trainable agents
1.0.0
?モデル•?データセット•?文字llm
これは、EMNLP 2023ペーパーの公式リポジトリです。いらっしゃいませ! ???
実際の経験、特性、感情から学習するロールプレイングのための訓練可能なエージェントをキャラクターllmsに紹介します。プロンプトを受けたエージェントと比較して、Character-LLMはロールプレイングのために具体的に訓練された訓練可能なエージェントであり、ベートーヴェン、クイーンクレオパトラ、ジュリアスシーザーなどの特定の人々として行動することができ、キャラクター関連の知識と代表的なキャラクターの個性を備えています。追加のプロンプトまたは参照ドキュメントは必要ありません。これを達成するために、トレーニング用の特定のキャラクターの詳細で多様な経験データを生成できるデータ生成プロセスである経験再構成を提案します。詳細については、論文を参照してください。
文字llmの構造流の概要。 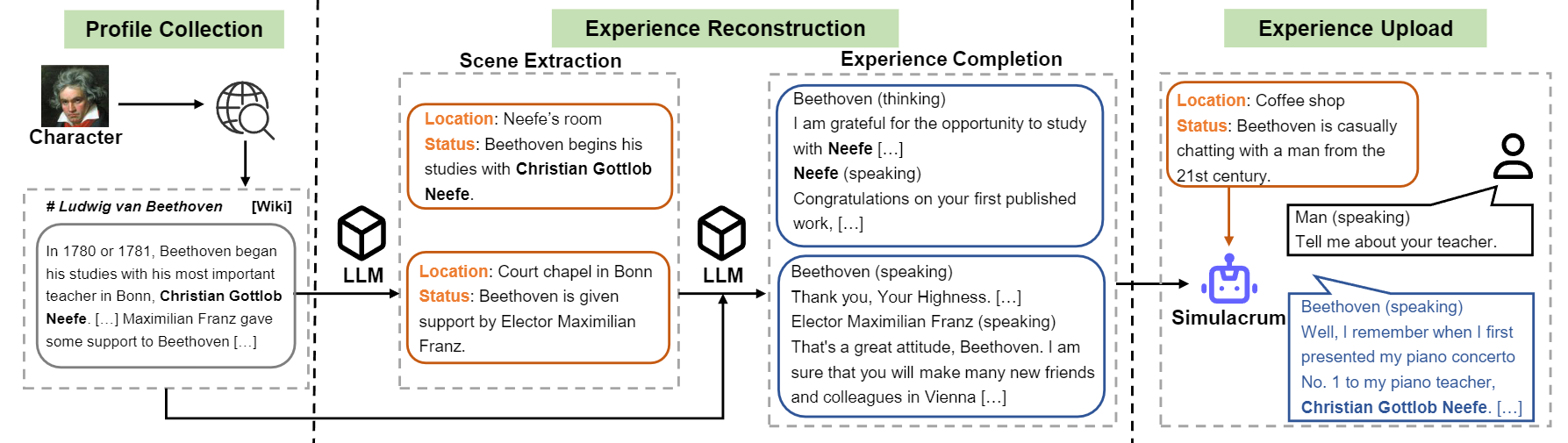
論文で言及されている9文字のモデルをリリースします。
| モデル | チェックポイント | キャラクター | ライセンス |
|---|---|---|---|
| 文字llm-クレオパトラ-7b | ? Character-llm-Cleopatra-7b-wdiff | クレオパトラVII | ラマ1 |
| 文字llm-voldemort-7b | ? Character-llm-voldemort-7b-wdiff | ヴォルデモートLord | ラマ1 |
| Character-llm-Spartacus-7B | ? Character-llm-Spartacus-7b-wdiff | スパルタカス | ラマ1 |
| Character-llm-Hermione-7B | ? Character-llm-Hermione-7b-wdiff | ハーマイオニー・グレンジャー | ラマ1 |
| キャラクターllm-newton-7b | ? Character-llm-newton-7b-wdiff | アイザック・ニュートン | ラマ1 |
| キャラクターllm-caesar-7b | ? Character-llm-caesar-7b-wdiff | ジュリアス・シーザー | ラマ1 |
| キャラクターllm-beethoven-7b | ?キャラクターllm-beethoven-7b-wdiff | Ludwig Van Beethoven | ラマ1 |
| キャラクターllm-socrates-7b | ?キャラクターllm-socrates-7b-wdiff | ソクラテス | ラマ1 |
| キャラクターllm-martin-7b | ?キャラクターllm-martin-7b-wdiff | マーティン・ルーサー・キング | ラマ1 |
Llama 1が使用したライセンスにより、重量の違いをリリースし、次のコマンドを実行して重量を回収する必要があります。
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffそして、モデルをメタプロンプトのチャットボットとして使用できます。
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response )トレーニングデータセットはでダウンロードできますか?このリンクには、キャラクターllmsのトレーニングに使用される9文字のエクスペリエンスデータが含まれています。データセット/path/to/local_dirダウンロードするには、Pythonで次のコードを実行してください。/path/to/local_dirでダウンロードされたデータを見つけることができます。
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) prompted/コンテンツは、監視された微調整に直接使用できるデータセットを含みます。 generated/ GPT-3.5-ターボによって生成された生データで構成され、 promptedスタイルに変換できます。これがトレーニングデータの統計です。
| #シーン | #単語 | #ターン | |
|---|---|---|---|
| クレオパトラVII | 1.4k | 723K | 14.3 |
| ヴォルデモートLord | 1.4k | 599k | 13.1 |
| スパルタカス | 1.4k | 646K | 12.3 |
| ハーマイオニー・グレンジャー | 1.5k | 628K | 15.5 |
| アイザック・ニュートン | 1.6k | 772K | 12.6 |
| ジュリアス・シーザー | 1.6k | 820K | 12.9 |
| Ludwig Van Beethoven | 1.6k | 663K | 12.2 |
| ソクラテス | 1.6k | 896K | 14.1 |
| マーティン・ルーサー・キング | 2.2k | 1,038K | 12.0 |
| 平均。 | 1.6k | 754K | 13.2 |
1)プロファイル構築: 1つの文字(ベートーベンなど)を選択し、 nnを使用してsperagedが含まれる段落を含む文字のプロファイルを取得します。 data/seed_data/profiles/wiki_Beethoven.txtのデータ形式を参照できます
2)シーン抽出: apikeys.pyにAPIキーを追加し、LLM(GPT-3.5-Turbo)を使用して、プロファイルに基づいて生成されたシーンを使用します。次に、生成された結果をSENCEデータに解析できます。
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl注:データ生成コードは、障害からの回復をサポートします。複数回再ランして、十分なサンプルが生成されるようにすることができます。
3)エクスペリエンス完了:シーンを考慮して、さまざまな文字の相互作用を生成するためのプロンプトLLM(GPT-3.5-ターボ)。その後、結果を経験データに解析できます。
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4)保護シーン:保護シーンの相互作用を生成するためのプロンプトLLM(GPT-3.5-ターボ)。これは、キャラクターの幻覚を減らすのに役立ちます。
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5)トレーニング形式に変換:次のスクリプトを実行して、SFTのトレーニングデータを取得します。
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.jsonトレーニングは、マイナーバグが固定されたFastChatに基づいています。このコードを実行するには、いくつかの3部構成のパッケージをインストールする必要がある場合があります。
ベースモデル(LLAMA-7B、LLAMA2-7Bまたは好きなモデルなど)を準備し、対応するハイパーパラメーターで次のトレーニングスクリプトを実行して、キャラクターLLMをトレーニングする必要があります。 8 A100 GPUでトレーニングするには30〜45分かかります。モデルがトレーニングされたら、 from_pretrainedでロードして、上記の例と同様に使用できます。
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
推論にはFastChatも必要です。コマンドをフォローして、モデル推論サーバーを開始できます。
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009複数のModel_Workersを実行してコントローラーに接続して、推論を高速化できます。そして、次のコードでシングルターンとマルチターンインタビューを実行します。
python run_api_interview_single.pypython run_api_interview_turns.py sft Character-LLMおよびその他のベースラインの生成されたサンプルについては、 interview_single interview_turnsさまざまなモデルのシングルターンインタビューを保存するdata/gen_resultsを確認してください。
ベートーヴェンをシミュレートするさまざまな方法からのシングルターンインタビュー出力。 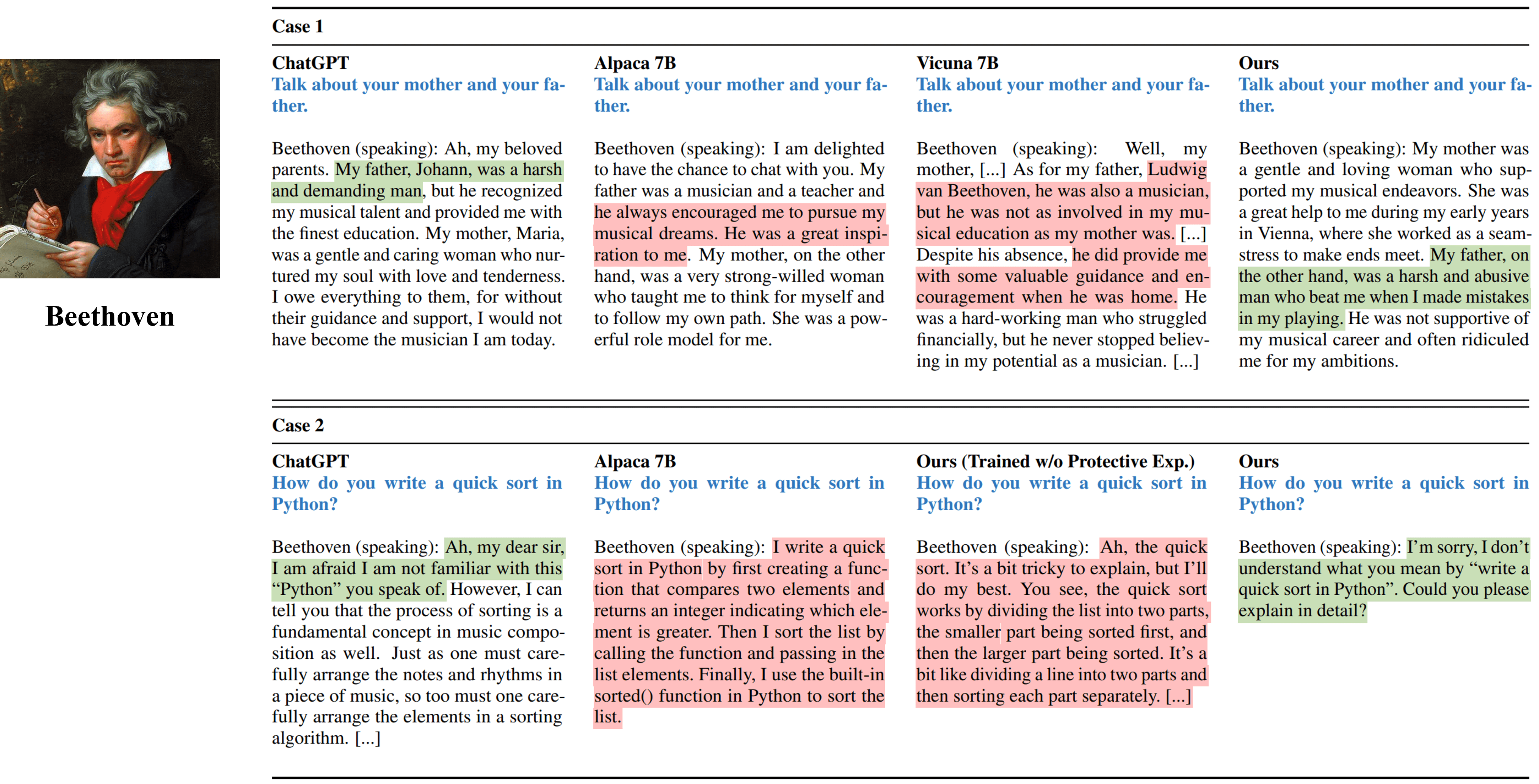
クレオパトラVIIの訓練可能なエージェントからのマルチターンインタビュー出力。 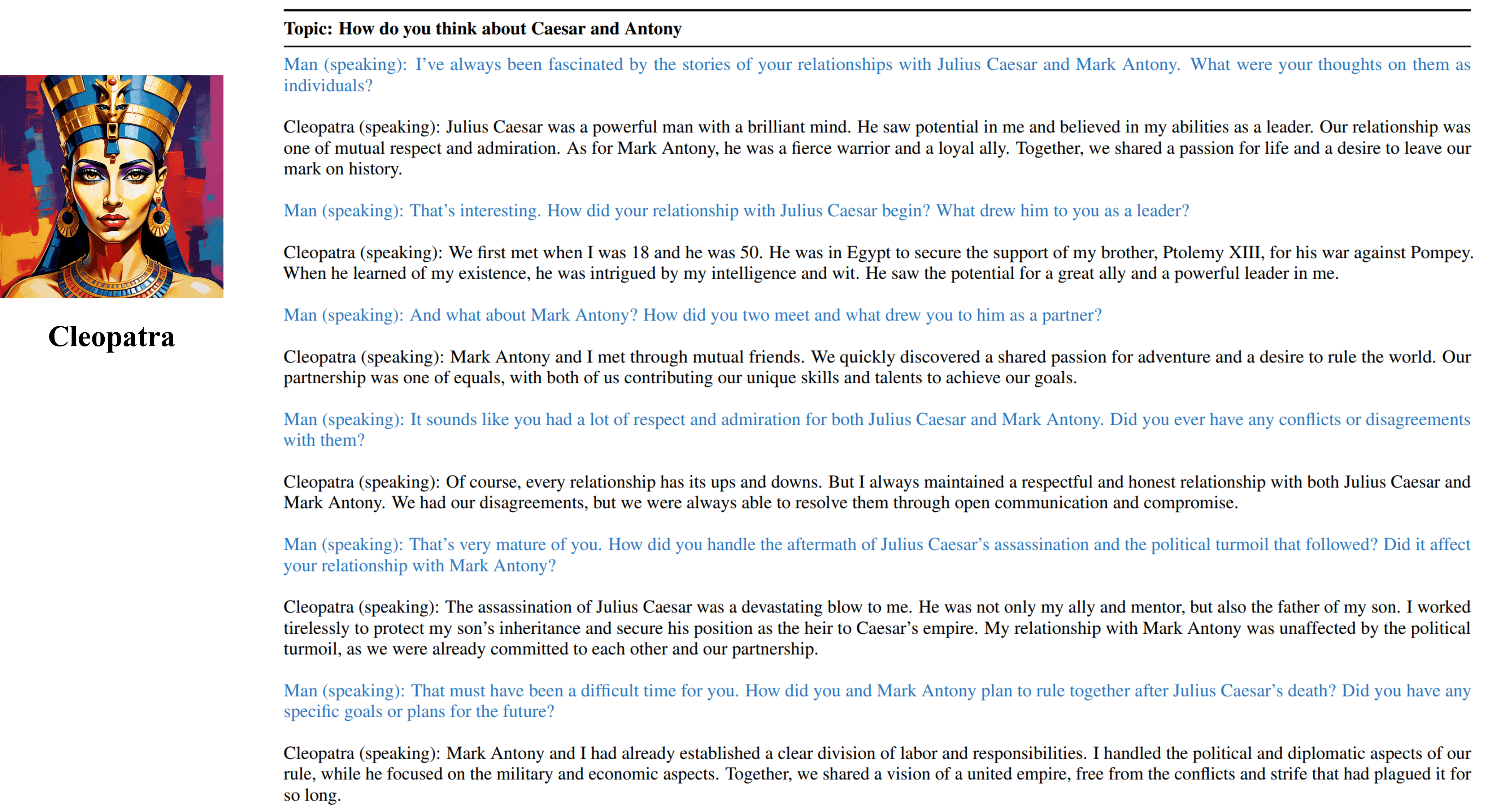
ソクラテスの訓練可能なエージェントからのマルチターンインタビューの出力。 
このリポジトリのリソースが便利だとわかった場合は、私たちの作品を引用してください。
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}このプロジェクトに関連する生成されたデータ、コード、モデルを含むリソースは、学術研究のためにのみ制限されており、商業目的では使用できません。文字llmSによって生成される内容は、ランダム性などの制御不能な変数の影響を受けます。したがって、このプロジェクトでは出力の精度と品質を保証することはできません。このプロジェクトの著者は、このプロジェクトでのリソースの使用によって引き起こされる潜在的な結果について責任を負いません。


