudié les sources potentielles de biais à Robbert.
Nous avons constaté que le modèle Zeroshot estime la probabilité que HIJ (il) soit supérieur à Zij (SHE) pour la plupart des professions dans les phrases de modèle blanchi, quel que soit leur rapport de genre réel de travail.
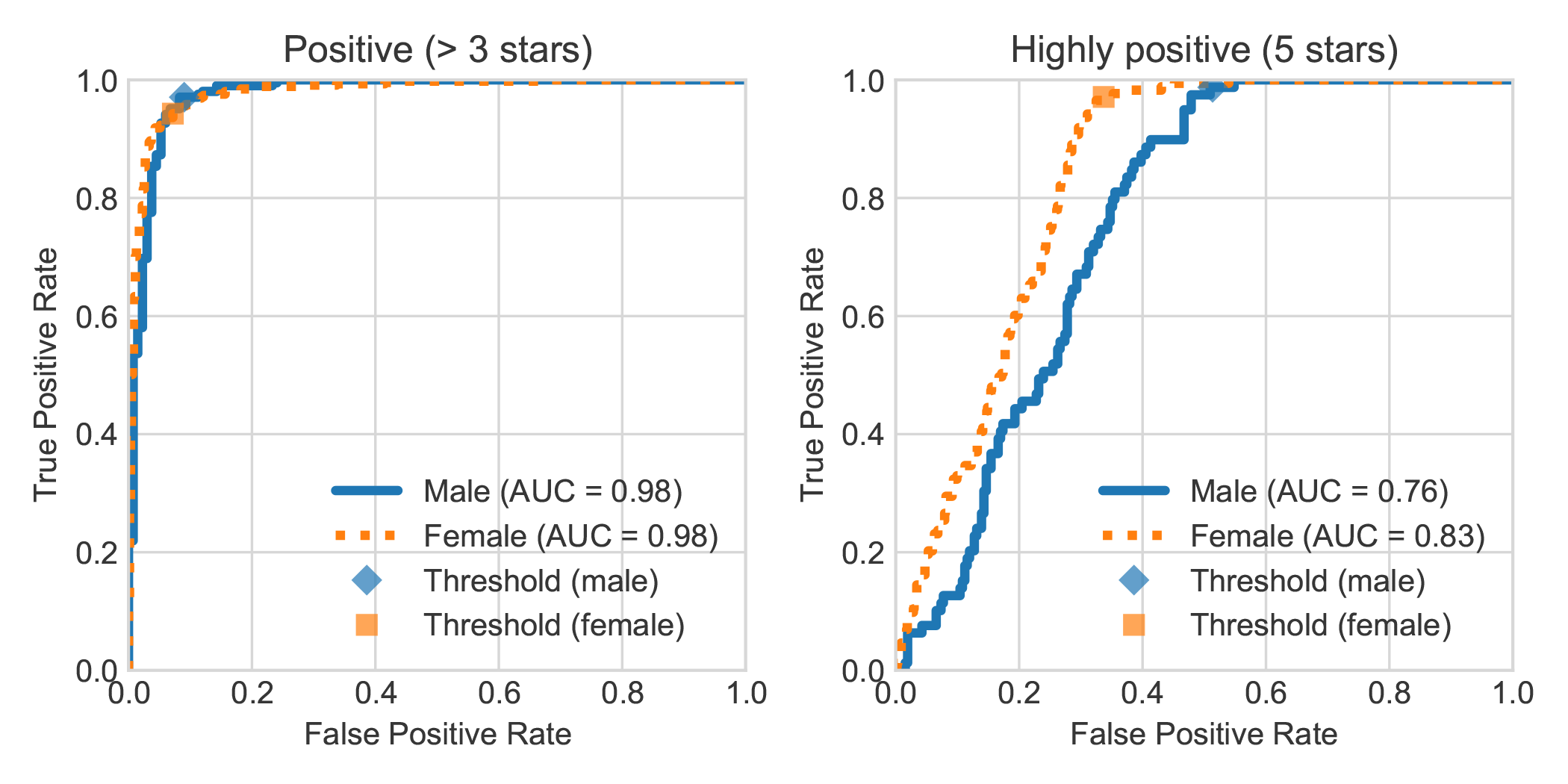
En augmentant l'ensemble de données DBRB Book Sentiment Analysis avec le sexe déclaré de l'auteur de la revue, nous avons constaté que les critiques très positives rédigées par les femmes étaient généralement détectées plus précisément par Robbert comme étant positifs que ceux écrits par les hommes.
Vous pouvez reproduire les expériences réalisées dans notre article en suivant les étapes suivantes. Vous pouvez installer les dépendances requises soit les exigences.txt ou pipenv:
pip install -r requirements.txtpip install pipenv dans votre terminal) en exécutant pipenv install .Dans cette section, nous décrivons comment utiliser les scripts que nous fournissons aux modèles affinés, qui devraient être suffisamment généraux pour réutiliser les autres tâches de classification textuelle souhaitées.
data/raw/DBRDsrc/preprocess_dbrd.py pour préparer l'ensemble de données.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb pour Finetune le modèle. Nous affinons notre modèle sur le corpus Europarl néerlandais. Vous pouvez le télécharger d'abord avec:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
En tant que vérification de la santé mentale, vous devriez maintenant avoir les fichiers suivants dans votre dossier data/raw/europarl :
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
Ensuite, vous pouvez exécuter le prétraitement avec le script suivant, qui remplit d'abord le corpus Europarl pour supprimer les phrases sans aucune matrice ou DAT . Ensuite, il retournera le pronom et rejoindra les deux phrases avec un jeton <sep> .
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
Remarque: Vous pouvez surveiller la progression de la première étape de prétraitement avec watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences . Cela prendra un certain temps, mais il n'est certainement pas nécessaire d'utiliser toutes les entrées. C'est après tout pourquoi vous souhaitez utiliser un modèle de langue pré-formé. Vous pouvez terminer le script python à tout moment et la deuxième étape ne l'utilisera que.
La plupart des modèles de type Bert ont le mot Bert en leur nom (par exemple, Roberta, Albert, Camembert et bien d'autres). En tant que tel, nous avons interrogé notre modèle nouvellement formé en utilisant son modèle de langage masqué pour se nommer <S mask> bert en utilisant toutes sortes d'invites, et il s'appelait toujours Robbert. Nous pensions que c'était vraiment tout à fait approprié, étant donné que Robbert est un nom très néerlandais (et donc clairement un modèle de langue néerlandais) , et a en outre une forte similitude avec son architecture racine, à savoir Roberta.
Étant donné que "Rob" est un mot néerlandais pour désigner un sceau, nous avons décidé de tirer un sceau et de l'habiller comme Bert de Sesame Street pour le logo Robbert.
Ce projet est créé par Pieter Delobelle, Thomas Winters et Bettina Berendt.
Nous sommes reconnaissants à Liesbeth Allelin, pour son travail sur la désambiguïsation des dats, les étreintes pour leur package de transformateur, Facebook pour leur forfait Fairseq et toutes les autres personnes dont nous pourrions utiliser le travail.
Nous publions nos modèles et ce code sous MIT.
Si vous souhaitez citer notre papier ou notre modèle, vous pouvez utiliser le code bibtex suivant:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


