RobBERT
v2.0

Robbert ist das hochmoderne niederländische Bert-Modell. Es handelt sich um ein großes, vorgebildetes allgemeines niederländisches Sprachmodell, das in einem bestimmten Datensatz fein abgestimmt werden kann, um eine Textklassifizierung, Regression oder Token-Tagging-Aufgabe auszuführen. Daher wurde es von vielen Forschern und Praktikern erfolgreich verwendet, um eine modernste Leistung für eine breite Palette von Aufgaben der niederländischen Sprachverarbeitung zu erzielen, darunter:
und erzielte auch herausragende Ergebnisse für die Nah-Sota für:
* Beachten Sie, dass mehrere Bewertungen Robbert-V1 verwenden und dass das zweite und verbesserte Robbert-V2 dieses erste Modell zu allem übertrifft, was wir getestet haben
(Beachten Sie auch, dass diese Liste nicht erschöpfend ist. Wenn Sie Robbert für Ihre Bewerbung verwendet haben, wissen wir, dass wir uns darüber informieren! Senden Sie uns eine E -Mail oder fügen Sie sie selbst zu dieser Liste hinzu, indem Sie eine Pull -Anfrage mit der Bearbeitung senden!)
Verwenden Sie die Verwendung des Robbert-Modells mit Huggingface-Transformatoren den Namen pdelobelle/robbert-v2-dutch-base .
In unserem Blog-Beitrag und in unserem Artikel finden Sie ein ausführlichere Informationen über Robbert.
Robbert verwendet die Roberta-Architektur und die Vorausbildung, jedoch mit einem niederländischen Tokenizer und Schulungsdaten. Roberta ist das robust optimierte englische Bert -Modell und macht es noch leistungsfähiger als das ursprüngliche Bert -Modell. Angesichts derselben Architektur kann Robbert mit Code für Finetune -Roberta -Modelle und den meisten Code, das für Bert -Modelle verwendet wird, leicht abgeleitet werden, z.
Robbert kann leicht auf zwei verschiedene Arten verwendet werden, nämlich entweder mit Fairseq Roberta Code oder mit Huggingface -Transformatoren
Standardmäßig hat Robbert den maskierten Sprachmodellkopf im Training verwendet. Dies kann als null-shot-Weg verwendet werden, um Masken in Sätzen zu füllen. Es kann kostenlos auf Robberts gehostete Meterce -API von Huggingface getestet werden. Sie können auch einen neuen Vorhersage-Kopf für Ihre eigene Aufgabe erstellen, indem Sie die Roberta-Runner von Huggingface verwenden, ihre Feinabstimmungsbücher, indem Sie den Modellnamen in pdelobelle/robbert-v2-dutch-base ändern oder die ursprünglichen Fairseq Roberta-Trainingsregime verwenden.
Sie können Robbert V2 problemlos verwenden? Transformatoren. Verwenden Sie den folgenden Code, um das Basismodell herunterzuladen und es selbst zu beenden, oder verwenden Sie eines unserer feinen Modelle (dokumentiert auf unserer Projektseite).
from transformers import RobertaTokenizer , RobertaForSequenceClassification
tokenizer = RobertaTokenizer . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" )
model = RobertaForSequenceClassification . from_pretrained ( "pdelobelle/robbert-v2-dutch-base" ) Beginnend mit transformers v2.4.0 (oder Installation von Quelle) können Sie Autotokenizer und Automodel verwenden. Sie können dann die meisten Bert-basierten Notebooks von Huggingface für den Finetuning Robbert auf Ihrem niederländischen Sprachdatensatz verwenden.
Alternativ können Sie Robbert auch mit dem Roberta Architecture Code verwenden. Sie können das Fairseq-Modell von Robbert V2 hier herunterladen: (Robbert-Base, 1,5 GB). Mit dieser Methode von Robberts model.pt können Sie alle anderen Funktionen von Roberta verwenden.
Alle Experimente werden in unserem Artikel ausführlicher beschrieben, mit dem Code in unserem Github -Repository.
Vorhersage, ob eine Bewertung mit dem niederländischen Buchbesprechungsdatensatz positiv oder negativ ist.
| Modell | Genauigkeit [%] |
|---|---|
| Ulmfit | 93.8 |
| Bertje | 93.0 |
| Robbert V2 | 95.1 |
Wir haben gemessen, wie gut die Modelle in der Lage sind, eine Coreference -Auflösung durchzuführen, indem sie vorhersagen, ob "sterben" oder "dat" in einen Satz ausgefüllt werden soll. Dafür haben wir den Europarl Corpus verwendet.
| Modell | Genauigkeit [%] | F1 [%] |
|---|---|---|
| Grundlinie (LSTM) | 75.03 | |
| Mbert | 98.285 | 98.033 |
| Bertje | 98.268 | 98.014 |
| Robbert V2 | 99.232 | 99.121 |
Wir haben auch die Leistung anhand nur 10K -Trainingsbeispiele gemessen. Dieses Experiment zeigt deutlich, dass Robbert andere Modelle übertrifft, wenn nur wenige Daten verfügbar sind.
| Modell | Genauigkeit [%] | F1 [%] |
|---|---|---|
| Mbert | 92.157 | 90.898 |
| Bertje | 93.096 | 91.279 |
| Robbert V2 | 97.816 | 97.514 |
Da Bert-Modelle mit der Wortmaskierungsaufgabe vorgebrannt werden, können wir dies verwenden, um vorherzusagen, ob "sterben" oder "dat" wahrscheinlicher ist. Dieses Experiment zeigt, dass Robbert mehr Informationen über Niederländisch als andere Modelle verinnerlicht hat.
| Modell | Genauigkeit [%] |
|---|---|
| Zeror | 66.70 |
| Mbert | 90.21 |
| Bertje | 94.94 |
| Robbert V2 | 98.75 |
Verwenden des lassigen UD -Datensatzes.
| Modell | Genauigkeit [%] |
|---|---|
| Frosch | 91.7 |
| Mbert | 96,5 |
| Bertje | 96,3 |
| Robbert V2 | 96,4 |
Interessanterweise stellten wir fest, dass Robbert V2 beim Umgang mit kleinen Datensätzen andere Modelle erheblich übertrifft .
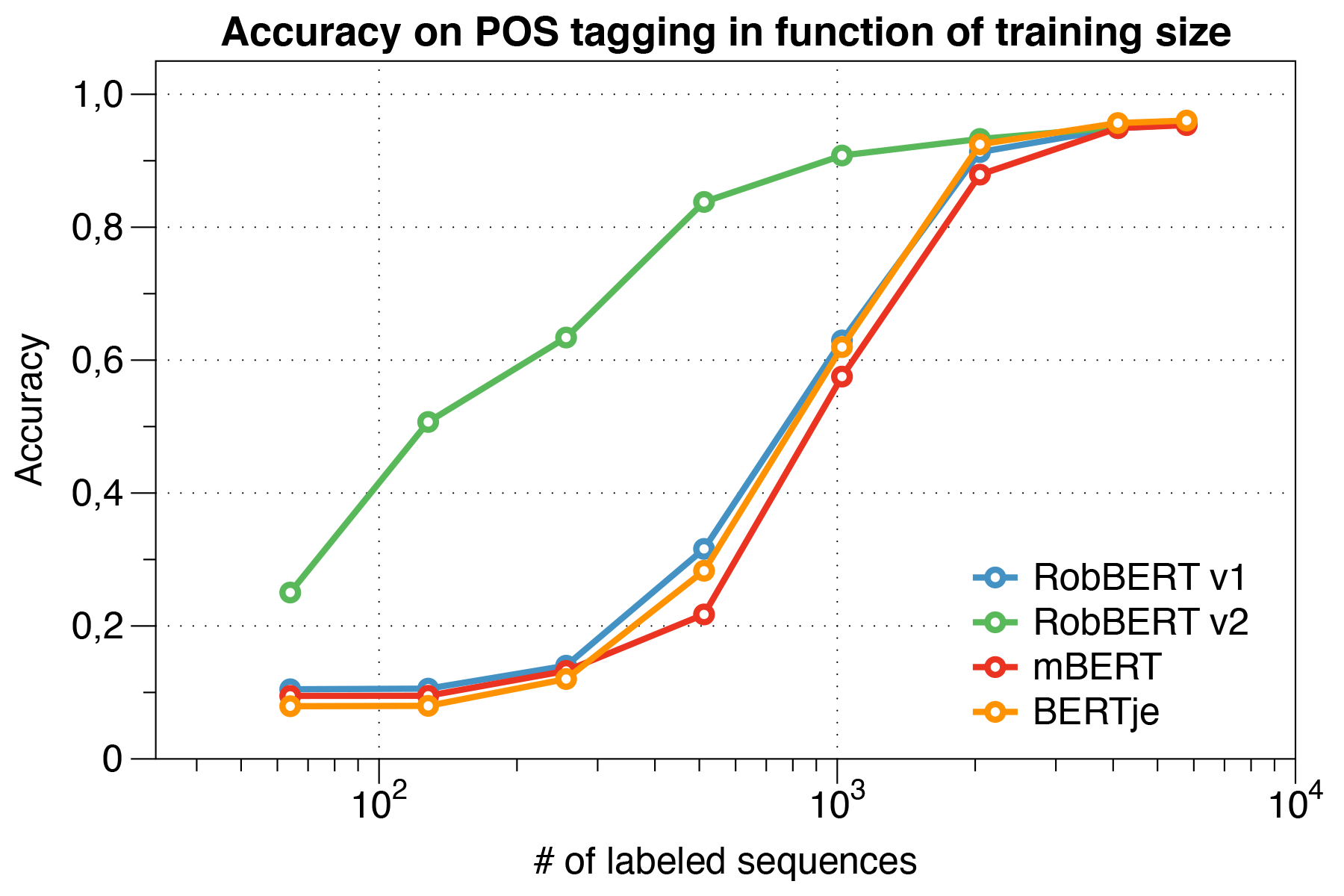
Verwenden des CONLL 2002 Evaluierungsskripts.
| Modell | Genauigkeit [%] |
|---|---|
| Frosch | 57.31 |
| Mbert | 90,94 |
| Bert-nl | 89.7 |
| Bertje | 88.3 |
| Robbert V2 | 89.08 |
Wir haben Robbert mit dem Roberta-Trainingsregime ausgebildet. Wir haben unser Modell auf dem niederländischen Abschnitt des Oscar Corpus vorgebracht, einem großen mehrsprachigen Korpus, der durch Sprachklassifizierung im gemeinsamen Crawl-Korpus erhalten wurde. Dieser niederländische Korpus ist 39 GB groß, mit 6,6 Milliarden Wörtern, die über 126 Millionen Textlinien verteilt sind, wobei jede Zeile mehrere Sätze enthalten kann, wodurch mehr Daten als gleichzeitig entwickelte niederländische Bert -Modelle verwendet werden.
Robbert teilt seine Architektur mit Robertas Basismodell, das selbst eine Replikation und Verbesserung gegenüber Bert ist. Wie Bert besteht die Architektur aus 12 Selbstbekämpfungsschichten mit 12 Köpfen mit 117 m trainierbaren Parametern. Ein Unterschied zum ursprünglichen Bert-Modell ist auf die von Roberta festgelegte Vor-Training-Aufgabe zurückzuführen, wobei nur die MLM-Aufgabe und nicht die NSP-Aufgabe verwendet werden. Während der Vorausbildung prognostiziert es nur, welche Wörter in bestimmten Positionen gegebener Sätze maskiert werden. Der Schulungsprozess verwendet den Adam-Optimierer mit Polynomabfall der Lernrate L_R = 10^-6 und einer Aufstiegszeit von 1000 Iterationen, wobei Hyperparameter Beta_1 = 0,9 und Robertas Standard-Beta_2 = 0,98. Darüber hinaus hilft ein Gewichtsverfall von 0,1 und ein kleiner Ausfall von 0,1 zu verhindern, dass das Modell übereinstimmt.
Robbert wurde auf einem Computing -Cluster mit 4 NVIDIA P100 GPUS pro Knoten trainiert, wobei die Anzahl der Knoten dynamisch eingestellt wurde, während eine feste Stapelgröße von 8192 Sätzen beibehalten wurde. In den meisten 20 Knoten wurden (dh 80 GPUs) verwendet, und der Median war 5 Knoten. Durch die Verwendung der Gradientenakkumulation könnte die Chargengröße unabhängig von der Anzahl der verfügbaren GPUs festgelegt werden, um den Cluster maximal zu verwenden. Unter Verwendung der Fairseq -Bibliothek trainierte das Modell für zwei Epochen, die insgesamt über 16.000 Chargen entsprechen und auf dem Computercluster etwa drei Tage dauerte. Zwischen den Trainingsjobs im Computercluster deckt 2 NVIDIA 1080 TI auch einige Parameter -Updates für Robbert V2 ab.
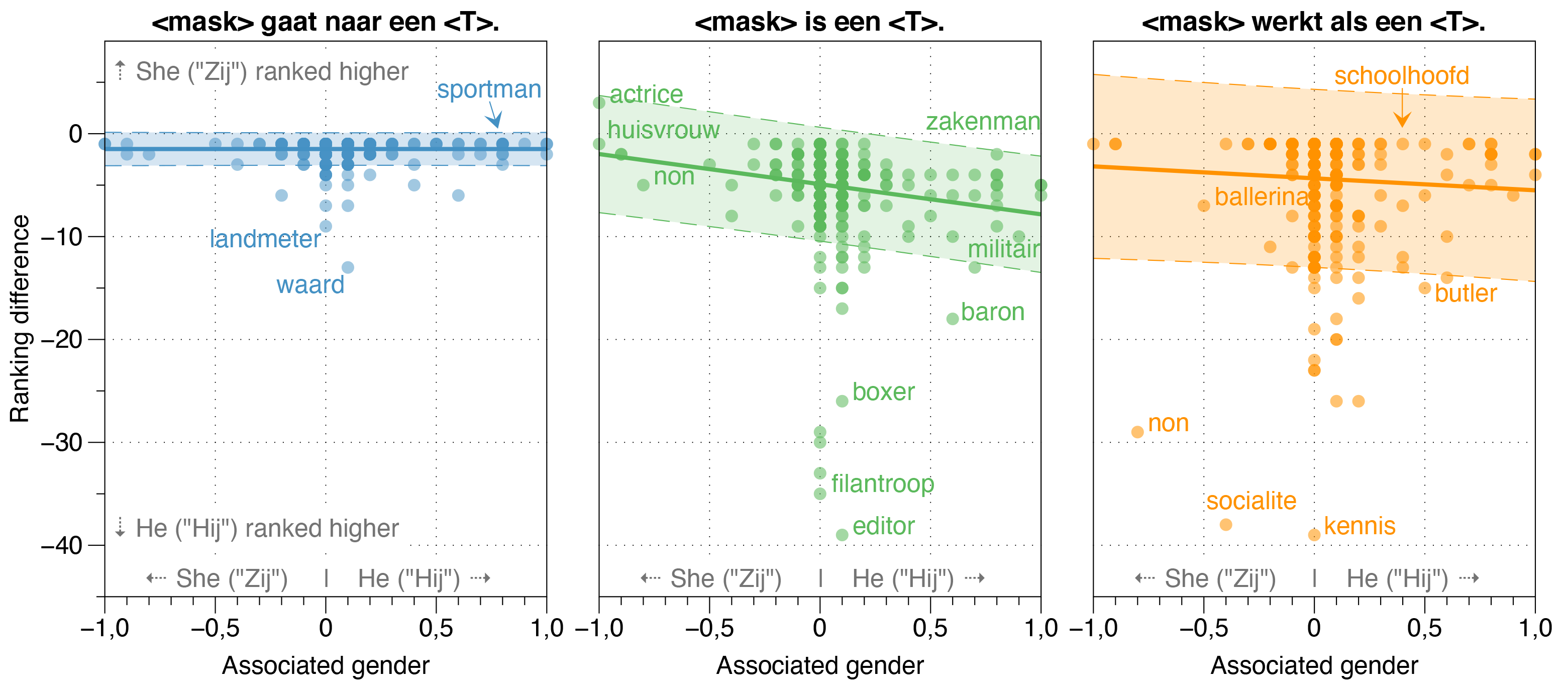
In der Robbert -Arbeit untersuchten wir auch potenzielle Verzerrungsquellen in Robbert.
Wir fanden heraus, dass das Zeroshot -Modell die Wahrscheinlichkeit von HIJ (er) schätzt, dass sie für die meisten Berufe in gebleichten Vorlagensätzen höher sind als Zij (She), unabhängig von ihrem tatsächlichen Geschlechtsverhältnis in der Realität.
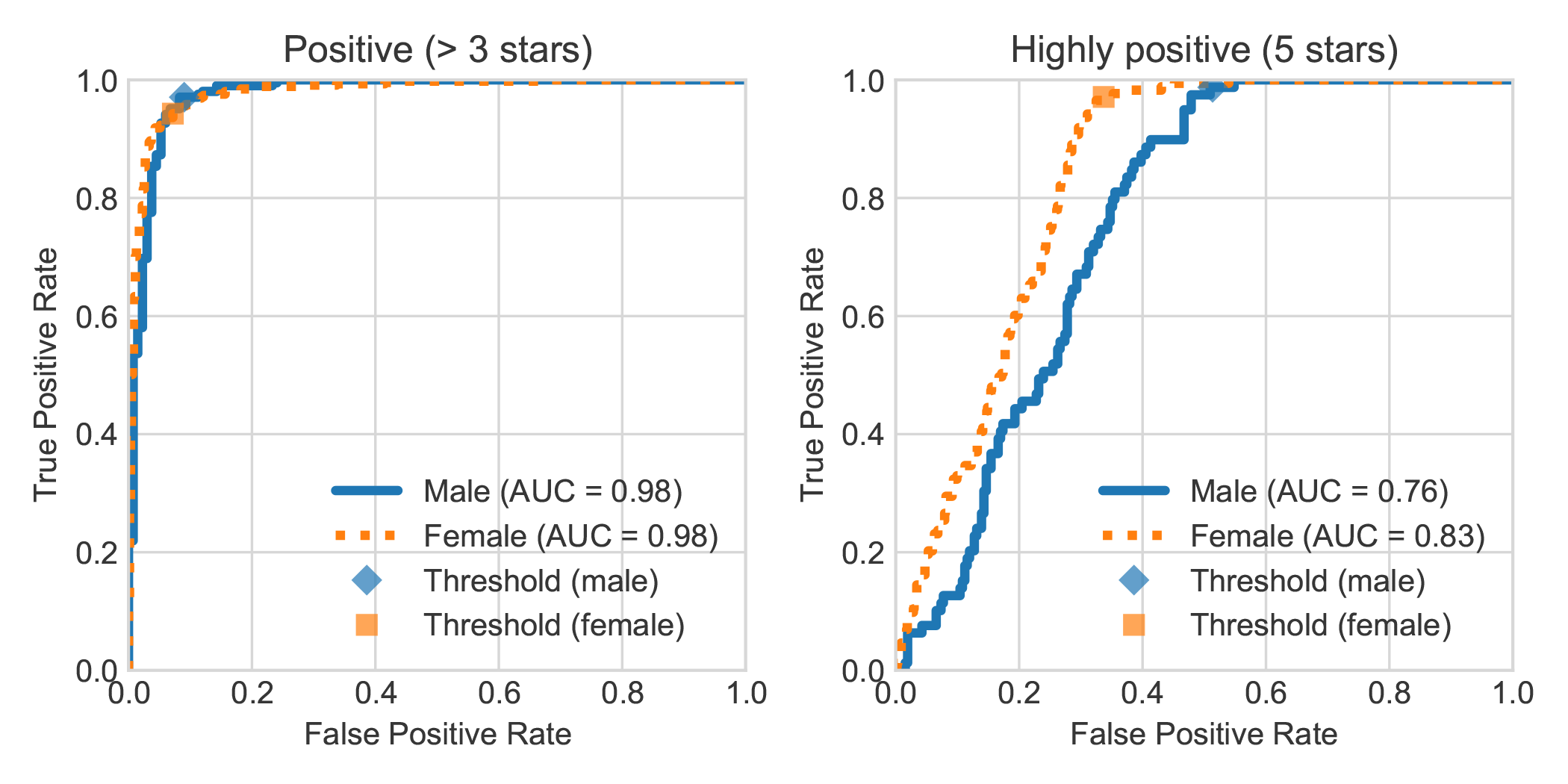
Durch die Erweiterung des Datasets DBRB Dutch Book Sentiment Analysis mit dem angegebenen Geschlecht des Autors der Überprüfung stellten wir fest, dass sehr positive Bewertungen von Frauen von Robbert im Allgemeinen genauer als positiv als die von Männern verfassten wurden.
Sie können die in unserem Papier durchgeführten Experimente replizieren, indem Sie den folgenden Schritten befolgen. Sie können die erforderlichen Abhängigkeiten entweder die Anforderungen installieren.
pip install -r requirements.txtpip install pipenv in Ihrem Terminal) , indem Sie pipenv install ausführen.In diesem Abschnitt beschreiben wir, wie wir die Skripte verwenden, die wir für Feinabstiegsmodelle anbieten, die allgemein genug sein sollten, um für andere gewünschte Textklassifizierungsaufgaben wiederzuverwenden.
data/raw/DBRDsrc/preprocess_dbrd.py aus, um den Datensatz vorzubereiten.src/split_dbrd_training.sh .notebooks/finetune_dbrd.ipynb um das Modell zu finanzieren. Wir stimmen unser Modell auf dem niederländischen Europarl Corpus gut ab. Sie können es zuerst herunterladen mit:
cd dataraweuroparl
wget -N 'http://www.statmt.org/europarl/v7/nl-en.tgz'
tar zxvf nl-en.tgz
Als Überprüfung der Vernunft sollten Sie jetzt die folgenden Dateien in Ihrem Ordner data/raw/europarl haben:
europarl-v7.nl-en.en
europarl-v7.nl-en.nl
nl-en.tgz
Anschließend können Sie die Vorverarbeitung mit dem folgenden Skript ausführen, mit dem der Europarl Corpus zuerst verarbeitet wird, um Sätze ohne Würfel oder DAT zu entfernen. Danach wird es das Pronomen umdrehen und beide Sätze mit einem <sep> -Token verbinden.
python src/preprocess_diedat.py
. src/preprocess_diedat.sh
Hinweis: Sie können den Fortschritt des ersten Vorverarbeitungsschritts mit watch -n 2 wc -l data/europarl-v7.nl-en.nl.sentences überwachen. Dies wird eine Weile dauern, aber es ist sicherlich nicht erforderlich, alle Eingaben zu verwenden. Dies ist schließlich der Grund, warum Sie ein vorgebildetes Sprachmodell verwenden möchten. Sie können das Python -Skript jederzeit beenden, und der zweite Schritt wird nur diese verwendet.
Die meisten Bert-ähnlichen Modelle haben das Wort Bert in ihrem Namen (z. B. Roberta, Albert, Camembert und viele, viele andere). Als solches haben wir unser neu trainiertes Modell mit seinem maskierten Sprachmodell befragt, um sich selbst <Mask> Bert mit allen Arten von Eingabeaufforderungen zu benennen, und es hat sich konsequent Robbert bezeichnet. Wir fanden es wirklich sehr passend, da Robbert ein sehr niederländischer Name ist (und damit eindeutig ein niederländisches Sprachmodell) , und zusätzlich eine hohe Ähnlichkeit mit seiner Wurzelarchitektur, nämlich Roberta, hat.
Da "Rob" ein niederländischer Worte ist, um ein Siegel zu bezeichnen, haben wir beschlossen, ein Siegel zu zeichnen und es wie Bert aus der Sesamstraße für das Robbert -Logo zu kleiden.
Dieses Projekt wird von Pieter Delobelle, Thomas Winters und Bettina Berendt erstellt.
Wir danken Liesbeth Allein für ihre Arbeit an der Disambiguation, Huggingface für ihr Transformer-Paket, Facebook für ihr Fairseq-Paket und alle anderen Personen, deren Arbeit wir verwenden konnten.
Wir veröffentlichen unsere Modelle und diesen Code unter MIT.
Wenn Sie unser Papier oder Modell zitieren möchten, können Sie den folgenden Bibtex -Code verwenden:
@inproceedings{delobelle2020robbert,
title = "{R}ob{BERT}: a {D}utch {R}o{BERT}a-based {L}anguage {M}odel",
author = "Delobelle, Pieter and
Winters, Thomas and
Berendt, Bettina",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.292",
doi = "10.18653/v1/2020.findings-emnlp.292",
pages = "3255--3265"
}


