RobBERT
v2.0

Robbert adalah model Bert Belanda yang canggih. Ini adalah model bahasa Belanda umum pra-terlatih besar yang dapat disesuaikan dengan dataset tertentu untuk melakukan klasifikasi teks, regresi, atau tugas penandaan token. Dengan demikian, telah berhasil digunakan oleh banyak peneliti dan praktisi untuk mencapai kinerja canggih untuk berbagai tugas pemrosesan bahasa alami Belanda, termasuk:
dan juga mencapai hasil yang luar biasa, dekat-sota untuk:
* Perhatikan bahwa beberapa evaluasi menggunakan Robbert-V1, dan bahwa Robbert-V2 yang kedua dan lebih baik mengungguli model pertama ini pada semua yang kami uji
;
Untuk menggunakan model Robbert menggunakan Transformers Huggingface, gunakan nama pdelobelle/robbert-v2-dutch-base .
Informasi yang lebih mendalam tentang Robbert dapat ditemukan di posting blog kami dan di makalah kami.
Robbert menggunakan arsitektur Roberta dan pra-pelatihan tetapi dengan tokenizer Belanda dan data pelatihan. Roberta adalah model Bert Inggris yang dioptimalkan dengan kuat, menjadikannya lebih kuat daripada model Bert asli. Mengingat arsitektur yang sama ini, Robbert dapat dengan mudah di -finetuned dan disimpulkan menggunakan kode untuk Finetune Roberta model dan sebagian besar kode yang digunakan untuk model BerT, misalnya sebagaimana disediakan oleh HuggingFace Transformers Library.
Robbert dapat dengan mudah digunakan dalam dua cara berbeda, yaitu menggunakan kode Fairseq Roberta atau menggunakan Transformers FaceFace
Secara default, Robbert memiliki kepala model bahasa bertopeng yang digunakan dalam pelatihan. Ini dapat digunakan sebagai cara zero-shot untuk mengisi topeng dalam kalimat. Ini dapat diuji secara gratis di API Huggingface yang di -host Robbert. Anda juga dapat membuat kepala prediksi baru untuk tugas Anda sendiri dengan menggunakan salah satu runna-runner HuggingFace, notebook yang menyempurnakan mereka dengan mengubah nama model menjadi pdelobelle/robbert-v2-dutch-base , atau menggunakan rezim pelatihan Fairseq Roberta asli.
Anda dapat dengan mudah mengunduh Robbert V2 menggunakan? Transformer. Gunakan kode berikut untuk mengunduh model dasar dan finetune sendiri, atau gunakan salah satu model finetuned kami (didokumentasikan di situs proyek kami).
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) Dimulai dengan transformers v2.4.0 (atau menginstal dari sumber), Anda dapat menggunakan AutoTokenizer dan Automodel. Anda kemudian dapat menggunakan sebagian besar notebook Bert HuggingFace untuk Finetuning Robbert pada jenis dataset bahasa Belanda Anda.
Atau, Anda juga dapat menggunakan Robbert menggunakan kode arsitektur Roberta. Anda dapat mengunduh model Fairseq Robbert V2 di sini: (Robbert-base, 1,5 GB). Menggunakan Robbert's model.pt , metode ini memungkinkan Anda untuk menggunakan semua fungsi lainnya dari Roberta.
Semua percobaan dijelaskan secara lebih rinci dalam makalah kami, dengan kode di repositori GitHub kami.
Memprediksi apakah suatu tinjauan positif atau negatif menggunakan dataset ulasan buku Belanda.
| Model | Akurasi [%] |
|---|---|
| Ulmfit | 93.8 |
| Bertje | 93.0 |
| Robbert V2 | 95.1 |
Kami mengukur seberapa baik model dapat melakukan resolusi coreference dengan memprediksi apakah "mati" atau "dat" harus diisi ke dalam kalimat. Untuk ini, kami menggunakan korpus Europarl.
| Model | Akurasi [%] | F1 [%] |
|---|---|---|
| Baseline (LSTM) | 75.03 | |
| mbert | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| Robbert V2 | 99.232 | 99.121 |
Kami juga mengukur kinerja hanya menggunakan 10K contoh pelatihan. Eksperimen ini dengan jelas menggambarkan bahwa Robbert mengungguli model lain ketika ada sedikit data yang tersedia.
| Model | Akurasi [%] | F1 [%] |
|---|---|---|
| mbert | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| Robbert V2 | 97.816 | 97.514 |
Karena model BERT dilatih sebelumnya menggunakan tugas masking kata, kita dapat menggunakan ini untuk memprediksi apakah "mati" atau "dat" lebih mungkin. Eksperimen ini menunjukkan bahwa Robbert telah menginternalisasi lebih banyak informasi tentang Belanda daripada model lainnya.
| Model | Akurasi [%] |
|---|---|
| Zeror | 66.70 |
| mbert | 90.21 |
| Bertje | 94.94 |
| Robbert V2 | 98.75 |
Menggunakan dataset Lassy UD.
| Model | Akurasi [%] |
|---|---|
| Katak | 91.7 |
| mbert | 96.5 |
| Bertje | 96.3 |
| Robbert V2 | 96.4 |
Menariknya, kami menemukan bahwa ketika berhadapan dengan set data kecil , Robbert V2 secara signifikan mengungguli model lain.
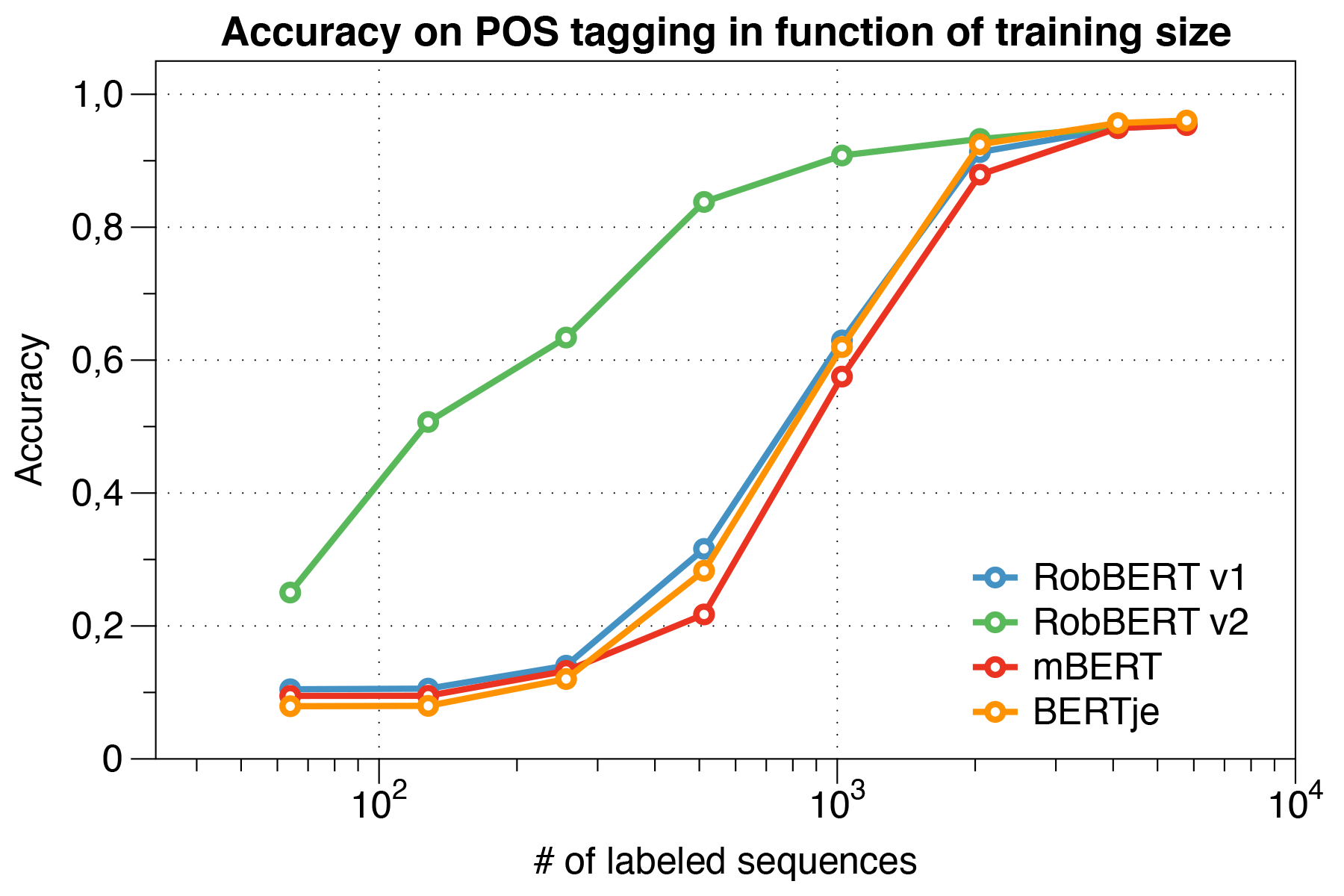
Menggunakan skrip evaluasi CONLL 2002.
| Model | Akurasi [%] |
|---|---|
| Katak | 57.31 |
| mbert | 90.94 |
| Bert-NL | 89.7 |
| Bertje | 88.3 |
| Robbert V2 | 89.08 |
Kami pra-terlatih Robbert menggunakan rezim pelatihan Roberta. Kami melakukan pra-terlatih model kami di bagian Belanda dari Oscar Corpus, sebuah korpus multibahasa besar yang diperoleh dengan klasifikasi bahasa dalam corpus perayapan umum. Corpus Belanda ini besar 39GB, dengan 6,6 miliar kata tersebar di 126 juta baris teks, di mana setiap baris dapat berisi beberapa kalimat, sehingga menggunakan lebih banyak data daripada model Bert Belanda yang dikembangkan secara bersamaan.
Robbert berbagi arsitekturnya dengan model dasar Roberta, yang dengan sendirinya merupakan replikasi dan peningkatan atas Bert. Seperti Bert, arsitekturnya terdiri dari 12 lapisan perhatian diri dengan 12 kepala dengan 117 juta parameter yang dapat dilatih. Satu perbedaan dengan model Bert asli adalah karena tugas pra-pelatihan yang berbeda yang ditentukan oleh Roberta, hanya menggunakan tugas MLM dan bukan tugas NSP. Selama pra-pelatihan, dengan demikian hanya memprediksi kata-kata mana yang ditutupi dalam posisi tertentu dari kalimat yang diberikan. Proses pelatihan menggunakan Adam Optimizer dengan peluruhan polinomial dari tingkat pembelajaran L_R = 10^-6 dan periode ramp-up dari 1000 iterasi, dengan hyperparameters beta_1 = 0,9 dan Beta_2 default Roberta = 0,98. Selain itu, pembusukan berat 0,1 dan dropout kecil 0,1 membantu mencegah model overfitting.
Robbert dilatih pada kluster komputasi dengan 4 NVIDIA P100 GPU per node, di mana jumlah node disesuaikan secara dinamis sambil menjaga ukuran batch tetap dari 8192 kalimat. Paling banyak 20 node digunakan (yaitu 80 GPU), dan mediannya adalah 5 node. Dengan menggunakan akumulasi gradien, ukuran batch dapat diatur secara independen dari jumlah GPU yang tersedia, untuk memanfaatkan cluster secara maksimal. Menggunakan perpustakaan Fairseq, model yang dilatih untuk dua zaman, yang sama dengan total lebih dari 16k batch, yang memakan waktu sekitar tiga hari pada cluster komputasi. Di sela -sela pelatihan pekerjaan di kluster komputasi, 2 NVIDIA 1080 TI juga mencakup beberapa pembaruan parameter untuk Robbert V2.
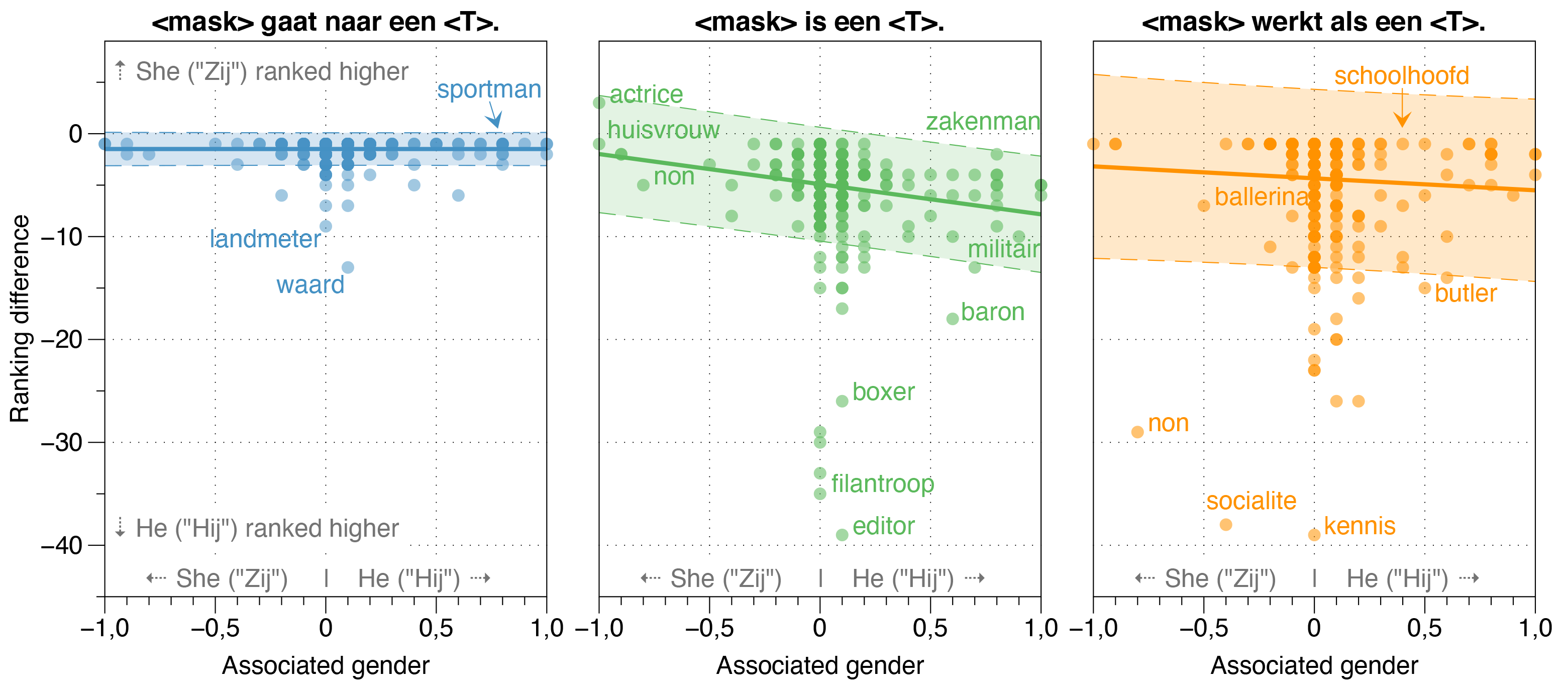
Di koran Robbert, kami juga menyelidiki sumber bias potensial di Robbert.
Kami menemukan bahwa model Zeroshot memperkirakan probabilitas Hij (dia) lebih tinggi dari Zij (dia) untuk sebagian besar pekerjaan dalam kalimat template yang diputihkan, terlepas dari rasio gender pekerjaan mereka yang sebenarnya dalam kenyataan.
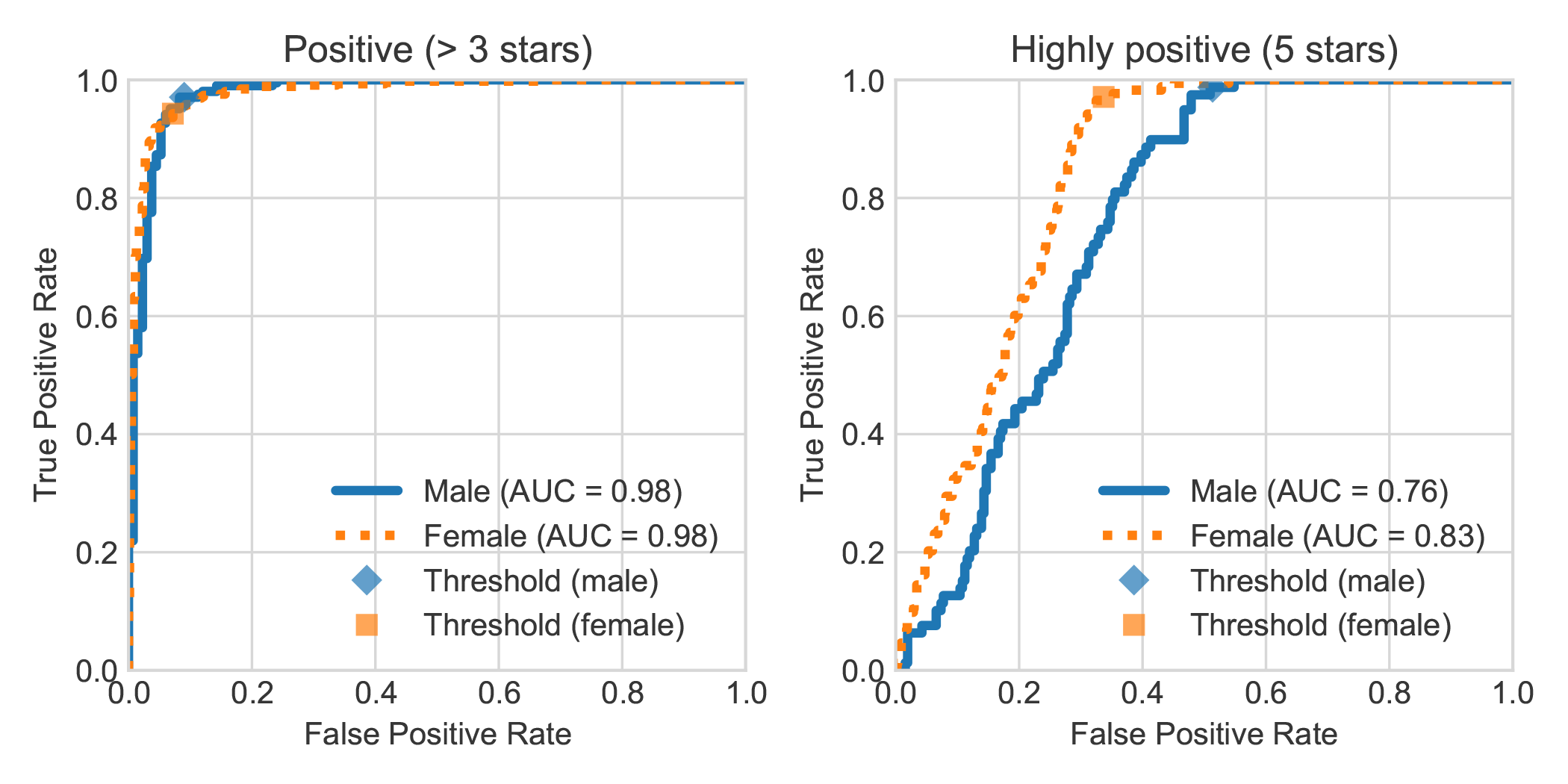
Dengan menambah dataset analisis sentimen buku Belanda DBRB dengan jenis kelamin penulis ulasan yang dinyatakan, kami menemukan bahwa ulasan yang sangat positif yang ditulis oleh perempuan umumnya lebih akurat terdeteksi oleh Robbert sebagai positif daripada yang ditulis oleh laki -laki.
Anda dapat mereplikasi eksperimen yang dilakukan dalam makalah kami dengan mengikuti langkah -langkah berikut. Anda dapat menginstal dependensi yang diperlukan baik persyaratan.txt atau Pipenv:
pip install -r requirements.txtpip install pipenv di terminal Anda) dengan menjalankan pipenv install .Pada bagian ini kami menjelaskan cara menggunakan skrip yang kami berikan untuk menyempurnakan model, yang seharusnya cukup umum untuk digunakan kembali untuk tugas klasifikasi tekstual yang diinginkan lainnya.
data/raw/DBRDsrc/preprocess_dbrd.py untuk menyiapkan dataset.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb untuk finetune model. Kami menyempurnakan model kami di Europarl Corpus Belanda. Anda dapat mengunduhnya terlebih dahulu dengan:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
Sebagai pemeriksaan kewarasan, sekarang Anda harus memiliki file berikut di folder data/raw/europarl Anda:
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
Kemudian Anda dapat menjalankan preprocessing dengan skrip berikut, yang mengisi terlebih dahulu memproses korpus Europarl untuk menghapus kalimat tanpa mati atau dat . Setelah itu, itu akan membalik kata ganti dan bergabung dengan kedua kalimat bersama dengan token <sep> .
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
Catatan: Anda dapat memantau kemajuan langkah preprocessing pertama dengan watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences . Ini akan memakan waktu, tetapi tentu saja tidak perlu menggunakan semua input. Bagaimanapun, inilah mengapa Anda ingin menggunakan model bahasa yang sudah terlatih. Anda dapat mengakhiri skrip Python kapan saja dan langkah kedua hanya akan menggunakannya._
Sebagian besar model Bert memiliki kata Bert dalam nama mereka (misalnya Roberta, Albert, Camembert, dan banyak, banyak lainnya). Dengan demikian, kami menanyakan model kami yang baru terlatih menggunakan model bahasa bertopengnya untuk menyebutkan dirinya <sh Mask> Bert menggunakan semua jenis petunjuk, dan secara konsisten menyebut dirinya Robbert. Kami pikir itu benar -benar sangat pas, mengingat bahwa Robbert adalah nama yang sangat Belanda (dan dengan demikian jelas model bahasa Belanda) , dan juga memiliki kemiripan yang tinggi dengan arsitektur root, yaitu Roberta.
Karena "Rob" adalah kata -kata Belanda untuk menunjukkan segel, kami memutuskan untuk menggambar segel dan mendandani seperti Bert dari Sesame Street untuk logo Robbert.
Proyek ini dibuat oleh Pieter Delobelle, Thomas Winters dan Bettina Berendt.
Kami berterima kasih kepada Liesbeth Alein, atas pekerjaannya tentang disambiguasi mati-dat, Huggingface untuk paket transformator mereka, Facebook untuk paket Fairseq mereka dan semua orang lain yang pekerjaannya dapat kami gunakan.
Kami merilis model kami dan kode ini di bawah MIT.
Jika Anda ingin mengutip kertas atau model kami, Anda dapat menggunakan kode BIBTEX berikut:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


