trainable agents
1.0.0
؟ النماذج •؟ مجموعة البيانات •؟ شخصية
هذا هو المستودع الرسمي لورقة EMNLP 2023 الخاصة بنا. مرحباً! ؟؟؟
نحن نقدم Forme-Llms وكيلًا قابلاً للتدريب للعب الأدوار الذي يتعلم من التجارب والخصائص والعواطف الفعلية. بالمقارنة مع الوكلاء المدعوين ، فإن الأحرف من العوامل هي عوامل قابلة للتدريب تدرب على وجه التحديد لعب الأدوار ، والتي يمكن أن تعمل كأشخاص محددين ، مثل بيتهوفن ، الملكة كليوباترا ، يوليوس قيصر ، إلخ ، مع شخصيات مفصلة ذات صلة بالشخصية وشخصيات الشخصية التمثيلية. لا توجد حاجة إلى مستند موجه أو مرجعي إضافي. لتحقيق ذلك ، نقترح إعادة بناء الخبرة ، وهي عملية لتوليد البيانات التي يمكن أن تولد بيانات خبرة مفصلة ومتنوعة ذات طابع معين للتدريب. لمزيد من التفاصيل ، يرجى الرجوع إلى الورقة.
نظرة عامة على تدفق البناء للشخصية. 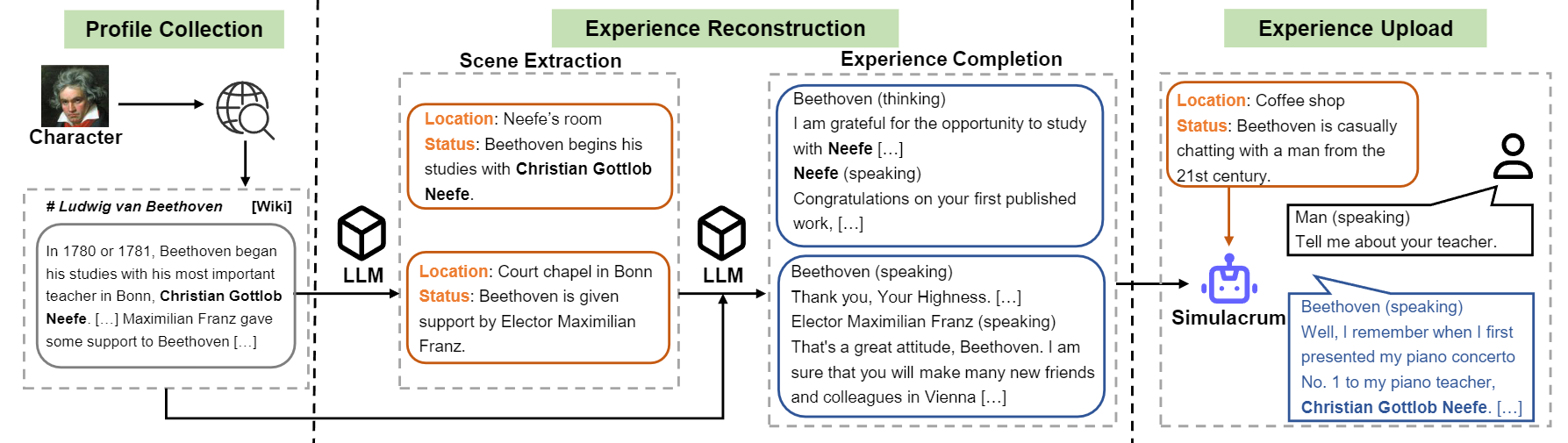
نطلق النموذج لتسعة أحرف المذكورة في الورقة.
| نموذج | نقطة التفتيش | شخصية | رخصة |
|---|---|---|---|
| حرف-llm-cleopatra-7b | ؟ حرف-llm-cleopatra-7b-wdiff | كليوباترا السابع | لاما 1 |
| حرف-llm-voldemort-7b | ؟ حرف-llm-voldemort-7b-wdiff | اللورد فولدمورت | لاما 1 |
| حرف-llm-spartacus-7b | ؟ حرف-llm-spartacus-7b-wdiff | سبارتاكوس | لاما 1 |
| حرف-LLM-HERMIONE-7B | ؟ حرف-LLM-HERMIONE-7B-WDIFF | هيرميون جرانجر | لاما 1 |
| حرف-ملم نورتون -7 ب | ؟ حرف-ملم نورتون-7 ب ويدف | إسحاق نيوتن | لاما 1 |
| حرف-ملم كايزار-7 ب | ؟ حرف-ملم-كايزار-7B-WDIFF | يوليوس قيصر | لاما 1 |
| شخصية-ملم بيتهوفن-7 ب | ؟ شخصية-ملم-بيتهوفن-7 ب ودف | لودفيج فان بيتهوفن | لاما 1 |
| حرف-ملم-سقرا-7 ب | ؟ حرف-ملم-سقرا-7B-WDIFF | سقراط | لاما 1 |
| حرف-مارتين-7 ب | ؟ حرف-مارتين-7B-WDIFF | مارتن لوثر كينغ | لاما 1 |
نظرًا للترخيص الذي يستخدمه Llama 1 ، فإننا نطلق اختلافات الوزن وتحتاج إلى استرداد الأوزان عن طريق تشغيل الأمر التالي.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffوبعد ذلك يمكنك استخدام النموذج كدردشة مع موجه التعريف.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) يمكن تنزيل مجموعات بيانات التدريب في؟ هذا الرابط ، الذي يحتوي على تسعة أحرف تجربة بيانات تستخدم لتدريب الأحرف. لتنزيل مجموعة البيانات ، يرجى تشغيل الكود التالي مع Python ، ويمكنك العثور على البيانات التي تم تنزيلها في /path/to/local_dir .
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) prompted/ تحتوي على مجموعات البيانات التي يمكن استخدامها للضبط الخاضع للإشراف مباشرة. generated/ يتكون من البيانات الأولية التي تم إنشاؤها بواسطة GPT-3.5-Turbo ، والتي يمكن تحويلها إلى نمط prompted . فيما يلي إحصائيات بيانات التدريب.
| # مشاهد | # كلمات | # المنعطفات | |
|---|---|---|---|
| كليوباترا السابع | 1.4k | 723 كيلو | 14.3 |
| اللورد فولدمورت | 1.4k | 599K | 13.1 |
| سبارتاكوس | 1.4k | 646 كيلو | 12.3 |
| هيرميون جرانجر | 1.5k | 628 كيلو | 15.5 |
| إسحاق نيوتن | 1.6k | 772K | 12.6 |
| يوليوس قيصر | 1.6k | 820 كيلو | 12.9 |
| لودفيج فان بيتهوفن | 1.6k | 663 كيلو | 12.2 |
| سقراط | 1.6k | 896K | 14.1 |
| مارتن لوثر كينغ | 2.2k | 1،038k | 12.0 |
| متوسط. | 1.6k | 754k | 13.2 |
1) بناء الملف الشخصي: اختر حرفًا واحدًا (على سبيل المثال Beethoven) واحصل على بعض الملفات الشخصية للشخصية ، والتي تحتوي على فقرات تتفوق باستخدام nn . يمكنك الرجوع إلى تنسيق البيانات data/seed_data/profiles/wiki_Beethoven.txt
2) استخراج المشهد: إضافة مفاتيح API إلى apikeys.py ، واستخدم LLM (GPT-3.5-TURBO) لمشاهد تم إنشاؤها بناءً على ملف التعريف. ثم يمكنك تحليل النتائج التي تم إنشاؤها إلى بيانات Sence.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlملاحظة: يدعم رمز توليد البيانات الاسترداد من الفشل. يمكنك إعادة تشغيله عدة مرات لضمان إنشاء عينات كافية.
3) إكمال الخبرة: موجه LLM (GPT-3.5-TURBO) لإنشاء تفاعلات من أحرف مختلفة بالنظر إلى المشاهد. ثم يمكنك تحليل النتائج في بيانات التجربة.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) المشهد الوقائي: المطالبة LLM (GPT-3.5-TURBO) لتوليد تفاعلات للمشاهد الواقية ، مما يساعد على تقليل الهلوسة الشخصية.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) التحويل إلى تنسيق التدريب: قم بتشغيل البرنامج النصي التالي للحصول على بيانات التدريب لـ SFT.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json يعتمد التدريب على FastChat مع علة صغيرة ثابتة. قد تحتاج إلى تثبيت بعض الحزم من الجزء الثالث لتشغيل هذا الرمز.
تحتاج إلى إعداد النموذج الأساسي (على سبيل المثال llama-7b أو llama2-7b أو غيرها من الطرز التي تريدها) وتشغيل البرنامج النصي التدريبي التالي مع المعلمات المفرطة المقابلة لتدريب الشخصيات. يجب أن يستغرق الأمر 30 ~ 45 دقيقة للتدريب على 8 A100 وحدات معالجة الرسومات. بمجرد أن يتم تدريب النموذج ، يمكنك تحميله من خلال from_pretrained واستخدامه مماثلة للمثال أعلاه.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
الاستدلال يتطلب أيضا FastChat . يمكنك بدء تشغيل خادم استنتاج النموذج باتباع الأوامر:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009يمكنك تشغيل العديد من عمال Model_ للاتصال بوحدة التحكم لتسريع الاستدلال. وبعد ذلك ، قم بتشغيل المقابلات المنعطفات في Singe و Multi Turn مع الكود التالي.
python run_api_interview_single.pypython run_api_interview_turns.py sft بالنسبة لعينات تم إنشاؤها من الأحرف-LLM وخطوط الأساس الأخرى ، يرجى التحقق من data/gen_results ، حيث تقوم interview_single بتخزين المقابلات المفردة المنعطف على النماذج المختلفة ، بينما تقوم interview_turns بمتجر المقابلات المتعددة.
مخرجات مقابلة واحدة من طرق مختلفة تحاكي بيتهوفن. 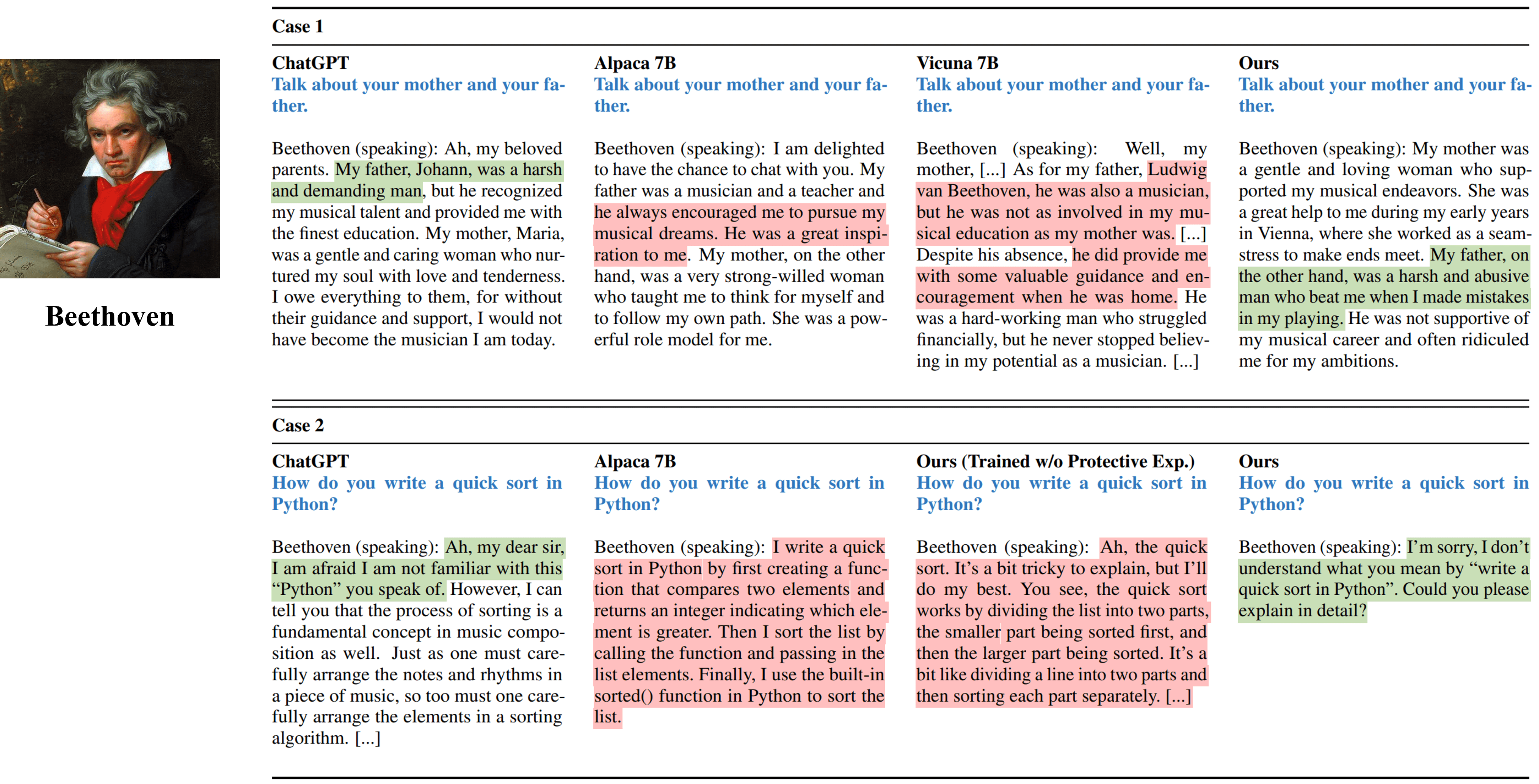
مخرجات مقابلة متعددة المنعطفات من وكيلنا القابل للتدريب في كليوباترا السابع. 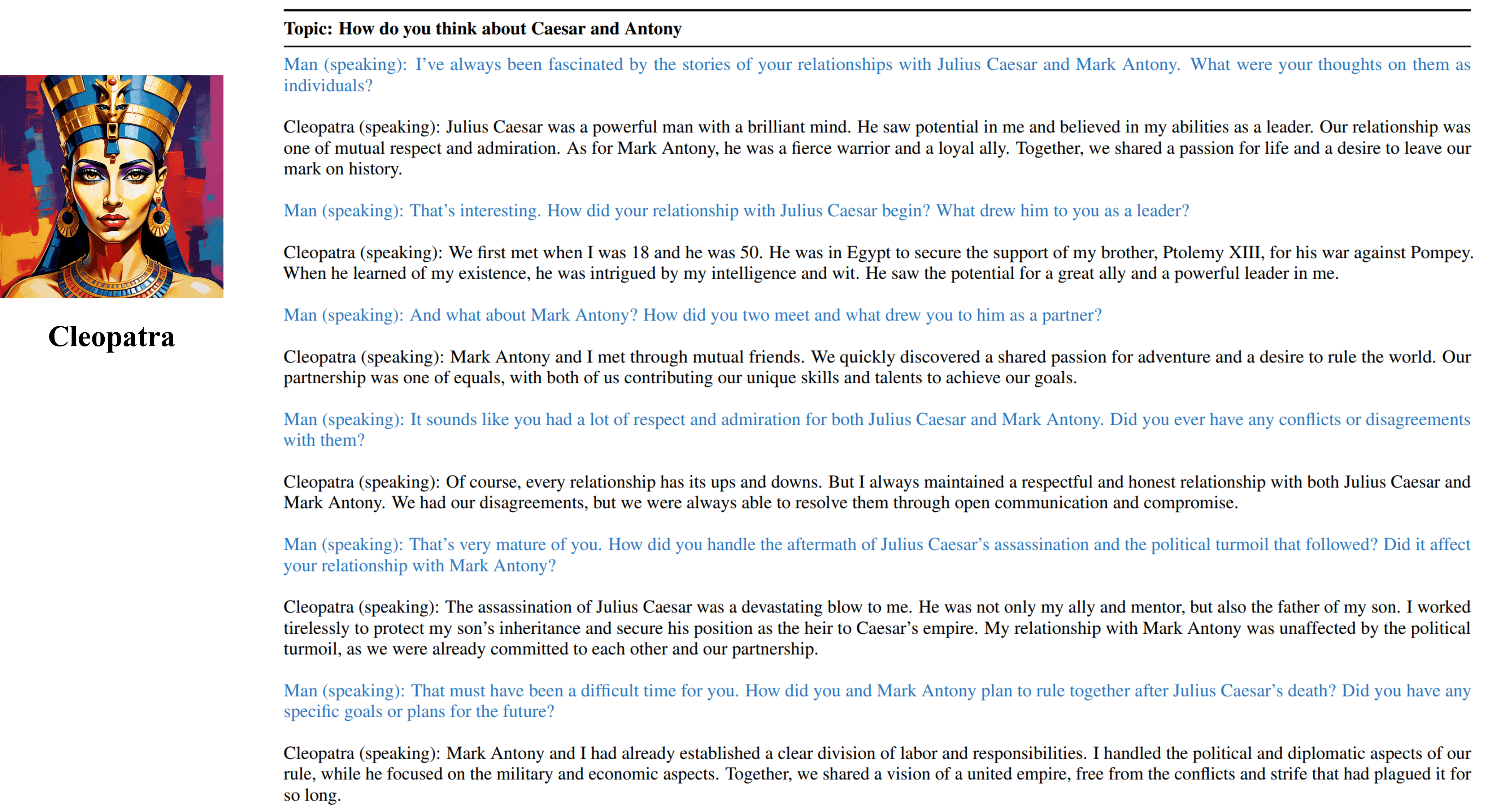
مخرجات مقابلة متعددة المنعطفات من وكيل سقراط القابل للتدريب لدينا. 
يرجى الاستشهاد بعملنا إذا وجدت الموارد في هذا المستودع مفيدة:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}يتم تقييد الموارد ، بما في ذلك البيانات والرموز والنماذج التي تم إنشاؤها ، المرتبطة بهذا المشروع لأغراض البحث الأكاديمي فقط ولا يمكن استخدامها للأغراض التجارية. تتأثر المحتويات التي تنتجها الأحرف إلى المتغيرات التي لا يمكن السيطرة عليها مثل العشوائية ، وبالتالي ، لا يمكن ضمان دقة وجودة الإخراج من خلال هذا المشروع. مؤلفو هذا المشروع ليسوا مسؤولين عن أي عواقب محتملة ناتجة عن استخدام الموارد في هذا المشروع.


