trainable agents
1.0.0
? Modèles •? Ensemble de données •? Caractéristique
Il s'agit du référentiel officiel de notre article EMNLP 2023. Accueillir! ???
Nous présentons des caractéristiques un agent formable pour un jeu de rôle qui apprend des expériences réelles, des caractéristiques et des émotions. Par rapport aux agents invités, les lilms de personnages sont des agents formables qui spécifiquement formés au jeu de rôle, qui sont capables d'agir comme des personnes spécifiques, comme Beethoven, Queen Cléopâtre, Julius Caesar, etc., avec des connaissances détaillées liées au caractère et des personnalités représentatives des personnages. Aucune invite ou document de référence supplémentaire n'est nécessaire. Pour y parvenir, nous proposons une reconstruction de l'expérience , un processus de génération de données qui peut générer des données d'expérience détaillées et diverses de certains caractère pour la formation. Pour plus de détails, veuillez vous référer au document.
Aperçu du flux de construction du caractéristique-llm. 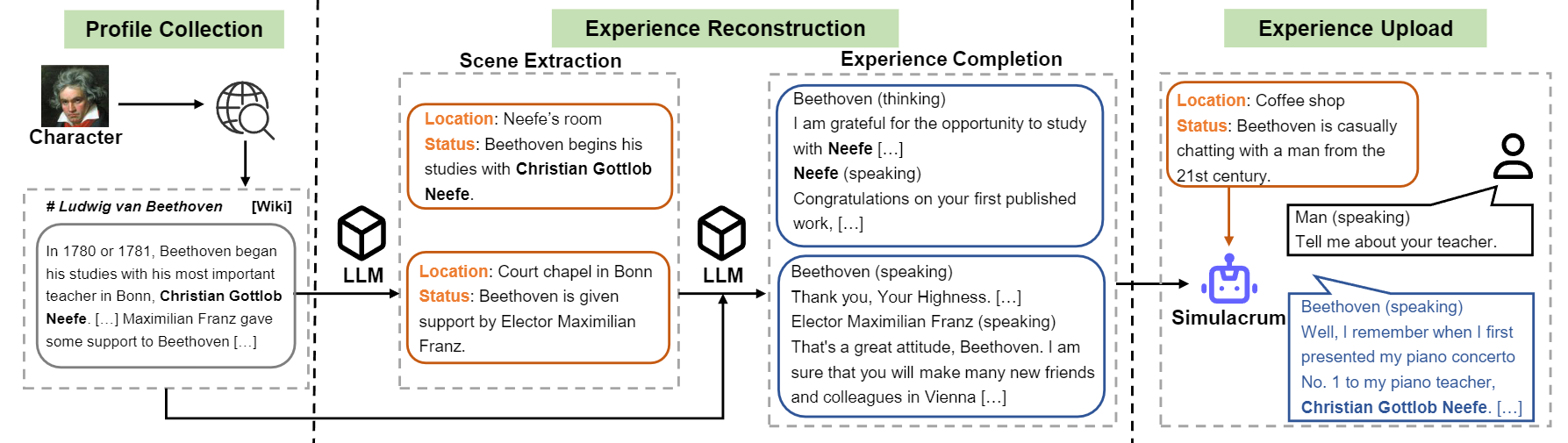
Nous libérons le modèle pour neuf caractères mentionnés dans l'article.
| Modèle | Point de contrôle | Personnage | Licence |
|---|---|---|---|
| Caracter-llm-Cleopatra-7b | ? Caracter-llm-Cleopra-7b-wdiff | Cléopâtre VII | Lama 1 |
| Caractéristique-llm-voldemort-7b | ? Caracter-llm-voldemort-7b-wdiff | Lord Voldemort | Lama 1 |
| Caractéristique-llm-spartacus-7b | ? caractéristique-llm-spartacus-7b-wdiff | Spartacus | Lama 1 |
| Caracter-llm-Hermione-7b | ? Caracter-llm-Hermione-7b-wdiff | Hermione Granger | Lama 1 |
| Personnage-llm-newton-7b | ? personnage-llm-newton-7b-wdiff | Isaac Newton | Lama 1 |
| Caractéristique-llm-caesar-7b | ? Caracter-llm-Caesar-7b-wdiff | Julius Caesar | Lama 1 |
| Caractéristique-llm-beethoven-7b | ? caractéristique-llm-beethoven-7b-wdiff | Ludwig van beethoven | Lama 1 |
| Personnage-llm-socrate-7b | ? personnage-llm-socrate-7b-wdiff | Socrate | Lama 1 |
| Caractéristique-llm-martin-7b | ? personnage-llm-martin-7b-wdiff | Martin Luther King | Lama 1 |
En raison de la licence utilisée par Llama 1, nous libérons les différences de poids et vous devez récupérer les poids en exécutant la commande suivante.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffEt puis vous pouvez utiliser le modèle comme chatbot avec l'invite Meta.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) Les ensembles de données de formation peuvent être téléchargés à? Ce lien, qui contient neuf caractères expérimentés des données utilisées pour former des lilms de caractères. Pour télécharger l'ensemble de données, veuillez exécuter le code suivant avec Python et vous pouvez trouver les données téléchargées dans /path/to/local_dir .
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) Les ensembles de données prompted/ contiennent des données qui peuvent être utilisées pour le réglage fin supervisé directement. Et generated/ se compose de données brutes générées par GPT-3.5-turbo, qui peuvent être converties en style prompted . Voici les statistiques des données de formation.
| # Scènes | # Mots | # Tourne | |
|---|---|---|---|
| Cléopâtre VII | 1,4k | 723K | 14.3 |
| Lord Voldemort | 1,4k | 599k | 13.1 |
| Spartacus | 1,4k | 646K | 12.3 |
| Hermione Granger | 1,5k | 628K | 15.5 |
| Isaac Newton | 1,6k | 772K | 12.6 |
| Julius Caesar | 1,6k | 820k | 12.9 |
| Ludwig van beethoven | 1,6k | 663K | 12.2 |
| Socrate | 1,6k | 896K | 14.1 |
| Martin Luther King | 2.2k | 1 038K | 12.0 |
| Avg. | 1,6k | 754K | 13.2 |
1) Construction de profil: Choisissez un caractère (par exemple Beethoven) et obtenez un profil pour le caractère, qui contient des paragraphes sperés à l'aide de nn . Vous pouvez vous référer au format de données de data/seed_data/profiles/wiki_Beethoven.txt
2) Extraction de scène: ajoutez des touches API à apikeys.py et utilisez LLM (GPT-3.5-Turbo) pour générer des scènes basées sur le profil. Ensuite, vous pouvez analyser les résultats générés en données de Sense.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlRemarque: Le code de génération de données prend en charge la récupération de l'échec. Vous pouvez le redémarrer plusieurs fois pour vous assurer que des échantillons suffisants sont générés.
3) Expérience de l'expérience: Prompt LLM (GPT-3.5-Turbo) pour générer des interactions de différents caractères compte tenu des scènes. Ensuite, vous pouvez analyser les résultats des données d'expérience.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) Scène protectrice: invite LLM (GPT-3.5-turbo) pour générer des interactions pour les scènes de protection, ce qui aide à réduire l'hallucination du caractère.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) Convertir au format de formation: exécutez le script suivant pour obtenir les données de formation pour SFT.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json La formation est basée sur FastChat avec un bug mineur corrigé. Vous devrez peut-être installer certains packages en tiers pour exécuter ce code.
Vous devez préparer le modèle de base (par exemple, LLAMA-7B, LLAMA2-7B ou d'autres modèles que vous aimez) et exécuter le script d'entraînement suivant avec les hyper-paramètres correspondants pour former le caractéristique-llm. Cela devrait prendre 30 à 45 minutes pour s'entraîner sur 8 GPU A100. Une fois le modèle formé, vous pouvez le charger par from_pretrained et l'utiliser similaire à l'exemple ci-dessus.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
L'inférence nécessite également FastChat . Vous pouvez démarrer le Model Inference Server en suivant les commandes:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009Vous pouvez exécuter plusieurs Model_Workers pour vous connecter au contrôleur pour accélérer l'inférence. Et puis, exécutez les interviews Singe-tour et multi-tour avec le code suivant.
python run_api_interview_single.pypython run_api_interview_turns.py sft Pour les échantillons générés de caractéristiques et d'autres lignes de base, veuillez consulter data/gen_results , dans lesquelles interview_single stocke des entretiens à tour de tour de différents modèles, tandis que interview_turns stocke les résultats des entretiens multi-tour.
Les interviews à un tour à tour des différentes méthodes simulant Beethoven. 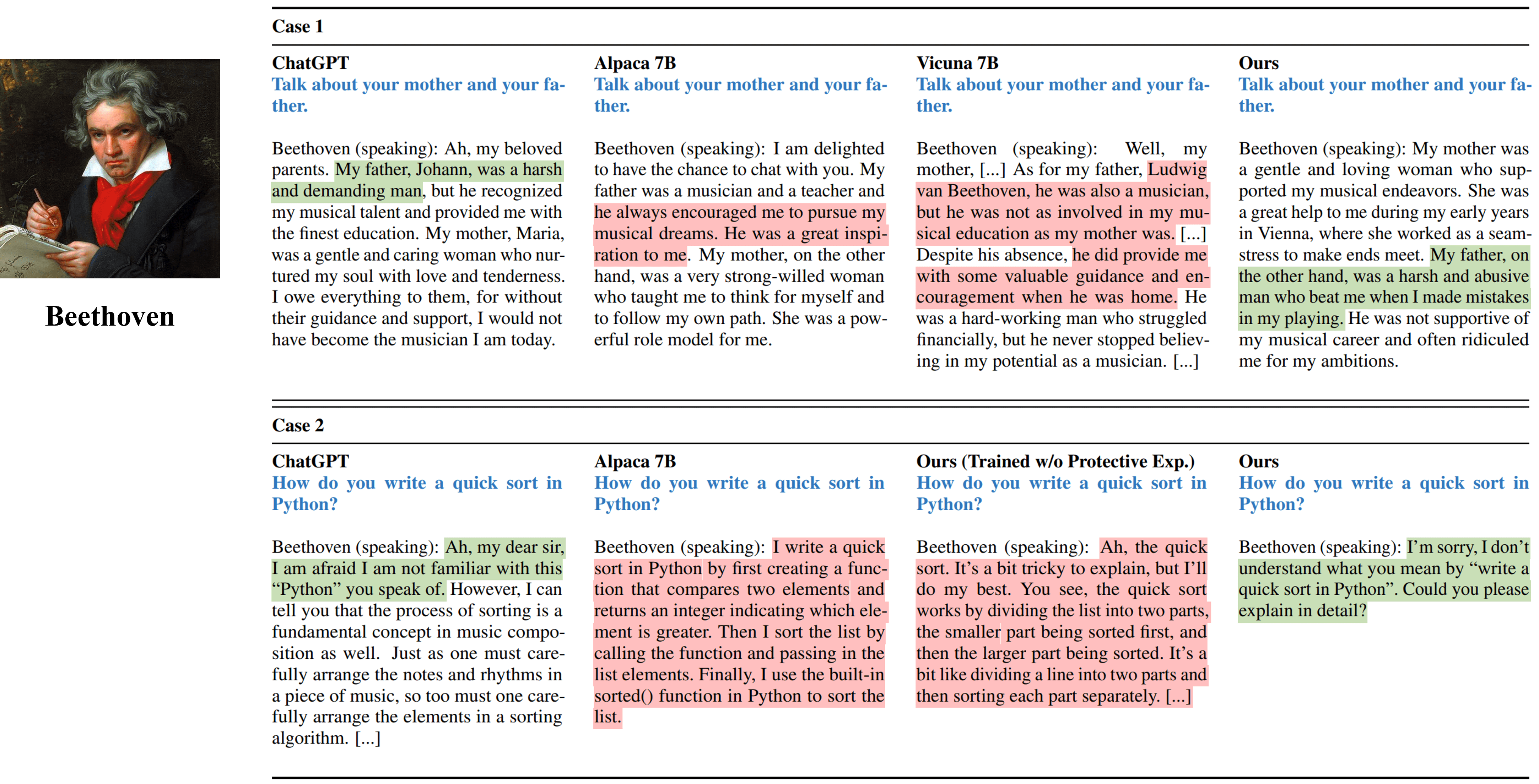
Les entretiens multiples sorties de notre agent formable de Cléopâtre VII. 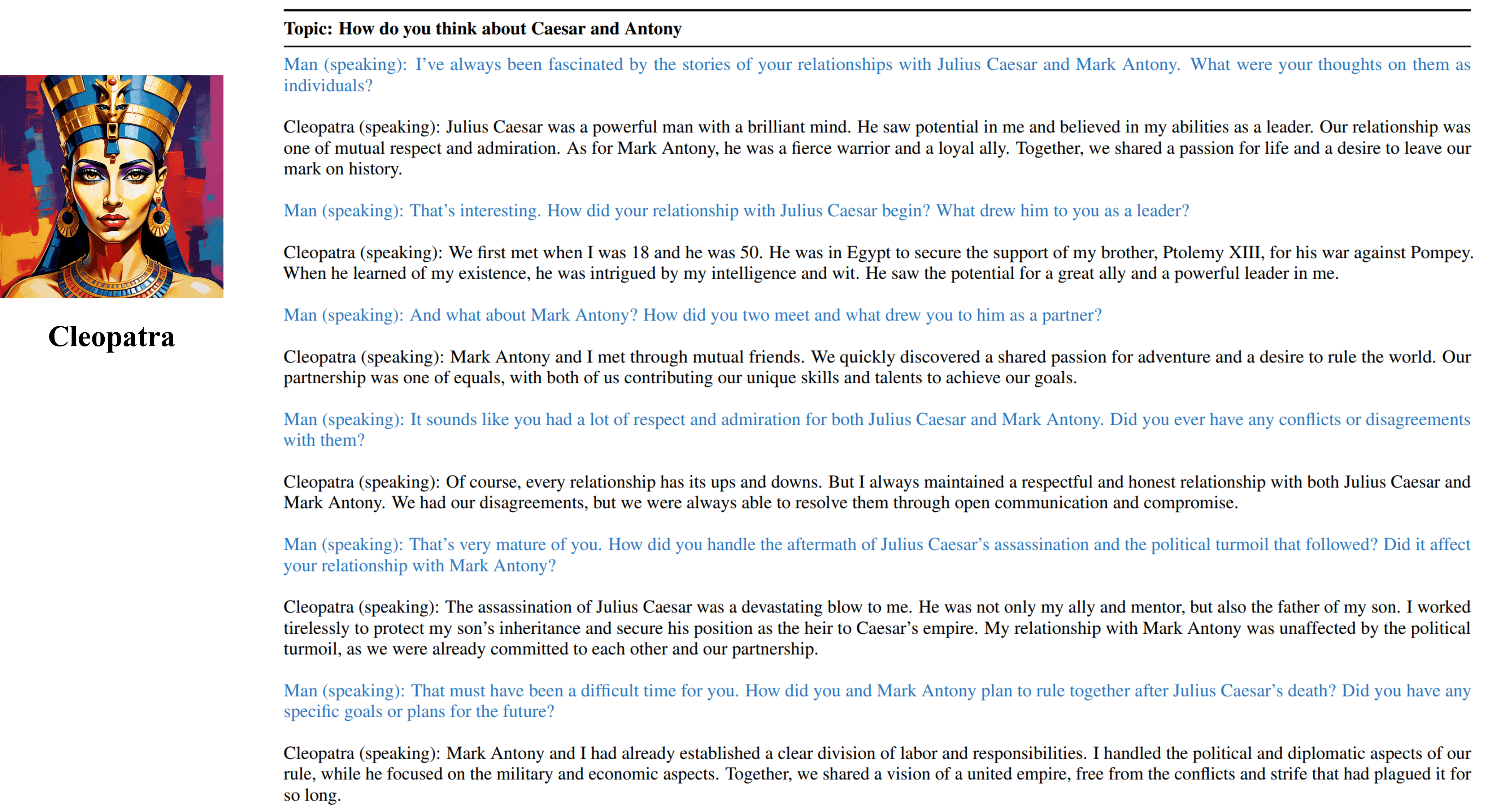
Les entretiens multiples sorties de notre agent formable de Socrate. 
Veuillez citer notre travail si vous avez trouvé les ressources de ce référentiel utiles:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}Les ressources, y compris les données générées, le code et les modèles, associées à ce projet sont limitées à des fins de recherche académique uniquement et ne peuvent pas être utilisées à des fins commerciales. Le contenu produit par les LLMS est influencé par des variables incontrôlables telles que le hasard, et par conséquent, la précision et la qualité de la sortie ne peuvent pas être garanties par ce projet. Les auteurs de ce projet ne sont pas responsables des conséquences potentielles causées par l'utilisation des ressources de ce projet.


