RobBERT
v2.0

Робберт-современная голландская модель Берта. Это большая предварительно обученная модель общего голландского языка, которая может быть точно настроена на данном наборе данных, чтобы выполнить любую задачу текстовой классификации, регрессии или токена. Таким образом, он успешно использовался многими исследователями и практиками для достижения современных результатов для широкого спектра голландских задач обработки естественного языка, в том числе:
а также достиг выдающихся, близких результатов для:
* Обратите внимание, что в нескольких оценках используется Robbert-V1, и что второй и улучшенный Robbert-V2 превосходит эту первую модель на все, что мы протестировали
(Также обратите внимание, что этот список не является исчерпывающим. Если вы использовали Robbert для вашего приложения, мы рады узнать об этом! Отправьте нам почту или добавьте его в этот список, отправив запрос на привлечение с редактированием!)
Чтобы использовать модель Robbert, используя трансформаторы huggingface, используйте имя pdelobelle/robbert-v2-dutch-base .
Более подробную информацию о Robbert можно найти в нашем сообщении в блоге и в нашей статье.
Робберт использует архитектуру и предварительную тренировку Роберты, но с голландскими токенизаторами и учебными данными. Роберта - надежная оптимизированная модель английской Bert, что делает ее еще более мощной, чем оригинальная модель Bert. Учитывая эту же архитектуру, Robbert может быть легко создан и выводится с использованием кода для моделей Finetune Roberta и большинства кода, используемых для моделей BERT, например, как это предусмотрено библиотекой Trangingface Transformers.
Робберт можно легко использовать двумя разными способами, а именно с использованием кода Fairseq Roberta или с использованием трансформаторов Huggingface
По умолчанию у Робберта есть глава модели в масках, используемая при обучении. Это можно использовать в качестве нулевого способа заполнения масок в предложениях. Его можно бесплатно протестировать на API вывод Robbert's API вывод о Huggingface. Вы также можете создать новую головку прогнозирования для вашей собственной задачи, используя любую из бегунов Roberta's Huggingface, их точные ноутбуки, изменяя название модели на pdelobelle/robbert-v2-dutch-base , или использовать оригинальные режимы обучения Fairseq Roberta.
Вы можете легко скачать Robbert V2 с помощью? Трансформеры. Используйте следующий код для загрузки базовой модели и самостоятельно, или используйте одну из наших современных моделей (документировано на нашем сайте проекта).
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) Начиная с transformers v2.4.0 (или установки из источника), вы можете использовать AutoTokenizer и Automodel. Затем вы можете использовать большую часть ноутбуков HuggingFace на базе BERT для Manetuning Robbert на вашем типе набора данных голландского языка.
В качестве альтернативы, вы также можете использовать Robbert, используя код архитектуры Roberta. Вы можете скачать модель Fairseq Robbert V2 здесь: (база Robbert, 1,5 ГБ). Используя model.pt Robbert.pt, этот метод позволяет использовать все другие функции Роберты.
Все эксперименты более подробно описаны в нашей статье, а код в нашем репозитории GitHub.
Предсказание, является ли обзор положительным или отрицательным, используя набор данных голландских книг.
| Модель | Точность [%] |
|---|---|
| Ulmfit | 93,8 |
| Бердье | 93.0 |
| Robbert v2 | 95.1 |
Мы измерили, насколько хорошо модели способны выполнять разрешение основной работы, предсказав, следует ли заполнить «DIM» или «DAT» в предложение. Для этого мы использовали корпус Europarl.
| Модель | Точность [%] | F1 [%] |
|---|---|---|
| Базовая линия (LSTM) | 75.03 | |
| Мберт | 98.285 | 98.033 |
| Бердье | 98.268 | 98.014 |
| Robbert v2 | 99,232 | 99.121 |
Мы также измерили производительность, используя только 10 тыс. Примеров обучения. Этот эксперимент ясно показывает, что Robbert превосходит другие модели, когда мало доступно.
| Модель | Точность [%] | F1 [%] |
|---|---|---|
| Мберт | 92.157 | 90.898 |
| Бердье | 93.096 | 91.279 |
| Robbert v2 | 97.816 | 97.514 |
Поскольку модели BERT предварительно обучены с использованием задачи маскировки слова, мы можем использовать это, чтобы предсказать, является ли «Die» или «DAT» более вероятным. Этот эксперимент показывает, что Робберт усвоил больше информации о голландцах, чем другие модели.
| Модель | Точность [%] |
|---|---|
| Zeror | 66.70 |
| Мберт | 90.21 |
| Бердье | 94,94 |
| Robbert v2 | 98,75 |
Использование набора данных Lassy UD.
| Модель | Точность [%] |
|---|---|
| Лягушка | 91.7 |
| Мберт | 96.5 |
| Бердье | 96.3 |
| Robbert v2 | 96.4 |
Интересно, что мы обнаружили, что при работе с небольшими наборами данных Robbert V2 значительно превосходит другие модели.
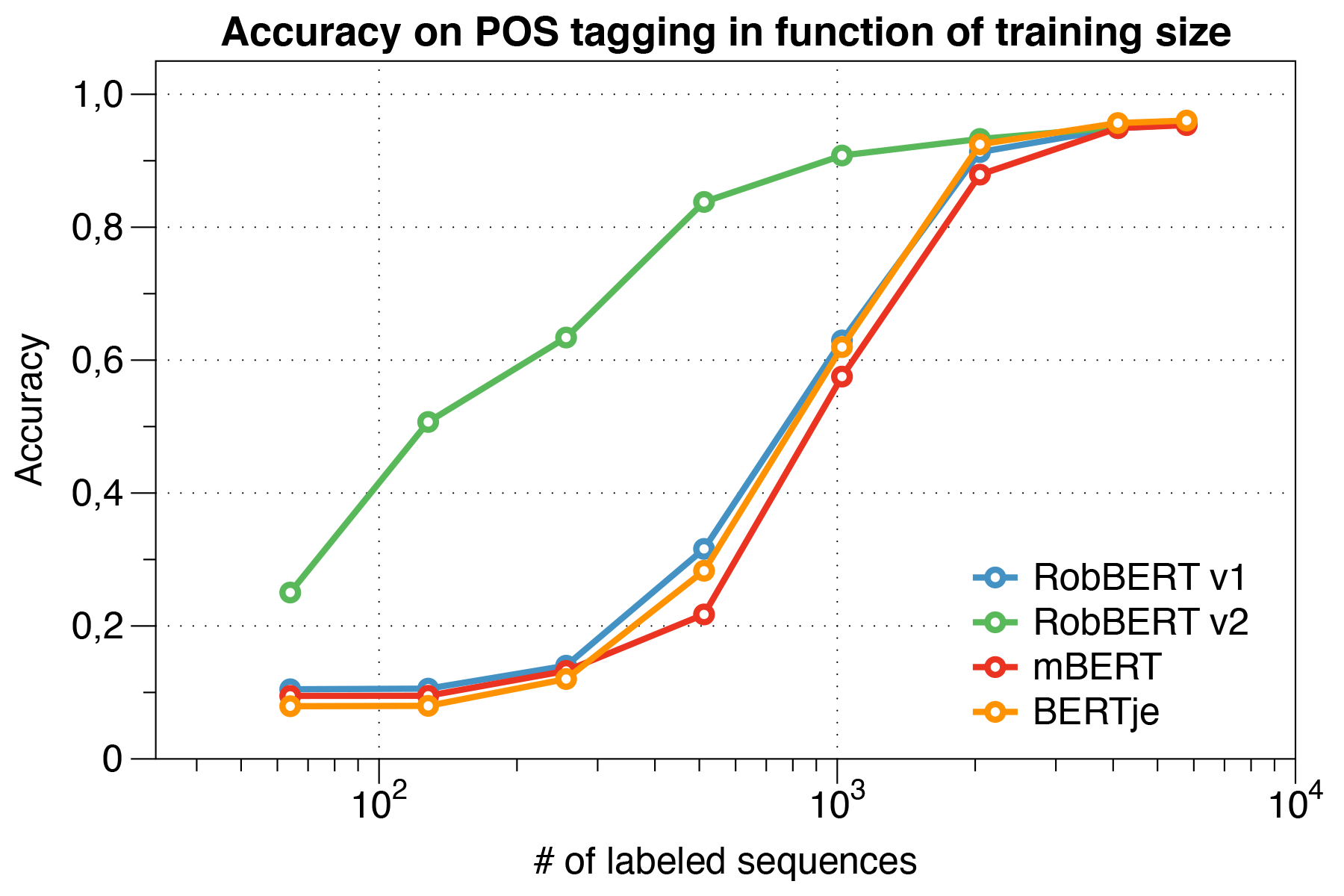
Использование сценария оценки Conll 2002.
| Модель | Точность [%] |
|---|---|
| Лягушка | 57.31 |
| Мберт | 90.94 |
| Берт-Нл | 89,7 |
| Бердье | 88.3 |
| Robbert v2 | 89.08 |
Мы предварительно обучили грабит, используя режим обучения Роберты. Мы предварительно обучили нашу модель на голландском участке Корпуса Оскара, большого многоязычного корпуса, которое было получено с помощью языковой классификации в общем корпусе. Этот голландский корпус составляет 39 ГБ, с 6,6 миллиардами слов, распределенных по 126 миллионам текста, где каждая строка может содержать несколько предложений, таким образом, используя больше данных, чем одновременно разработанные голландские модели BERT.
Robbert делится своей архитектурой с базовой моделью Роберты, которая сама представляет собой репликацию и улучшение по сравнению с Бертом. Как и Берт, это архитектура состоит из 12 слоев самосознания с 12 головами с 117-метровыми обучаемыми параметрами. Одно отличие с исходной моделью BERT связано с различной задачей предварительного обучения, указанной Робертой, используя только задачу MLM, а не задачу NSP. Во время предварительного обучения он только предсказывает, какие слова маскируются в определенных позициях заданных предложений. Процесс обучения использует оптимизатор ADAM с полиномиальным распадом скорости обучения L_R = 10^-6 и периода наращивания 1000 итераций, с гиперпараметрами Beta_1 = 0,9 и Робертой по умолчанию Beta_2 = 0,98. Кроме того, распад веса 0,1 и небольшой выпуск 0,1 помогает предотвратить переживание модели.
Робберт обучался на вычислительном кластере с 4 графическими процессорами NVIDIA P100 на узел, где количество узлов было динамически скорректировано при сохранении фиксированного размера партии 8192 предложений. Не более 20 узлов были использованы (то есть 80 графических процессоров), а медиана составляла 5 узлов. Используя накопление градиента, размер партии может быть установлен независимо от количества доступных графических процессоров, чтобы максимально использовать кластер. Используя библиотеку Fairseq, модель, обучающаяся для двух эпох, что в общей сложности равняется более 16 тысячам партий, что заняло около трех дней на вычислительном кластере. В промежутке между тренировочными заданиями в вычислительном кластере 2 Nvidia 1080 TI также охватывали некоторые обновления параметров для Robbert V2.
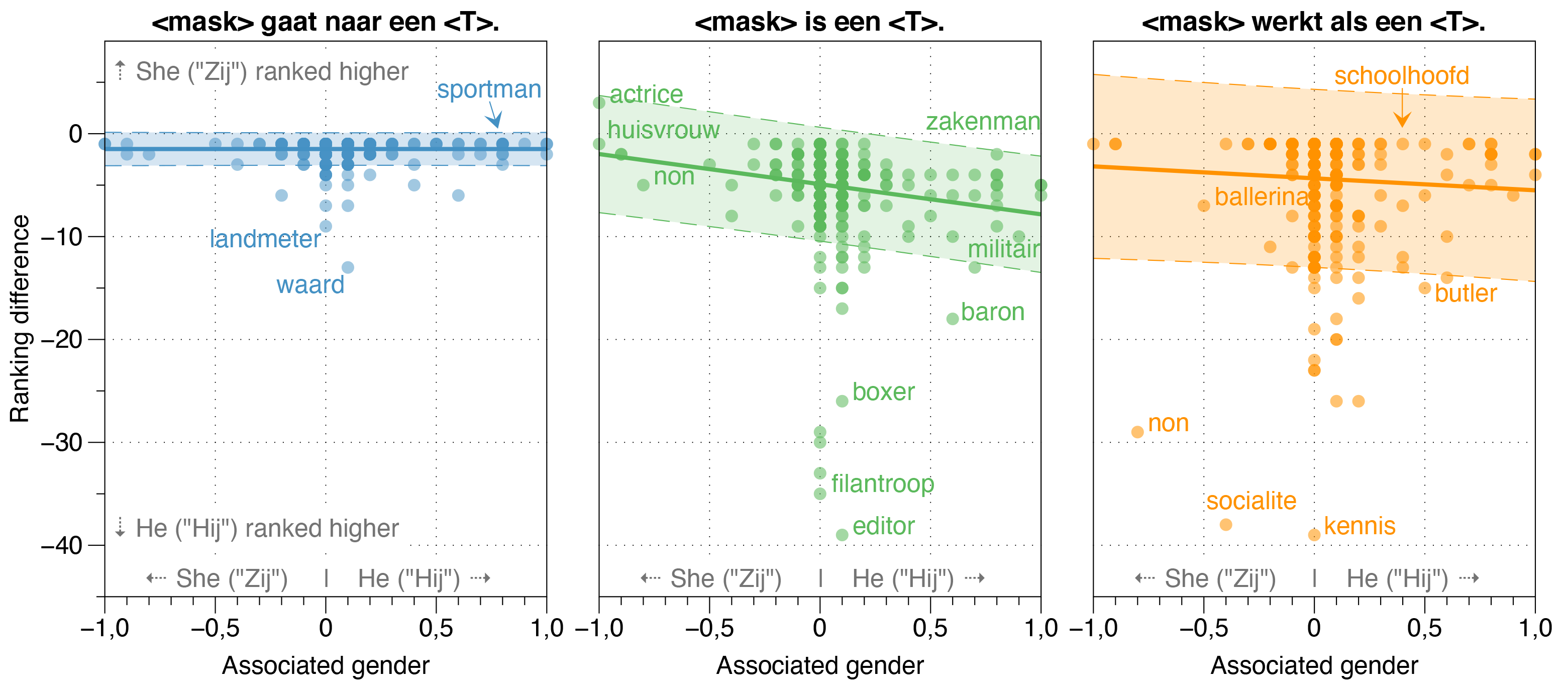
В газете грабит мы также исследовали потенциальные источники предвзятости в Robbert.
Мы обнаружили, что модель ZeroShot оценивает вероятность того, что HIJ (HE) будет выше, чем ZIJ (она) для большинства профессий в отбеленных шаблонных предложениях, независимо от их фактического соотношения рабочих мест в реальности.
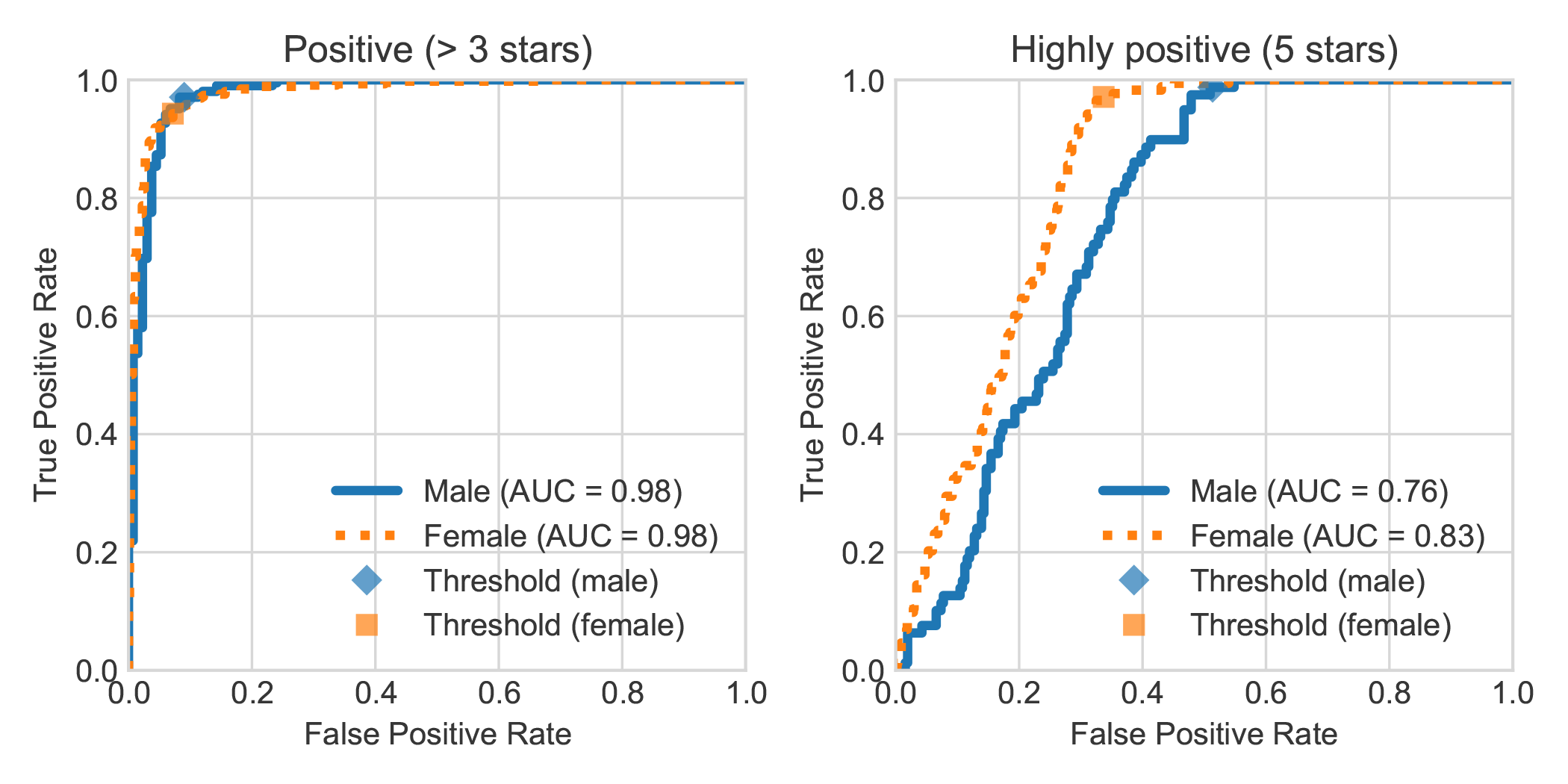
Увеличив набор данных анализа голландских книг DBRB с указанным полом автора обзора, мы обнаружили, что Робберт, написанные женщинами, были в целом более точно обнаружены как положительные, чем те, которые написаны мужчинами.
Вы можете повторить эксперименты, проведенные в нашей статье, выполнив следующие действия. Вы можете установить требуемые зависимости либо требования, либо Pipenv:
pip install -r requirements.txtpip install pipenv в вашем терминале), выполняя pipenv install .В этом разделе мы описываем, как использовать сценарии, которые мы предоставляем для моделей тонкой настройки, которые должны быть достаточно общими для повторного использования для других желаемых задач текстовой классификации.
data/raw/DBRDsrc/preprocess_dbrd.py , чтобы подготовить набор данных.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb чтобы Finetune The Model. Мы настраиваем нашу модель на голландском корпусе Европарла. Вы можете скачать его первым с помощью:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
В качестве проверки здравомыслия, теперь у вас должны быть следующие файлы в папке data/raw/europarl :
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
Затем вы можете запустить предварительную обработку с помощью следующего сценария, который заполняет сначала обрабатывать корпус Europarl для удаления предложений без какой -либо матрицы или DAT . После этого он перевернет местоимение и соединит оба предложения вместе с токеном <sep> .
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
Примечание. Вы можете отслеживать прогресс первого этапа предварительной обработки с помощью watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences . Это займет некоторое время, но это, конечно, не нужно использовать все входы. В конце концов, почему вы хотите использовать предварительно обученную языковую модель. Вы можете прекратить сценарий Python в любое время, а второй шаг будет использовать только их.
У большинства моделей, похожих на BERT, есть слово BERT в своем имени (например, Роберта, Альберт, Камаберт и многие, многие другие). Таким образом, мы запросили нашу недавно обученную модель, используя свою модель маскированного языка, чтобы назвать себя <Mask> BERT, используя все виды подсказок, и она последовательно называла себя Robbert. Мы подумали, что это действительно довольно уместно, учитывая, что Робберт - очень голландское имя (и, следовательно, явно голландская языковая модель) , и дополнительно имеет высокое сходство с корневой архитектурой, а именно Роберта.
Поскольку «Роб» - это голландские слова, обозначающие печать, мы решили нарисовать печать и одеть ее, как Берт с Улицы Сезам для логотипа Робберта.
Этот проект создан Питером Делобель, Томасом Уинтерсом и Беттиной Берендт.
Мы благодарны Лисбет Аллин за ее работу по устранению неоднозначности Di-Dat, Huggingface для их пакета Transformer, Facebook для их пакета Fairseq и всех других людей, чьи работы мы могли бы использовать.
Мы выпускаем наши модели и этот код под MIT.
Если вы хотите процитировать нашу статью или модель, вы можете использовать следующий код Bibtex:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


