RobBERT
v2.0

ロバートは、最先端のオランダのバートモデルです。これは、特定のデータセットで微調整してテキスト分類、回帰、またはトークンタグを実行するタスクを実行することができる大規模な事前に訓練された一般的なオランダ語モデルです。そのため、多くの研究者や実践者が、以下を含む幅広いオランダの自然言語処理タスクの最先端のパフォーマンスを達成するために成功裏に使用されています。
また、次のような傑出した、近視結果も達成されました。
*いくつかの評価がRobbert-V1を使用しており、2番目と改善されたRobbert-V2がこの最初のモデルをテストしたすべてのモデルよりも優れていることに注意してください。
(また、このリストは網羅的ではないことに注意してください。Robbertをアプリケーションに使用した場合、私たちはそれについて知ってうれしいです!メールを送信するか、編集でプルリクエストを送信してこのリストに自分で追加してください!)
Huggingface Transformersを使用してRobbertモデルを使用するには、 pdelobelle/robbert-v2-dutch-base名前を使用します。
ロババートに関するより詳細な情報は、ブログ投稿と私たちの論文にあります。
ロバートは、ロバータの建築とトレーニング前を使用していますが、オランダのトークネイザーとトレーニングデータを使用しています。 Robertaは、堅牢に最適化された英語のBertモデルであり、元のBertモデルよりもさらに強力です。これと同じアーキテクチャを考えると、ロバートは簡単に微調整され、コードを使用してロベルタモデルとBERTモデルに使用されるほとんどのコードを使用して推測することができます。
ロババートは、2つの異なる方法で簡単に使用できます。つまり、FairSeq Robertaコードを使用するか、ハギングフェイストランス
デフォルトでは、Robbertにはトレーニングで使用されるマスクされた言語モデルヘッドがあります。これは、文のマスクを埋めるためのゼロショット方法として使用できます。 Huggingfaceのロバートのホストされた推論APIで無料でテストすることができます。また、モデル名をpdelobelle/robbert-v2-dutch-baseに変更することにより、HuggingfaceのRoberta-Runners、微調整されたノートブックを使用することで、独自のタスクの新しい予測ヘッドを作成するか、元のFairSeq Robertaトレーニング体制を使用することもできます。
Robbert V2を使用して簡単にダウンロードできますか?トランス。次のコードを使用して、ベースモデルをダウンロードして自分でFinetuneを使用するか、Finetunedモデルのいずれかを使用します(プロジェクトサイトに記載されています)。
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) transformers v2.4.0 (またはソースからのインストール)から始めて、オートトケン装置とAutomodelを使用できます。その後、オランダ語データセットのタイプでロブバートを獲得するために、HuggingfaceのBertベースのノートブックのほとんどを使用できます。
または、Roberta Architecture Codeを使用してRobbertを使用することもできます。 Robbert V2のFairSeqモデルをこちらからダウンロードできます:(Robbert-Base、1.5 GB)。 Robbert's model.ptを使用して、この方法では、Robertaの他のすべての機能を使用できます。
すべての実験については、GitHubリポジトリにコードを使用して、ペーパーで詳細に説明されています。
オランダの書籍レビューデータセットを使用して、レビューが肯定的か否定的かを予測します。
| モデル | 正確さ [%] |
|---|---|
| ulmfit | 93.8 |
| Bertje | 93.0 |
| ロブバートv2 | 95.1 |
「ダイ」または「DAT」を文に埋めるべきかどうかを予測することにより、モデルがどの程度うまくコアレファレンス解像度を行うことができるかを測定しました。このために、Europarlコーパスを使用しました。
| モデル | 正確さ [%] | F1 [%] |
|---|---|---|
| ベースライン(LSTM) | 75.03 | |
| Mbert | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| ロブバートv2 | 99.232 | 99.121 |
また、10kのトレーニングの例のみを使用してパフォーマンスを測定しました。この実験は、利用可能なデータがほとんどない場合、ロブバートが他のモデルよりも優れていることを明確に示しています。
| モデル | 正確さ [%] | F1 [%] |
|---|---|---|
| Mbert | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| ロブバートv2 | 97.816 | 97.514 |
Bertモデルはワードマスキングタスクを使用して事前に訓練されているため、これを使用して「Die」または「DAT」がより可能性が高いかどうかを予測できます。この実験は、ロブバートが他のモデルよりもオランダに関するより多くの情報を内面化したことを示しています。
| モデル | 正確さ [%] |
|---|---|
| ゼロ | 66.70 |
| Mbert | 90.21 |
| Bertje | 94.94 |
| ロブバートv2 | 98.75 |
Lassy UDデータセットを使用します。
| モデル | 正確さ [%] |
|---|---|
| 蛙 | 91.7 |
| Mbert | 96.5 |
| Bertje | 96.3 |
| ロブバートv2 | 96.4 |
興味深いことに、小さなデータセットを扱うとき、Robbert V2は他のモデルを大幅に上回ることがわかりました。
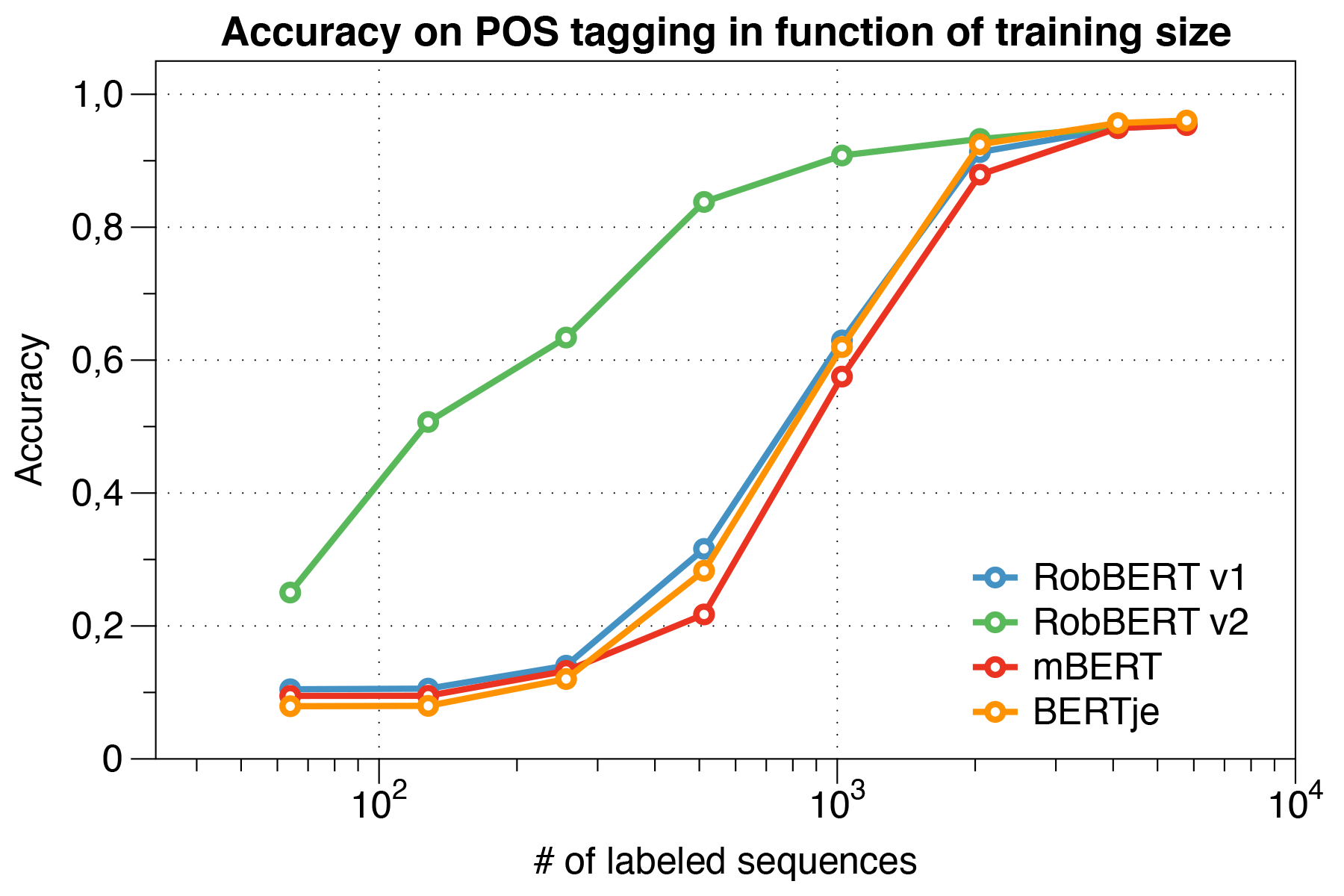
CONLL 2002評価スクリプトを使用します。
| モデル | 正確さ [%] |
|---|---|
| 蛙 | 57.31 |
| Mbert | 90.94 |
| bert-nl | 89.7 |
| Bertje | 88.3 |
| ロブバートv2 | 89.08 |
ロベルタトレーニング体制を使用して、ロバートを事前に訓練しました。オスカーコーパスのオランダ語セクションでモデルを事前に訓練しました。これは、一般的なクロールコーパスの言語分類によって得られた大きな多言語コーパスです。このオランダのコーパスは39GBの大きさで、66億語が1億2600万行に広がっており、各行は複数の文を含むことができるため、同時に開発されたオランダのバートモデルよりも多くのデータを使用できます。
ロバートは、そのアーキテクチャをロベルタの基本モデルと共有しています。ロベルタは、それ自体がバートよりも複製と改善です。バートと同様に、それはアーキテクチャは、117mのトレーニング可能なパラメーターを備えた12のヘッドを備えた12の自己関節層で構成されています。元のBertモデルとの違いの1つは、NSPタスクではなくMLMタスクのみを使用して、Robertaが指定した異なるトレーニング前タスクによるものです。したがって、トレーニング前に、与えられた文の特定の位置でどの単語がマスクされるかを予測するだけです。トレーニングプロセスでは、学習率L_R = 10^-6の多項式減衰と1000回の反復期のAdamオプティマイザーを使用し、ハイパーパラメーターBeta_1 = 0.9およびRobertaのデフォルトBeta_2 = 0.98を使用します。さらに、0.1の重量減衰と0.1の少量のドロップアウトは、モデルの過剰フィットを防ぐのに役立ちます。
ロバートは、ノードごとに4つのNVIDIA P100 GPUを備えたコンピューティングクラスターでトレーニングを受けました。この数ノードの数は、8192文の固定バッチサイズを保持しながら動的に調整されました。ほとんどのノードが使用され(すなわち80 GPU)、中央値は5つのノードでした。勾配蓄積を使用することにより、クラスターを最大限に活用するために、利用可能なGPUの数とは独立してバッチサイズを設定できます。 FairSeqライブラリを使用して、モデルは2つのエポックのために訓練されました。これは合計で16Kバッチを超えるバッチを超え、コンピューティングクラスターで約3日かかりました。コンピューティングクラスターでのトレーニングジョブの間に、2 Nvidia 1080 TiはRobbert V2のパラメーターの更新もカバーしました。
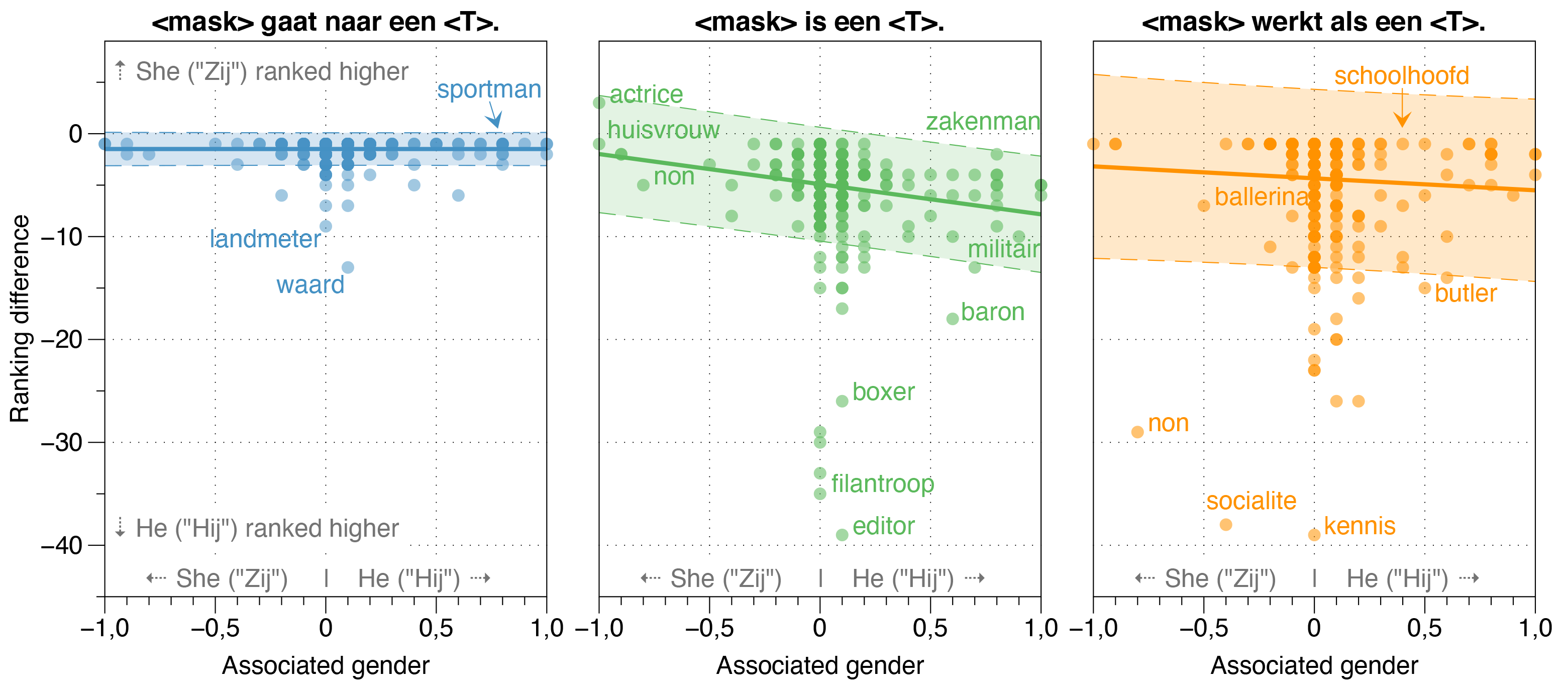
ロバートペーパーでは、ロバートの潜在的なバイアス源も調査しました。
Zeroshotモデルは、実際の実際の雇用性比率に関係なく、漂白されたテンプレート文のほとんどの職業について、 hij (HE)がZIJ (SH)よりも高いと推定することを発見しました。
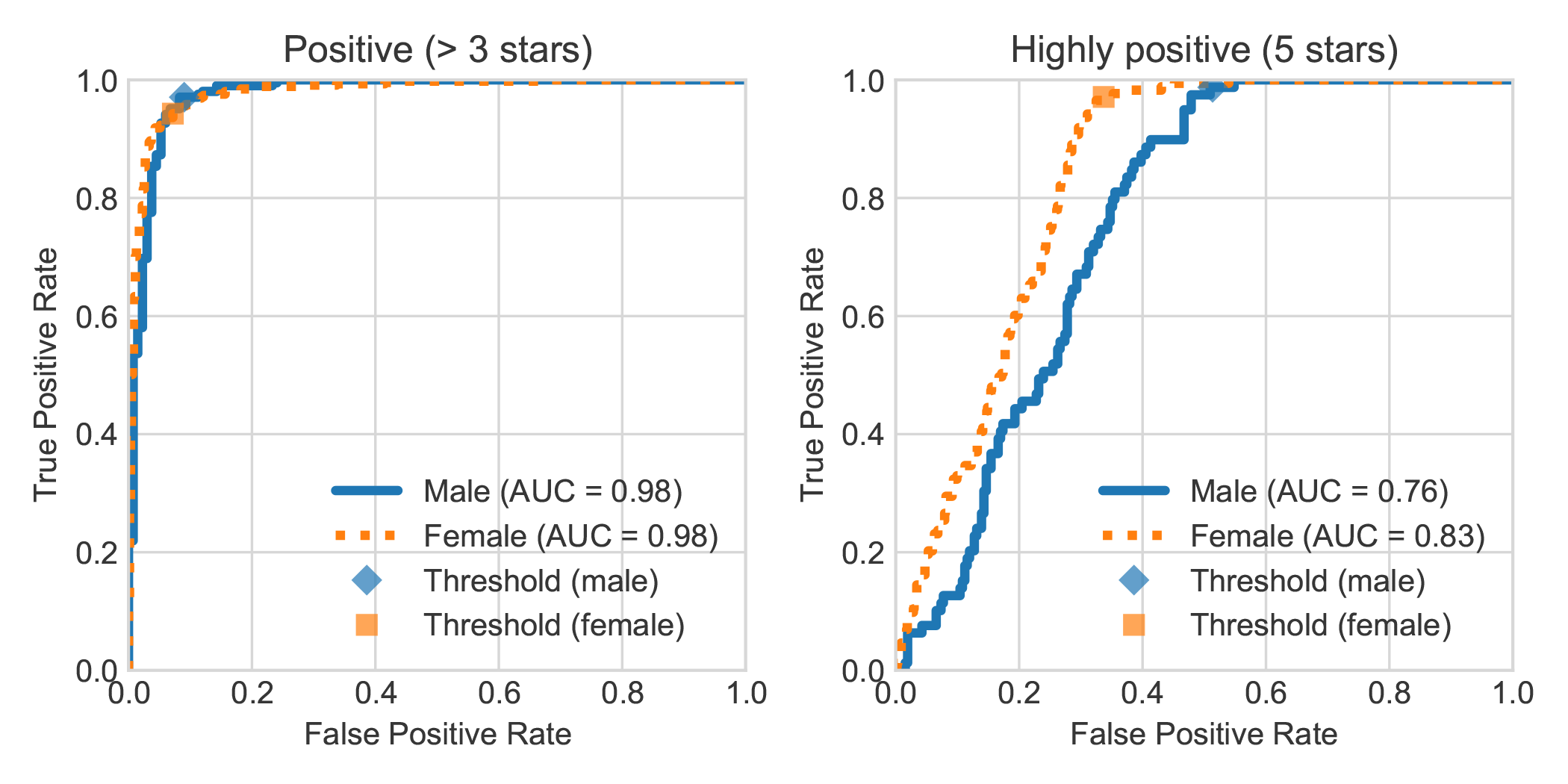
レビューの著者の述べられた性別とDBRBダッチブックセンチメント分析データセットを増強することにより、女性によって書かれた非常に肯定的なレビューは、ロブバートによって一般に男性によって書かれたものよりも肯定的であるとより正確に検出されたことがわかりました。
次の手順に従って、私たちの論文で行われた実験を再現できます。要件またはpipenvのいずれかの依存関係をインストールできます。
pip install -r requirements.txtpip install pipenv )を使用してpipenv install 。このセクションでは、モデルを微調整するために提供するスクリプトを使用する方法について説明します。これは、他の望ましいテキスト分類タスクを再利用するのに十分な一般的なものでなければなりません。
data/raw/DBRDに保存しますsrc/preprocess_dbrd.pyを実行して、データセットを準備します。src/split_dbrd_training.sh 。notebooks/finetune_dbrd.ipynbをフォローして、モデルをFintuneします。 モデルでモデルを微調整します。最初にダウンロードできます:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
正気のチェックとして、次のファイルをdata/raw/europarlフォルダーに入れる必要があります。
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
次に、次のスクリプトで前処理を実行できます。これにより、最初の処理をeuroparlコーパスに処理して、ダイやデータなしで文章を削除します。その後、代名詞をひっくり返し、 <sep>トークンと両方の文章を結合します。
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
注: watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentencesを使用して、最初の前処理ステップの進捗を監視できます。これにはしばらく時間がかかりますが、すべての入力を使用する必要はありません。これが、事前に訓練された言語モデルを使用したい理由です。 Pythonスクリプトをいつでも終了でき、2番目のステップはそれらのみを使用します。
ほとんどのBertのようなモデルには、 Bertという言葉がその名前にあります(例:Roberta、Albert、Camembertなど、他の多く)。そのため、マスクされた言語モデルを使用して新たに訓練されたモデルを照会し、あらゆる種類のプロンプトを使用して<マスク> bertを名前を付けました。ロブバートは非常にオランダ語の名前であり(したがって明らかにオランダ語モデル) 、さらにそのルートアーキテクチャ、つまりロベルタと高い類似点を持っていることを考えると、本当にふさわしいと思いました。
「ロブ」はシールを示すオランダ語であるため、ロバートストリートのバートのようにシールを描き、ドレスアップすることにしました。
このプロジェクトは、Pieter Delobelle、Thomas Winters、Bettina Berendtによって作成されます。
Liesbeth Alleinは、Die-Datの乱用、トランスパッケージのHuggingface、FacebookのFairSeqパッケージ、および私たちが使用できる他のすべての人々に感謝しています。
MITの下でモデルとこのコードをリリースします。
私たちの論文またはモデルを引用したい場合は、次のBibtexコードを使用できます。
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


