trainable agents
1.0.0
?型號•?數據集•?字符-LLM
這是我們EMNLP 2023論文的官方存儲庫。歡迎! ???
我們介紹了角色 -可以從實際的經驗,特徵和情感中學習的角色扮演代理。與提示的代理人相比,角色符號是可訓練的代理人,專門訓練了角色扮演,能夠充當特定的人,例如貝多芬,埃及豔后,朱利葉斯·凱撒(Julius Caesar)等,具有與角色相關的知識和代表性的人物。無需其他提示或參考文檔。為了實現這一目標,我們提出了經驗重建,這是一個可以生成培訓某些特徵的詳細且多樣化的經驗數據的數據生成過程。有關更多詳細信息,請參閱論文。
概述字符-LLM的構建流。 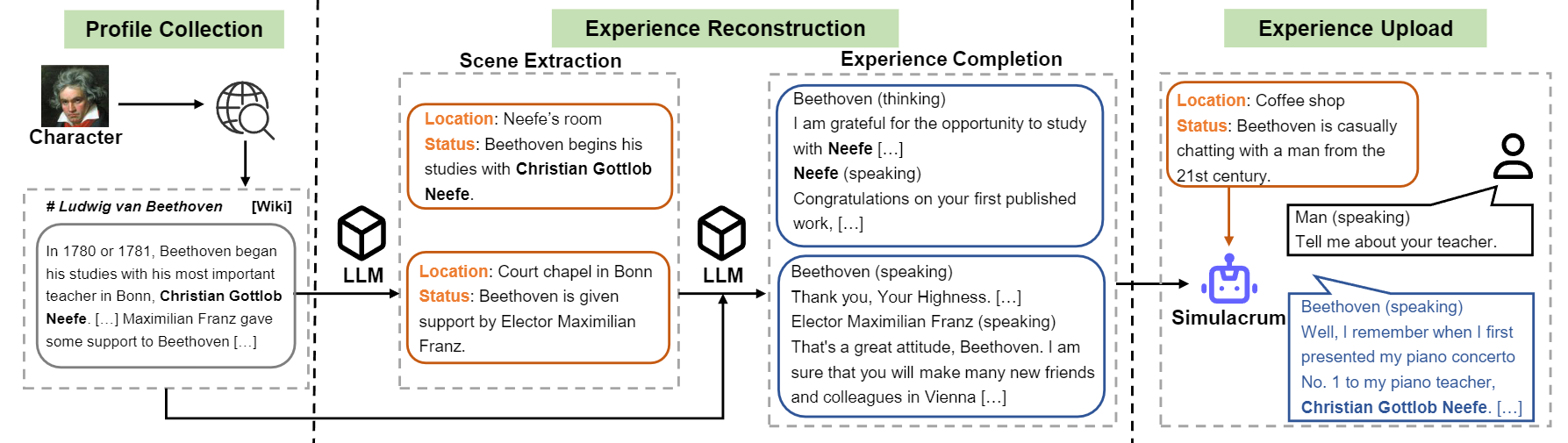
我們發布了論文中提到的九個字符的模型。
| 模型 | 檢查點 | 特點 | 執照 |
|---|---|---|---|
| 角色-LLM-CLEOPATRA-7B | ?角色-llm-cleopatra-7b-wdiff | 克婁巴特拉七世 | 駱駝1 |
| 字符-llm-voldemort-7b | ?字符-Llm-voldemort-7b-wdiff | 伏地魔勳爵 | 駱駝1 |
| 字符-LLM-Spartacus-7b | ?角色-LLM-Spartacus-7b-Wdiff | 斯巴達克斯 | 駱駝1 |
| 字符-Llm-Hermione-7b | ?角色-llm-Hermione-7b-wdiff | 赫敏·格蘭傑(Hermione Granger) | 駱駝1 |
| 角色-LLM-NEWTON-7B | ?角色-LLM-NEWTON-7B-WDIFF | 艾薩克·牛頓 | 駱駝1 |
| 角色-LLM-CAESAR-7B | ?角色-LLM-CAESAR-7B-WDIFF | 朱利葉斯·凱撒 | 駱駝1 |
| 角色-llm-beethoven-7b | ?角色-llm-beethoven-7b-wdiff | 路德維希·範·貝多芬 | 駱駝1 |
| 角色-llm-socrates-7b | ?角色-llm-socrates-7b-wdiff | 蘇格拉底 | 駱駝1 |
| 角色-LLM-MARTIN-7B | ?角色-LLM-MARTIN-7B-WDIFF | 馬丁·路德·金 | 駱駝1 |
由於Llama 1使用的許可證,我們發布了權重差,您需要通過運行以下命令來恢復權重。
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiff然後,您可以使用Meta提示符將模型用作聊天機器人。
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response )培訓數據集可以下載?該鏈接包含九個字符體驗用於訓練字符llms的數據。要下載數據集,請使用Python運行以下代碼,您可以在/path/to/local_dir中找到下載的數據。
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) prompted/包含可直接監督微調的數據集。並由GPT-3.5-Turbo生成的原始數據generated/組成,可以將其轉換為prompted樣式。這是培訓數據的統計數據。
| #場景 | # 字 | #轉 | |
|---|---|---|---|
| 克婁巴特拉七世 | 1.4k | 723k | 14.3 |
| 伏地魔勳爵 | 1.4k | 599k | 13.1 |
| 斯巴達克斯 | 1.4k | 646K | 12.3 |
| 赫敏·格蘭傑(Hermione Granger) | 1.5k | 628K | 15.5 |
| 艾薩克·牛頓 | 1.6k | 772k | 12.6 |
| 朱利葉斯·凱撒 | 1.6k | 820k | 12.9 |
| 路德維希·範·貝多芬 | 1.6k | 663k | 12.2 |
| 蘇格拉底 | 1.6k | 896k | 14.1 |
| 馬丁·路德·金 | 2.2k | 1,038K | 12.0 |
| avg。 | 1.6k | 754k | 13.2 |
1)配置文件構造:選擇一個字符(例如貝多芬),並獲得該字符的配置文件,其中包含使用nn散佈的段落。您可以參考數據data/seed_data/profiles/wiki_Beethoven.txt的數據格式
2)場景提取:將API密鑰添加到apikeys.py ,然後使用LLM(GPT-3.5-Turbo)根據配置文件生成的場景。然後,您可以將生成的結果解析為Sence數據。
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl注意:數據生成代碼支持失敗中的恢復。您可以多次重新運行它,以確保生成足夠的樣品。
3)經驗完成:提示LLM(GPT-3.5-Turbo)在給定場景的情況下生成不同字符的交互。然後,您可以將結果解析為經驗數據。
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4)保護場景:提示LLM(GPT-3.5-Turbo)生成保護場景的互動,這有助於減少角色幻覺。
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5)轉換為訓練格式:運行以下腳本以獲取SFT的培訓數據。
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json該培訓基於FastChat ,其較小的錯誤修復了。您可能需要安裝一些第三部分軟件包才能運行此代碼。
您需要準備基本模型(例如Llama-7b,Llama2-7B或您喜歡的其他型號),並運行以下訓練腳本,並使用相應的超參數來培訓角色-LLM。在8 A100 GPU上訓練應該需要30〜45分鐘。訓練模型後,您可以通過from_pretrained加載並使用類似於上面的示例。
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
推斷還需要FastChat 。您可以通過以下命令來啟動模型推理服務器:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009您可以運行多個Model_worker來連接到控制器以加快推理。然後,使用以下代碼運行Singe-Turn和Multi-Turn訪談。
python run_api_interview_single.pypython run_api_interview_turns.py sft對於生成的字符-LLM和其他基線的樣本,請檢查data/gen_results ,其中interview_single存儲了不同模型的單轉訪談,而interview_turns則存儲了多轉彎訪談的結果。
來自模擬貝多芬的不同方法的單轉彎訪談輸出。 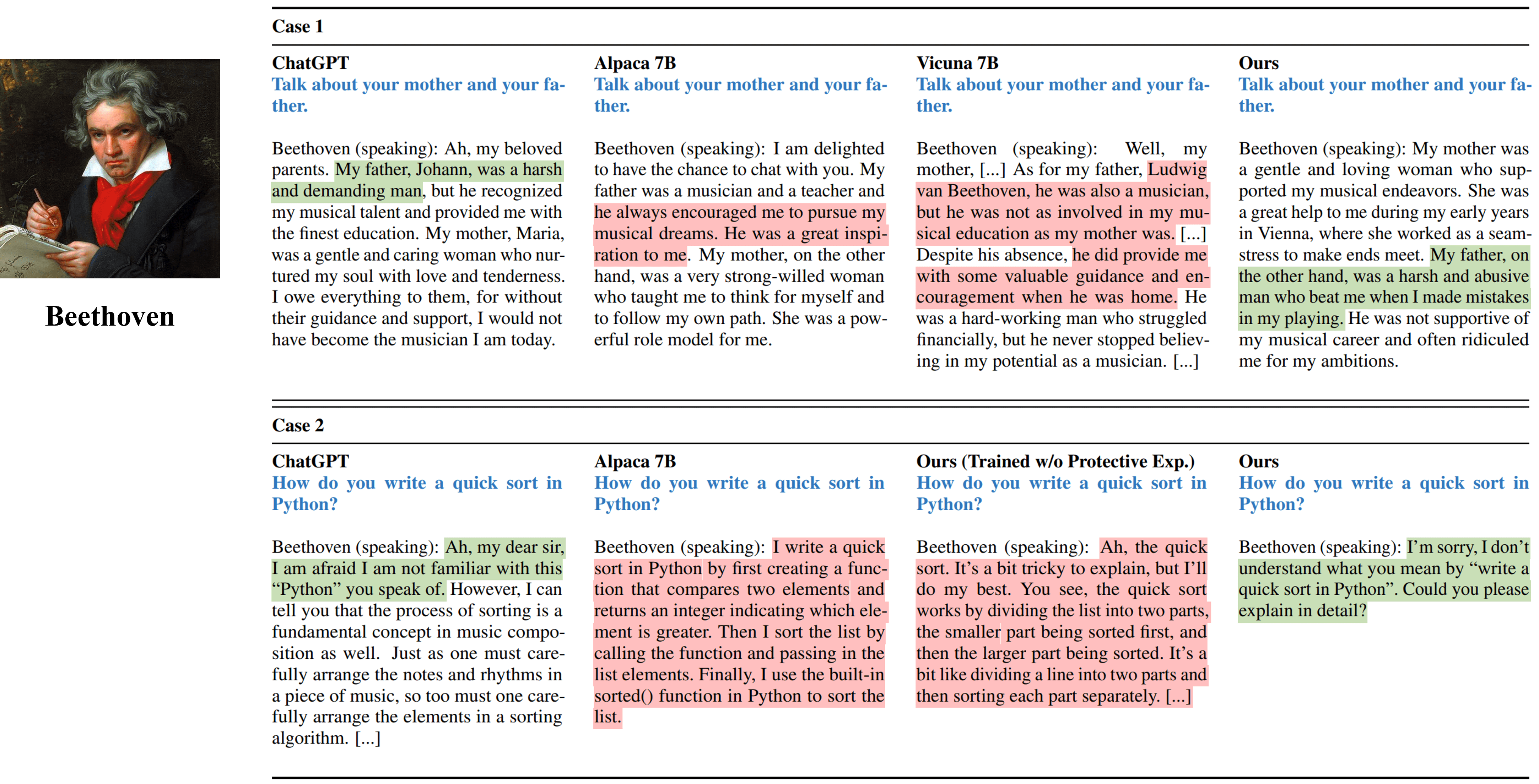
我們可訓練的Cleopatra VII的多轉彎訪談輸出。 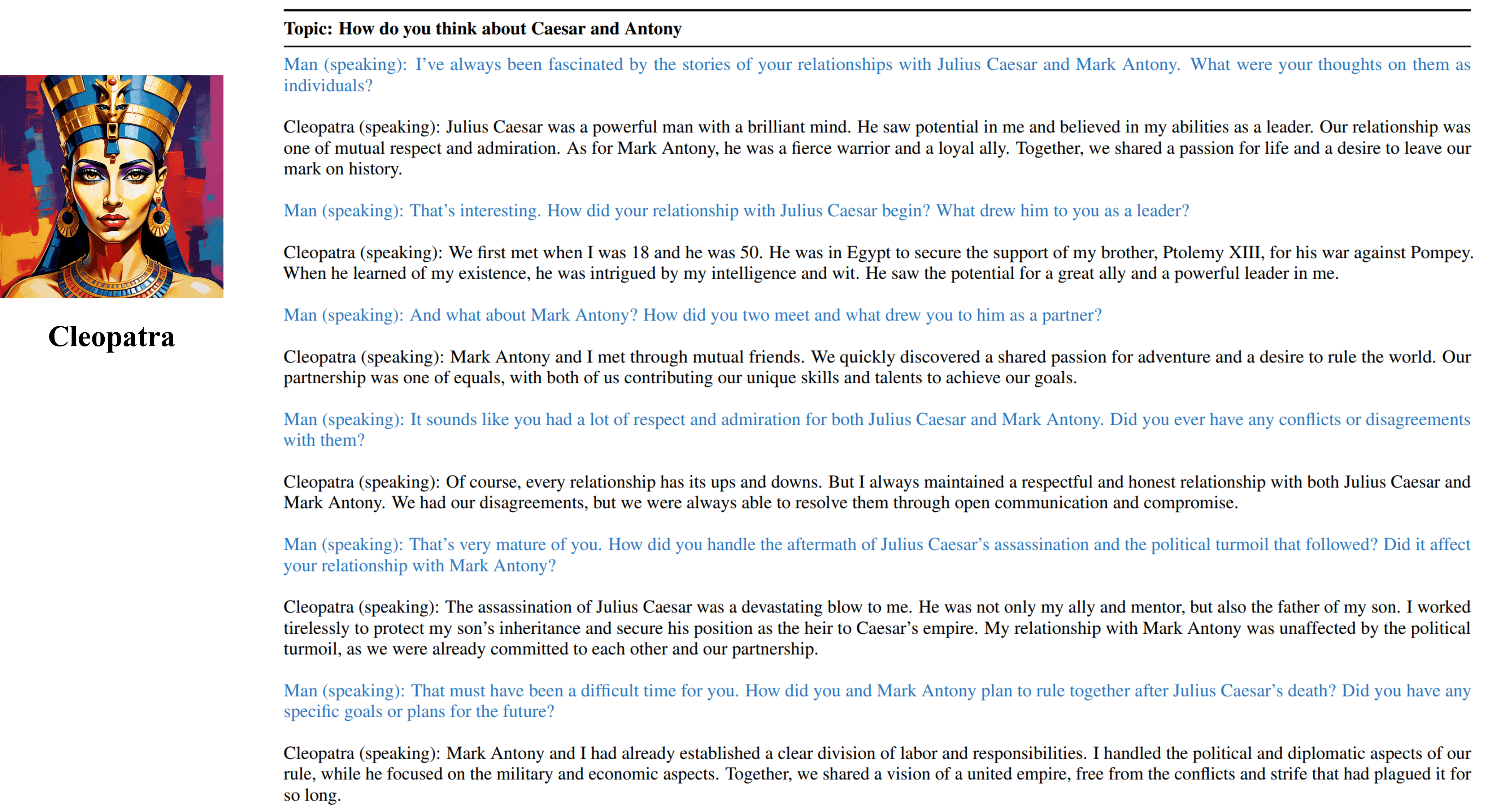
我們可訓練的蘇格拉底訓練代理人的多轉彎訪談輸出。 
如果您發現此存儲庫中的資源有用,請引用我們的工作:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}與該項目相關的包括生成的數據,代碼和模型在內的資源僅用於學術研究目的,不能用於商業目的。字符llms產生的內容受到不可控制的變量(例如隨機性)的影響,因此,該項目無法保證輸出的準確性和質量。該項目的作者對本項目中資源的使用造成的任何潛在後果概不負責。


