trainable agents
1.0.0
? Model •? Dataset •? Karakter-llm
Ini adalah gudang resmi dari makalah EMNLP 2023 kami. Selamat datang! ???
Kami memperkenalkan karakter-llms agen yang dapat dilatih untuk bermain peran yang belajar dari pengalaman, karakteristik, dan emosi yang sebenarnya. Dibandingkan dengan agen yang diminta, karakter-llm adalah agen yang dapat dilatih yang secara khusus dilatih untuk bermain peran, yang mampu bertindak sebagai orang tertentu, seperti Beethoven, Ratu Cleopatra, Julius Caesar, dll, dengan pengetahuan yang terkait dengan karakter dan kepribadian karakter yang terperinci. Tidak diperlukan dokumen prompt atau referensi tambahan. Untuk mencapai hal ini, kami mengusulkan rekonstruksi pengalaman , proses pembuatan data yang dapat menghasilkan data pengalaman terperinci dan beragam dari karakter tertentu untuk pelatihan. Untuk detail lebih lanjut, silakan merujuk ke kertas.
Tinjauan Aliran Konstruksi Karakter-LLM. 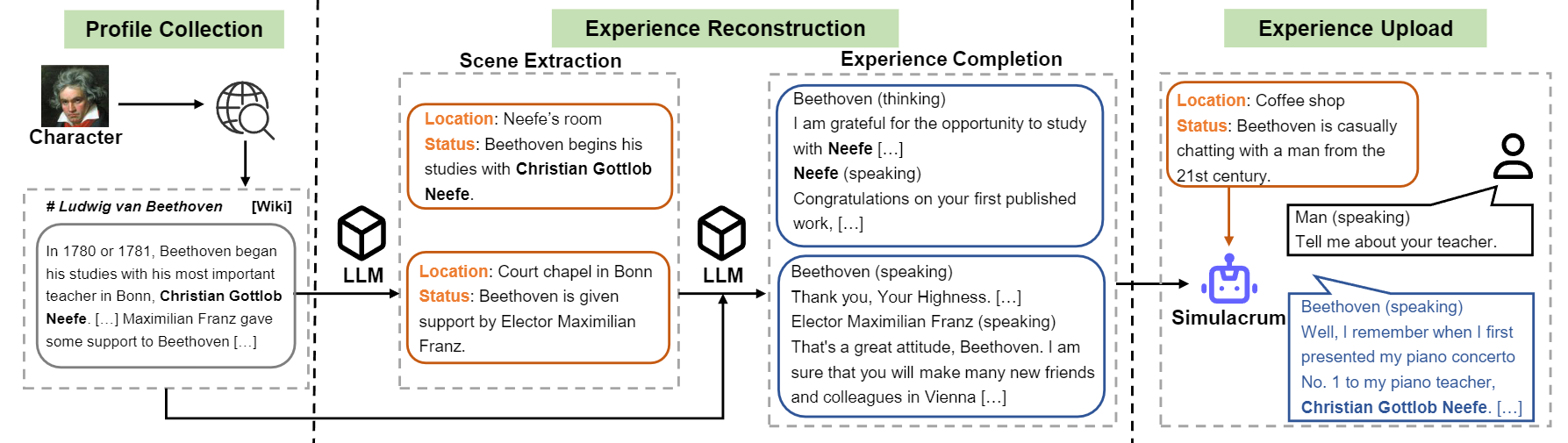
Kami merilis model untuk sembilan karakter yang disebutkan dalam makalah.
| Model | Pos pemeriksaan | Karakter | Lisensi |
|---|---|---|---|
| Karakter-llm-cleopatra-7b | ? karakter-llm-cleopatra-7b-wdiff | Cleopatra VII | Llama 1 |
| Karakter-llm-voldemort-7b | ? karakter-llm-voldemort-7b-wdiff | Lord Voldemort | Llama 1 |
| Karakter-llm-spartacus-7b | ? karakter-llm-spartacus-7b-wdiff | Spartacus | Llama 1 |
| Karakter-llm-hermione-7b | ? karakter-llm-hermione-7b-wdiff | Hermione Granger | Llama 1 |
| Karakter-llm-newton-7b | ? karakter-llm-newton-7b-wdiff | Isaac Newton | Llama 1 |
| Karakter-llm-caesar-7b | ? karakter-llm-caesar-7b-wdiff | Julius Caesar | Llama 1 |
| Karakter-llm-beethoven-7b | ? karakter-llm-beethoven-7b-wdiff | Ludwig Van Beethoven | Llama 1 |
| Karakter-llm-socrates-7b | ? karakter-llm-socrates-7b-wdiff | Socrates | Llama 1 |
| Karakter-llm-martin-7b | ? karakter-llm-martin-7b-wdiff | Martin Luther King | Llama 1 |
Karena lisensi yang digunakan oleh Llama 1, kami melepaskan perbedaan berat badan dan Anda perlu memulihkan bobot dengan menjalankan perintah berikut.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffDan kemudian Anda dapat menggunakan model sebagai chatbot dengan prompt meta.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) Dataset pelatihan dapat diunduh di? Tautan ini, yang berisi sembilan karakter mengalami data yang digunakan untuk melatih karakter-llms. Untuk mengunduh dataset, silakan jalankan kode berikut dengan Python, dan Anda dapat menemukan data yang diunduh di /path/to/local_dir .
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) Dataset prompted/ berisi yang dapat digunakan untuk menyempurnakan yang diawasi secara langsung. Dan generated/ terdiri dari data mentah yang dihasilkan oleh GPT-3.5-turbo, yang dapat dikonversi menjadi gaya prompted . Berikut adalah statistik data pelatihan.
| # Adegan | # Kata-kata | # Turn | |
|---|---|---|---|
| Cleopatra VII | 1.4k | 723k | 14.3 |
| Lord Voldemort | 1.4k | 599k | 13.1 |
| Spartacus | 1.4k | 646K | 12.3 |
| Hermione Granger | 1.5k | 628k | 15.5 |
| Isaac Newton | 1.6k | 772k | 12.6 |
| Julius Caesar | 1.6k | 820k | 12.9 |
| Ludwig Van Beethoven | 1.6k | 663K | 12.2 |
| Socrates | 1.6k | 896k | 14.1 |
| Martin Luther King | 2.2k | 1.038K | 12.0 |
| Rata -rata. | 1.6k | 754k | 13.2 |
1) Konstruksi Profil: Pilih satu karakter (misalnya Beethoven) dan dapatkan beberapa profil untuk karakter, yang berisi paragraf yang dispirasi menggunakan nn . Anda dapat merujuk pada format data data/seed_data/profiles/wiki_Beethoven.txt
2) Ekstraksi adegan: Tambahkan tombol API ke apikeys.py , dan gunakan LLM (GPT-3.5-turbo) ke adegan yang dihasilkan berdasarkan profil. Kemudian Anda dapat menguraikan hasil yang dihasilkan ke dalam data SADE.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlCatatan: Kode pembuatan data mendukung pemulihan dari kegagalan. Anda dapat menjalankannya kembali beberapa kali untuk memastikan sampel yang cukup dihasilkan.
3) Penyelesaian Pengalaman: Prompt LLM (GPT-3.5-Turbo) untuk menghasilkan interaksi karakter yang berbeda yang diberikan adegan. Kemudian Anda dapat menguraikan hasil menjadi data pengalaman.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) Adegan Pelindung: Prompt LLM (GPT-3.5-Turbo) untuk menghasilkan interaksi untuk adegan pelindung, yang membantu mengurangi halusinasi karakter.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) Konversi ke format pelatihan: Jalankan skrip berikut untuk mendapatkan data pelatihan untuk SFT.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json Pelatihan ini didasarkan pada FastChat dengan bug kecil tetap. Anda mungkin perlu menginstal beberapa paket bagian ketiga untuk menjalankan kode ini.
Anda perlu menyiapkan model dasar (misalnya Llama-7b, Llama2-7B atau model lain yang Anda sukai) dan menjalankan skrip pelatihan berikut dengan hyper-parameter yang sesuai untuk melatih karakter-llm. Butuh 30 ~ 45 menit untuk berlatih di 8 A100 GPU. Setelah model dilatih, Anda dapat memuatnya dengan from_pretrained dan menggunakannya mirip dengan contoh di atas.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
Inferensi juga membutuhkan FastChat . Anda dapat memulai server inferensi model dengan mengikuti perintah:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009Anda dapat menjalankan beberapa Model_Workers untuk terhubung ke pengontrol untuk mempercepat inferensi. Dan kemudian, jalankan singe-turn dan wawancara multi-turn dengan kode berikut.
python run_api_interview_single.pypython run_api_interview_turns.py sft Untuk sampel yang dihasilkan dari karakter-llm dan garis dasar lainnya, silakan periksa data/gen_results , di mana interview_single menyimpan wawancara putaran tunggal dari model yang berbeda, sementara interview_turns menyimpan hasil wawancara multi-putar.
Output wawancara satu putaran dari berbagai metode yang mensimulasikan Beethoven. 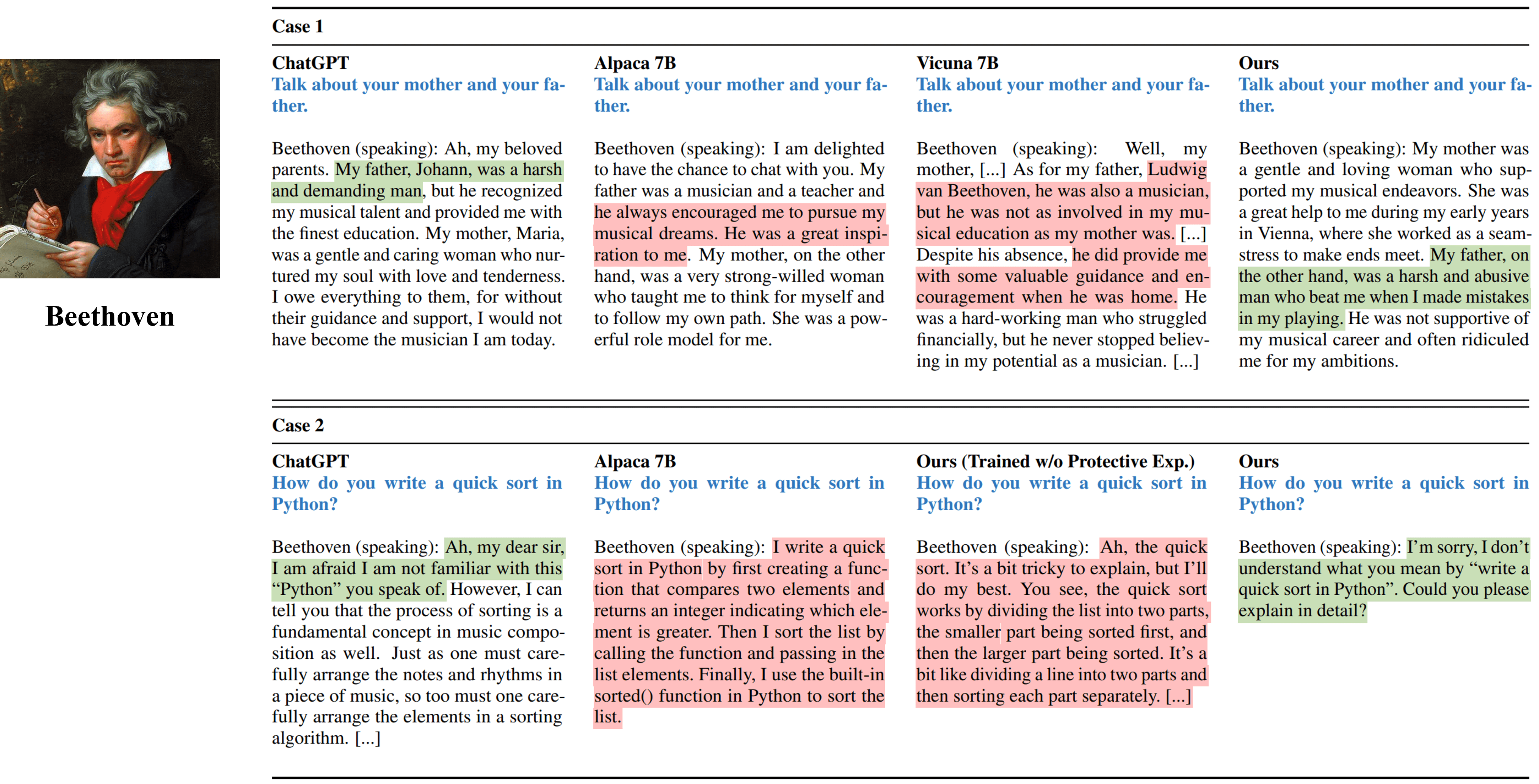
Output wawancara multi-putar dari agen kami yang dapat dilatih dari Cleopatra VII. 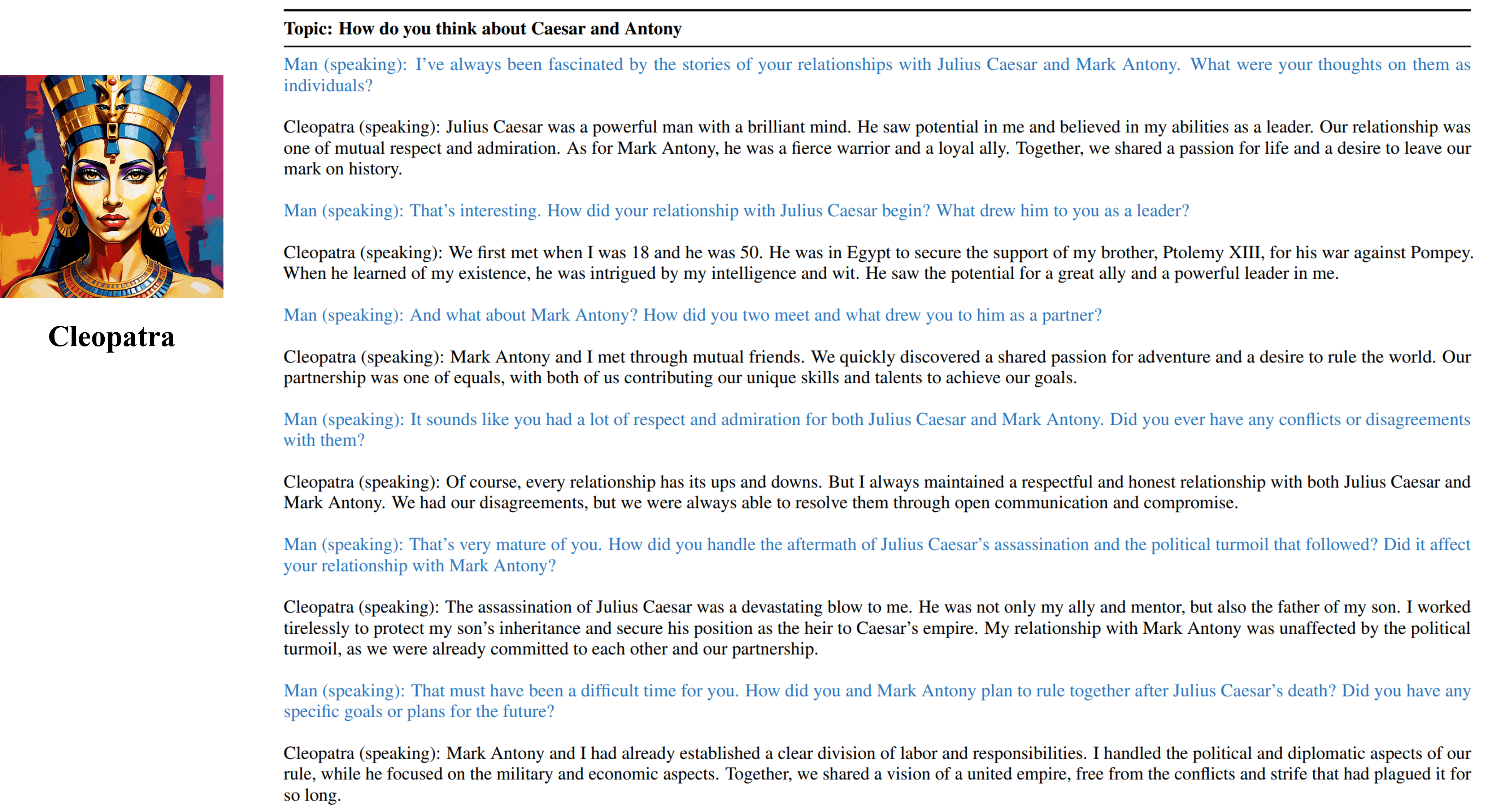
Output wawancara multi-putar dari agen Socrates kami yang dapat dilatih. 
Harap kutip pekerjaan kami jika Anda menemukan sumber daya di repositori ini berguna:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}Sumber daya, termasuk data yang dihasilkan, kode dan model, yang terkait dengan proyek ini dibatasi hanya untuk tujuan penelitian akademik dan tidak dapat digunakan untuk tujuan komersial. Isi yang dihasilkan oleh karakter-LLM dipengaruhi oleh variabel yang tidak terkendali seperti keacakan, dan oleh karena itu, akurasi dan kualitas output tidak dapat dijamin oleh proyek ini. Para penulis proyek ini tidak bertanggung jawab atas potensi konsekuensi yang disebabkan oleh penggunaan sumber daya dalam proyek ini.


