RobBERT
v2.0

Robbert เป็นแบบจำลองเบิร์ตดัตช์ล้ำสมัย มันเป็นรูปแบบภาษาภาษาดัตช์ทั่วไปที่ผ่านการฝึกอบรมมาก่อนซึ่งสามารถปรับแต่งได้อย่างละเอียดในชุดข้อมูลที่กำหนดเพื่อดำเนินการจัดประเภทข้อความการถดถอยหรืองานแท็กโทเค็น ดังนั้นจึงมีการใช้งานโดยนักวิจัยและผู้ปฏิบัติงานหลายคนเพื่อให้บรรลุประสิทธิภาพที่ทันสมัยสำหรับงานการประมวลผลภาษาธรรมชาติที่หลากหลายของดัตช์รวมถึง::
และยังได้ผลลัพธ์ที่โดดเด่นใกล้กับ SOTA สำหรับ:
* โปรดทราบว่าการประเมินผลหลายครั้งใช้ Robbert-V1 และการปรับปรุงที่สองและปรับปรุงให้ดีขึ้นเหนือกว่ารุ่นแรกนี้ในทุกสิ่งที่เราทดสอบ
(โปรดทราบว่ารายการนี้ไม่ครบถ้วนสมบูรณ์หากคุณใช้ Robbert สำหรับแอปพลิเคชันของคุณเรายินดีที่จะรู้เกี่ยวกับเรื่องนี้! ส่งจดหมายถึงเราหรือเพิ่มด้วยตัวคุณเองในรายการนี้โดยส่งคำขอดึงด้วยการแก้ไข!)
หากต้องการใช้โมเดล Robbert โดยใช้ Transformers HuggingFace ให้ใช้ชื่อ pdelobelle/robbert-v2-dutch-base
ข้อมูลเชิงลึกเพิ่มเติมเกี่ยวกับ Robbert สามารถพบได้ในโพสต์บล็อกของเราและในบทความของเรา
Robbert ใช้สถาปัตยกรรม Roberta และการฝึกอบรมล่วงหน้า แต่มีโทเค็นดัตช์และข้อมูลการฝึกอบรม Roberta เป็นรุ่น Bert ภาษาอังกฤษที่ได้รับการปรับปรุงอย่างดีทำให้มีประสิทธิภาพยิ่งกว่ารุ่น Bert ดั้งเดิม ด้วยสถาปัตยกรรมเดียวกันนี้ Robbert สามารถ finetuned และอนุมานได้อย่างง่ายดายโดยใช้รหัสไปยังรุ่น Finetune Roberta และรหัสส่วนใหญ่ที่ใช้สำหรับรุ่น Bert เช่นตามที่จัดทำโดย HuggingFace Transformers Library
Robbert สามารถใช้งานได้อย่างง่ายดายสองวิธีคือการใช้รหัส Fairseq Roberta หรือใช้ Transformers HuggingFace
โดยค่าเริ่มต้น Robbert มีหัวโมเดลภาษาที่สวมหน้ากากที่ใช้ในการฝึกอบรม สิ่งนี้สามารถใช้เป็นวิธีการช็อตเป็นศูนย์ในการเติมมาสก์ในประโยค มันสามารถทดสอบได้ฟรีบน API ของ Robbert ที่เป็นเจ้าภาพของ HuggingFace นอกจากนี้คุณยังสามารถสร้างหัวการทำนายใหม่สำหรับงานของคุณเองโดยใช้ Roberta-Runners ของ HuggingFace, สมุดบันทึกการปรับแต่งของพวกเขาโดยการเปลี่ยนชื่อโมเดลเป็น pdelobelle/robbert-v2-dutch-base หรือใช้ระบบฝึกอบรม Fairseq Roberta ดั้งเดิม
คุณสามารถดาวน์โหลด Robbert V2 ได้อย่างง่ายดายโดยใช้? หม้อแปลง ใช้รหัสต่อไปนี้เพื่อดาวน์โหลดโมเดลพื้นฐานและ finetune ด้วยตัวคุณเองหรือใช้หนึ่งในโมเดล Finetuned ของเรา (บันทึกไว้ในเว็บไซต์โครงการของเรา)
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) เริ่มต้นด้วย transformers v2.4.0 (หรือติดตั้งจากแหล่งที่มา) คุณสามารถใช้ AutoTokenizer และ Automodel จากนั้นคุณสามารถใช้สมุดบันทึกที่ใช้ Bert ของ HuggingFace ส่วนใหญ่สำหรับ Finetuning Robbert ในชุดข้อมูลภาษาดัตช์ของคุณ
หรือคุณสามารถใช้ Robbert โดยใช้รหัสสถาปัตยกรรม Roberta คุณสามารถดาวน์โหลดโมเดล Fairseq ของ Robbert V2 ได้ที่นี่: (Robbert-Base, 1.5 GB) การใช้ model.pt ของ Robbert วิธีนี้ช่วยให้คุณสามารถใช้ฟังก์ชันอื่น ๆ ทั้งหมดของ Roberta
การทดลองทั้งหมดมีการอธิบายรายละเอียดเพิ่มเติมในบทความของเราด้วยรหัสในที่เก็บ GitHub ของเรา
การทำนายว่าการทบทวนเป็นบวกหรือลบโดยใช้ชุดข้อมูลรีวิวหนังสือภาษาดัตช์
| แบบอย่าง | ความแม่นยำ [%] |
|---|---|
| ulmfit | 93.8 |
| เบิร์ตเจ | 93.0 |
| Robbert v2 | 95.1 |
เราวัดว่าแบบจำลองนั้นสามารถทำความละเอียด coreference ได้ดีเพียงใดโดยทำนายว่า "ตาย" หรือ "dat" ควรกรอกลงในประโยคหรือไม่ สำหรับสิ่งนี้เราใช้ Europarl Corpus
| แบบอย่าง | ความแม่นยำ [%] | F1 [%] |
|---|---|---|
| พื้นฐาน (LSTM) | 75.03 | |
| Mbert | 98.285 | 98.033 |
| เบิร์ตเจ | 98.268 | 98.014 |
| Robbert v2 | 99.232 | 99.121 |
นอกจากนี้เรายังวัดประสิทธิภาพโดยใช้ตัวอย่างการฝึกอบรมเพียง 10k การทดลองนี้แสดงให้เห็นอย่างชัดเจนว่า Robbert มีประสิทธิภาพสูงกว่ารุ่นอื่น ๆ เมื่อมีข้อมูลน้อย
| แบบอย่าง | ความแม่นยำ [%] | F1 [%] |
|---|---|---|
| Mbert | 92.157 | 90.898 |
| เบิร์ตเจ | 93.096 | 91.279 |
| Robbert v2 | 97.816 | 97.514 |
เนื่องจากโมเดล Bert ได้รับการฝึกอบรมล่วงหน้าโดยใช้งานการปิดบังคำเราจึงสามารถใช้สิ่งนี้เพื่อทำนายว่า "ตาย" หรือ "dat" มีแนวโน้มมากขึ้น การทดลองนี้แสดงให้เห็นว่า Robbert ได้ให้ข้อมูลเกี่ยวกับภาษาดัตช์มากกว่ารุ่นอื่น ๆ
| แบบอย่าง | ความแม่นยำ [%] |
|---|---|
| Zeror | 66.70 |
| Mbert | 90.21 |
| เบิร์ตเจ | 94.94 |
| Robbert v2 | 98.75 |
ใช้ชุดข้อมูล UD Lassy
| แบบอย่าง | ความแม่นยำ [%] |
|---|---|
| กบ | 91.7 |
| Mbert | 96.5 |
| เบิร์ตเจ | 96.3 |
| Robbert v2 | 96.4 |
ที่น่าสนใจเราพบว่าเมื่อจัดการกับ ชุดข้อมูลขนาดเล็ก Robbert V2 มีประสิทธิภาพสูงกว่า รุ่นอื่น ๆ
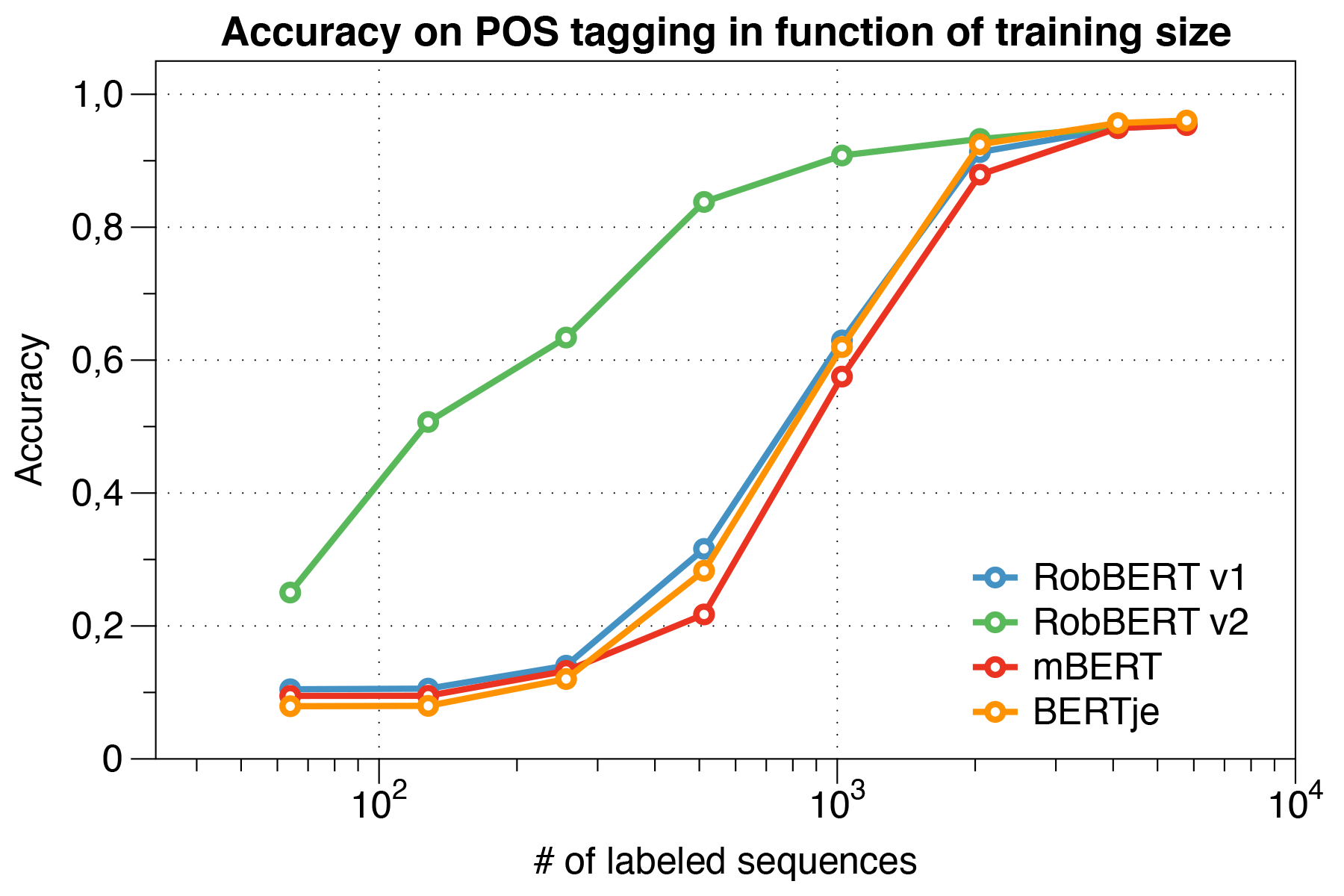
ใช้สคริปต์การประเมินผล Conll 2002
| แบบอย่าง | ความแม่นยำ [%] |
|---|---|
| กบ | 57.31 |
| Mbert | 90.94 |
| Bert-NL | 89.7 |
| เบิร์ตเจ | 88.3 |
| Robbert v2 | 89.08 |
เราได้รับการฝึกฝนมาก่อน Robbert โดยใช้ระบอบการฝึกอบรมของ Roberta เราได้รับการฝึกอบรมแบบจำลองของเราล่วงหน้าในส่วนดัตช์ของ Oscar Corpus ซึ่งเป็นคลังข้อมูลหลายภาษาที่มีขนาดใหญ่ซึ่งได้มาจากการจำแนกภาษาในคลังข้อมูลการรวบรวมข้อมูลทั่วไป คลังข้อมูลดัตช์นี้มีขนาดใหญ่ 39GB โดยมีคำ 6.6 พันล้านคำแพร่กระจายมากกว่า 126 ล้านบรรทัดของข้อความซึ่งแต่ละบรรทัดอาจมีหลายประโยคดังนั้นใช้ข้อมูลมากกว่าแบบจำลองเบิร์ตดัตช์ที่พัฒนาขึ้นพร้อมกัน
Robbert แบ่งปันสถาปัตยกรรมกับโมเดลพื้นฐานของ Roberta ซึ่งเป็นตัวจำลองและปรับปรุง Bert เช่นเดียวกับเบิร์ตสถาปัตยกรรมประกอบด้วย 12 เลเยอร์การใส่ใจในตัวเองที่มี 12 หัวด้วยพารามิเตอร์การฝึกอบรมที่สามารถฝึกอบรมได้ 117 ม. ความแตกต่างอย่างหนึ่งกับโมเดล Bert ดั้งเดิมนั้นเกิดจากงานการฝึกอบรมล่วงหน้าที่แตกต่างกันที่ระบุโดย Roberta โดยใช้เฉพาะงาน MLM และไม่ใช่งาน NSP ในระหว่างการฝึกอบรมก่อนจึงคาดการณ์ว่าคำใดจะถูกปิดบังในบางตำแหน่งของประโยคที่กำหนด กระบวนการฝึกอบรมใช้ Adam Optimizer ที่มีการสลายตัวของพหุนามของอัตราการเรียนรู้ L_R = 10^-6 และระยะเวลาการทำซ้ำ 1,000 การวนซ้ำด้วย HyperParameters BETA_1 = 0.9 และ BETA_2 ที่เริ่มต้นของ Roberta = 0.98 นอกจากนี้การสลายตัวของน้ำหนัก 0.1 และการออกกลางคันขนาดเล็กที่ 0.1 ช่วยป้องกันไม่ให้โมเดลไม่ได้รับมากเกินไป
Robbert ได้รับการฝึกฝนเกี่ยวกับคลัสเตอร์คอมพิวเตอร์ที่มี 4 Nvidia P100 GPU ต่อโหนดซึ่งจำนวนโหนดถูกปรับแบบไดนามิกในขณะที่รักษาขนาดแบทช์คงที่ 8192 ประโยค ส่วนใหญ่ 20 โหนดถูกใช้ (เช่น 80 GPU) และค่ามัธยฐานคือ 5 โหนด ด้วยการใช้การสะสมการไล่ระดับสีขนาดแบทช์สามารถตั้งค่าได้อย่างอิสระจากจำนวน GPU ที่มีอยู่เพื่อใช้ประโยชน์จากคลัสเตอร์มากที่สุด ด้วยการใช้ไลบรารี Fairseq รุ่นที่ผ่านการฝึกอบรมสำหรับสองยุคซึ่งเท่ากับรวมกว่า 16k แบทช์ทั้งหมดซึ่งใช้เวลาประมาณสามวันในคลัสเตอร์คอมพิวเตอร์ ในระหว่างการฝึกอบรมงานบนคลัสเตอร์คอมพิวเตอร์ 2 Nvidia 1080 TI ยังครอบคลุมการอัปเดตพารามิเตอร์สำหรับ Robbert V2
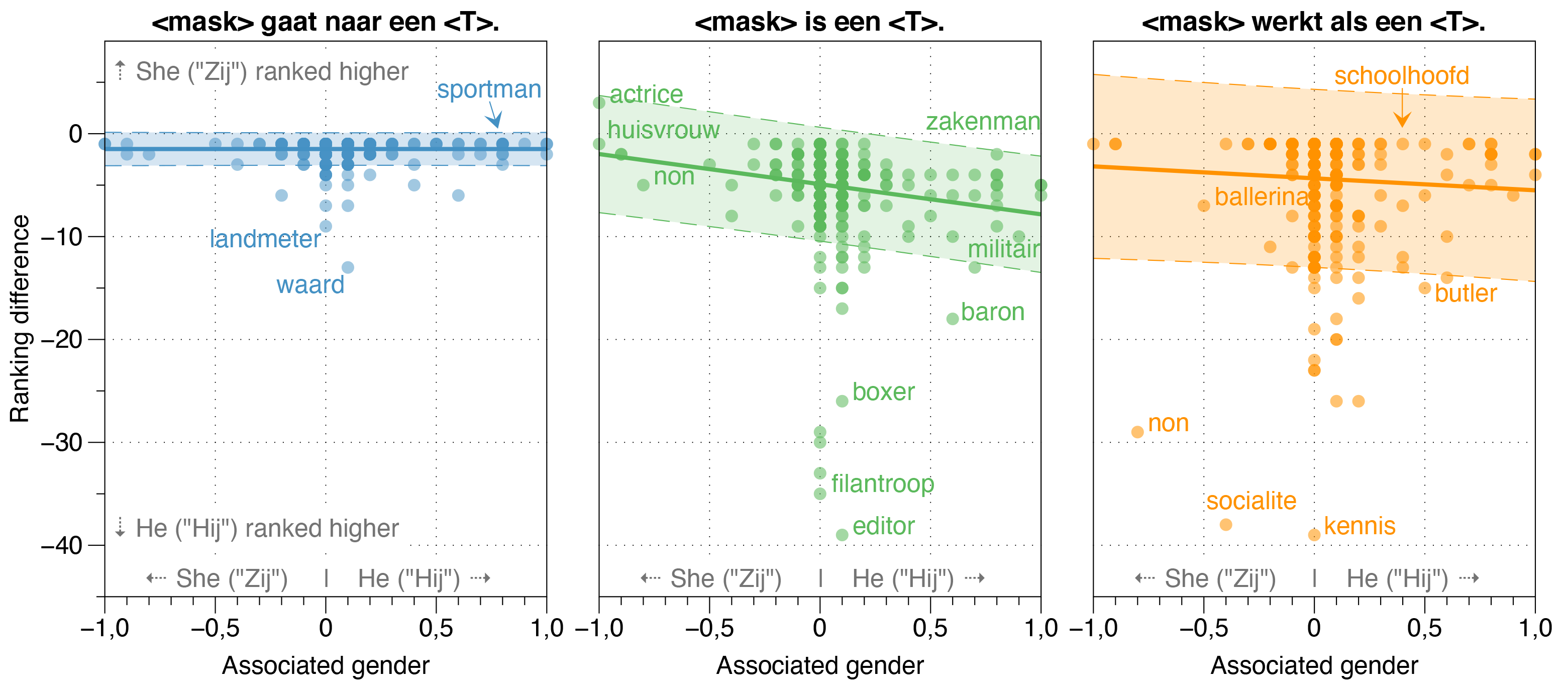
ในกระดาษ Robbert เรายังตรวจสอบแหล่งที่มาของอคติใน Robbert
เราพบว่าโมเดล ZeroShot ประเมินความน่าจะเป็นของ Hij (HE) ที่สูงกว่า Zij (เธอ) สำหรับอาชีพส่วนใหญ่ในประโยคเทมเพลตฟอกขาวโดยไม่คำนึงถึงอัตราส่วนเพศงานจริงของพวกเขาในความเป็นจริง
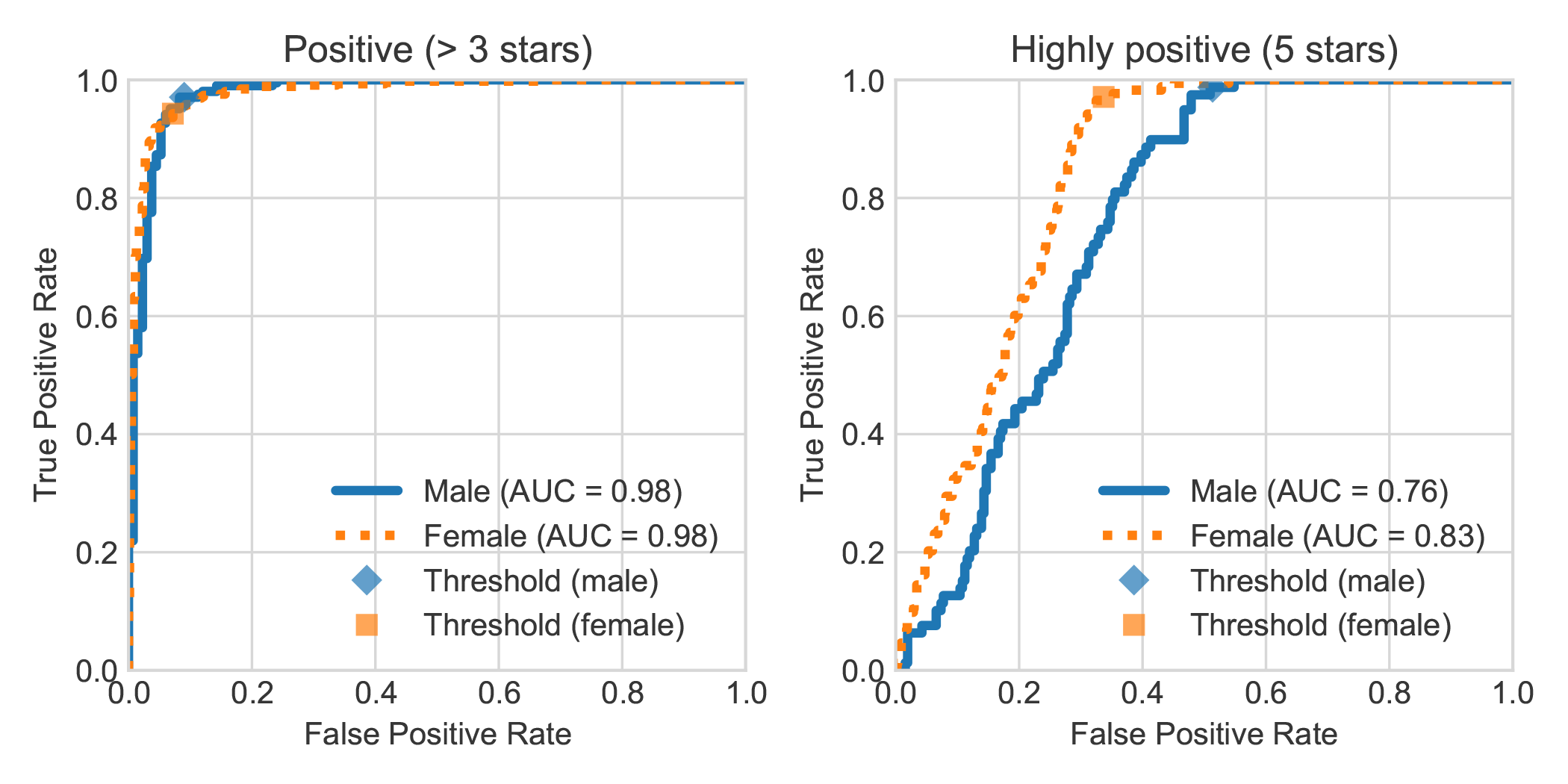
ด้วยการเพิ่มชุดข้อมูลการวิเคราะห์ความเชื่อมั่นของหนังสือ DBRB ดัตช์ด้วยเพศที่ระบุไว้ของผู้เขียนบทวิจารณ์เราพบว่าบทวิจารณ์ที่เป็นบวกอย่างมากที่เขียนโดยผู้หญิงมักตรวจพบได้อย่างแม่นยำมากขึ้นโดย Robbert ว่าเป็นบวกมากกว่าที่เขียนโดยผู้ชาย
คุณสามารถทำซ้ำการทดลองที่ทำในบทความของเราโดยทำตามขั้นตอนต่อไปนี้ คุณสามารถติดตั้งการอ้างอิงที่ต้องการไม่ว่าจะเป็นข้อกำหนด TXT หรือ PIPENV:
pip install -r requirements.txtpip install pipenv ในเทอร์มินัลของคุณ) โดยใช้การ pipenv installในส่วนนี้เราอธิบายถึงวิธีการใช้สคริปต์ที่เราจัดเตรียมไว้เพื่อปรับแต่งแบบจำลองซึ่งควรจะเป็นเรื่องทั่วไปพอที่จะนำกลับมาใช้ใหม่สำหรับงานการจำแนกประเภทข้อความอื่น ๆ ที่ต้องการ
data/raw/DBRDsrc/preprocess_dbrd.py เพื่อเตรียมชุดข้อมูลsrc/split_dbrd_training.shnotebooks/finetune_dbrd.ipynb เพื่อ finetune รุ่น เราปรับโมเดลของเราในคลังข้อมูลของ Europarl Dutch คุณสามารถดาวน์โหลดได้ก่อนด้วย:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
เพื่อตรวจสอบสติตอนนี้คุณควรมีไฟล์ต่อไปนี้ในโฟลเดอร์ data/raw/europarl ของคุณ:
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
จากนั้นคุณสามารถเรียกใช้การประมวลผลล่วงหน้าด้วยสคริปต์ต่อไปนี้ซึ่งเติมกระบวนการแรกของ Europarl Corpus เพื่อลบประโยคโดยไม่ต้อง ตาย หรือ dat หลังจากนั้นมันจะพลิกคำสรรพนามและเข้าร่วมทั้งสองประโยคพร้อมกับโทเค็น <sep>
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
หมายเหตุ: คุณสามารถตรวจสอบความคืบหน้าของขั้นตอนการประมวลผลล่วงหน้าครั้งแรกด้วย watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences จะใช้เวลาสักครู่ แต่ก็ไม่จำเป็นต้องใช้อินพุตทั้งหมด นี่คือเหตุผลที่คุณต้องการใช้รูปแบบภาษาที่ผ่านการฝึกอบรมมาก่อน คุณสามารถยกเลิกสคริปต์ Python ได้ตลอดเวลาและขั้นตอนที่สองจะใช้เฉพาะนั้น _
โมเดลที่มีลักษณะคล้ายเบิร์ตส่วนใหญ่มีคำว่า เบิร์ต ในชื่อของพวกเขา (เช่น Roberta, Albert, Camembert และอื่น ๆ อีกมากมาย) ดังนั้นเราจึงสอบถามโมเดลที่ผ่านการฝึกอบรมใหม่ของเราโดยใช้รูปแบบภาษาที่สวมหน้ากากเพื่อตั้งชื่อตัวเอง <mask> เบิร์ต โดยใช้พรอมต์ทุกชนิดและเรียกตัวเองว่าร็อบเบิร์ตอย่างสม่ำเสมอ เราคิดว่ามันค่อนข้างเหมาะสมเพราะ Robbert เป็นชื่อดัตช์ มาก (และเป็นรูปแบบภาษาดัตช์ที่ชัดเจน) และนอกจากนี้ยังมีความคล้ายคลึงกันสูงกับสถาปัตยกรรมรากของมันคือ Roberta
เนื่องจาก "Rob" เป็นคำภาษาดัตช์ที่แสดงถึงตราประทับเราจึงตัดสินใจวาดตราประทับและแต่งตัวเหมือนเบิร์ตจากเซซามีสตรีทเพื่อโลโก้ Robbert
โครงการนี้สร้างขึ้นโดย Pieter Delobelle, Thomas Winters และ Bettina Berendt
เราขอขอบคุณ Liesbeth Allein สำหรับการทำงานของเธอเกี่ยวกับ Die-Dat Disambiguation, HuggingFace สำหรับแพ็คเกจ Transformer, Facebook สำหรับแพ็คเกจ Fairseq และคนอื่น ๆ ที่เราสามารถใช้งานได้
เราปล่อยโมเดลของเราและรหัสนี้ภายใต้ MIT
หากคุณต้องการอ้างอิงกระดาษหรือโมเดลของเราคุณสามารถใช้รหัส BibTex ต่อไปนี้:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


