trainable agents
1.0.0
? Modelos •? Conjunto de datos •? Carácter-llm
Este es el repositorio oficial de nuestro artículo EMNLP 2023. ¡Bienvenido! ????
Introducimos a los personajes un agente capacitable para el juego de roles que aprende de experiencias, características y emociones reales. En comparación con los agentes solicitados, los LLM de caracteres son agentes entrenables que se entrenan específicamente para el juego de roles, que pueden actuar como personas específicas, como Beethoven, la Reina Cleopatra, Julius César, etc., con conocimiento detallado relacionado con el carácter y personalidades representativas de los caracteres. No se necesita ningún documento adicional de solicitud o referencia. Para lograr esto, proponemos la Reconstrucción de la experiencia , un proceso de generación de datos que puede generar datos de experiencia detallados y diversos de cierto carácter para el entrenamiento. Para obtener más detalles, consulte el documento.
Descripción general del flujo de construcción de carácter-llm. 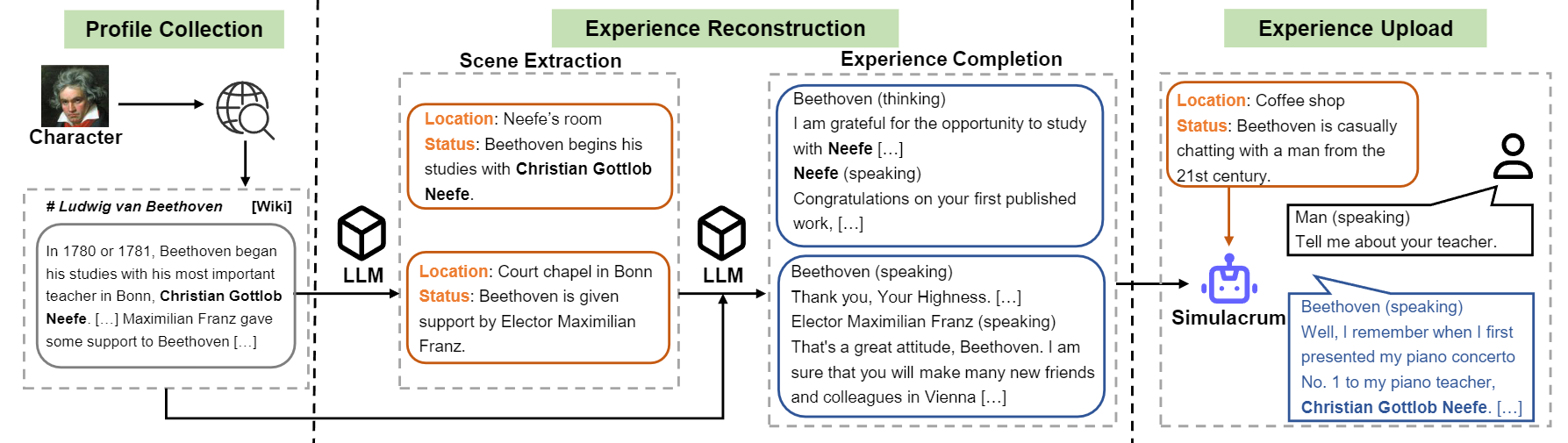
Lanzamos el modelo para nueve caracteres mencionados en el documento.
| Modelo | Control | Personaje | Licencia |
|---|---|---|---|
| Personaje-llm-cleopatra-7b | ? personaje-llm-cleopatra-7b-wdiff | Cleopatra VII | LLAMA 1 |
| Personaje-llm-Voldemort-7b | ? personaje-llm-Voldemort-7b-Wdiff | Lord Voldemort | LLAMA 1 |
| Personaje-llm spartacus-7b | ? personaje-llm spartacus-7b-wdiff | Espartaco | LLAMA 1 |
| Personaje-llm-hermione-7b | ? personaje-llm-hermione-7b-wdiff | Hermione Granger | LLAMA 1 |
| Personaje-llm-newton-7b | ? personaje-llm-newton-7b-wdiff | Isaac Newton | LLAMA 1 |
| Personaje-llm-caesar-7b | ? personaje-llm-caesar-7b-wdiff | Julio César | LLAMA 1 |
| Personaje-llm-beethoven-7b | ? personaje-llm-beethoven-7b-wdiff | Ludwig Van Beethoven | LLAMA 1 |
| Personaje-llm-Socrates-7b | ? personaje-llm-Socrates-7B-Wdiff | Sócrates | LLAMA 1 |
| Personaje-llm-martin-7b | ? personaje-llm-martin-7b-wdiff | Martin Luther King | LLAMA 1 |
Debido a la licencia utilizada por Llama 1, liberamos las diferencias de peso y debe recuperar los pesos ejecutando el siguiente comando.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffY luego puede usar el modelo como chatbot con el meta solicitante.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) ¿Se pueden descargar conjuntos de datos de capacitación en? Este enlace, que contiene nueve caracteres de experiencia de experiencia utilizados para entrenar caracteres-LLM. Para descargar el conjunto de datos, ejecute el siguiente código con Python, y puede encontrar los datos descargados en /path/to/local_dir .
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) Los conjuntos de datos prompted/ contienen directamente para el ajuste fino supervisado. Y generated/ consiste en datos sin procesar que generan GPT-3.5-TURBO, que se puede convertir en estilo prompted . Aquí están las estadísticas de los datos de capacitación.
| # Escenas | # Palabras | # Giros | |
|---|---|---|---|
| Cleopatra VII | 1.4k | 723K | 14.3 |
| Lord Voldemort | 1.4k | 599k | 13.1 |
| Espartaco | 1.4k | 646k | 12.3 |
| Hermione Granger | 1.5k | 628k | 15.5 |
| Isaac Newton | 1.6k | 772k | 12.6 |
| Julio César | 1.6k | 820k | 12.9 |
| Ludwig Van Beethoven | 1.6k | 663k | 12.2 |
| Sócrates | 1.6k | 896k | 14.1 |
| Martin Luther King | 2.2k | 1.038k | 12.0 |
| Avg. | 1.6k | 754k | 13.2 |
1) Construcción del perfil: elija un carácter (por ejemplo, Beethoven) y obtenga un perfil para el personaje, que contiene párrafos esperados usando nn . Puede consultar el formato de datos de data/seed_data/profiles/wiki_Beethoven.txt
2) Extracción de la escena: Agregue las teclas API a apikeys.py y use LLM (GPT-3.5-TURBO) a las escenas generadas basadas en el perfil. Luego puede analizar los resultados generados en los datos de SENCE.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlNota: El código de generación de datos admite la recuperación de la falla. Puede volver a ejecutarlo varias veces para garantizar que se generen muestras suficientes.
3) Finalización de la experiencia: pronto LLM (GPT-3.5-TURBO) para generar interacciones de diferentes personajes dadas las escenas. Luego puede analizar los resultados en datos de experiencia.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) Escena de protección: Prácticas LLM (GPT-3.5-TURBO) para generar interacciones para escenas protectores, lo que ayuda a reducir la alucinación de los personajes.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) Convertir al formato de entrenamiento: ejecute el siguiente script para obtener los datos de capacitación para SFT.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json El entrenamiento se basa en FastChat con un error menor solucionado. Es posible que deba instalar algunos paquetes de terceros para ejecutar este código.
Debe preparar el modelo base (por ejemplo, LLAMA-7B, LLAMA2-7B u otros modelos que le gusten) y ejecutar el siguiente guión de entrenamiento con los hiper-parámetros correspondientes para entrenar a caracteres-llm. Debería tomar 30 ~ 45 minutos para entrenar en 8 GPU A100. Una vez que el modelo está entrenado, puede cargarlo de from_pretrained y usarlo similar al ejemplo anterior.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
La inferencia también requiere FastChat . Puede iniciar el servidor de inferencia de modelos siguiendo comandos:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009Puede ejecutar múltiples Model_Workers para conectarse al controlador para acelerar la inferencia. Y luego, ejecute entrevistas con giro y múltiple giro con el siguiente código.
python run_api_interview_single.pypython run_api_interview_turns.py sft Para muestras generadas de carácter-llm y otras líneas de base, verifique data/gen_results , en las que interview_single almacena entrevistas de un solo cambio de diferentes modelos, mientras que interview_turns almacena resultados de entrevistas con múltiples vueltas.
Salidas de entrevista de un solo cambio de diferentes métodos que simulan Beethoven. 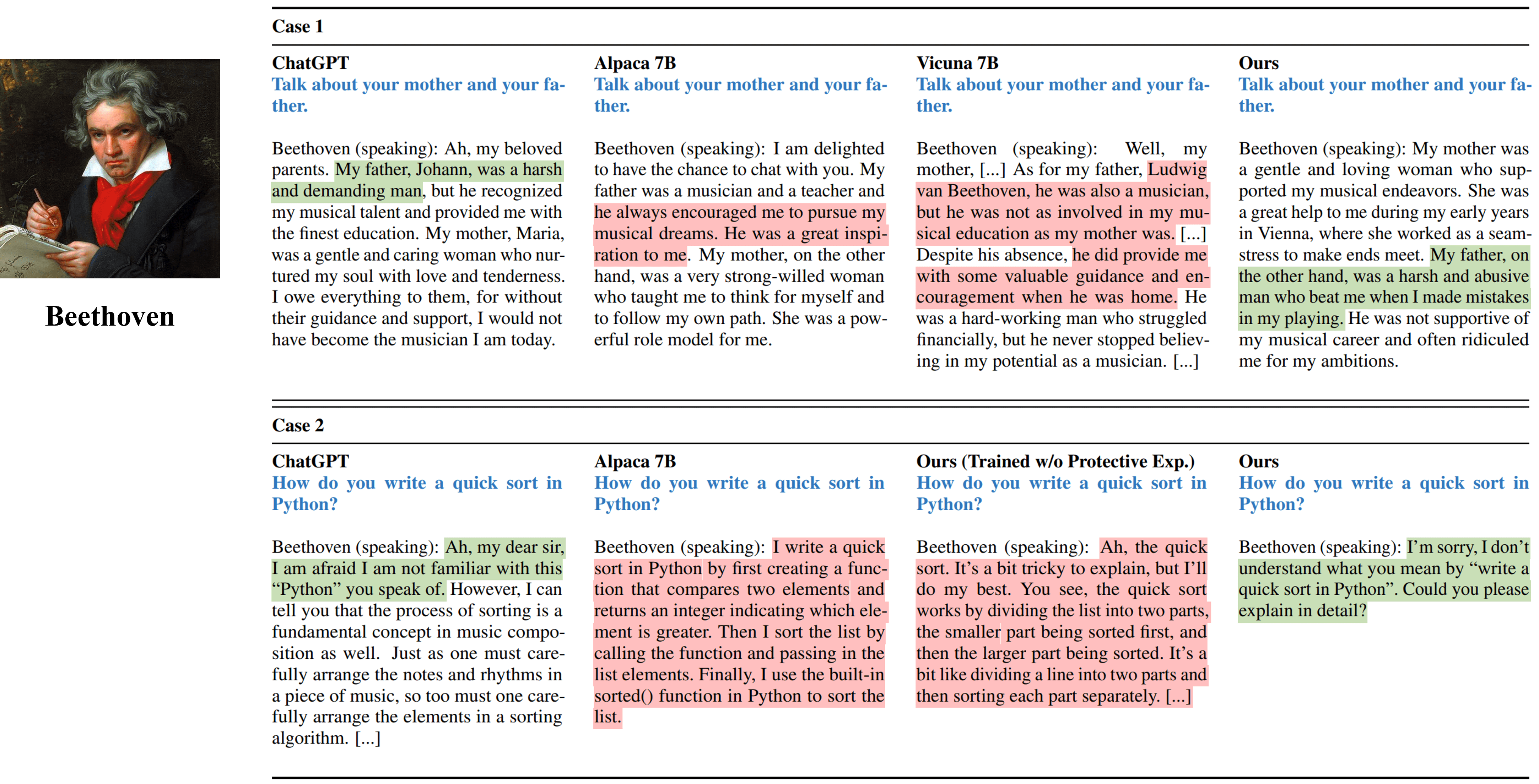
Los resultados de entrevistas de múltiples vueltas de nuestro agente capacitable de Cleopatra VII. 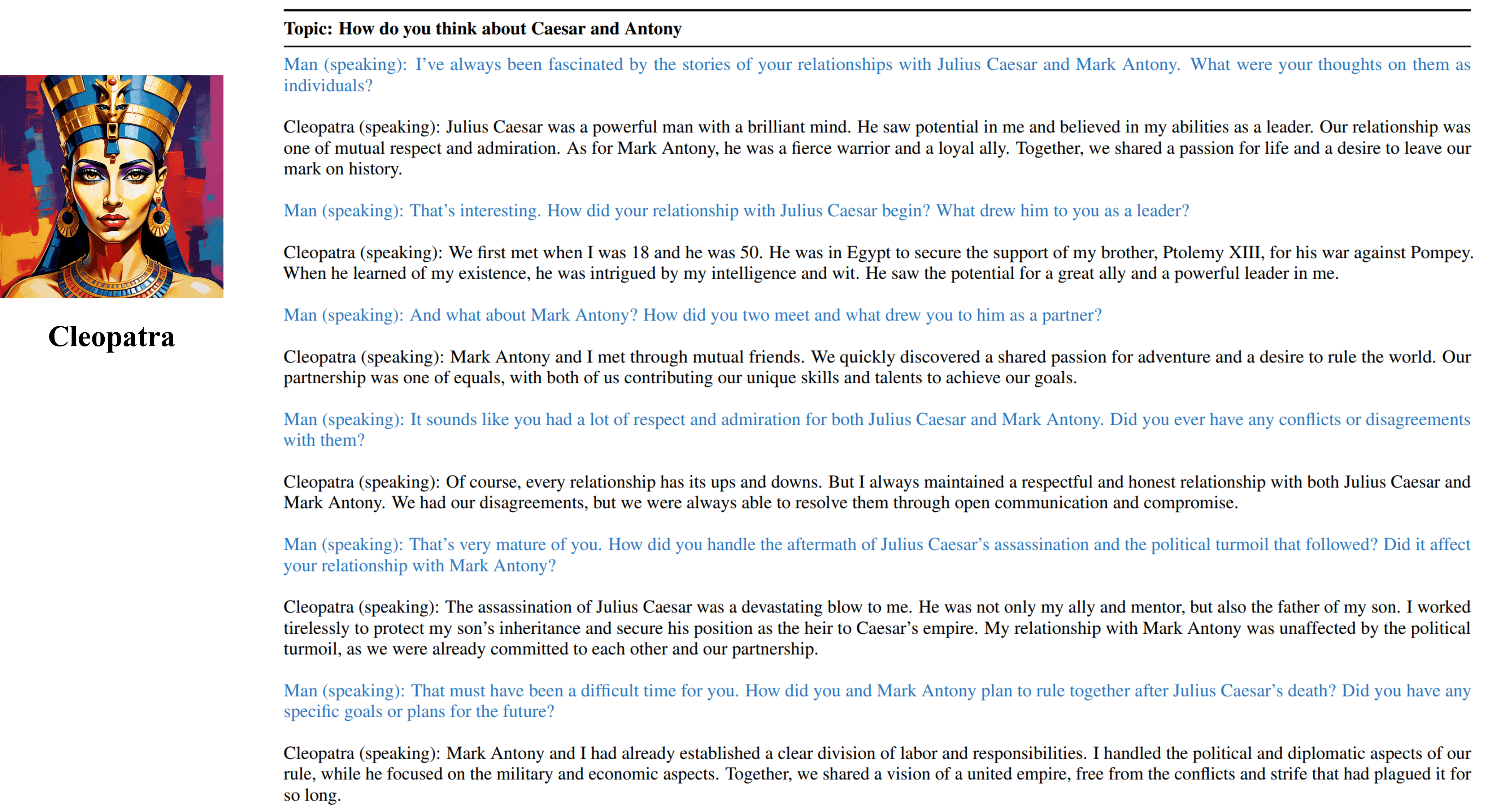
Los resultados de entrevistas de múltiples vueltas de nuestro agente capacitable de Sócrates. 
Cite nuestro trabajo si encontró útiles los recursos en este repositorio:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}Los recursos, incluidos los datos, el código y los modelos generados, asociados con este proyecto están restringidos solo para fines de investigación académica y no pueden usarse con fines comerciales. Los contenidos producidos por caracteres-llms están influenciados por variables incontrolables como la aleatoriedad y, por lo tanto, la precisión y la calidad de la producción no pueden garantizarse por este proyecto. Los autores de este proyecto no son responsables de las posibles consecuencias causadas por el uso de los recursos en este proyecto.


