RobBERT
v2.0

Robbert는 최첨단 네덜란드 버트 모델입니다. 텍스트 분류, 회귀 또는 토큰 태깅 작업을 수행하기 위해 주어진 데이터 세트에서 미세 조정할 수있는 대규모 미리 훈련 된 일반 네덜란드 언어 모델입니다. 따라서 많은 연구자와 실무자들이 다음을 포함하여 광범위한 네덜란드 자연 언어 처리 작업을위한 최첨단 성과를 달성하기 위해 성공적으로 사용되었습니다.
또한 다음에 대한 뛰어난 소타 결과를 달성했습니다.
* 여러 평가는 Robbert-V1을 사용하고 두 번째로 향상된 Robbert-V2는 테스트 한 모든 것에 대한 첫 번째 모델보다 우수합니다.
(또한이 목록은 철저하지 않습니다. 응용 프로그램에 Robbert를 사용했다면 기꺼이 알게되어 기쁩니다! 편집으로 풀 요청을 보내서 우편물을 보내 거나이 목록에 직접 추가하십시오!)
Huggingface Transformers를 사용하여 Robbert 모델을 사용하려면 pdelobelle/robbert-v2-dutch-base 이름을 사용하십시오.
Robbert에 대한 심층적 인 정보는 블로그 게시물과 논문에서 찾을 수 있습니다.
Robbert는 Roberta 아키텍처 및 사전 훈련을 사용하지만 네덜란드 토큰 화기 및 교육 데이터를 사용합니다. Roberta는 강력하게 최적화 된 영어 버트 모델로 원래 Bert 모델보다 훨씬 강력합니다. 이와 동일한 아키텍처가 주어지면 Robbert는 Roberta 모델을 Finetune에 사용하기 위해 코드를 사용하여 쉽게 미세 조정하고 추론 할 수 있습니다.
Robbert는 FairSeQ Roberta 코드를 사용하거나 Huggingface Transformers를 사용하는 두 가지 방식으로 쉽게 사용할 수 있습니다.
기본적으로 Robbert는 교육에 사용되는 가면 언어 모델 헤드를 가지고 있습니다. 이것은 마스크를 문장으로 채우는 제로 샷 방법으로 사용할 수 있습니다. Robbert의 호스팅 FERENCE API에서 무료로 테스트 할 수 있습니다. pdelobelle/robbert-v2-dutch-base Huggingf
Robbert V2를 사용하여 쉽게 다운로드 할 수 있습니까? 변압기. 다음 코드를 사용하여 기본 모델을 다운로드하고 직접 결합하거나 Finetuned 모델 중 하나 (프로젝트 사이트에 문서화)를 사용하십시오.
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) transformers v2.4.0 (또는 소스에서 설치)부터 Autotokenizer 및 Automodel을 사용할 수 있습니다. 그런 다음 네덜란드 언어 데이터 세트 유형에서 Robbert를 미세 조정하기 위해 대부분의 Huggingface의 Bert 기반 노트북을 사용할 수 있습니다.
또는 Roberta 아키텍처 코드를 사용하여 Robbert를 사용할 수도 있습니다. Robbert V2의 FairSeQ 모델을 여기에서 다운로드 할 수 있습니다 : (Robbert-Base, 1.5GB). Robbert의 model.pt 사용 하여이 방법을 사용하면 Roberta의 다른 모든 기능을 사용할 수 있습니다.
모든 실험은 GitHub 저장소의 코드와 함께 논문에 자세히 설명되어 있습니다.
네덜란드 서적 검토 데이터 세트를 사용하여 검토가 긍정적인지 부정적인지 예측합니다.
| 모델 | 정확성 [%] |
|---|---|
| ulmfit | 93.8 |
| Bertje | 93.0 |
| Robbert V2 | 95.1 |
우리는 "다이"또는 "DAT"가 문장에 채워야하는지 여부를 예측하여 모델이 얼마나 잘 조정 해상도를 수행 할 수 있는지 측정했습니다. 이를 위해 Europarl 코퍼스를 사용했습니다.
| 모델 | 정확성 [%] | F1 [%] |
|---|---|---|
| 기준선 (LSTM) | 75.03 | |
| Mbert | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| Robbert V2 | 99.232 | 99.121 |
또한 10K 교육 예제 만 사용하여 성능을 측정했습니다. 이 실험은 Robbert가 사용 가능한 데이터가 거의 없을 때 다른 모델을 능가한다는 것을 분명히 보여줍니다.
| 모델 | 정확성 [%] | F1 [%] |
|---|---|---|
| Mbert | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| Robbert V2 | 97.816 | 97.514 |
버트 모델은 마스킹 작업이라는 단어를 사용하여 미리 훈련되므로이를 사용하여 "다이"또는 "DAT"가 더 가능성이 높은지 예측할 수 있습니다. 이 실험은 Robbert가 다른 모델보다 네덜란드에 대한 더 많은 정보를 내재화했음을 보여줍니다.
| 모델 | 정확성 [%] |
|---|---|
| Zeror | 66.70 |
| Mbert | 90.21 |
| Bertje | 94.94 |
| Robbert V2 | 98.75 |
Lassy UD 데이터 세트 사용.
| 모델 | 정확성 [%] |
|---|---|
| 개구리 | 91.7 |
| Mbert | 96.5 |
| Bertje | 96.3 |
| Robbert V2 | 96.4 |
흥미롭게도, 우리는 작은 데이터 세트를 처리 할 때 Robbert V2가 다른 모델 보다 훨씬 능가한다는 것을 발견했습니다.
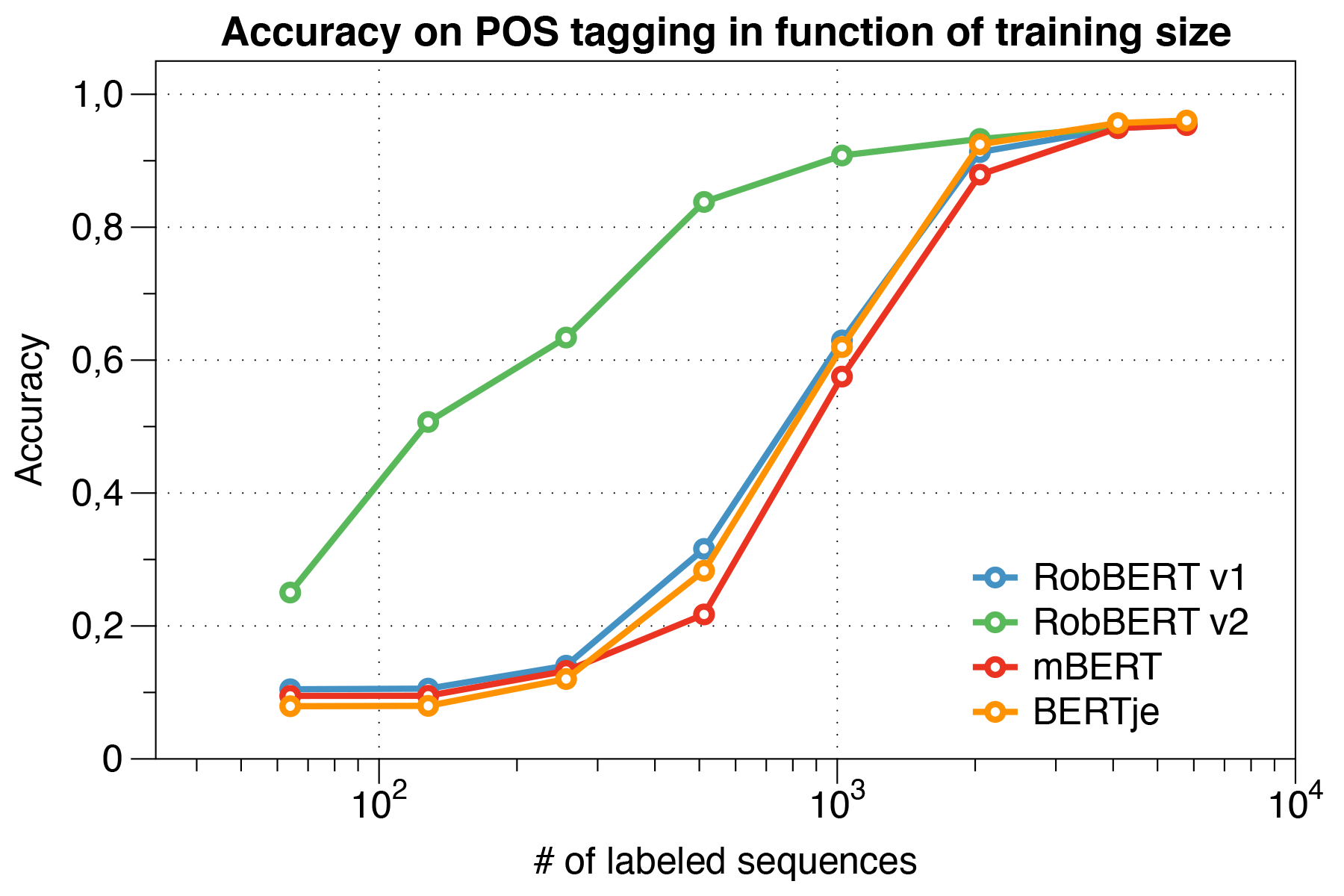
Conll 2002 평가 스크립트 사용.
| 모델 | 정확성 [%] |
|---|---|
| 개구리 | 57.31 |
| Mbert | 90.94 |
| Bert-nl | 89.7 |
| Bertje | 88.3 |
| Robbert V2 | 89.08 |
우리는 Roberta 훈련 체제를 사용하여 강도를 미리 훈련했습니다. 우리는 일반 크롤링 코퍼스에서 언어 분류에 의해 얻어진 대규모 다국어 코퍼스 인 오스카 코퍼스의 네덜란드 섹션에서 우리의 모델을 미리 훈련시켰다. 이 네덜란드의 코퍼스는 39GB의 대규모이며 66 억 단어는 1 억 2 천 6 백만 줄 이상의 텍스트를 펼쳤으며, 각 라인에는 여러 문장이 포함되어있어 동시에 개발 된 네덜란드 버트 모델보다 더 많은 데이터를 사용합니다.
Robbert는 Roberta의 기본 모델과 아키텍처를 공유하는데,이 모델은 Bert보다 복제 및 개선입니다. Bert와 마찬가지로 아키텍처는 117m의 훈련 가능한 매개 변수가있는 12 개의 헤드가있는 12 개의 자체 변환 레이어로 구성됩니다. 원래 Bert 모델과의 한 가지 차이점은 NSP 작업이 아닌 MLM 작업 만 사용하여 Roberta가 지정한 다른 사전 훈련 작업 때문입니다. 사전 훈련 동안, 주어진 문장의 특정 위치에서 어떤 단어가 마스킹되는지 예측합니다. 교육 프로세스는 학습 속도 L_R = 10^-6의 다항식 부패와 함께 Adam Optimizer를 사용하고 1000 개의 반복의 램프 업 기간을 사용하며, 하이퍼 파라미터 Beta_1 = 0.9 및 Roberta의 기본 Beta_2 = 0.98이 있습니다. 또한, 체중 감소 0.1과 0.1의 작은 드롭 아웃은 모델이 과적으로 적합하지 않도록하는 데 도움이됩니다.
Robbert는 노드 당 4 NVIDIA P100 GPUS를 갖춘 컴퓨팅 클러스터에서 교육을 받았으며, 여기서 노드 수는 8192 개의 문장의 고정 배치 크기를 유지하면서 동적으로 조정되었습니다. 최대 20 개의 노드가 사용되었고 (예 : 80 GPU) 중앙값은 5 개의 노드였습니다. 그라디언트 축적을 사용함으로써, 배치 크기는 클러스터를 최대한 활용하기 위해 이용 가능한 GPU 수와 독립적으로 설정할 수있다. FairSeQ 라이브러리를 사용 하여이 모델은 전체 16K 배치에 해당하는 2 개의 에포크로 훈련되어 컴퓨팅 클러스터에서 약 3 일이 걸렸습니다. 컴퓨팅 클러스터의 교육 작업 사이에서 2 NVIDIA 1080 TI는 Robbert V2의 일부 매개 변수 업데이트를 다루었습니다.
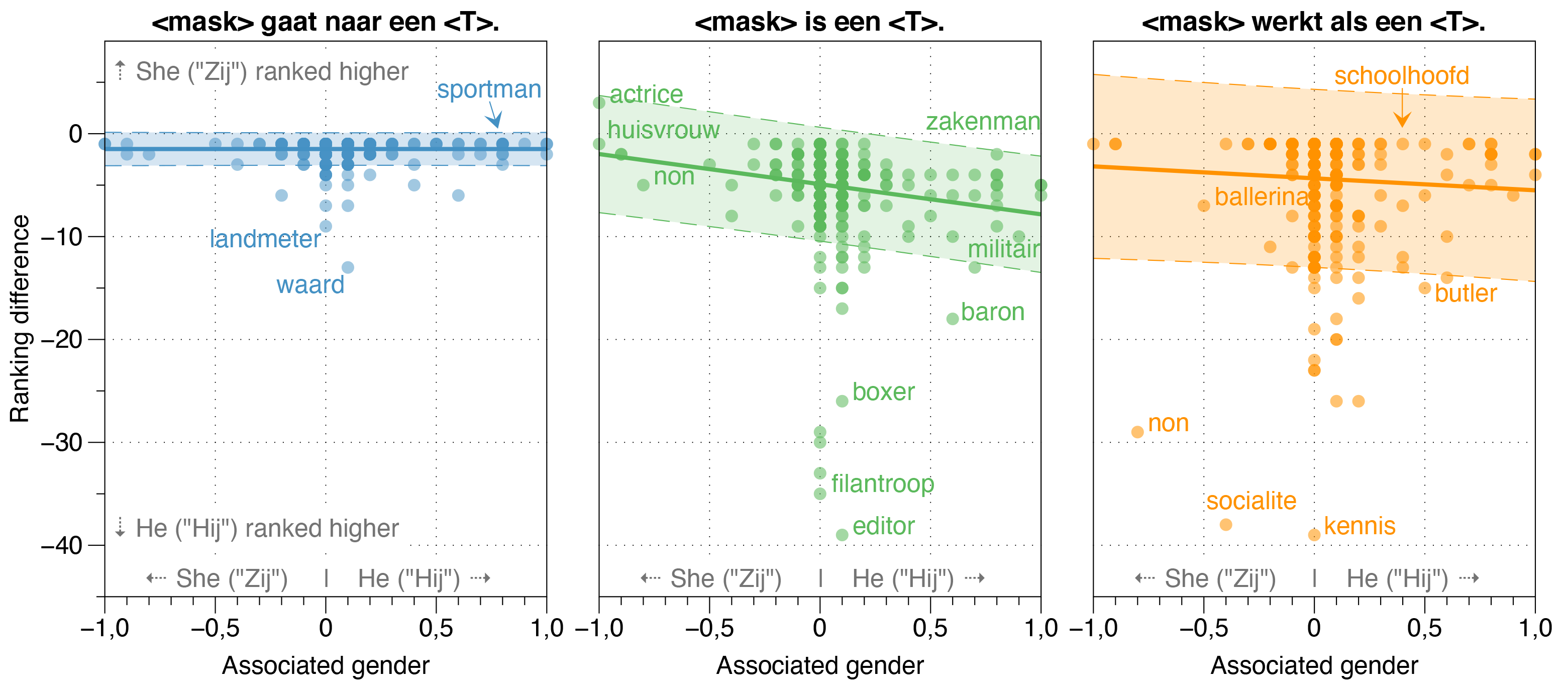
Robbert 신문에서 우리는 또한 Robbert에서 잠재적 인 편견의 원천을 조사했습니다.
우리는 Zeroshot 모델이 실제 직무 성별 비율에 관계없이 표백 된 템플릿 문장의 대부분의 직업에 대해 Hij (HE)가 Zij (그녀)보다 높을 확률이 Zij (그녀)보다 높을 것으로 추정합니다.
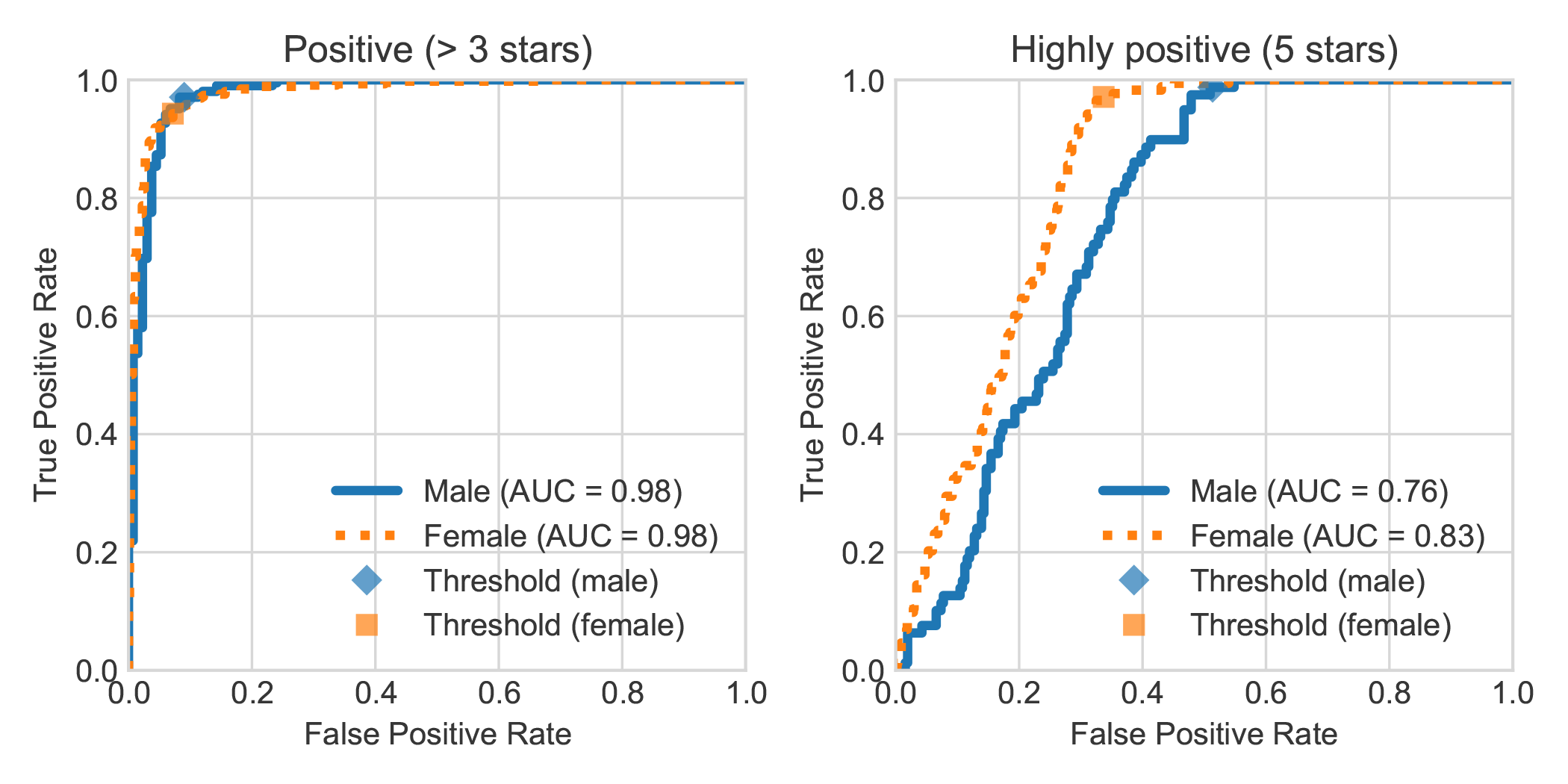
검토 저자의 성별로 DBRB Dutch Book Sentiment Analysis 데이터 세트를 확대함으로써, 우리는 여성이 작성한 매우 긍정적 인 리뷰가 일반적으로 Robbert에 의해 남성이 쓴 것보다 긍정적 인 것으로 더 정확하게 감지된다는 것을 발견했습니다.
다음 단계에 따라 논문에서 수행 한 실험을 복제 할 수 있습니다. 필요한 종속성을 요구 사항을 설치할 수 있습니다 .txt 또는 Pipenv :
pip install -r requirements.txtpip install pipenv 하여 pipenv install ).이 섹션에서는 우리가 제공하는 스크립트를 미세 조정 모델에 사용하는 방법을 설명하며, 이는 다른 원하는 텍스트 분류 작업을 재사용 할 수있을 정도로 일반적이어야합니다.
data/raw/DBRD 에 저장하십시오.src/preprocess_dbrd.py 실행하십시오.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb 따라 모델을 미세하게하십시오. 우리는 네덜란드 Europarl 코퍼스에 대한 모델을 미세 조정합니다. 먼저 다음과 같이 다운로드 할 수 있습니다.
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
Wanity Check로서 이제 data/raw/europarl 폴더에 다음 파일이 있어야합니다.
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
그런 다음 다음 스크립트로 전처리를 실행할 수 있습니다. 다음 스크립트는 Europarl 코퍼스를 먼저 처리하여 다이 또는 DAT 없이 문장을 제거합니다. 그 후 대명사를 뒤집고 <sep> 토큰과 함께 두 문장에 합류합니다.
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
참고 : watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences 사용하여 첫 번째 전처리 단계의 진행 상황을 모니터링 할 수 있습니다. 시간이 걸리지 만 모든 입력을 사용할 필요는 없습니다. 이것은 결국 미리 훈련 된 언어 모델을 사용하려는 이유입니다. 언제든지 파이썬 스크립트를 종료 할 수 있으며 두 번째 단계는 그에 대해서만 사용합니다 ._.
대부분의 Bert와 같은 모델은 이름으로 Bert라는 단어를 가지고 있습니다 (예 : Roberta, Albert, Camembert 및 많은 사람들). 따라서, 우리는 마스크 된 언어 모델을 사용하여 새로 훈련 된 모델을 쿼리하여 모든 종류의 프롬프트를 사용하여 <mask> 버트 자체를 지명했으며 지속적으로 Robbert라고 불렀습니다. 우리는 Robbert가 매우 네덜란드 이름 (따라서 분명히 네덜란드 언어 모델) 이라는 점을 감안할 때 그것이 매우 적합하다고 생각했으며, 또한 루트 아키텍처, 즉 Roberta와 유사합니다.
"Rob" 은 인감을 나타내는 네덜란드어이기 때문에 우리는 인감을 그리고 세서미 스트리트에서 강도 로고를 위해 버트처럼 옷을 입기로 결정했습니다.
이 프로젝트는 Pieter Delobelle, Thomas Winters 및 Bettina Berendt에 의해 만들어졌습니다.
우리는 Liesbeth Allein에게 Die-Dat Disambiguation에 대한 작업, 변압기 패키지, FairseQ 패키지를위한 Facebook 및 우리가 사용할 수있는 다른 모든 사람들에게 감사합니다.
우리는 MIT에서 모델 과이 코드를 출시합니다.
당사 논문이나 모델을 인용하려면 다음 Bibtex 코드를 사용할 수 있습니다.
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


