trainable agents
1.0.0
? Модели •? Набор данных •? Персонаж-llm
Это официальный репозиторий нашей бумаги EMNLP 2023. Добро пожаловать! ???
Мы вводим персонаж-LLMS обучаемого агента для ролевой игры, который учится на реальном опыте, характеристиках и эмоциях. По сравнению с побуждаемыми агентами, символ-LLM являются обучаемыми агентами, которые специально обучались для ролевой игры, которые способны действовать как конкретные люди, такие как Бетховена, королева Клеопатра, Юлий Цезарь и т. Д., С детальными знаниями, связанными с характером и представительными персонажами. Никакой дополнительной подсказки или справочного документа не требуется. Чтобы достичь этого, мы предлагаем реконструкцию опыта , процесс создания данных, который может генерировать подробные и разнообразные данные об опыте определенного характера для обучения. Для получения более подробной информации, пожалуйста, обратитесь к газете.
Обзор конструкции потока символов-LLM. 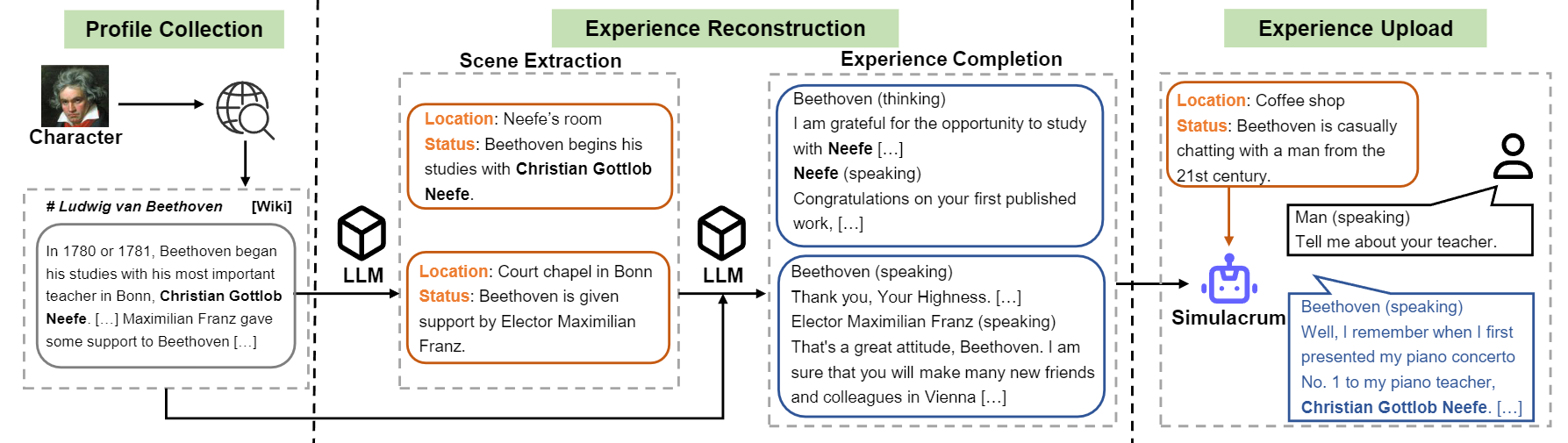
Мы выпускаем модель для девяти символов, упомянутых в статье.
| Модель | Контрольная точка | Характер | Лицензия |
|---|---|---|---|
| Характер-LLM-Клеопатра-7B | ? Характер-LLM-Cleopatra-7B-WDIFF | Клеопатра VII | Лама 1 |
| Символ-llm-voldemort-7b | ? символ-llm-voldemort-7b-wdiff | Лорд Волдеморт | Лама 1 |
| Символ-llm-spartacus-7b | ? символ-llm-spartacus-7b-wdiff | Спартак | Лама 1 |
| Символ-llm-hermione-7b | ? символ-llm-hermione-7b-wdiff | Гермиона Грейнджер | Лама 1 |
| Персонаж-llm-newton-7b | ? персонаж-LLM-Newton-7B-WDIFF | Исаак Ньютон | Лама 1 |
| Характер-LLM-CAESAR-7B | ? Характер-LLM-CAESAR-7B-WDIFF | Юлий Цезарь | Лама 1 |
| Символ-llm-beethoven-7b | ? символ-llm-beethoven-7b-wdiff | Людвиг Ван Бетховен | Лама 1 |
| Персонаж-llm-socrates-7b | ? персонаж-llm-socrates-7b-wdiff | Сократ | Лама 1 |
| Персонаж-llm-martin-7b | ? персонаж-llm-martin-7b-wdiff | Мартин Лютер Кинг | Лама 1 |
Из -за лицензии, используемой Llama 1, мы выпускаем различия в весах, и вам необходимо восстановить веса, выполнив следующую команду.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffИ тогда вы можете использовать модель в качестве чат -бота с помощью Meta Rismer.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) Обучающие наборы данных можно загрузить? Эта ссылка, которая содержит девять символов, испытывают данные, используемые для обучения символов-LLM. Чтобы загрузить набор данных, пожалуйста, запустите следующий код с Python, и вы можете найти загруженные данные в /path/to/local_dir .
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) prompted/ содержит наборы данных, которые могут быть использованы для непосредственной настройки. И generated/ состоит из необработанных данных, которые генерируются GPT-3.5-Turbo, которые могут быть преобразованы в prompted стиль. Вот статистика учебных данных.
| # Сцены | # Слова | # Повороты | |
|---|---|---|---|
| Клеопатра VII | 1,4k | 723K | 14.3 |
| Лорд Волдеморт | 1,4k | 599K | 13.1 |
| Спартак | 1,4k | 646K | 12.3 |
| Гермиона Грейнджер | 1,5 тыс | 628K | 15.5 |
| Исаак Ньютон | 1,6k | 772K | 12.6 |
| Юлий Цезарь | 1,6k | 820K | 12.9 |
| Людвиг Ван Бетховен | 1,6k | 663K | 12.2 |
| Сократ | 1,6k | 896K | 14.1 |
| Мартин Лютер Кинг | 2.2K | 1 038K | 12.0 |
| Ав. | 1,6k | 754K | 13.2 |
1) Конструкция профиля: выберите один символ (например, Bethoven) и получите некоторый профиль для символа, который содержит параграфы, спервые с использованием nn . Вы можете обратиться к формату данных data/seed_data/profiles/wiki_Beethoven.txt
2) Извлечение сцены: добавьте клавиши API в apikeys.py и используйте LLM (GPT-3.5-Turbo) в сгенерированные сцены на основе профиля. Затем вы можете проанализировать сгенерированные результаты в данные о Sense.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlПримечание. Код генерации данных поддерживает восстановление после сбоя. Вы можете перезапустить его несколько раз, чтобы обеспечить создание достаточных образцов.
3) Опыт завершить: приглашение LLM (GPT-3.5-Turbo) для создания взаимодействия различных символов, учитывая сцены. Затем вы можете проанализировать результаты в данные опыта.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) Защитная сцена: приглашение LLM (GPT-3.5-Turbo) для создания взаимодействий для защитных сцен, что помогает уменьшить галлюцинацию персонажа.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) Преобразовать в формат обучения: запустите следующий сценарий, чтобы получить учебные данные для SFT.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json Обучение основано на FastChat с небольшой ошибкой. Возможно, вам потребуется установить несколько сторонних пакетов для запуска этого кода.
Вам необходимо подготовить базовую модель (например, Llama-7B, Llama2-7B или другие модели, которые вам нравятся) и запустить следующий тренировочный скрипт с соответствующими гиперпараметрами для обучения символа-LLM. На тренировку 8 A100 потребуется 30 ~ 45 минут. Как только модель обучена, вы можете загрузить ее с помощью from_pretrained и использовать ее аналогичным примеру выше.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
Вывод также требует FastChat . Вы можете запустить сервер вывода модели, следуя командам:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009Вы можете запустить несколько Model_workers для подключения к контроллеру, чтобы ускорить вывод. А потом запустите интервью с пожизненным поворотом и несколькими обращениями со следующим кодом.
python run_api_interview_single.pypython run_api_interview_turns.py sft Для сгенерированных образцов символов-LLM и других базовых показателей, пожалуйста, проверьте data/gen_results , в которых interview_single интервью с одним поворотом различных моделей, в то время как interview_turns содерживает многократные интервью.
Выходы интервью с одним поворотом из разных методов, имитирующих Бетховена. 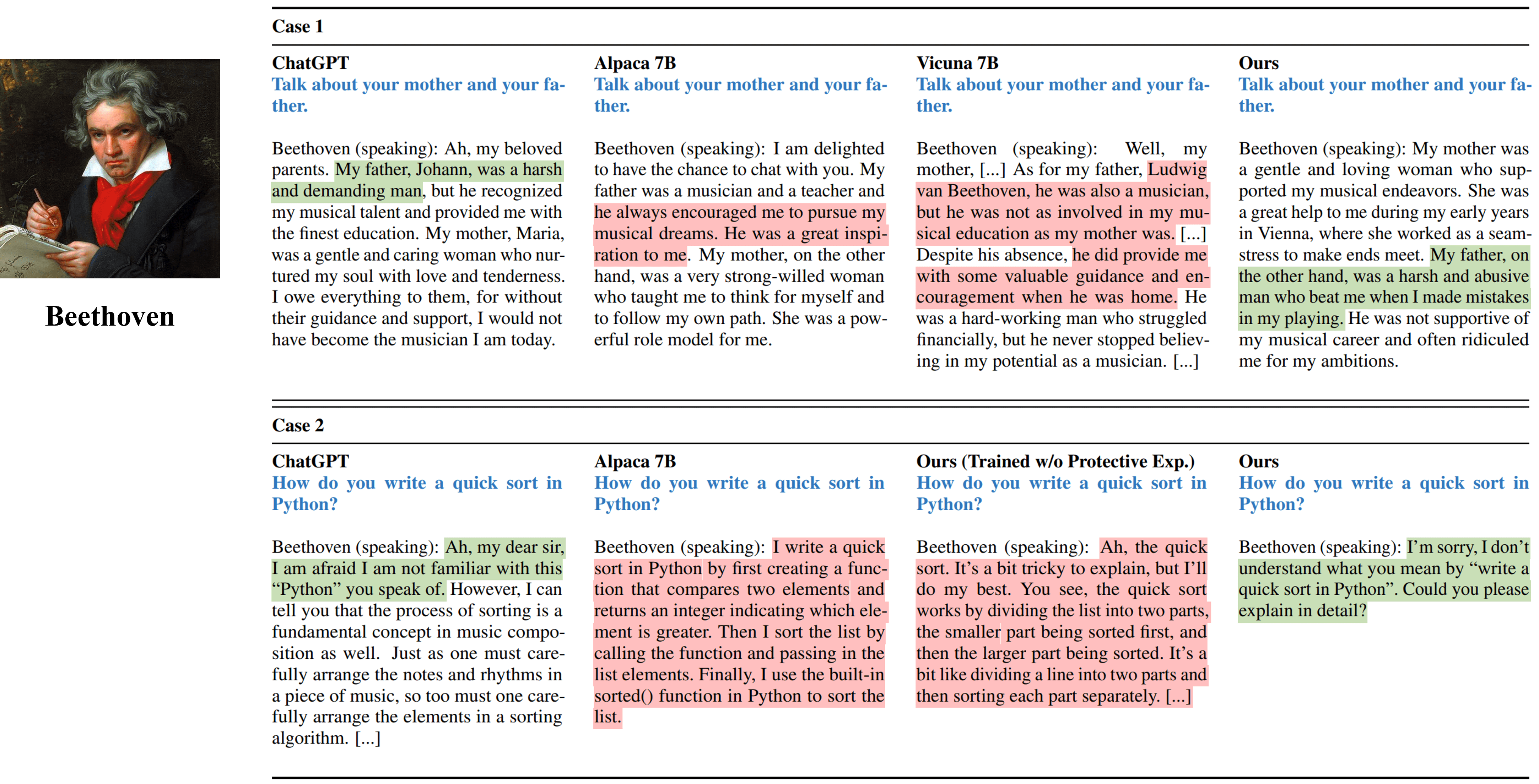
Многообразные результаты интервью от нашего обучаемого агента Клеопатры VII. 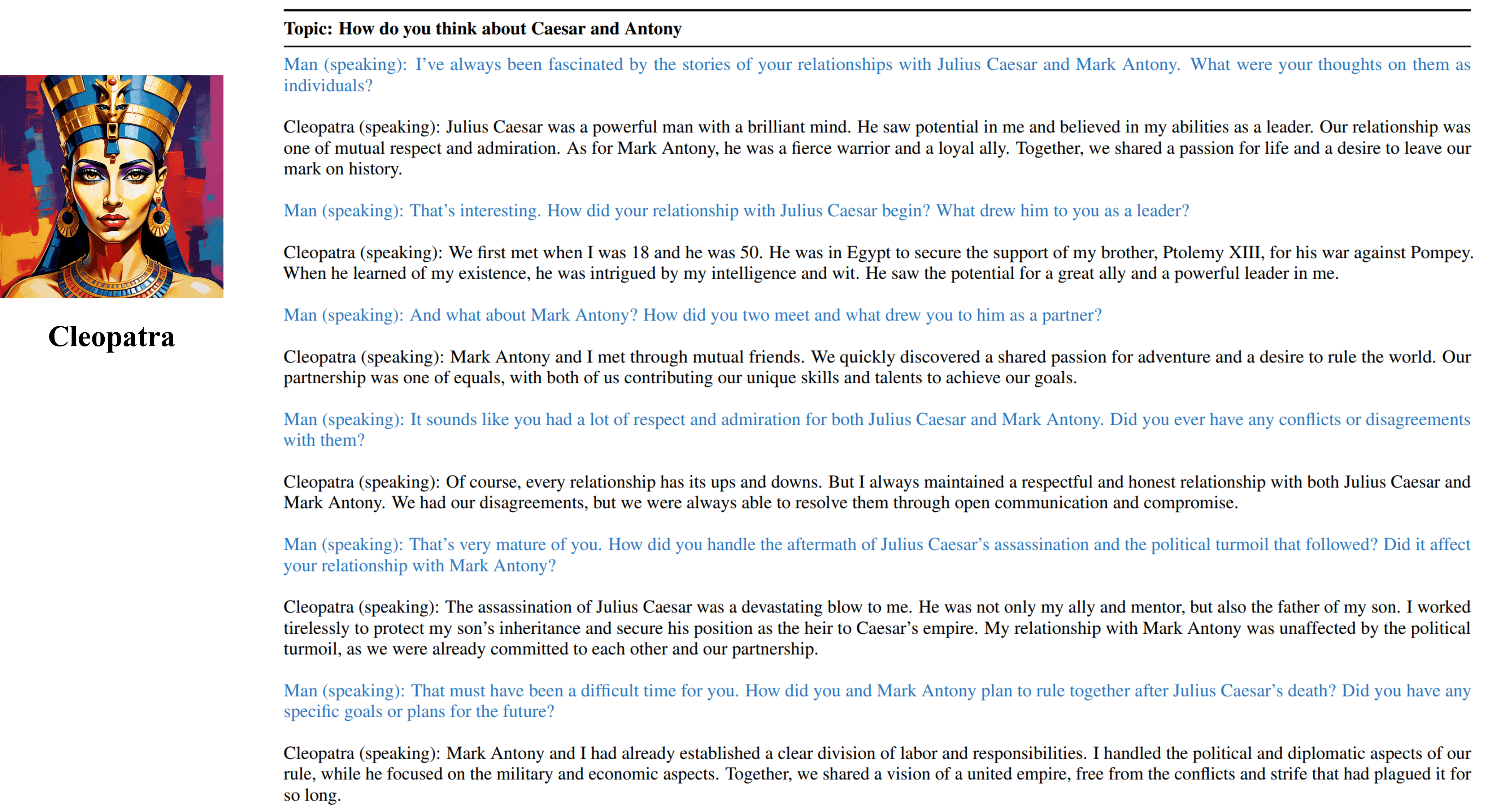
Многообразные результаты интервью от нашего обучаемого агента Сократа. 
Пожалуйста, процитируйте нашу работу, если вы нашли ресурсы в этом репозитории полезными:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}Ресурсы, включая сгенерированные данные, код и модели, связанные с этим проектом, ограничены только для академических исследований и не могут использоваться в коммерческих целях. Содержимое, создаваемое символами-LLM, зависит от неконтролируемых переменных, таких как случайность, и, следовательно, точность и качество вывода не могут быть гарантированы этим проектом. Авторы этого проекта не несут ответственности за какие -либо потенциальные последствия, вызванные использованием ресурсов в этом проекте.


