RobBERT
v2.0

Robbert é o modelo Bert holandês de última geração. É um grande modelo de idioma holandês geral pré-treinado que pode ser ajustado em um determinado conjunto de dados para executar qualquer tarefa de classificação, regressão ou margem de token. Como tal, foi usado com sucesso por muitos pesquisadores e profissionais para alcançar o desempenho de última geração para uma ampla gama de tarefas de processamento de linguagem natural holandesa, incluindo:
e também alcançou resultados excelentes e próximos à SOTA para:
* Observe que várias avaliações usam Robbert-V1 e que o segundo e melhorado Robbert-V2 supera esse primeiro modelo em tudo o que testamos
(Observe também que esta lista não é exaustiva. Se você usou Robbert para sua inscrição, estamos felizes em saber sobre isso! Envie -nos um e -mail ou adicione -o a esta lista enviando uma solicitação de tração com a edição!)
Para usar o modelo Robbert usando Transformers Huggingface, use o nome pdelobelle/robbert-v2-dutch-base .
Informações mais aprofundadas sobre Robbert podem ser encontradas em nossa postagem no blog e em nosso artigo.
Robbert usa a arquitetura e pré-treinamento Roberta, mas com um tokenizador holandês e dados de treinamento. Roberta é o modelo Bert inglês robustamente otimizado, tornando -o ainda mais poderoso que o modelo Bert original. Dada a mesma arquitetura, Robbert pode ser facilmente fino e inferido usando o código para os modelos FineTune Roberta e a maioria dos códigos usados para os modelos Bert, por exemplo, conforme fornecido pela Biblioteca de Transformers do Huggingface.
Robbert pode ser facilmente usado de duas maneiras diferentes, ou seja, usando o código Fairseq Roberta ou usando os Transformers Huggingface
Por padrão, Robbert possui o cabeçalho do modelo de idioma mascarado usado no treinamento. Isso pode ser usado como uma maneira de tiro zero de preencher máscaras nas frases. Ele pode ser testado gratuitamente na API Hosterence Host Hospedy de Robbert de Huggingface. Você também pode criar uma nova cabeça de previsão para sua própria tarefa, usando qualquer um dos Roberta-Runners da Huggingface, seus notebooks de ajuste fino alterando o nome do modelo para pdelobelle/robbert-v2-dutch-base ou usar os regimes originais de treinamento Fairseq Roberta.
Você pode fazer o download facilmente do Robbert V2 usando? Transformadores. Use o código a seguir para baixar o modelo básico e o FineTune, ou use um de nossos modelos FinetUned (documentado em nosso site de projeto).
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) Começando com transformers v2.4.0 (ou instalando da fonte), você pode usar o AutoTokenizer e o Automodel. Em seguida, você pode usar a maior parte dos notebooks baseados em Bert da HuggingFace para o Finetuning Robbert no seu tipo de conjunto de dados de idiomas holandês.
Como alternativa, você também pode usar o Robbert usando o Código de Arquitetura Roberta. Você pode baixar o modelo Fairseq do Robbert V2 aqui: (Robbert-Base, 1,5 GB). Usando model.pt de Robbert, esse método permite que você use todas as outras funcionalidades de Roberta.
Todas as experiências são descritas em mais detalhes em nosso artigo, com o código em nosso repositório do GitHub.
Prevendo se uma revisão é positiva ou negativa usando o conjunto de dados de análises de livros holandeses.
| Modelo | Precisão [%] |
|---|---|
| Ulmfit | 93.8 |
| Bertje | 93.0 |
| Robbert V2 | 95.1 |
Medimos o quão bem os modelos são capazes de fazer resolução de coreferência prevendo se "morrer" ou "dat" deve ser preenchido em uma frase. Para isso, usamos o Corpus Europarl.
| Modelo | Precisão [%] | F1 [%] |
|---|---|---|
| Linha de base (LSTM) | 75.03 | |
| Mbert | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| Robbert V2 | 99.232 | 99.121 |
Também medimos o desempenho usando apenas 10K de treinamento em exemplos. Este experimento ilustra claramente que Robbert supera outros modelos quando há poucos dados disponíveis.
| Modelo | Precisão [%] | F1 [%] |
|---|---|---|
| Mbert | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| Robbert V2 | 97.816 | 97.514 |
Como os modelos BERT são pré-treinados usando a tarefa de mascaramento de palavras, podemos usá-la para prever se "Die" ou "Dat" é mais provável. Este experimento mostra que Robbert internalizou mais informações sobre holandês do que outros modelos.
| Modelo | Precisão [%] |
|---|---|
| Zeror | 66.70 |
| Mbert | 90.21 |
| Bertje | 94.94 |
| Robbert V2 | 98.75 |
Usando o conjunto de dados Lassy UD.
| Modelo | Precisão [%] |
|---|---|
| Sapo | 91.7 |
| Mbert | 96.5 |
| Bertje | 96.3 |
| Robbert V2 | 96.4 |
Curiosamente, descobrimos que, ao lidar com pequenos conjuntos de dados , o Robbert V2 supera significativamente outros modelos.
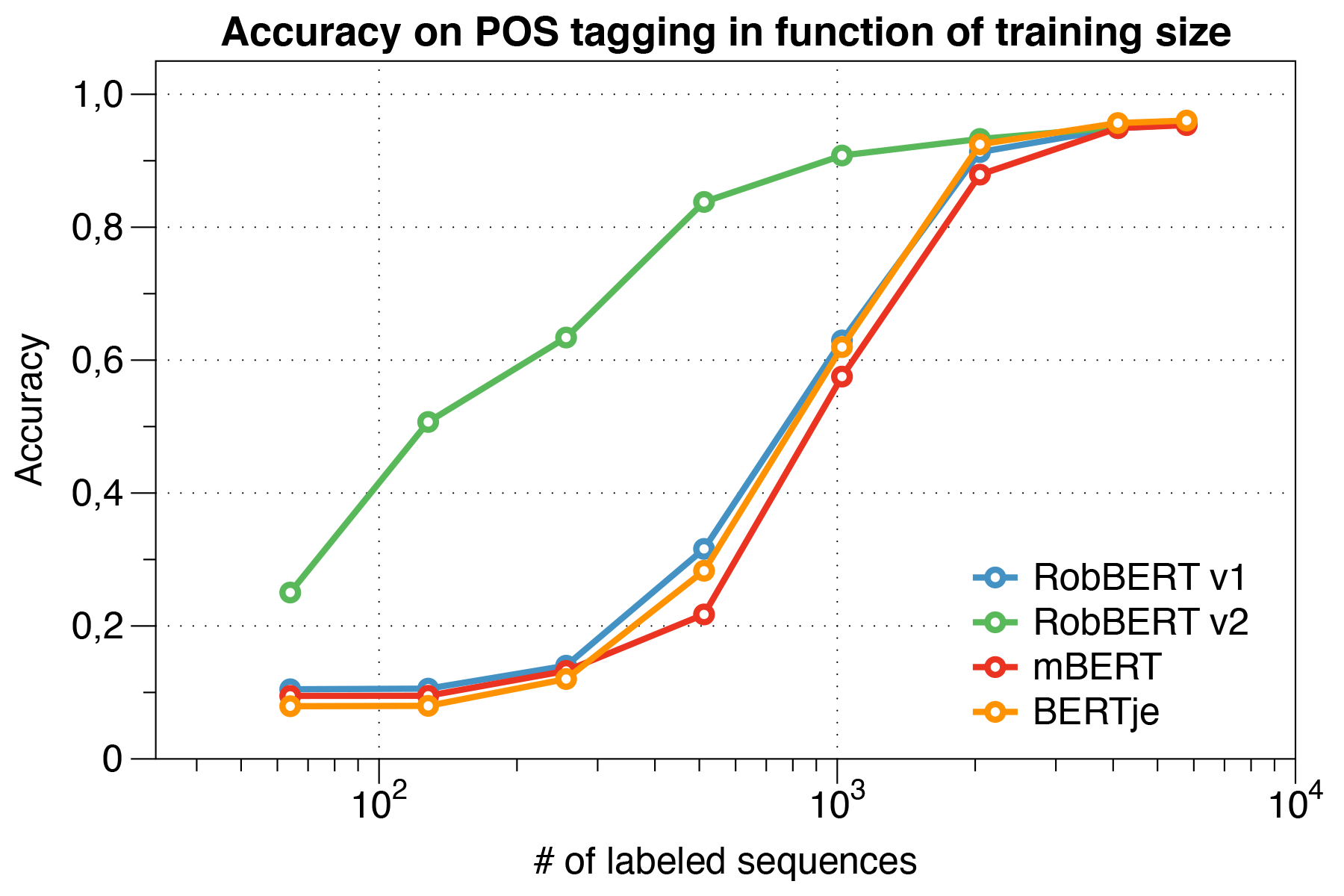
Usando o script de avaliação Conll 2002.
| Modelo | Precisão [%] |
|---|---|
| Sapo | 57.31 |
| Mbert | 90.94 |
| Bert-nl | 89.7 |
| Bertje | 88.3 |
| Robbert V2 | 89.08 |
Robert pré-treinados usando o regime de treinamento de Roberta. Pré-treinamos nosso modelo na seção holandesa do Oscar Corpus, um grande corpus multilíngue que foi obtido pela classificação de idiomas no corpus de rastreamento comum. Este corpus holandês é 39 GB grande, com 6,6 bilhões de palavras espalhadas por 126 milhões de linhas de texto, onde cada linha pode conter várias frases, usando mais dados do que os modelos hutch Bert desenvolvidos simultaneamente.
Robbert compartilha sua arquitetura com o modelo básico de Roberta, que por si só é uma replicação e melhoria sobre Bert. Como Bert, sua arquitetura consiste em 12 camadas de auto-ataque com 12 cabeças com 117 milhões de parâmetros treináveis. Uma diferença com o modelo BERT original se deve à diferente tarefa de pré-treinamento especificada por Roberta, usando apenas a tarefa MLM e não a tarefa NSP. Durante o pré-treinamento, assim prevê apenas quais palavras são mascaradas em certas posições de determinadas frases. O processo de treinamento usa o otimizador Adam com decaimento polinomial da taxa de aprendizado l_r = 10^-6 e um período de aceleração de 1000 iterações, com hyperparameters beta_1 = 0.9 e beta_2 padrão de Roberta = 0,98. Além disso, uma decaimento de peso de 0,1 e um pequeno abandono de 0,1 ajuda a impedir que o modelo exagere.
Robbert foi treinado em um cluster de computação com 4 GPUs NVIDIA P100 por nó, onde o número de nós foi ajustado dinamicamente, mantendo um tamanho fixo em lote de 8192 frases. No máximo 20 nós foram utilizados (por exemplo, 80 GPUs) e a mediana foi de 5 nós. Ao usar o acúmulo de gradiente, o tamanho do lote pode ser definido independentemente do número de GPUs disponíveis, a fim de utilizar o cluster ao máximo. Usando a biblioteca Fairseq, o modelo treinado para duas épocas, que equivale a mais de 16k lotes no total, que levaram cerca de três dias no cluster de computação. Entre os trabalhos de treinamento no cluster de computação, o 2 NVIDIA 1080 TIs também abrangeu algumas atualizações de parâmetros do Robbert V2.
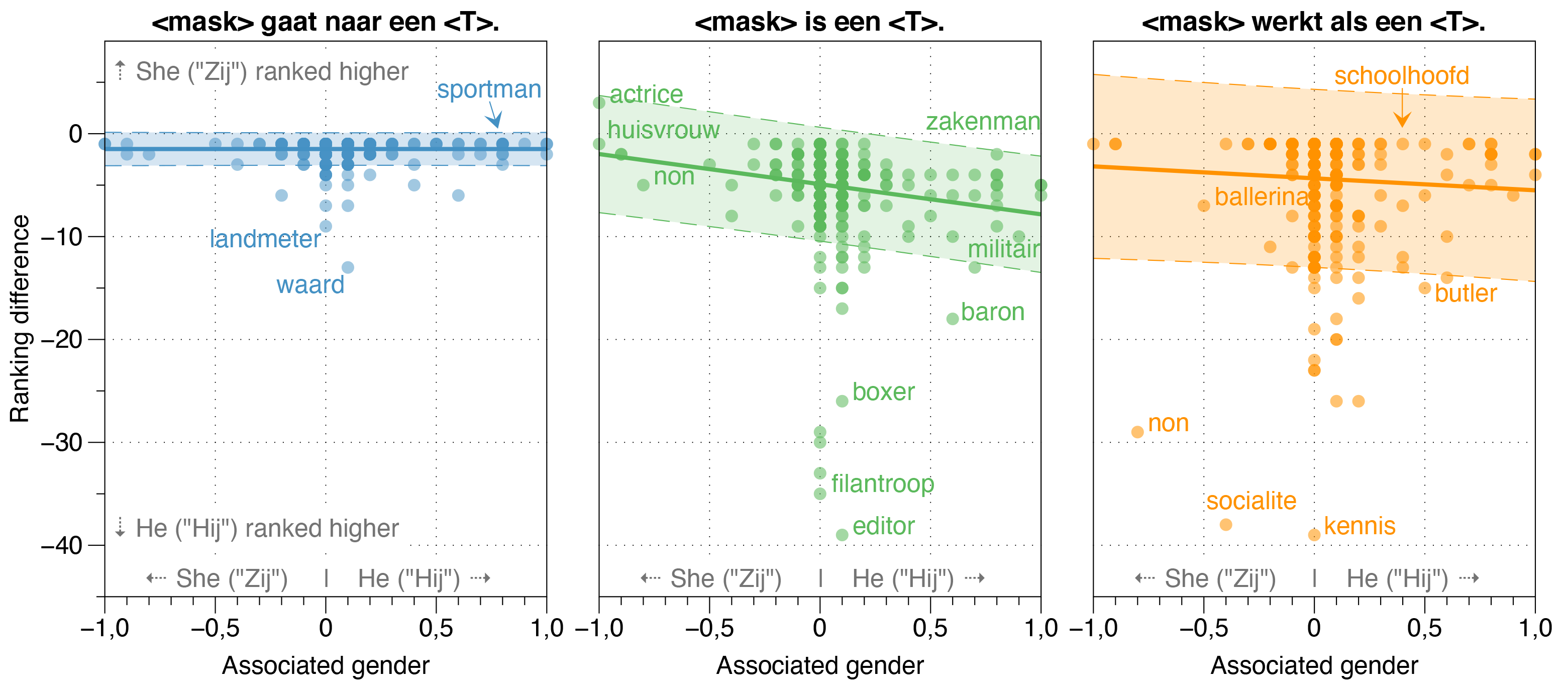
No artigo de Robbert, também investigamos possíveis fontes de preconceito em Robbert.
Descobrimos que o modelo de Zeroshot estima a probabilidade de a HIJ (ele) ser maior que Zij (ela) para a maioria das ocupações em frases de modelo branqueado, independentemente da relação de gênero real na realidade.
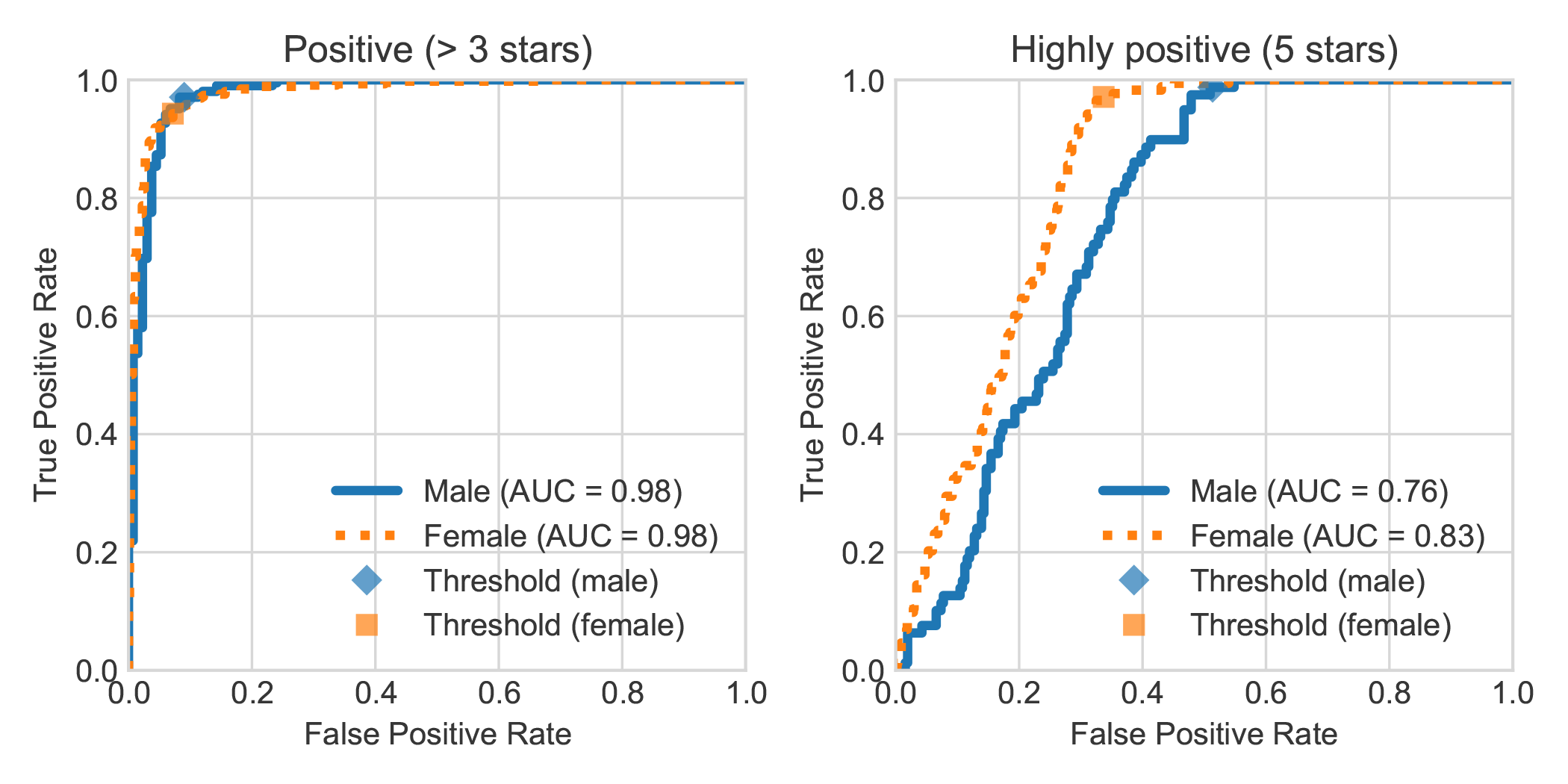
Ao aumentar o conjunto de dados de análise de análise de sentimentos do livro holandês do DBRB com o gênero declarado do autor da revisão, descobrimos que críticas altamente positivas escritas por mulheres eram geralmente detectadas com mais precisão por Robbert como positivas do que as escritas por homens.
Você pode replicar os experimentos feitos em nosso artigo seguindo as etapas a seguir. Você pode instalar as dependências necessárias os requisitos.txt ou Pipenv:
pip install -r requirements.txtpip install pipenv no seu terminal) executando pipenv install .Nesta seção, descrevemos como usar os scripts que fornecemos aos modelos ajustados, que devem ser gerais o suficiente para reutilizar para outras tarefas desejadas de classificação textual.
data/raw/DBRDsrc/preprocess_dbrd.py para preparar o conjunto de dados.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb para finalizar o modelo. Nós ajustamos nosso modelo no corpus europarl holandês. Você pode baixá -lo primeiro com:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
Como verificação de sanidade, agora você deve ter os seguintes arquivos em sua pasta data/raw/europarl :
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
Em seguida, você pode executar o pré -processamento com o seguinte script, que preenche o primeiro processo do Europarl Corpus para remover frases sem qualquer dado ou dat . Posteriormente, ele virará o pronome e unirá as duas frases junto com um token <sep> .
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
NOTA: Você pode monitorar o progresso da primeira etapa de pré -processamento com watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences . Isso vai demorar um pouco, mas certamente não é necessário usar todas as entradas. Afinal, é por isso que você deseja usar um modelo de idioma pré-treinado. Você pode encerrar o script python a qualquer momento e a segunda etapa usará apenas isso.
A maioria dos modelos semelhantes a Bert tem a palavra Bert em seu nome (por exemplo, Roberta, Albert, Camembert e muitos, muitos outros). Como tal, consultamos nosso modelo recém -treinado usando seu modelo de linguagem mascarada para se nomear <kask> bert usando todos os tipos de instruções, e ele se chamou consistentemente de robert. Achamos que era realmente bastante apropriado, já que Robbert é um nome muito holandês (e, portanto, claramente um modelo de idioma holandês) e, além disso, tem uma alta semelhança com sua arquitetura raiz, a saber, Roberta.
Como "Rob" é uma palavra holandesa para denotar um selo, decidimos desenhar um selo e vesti -lo como Bert da Vila Sésamo para o logotipo do Robbert.
Este projeto é criado por Pieter Delobelle, Thomas Winters e Bettina Berendt.
Somos gratos a Liesbeth Allein, por seu trabalho sobre a desambiguação de débitos, Huggingface para o seu pacote de transformadores, o Facebook para o pacote Fairseq e todas as outras pessoas cujo trabalho poderíamos usar.
Lançamos nossos modelos e esse código no MIT.
Se você deseja citar nosso papel ou modelo, pode usar o seguinte código Bibtex:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


