trainable agents
1.0.0
? Modelle •? Datensatz •? Charakter-llm
Dies ist das offizielle Repository unseres EMNLP 2023 -Papiers. Willkommen! ???
Wir stellen Charakter-L-Lichte ein trainierbarer Agent für Rollenspiele ein, das aus tatsächlichen Erfahrungen, Eigenschaften und Emotionen lernt. Im Vergleich zu den Anlaufgeräten sind Charakter-LLLMs trainierbare Wirkstoffe, die speziell für das Rollenspiel ausgebildet wurden, die als bestimmte Personen wie Beethoven, Königin Cleopatra, Julius Caesar usw. fungieren können, mit detaillierten charakterbezogenen Kenntnissen und repräsentativen Charakterpersönlichkeiten. Es ist kein zusätzliches Eingabeaufforderung oder Referenzdokument erforderlich. Um dies zu erreichen, schlagen wir den Rekonstruktion der Erfahrung vor, einen Datenerzeugungsprozess, der detaillierte und vielfältige Erfahrungsdaten eines bestimmten Charakters für das Training erzeugt. Weitere Informationen finden Sie in der Zeitung.
Überblick über den Konstruktionsfluss von Charakter-LlM. 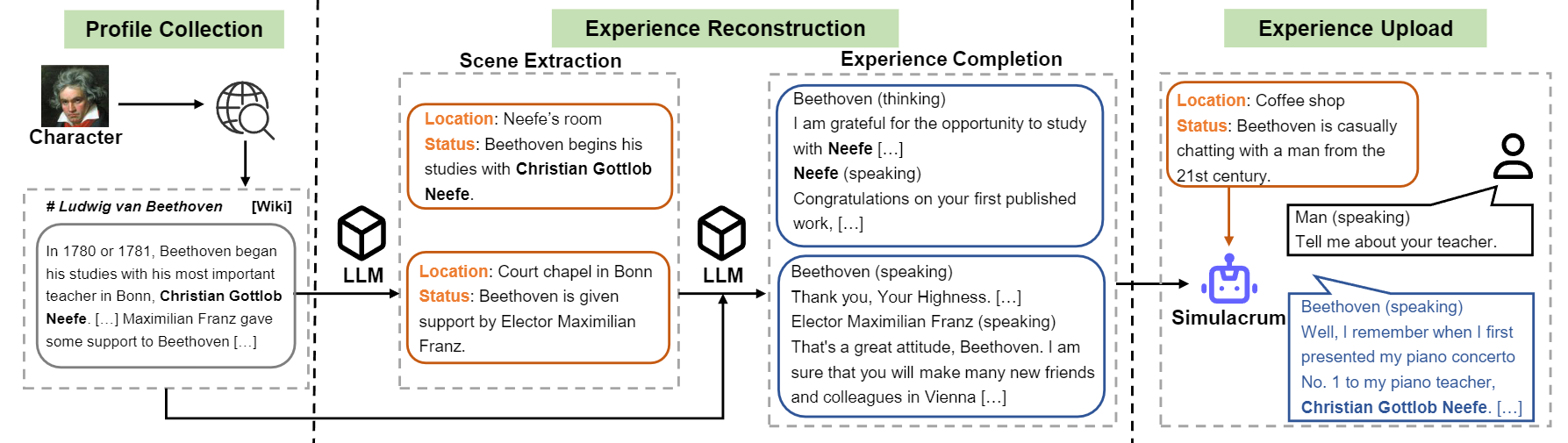
Wir veröffentlichen das Modell für neun in der Zeitung erwähnte Zeichen.
| Modell | Kontrollpunkt | Charakter | Lizenz |
|---|---|---|---|
| Charakter-llm-cleopatra-7b | ? Charakter-llm-cleopatra-7b-wdiff | Cleopatra VII | Lama 1 |
| Charakter-llm-voldemort-7b | ? Charakter-llm-voldemort-7b-wdiff | Lord Voldemort | Lama 1 |
| Charakter-LlM-Spartacus-7b | ? Charakter-llm-Spartacus-7b-wdiff | Spartacus | Lama 1 |
| Charakter-llm-hermion-7b | ? Charakter-llm-hermion-7b-wdiff | Hermine Granger | Lama 1 |
| Charakter-LlM-Newton-7b | ? Charakter-Llm-Newton-7b-Wdiff | Isaac Newton | Lama 1 |
| Charakter-llm-caesar-7b | ? Charakter-llm-caesar-7b-wdiff | Julius Caesar | Lama 1 |
| Charakter-llm-bethoven-7b | ? Charakter-LlM-BEETHOVEN-7B-WDIFF | Ludwig van Beethoven | Lama 1 |
| Charakter-llm-sokrates-7b | ? Charakter-llm-sokrates-7b-wdiff | Sokrates | Lama 1 |
| Charakter-Llm-Martin-7b | ? Charakter-llm-Martin-7b-wdiff | Martin Luther King | Lama 1 |
Aufgrund der von LLAMA 1 verwendeten Lizenz veröffentlichen wir die Gewichtsunterschiede und Sie müssen die Gewichte wiederherstellen, indem Sie den folgenden Befehl ausführen.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffUnd dann können Sie das Modell als Chatbot mit der Meta -Eingabeaufforderung verwenden.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) Trainingsdatensätze können bei heruntergeladen werden? Dieser Link, in dem neun Zeichen erfahrungsdaten enthält, die zum Trainieren von Zeichen-LlMs verwendet werden. Um den Datensatz herunterzuladen, führen Sie bitte den folgenden Code mit Python aus und finden Sie die heruntergeladenen Daten in /path/to/local_dir .
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) Die prompted/ enthält Datensätze, die für die direkte Feinabstimmung verwendet werden können. Und generated/ besteht aus Rohdaten, die von GPT-3,5-Turbo generiert werden und in den prompted Stil umgewandelt werden können. Hier finden Sie die Statistiken der Trainingsdaten.
| # Szenen | # Wörter | # Dreht sich | |
|---|---|---|---|
| Cleopatra VII | 1,4K | 723K | 14.3 |
| Lord Voldemort | 1,4K | 599K | 13.1 |
| Spartacus | 1,4K | 646K | 12.3 |
| Hermine Granger | 1,5K | 628K | 15.5 |
| Isaac Newton | 1,6K | 772K | 12.6 |
| Julius Caesar | 1,6K | 820K | 12.9 |
| Ludwig van Beethoven | 1,6K | 663K | 12.2 |
| Sokrates | 1,6K | 896K | 14.1 |
| Martin Luther King | 2,2k | 1.038K | 12.0 |
| Avg. | 1,6K | 754K | 13.2 |
1) Profilkonstruktion: Wählen Sie ein Zeichen (z. B. Beethoven) und erhalten Sie ein gewisses Profil für das Zeichen, das Absätze enthält, die mit nn gesperert sind. Sie können sich auf das Datenformat von data/seed_data/profiles/wiki_Beethoven.txt beziehen
2) Szenenextraktion: Fügen Sie apikeys.py API-Schlüssel hinzu und verwenden Sie LLM (GPT-3.5-Turbo) zu generierten Szenen basierend auf dem Profil. Anschließend können Sie die generierten Ergebnisse in SENCE -Daten analysieren.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlHINWEIS: Der Datenerzeugungscode unterstützt die Wiederherstellung vom Fehler. Sie können es mehrmals erneut ausführen, um sicherzustellen, dass ausreichende Proben erzeugt werden.
3) Fertigstellung der Erfahrung: Eingabeaufforderung LLM (GPT-3,5-Turbo), um Interaktionen verschiedener Zeichen zu erzeugen, die die Szenen angegeben haben. Anschließend können Sie die Ergebnisse in Erfahrungsdaten analysieren.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) Schutzszene: prompt LLM (GPT-3,5-Turbo), um Wechselwirkungen für Schutzszenen zu erzeugen, die zur Reduzierung der Charakter-Halluzination beitragen.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) Konvertieren in das Trainingsformat: Führen Sie das folgende Skript aus, um die Trainingsdaten für SFT zu erhalten.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json Das Training basiert auf FastChat mit geringfügigem Fehler. Möglicherweise müssen Sie einige Pakete von Drittanbietern installieren, um diesen Code auszuführen.
Sie müssen das Basismodell (z. B. LLAMA-7B, LAMA2-7B oder andere Modelle, die Sie mögen) vorbereiten und das folgende Trainingsskript mit den entsprechenden Hyper-Parametern ausführen, um Charakter-Llm zu trainieren. Es sollte 30 ~ 45 Minuten dauern, um mit 8 A100 GPUs zu trainieren. Sobald das Modell trainiert ist, können Sie es von from_pretrained laden und ähnlich dem obigen Beispiel verwenden.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
Die Inferenz erfordert auch FastChat . Sie können den Modell -Inferenzserver starten, indem Sie folgende Befehle folgen:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009Sie können mehrere Model_worker ausführen, um eine Verbindung zum Controller herzustellen, um die Inferenz zu beschleunigen. Und dann führen Sie mit dem folgenden Code Interviews mit Singen und Multiturn-Interviews aus.
python run_api_interview_single.pypython run_api_interview_turns.py sft Für generierte Beispiele von Charakter-LlM und anderen Baselines überprüfen Sie bitte data/gen_results , in denen interview_single einzelne Turn-Interviews verschiedener Modelle speichert, während interview_turns Multi-Turn-Interviews Ergebnisse speichert.
Einzelgezogene Interviews aus verschiedenen Methoden, die Beethoven simulieren. 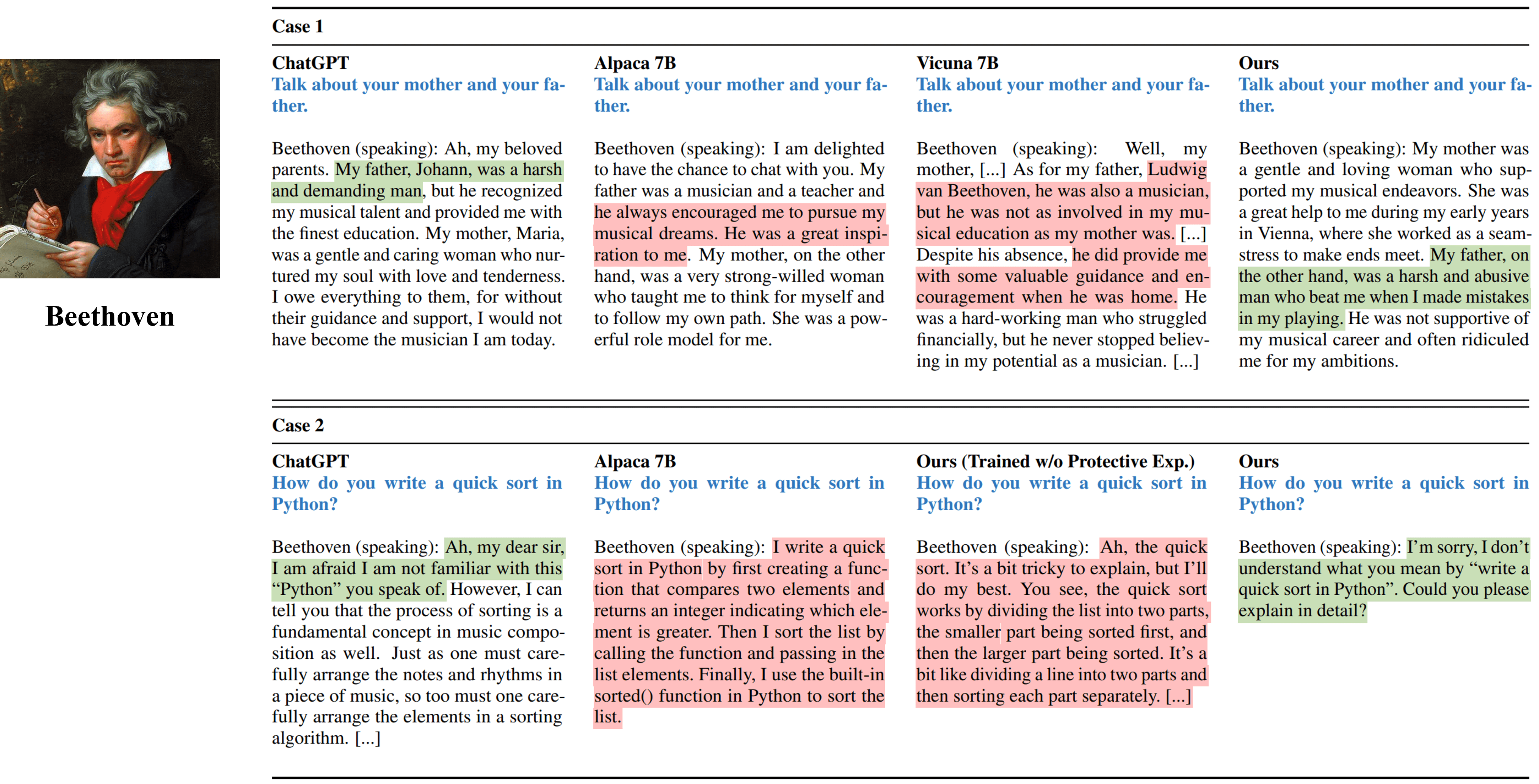
Multi-Turn-Interviewausgaben von unserem trainierbaren Agenten von Cleopatra VII. 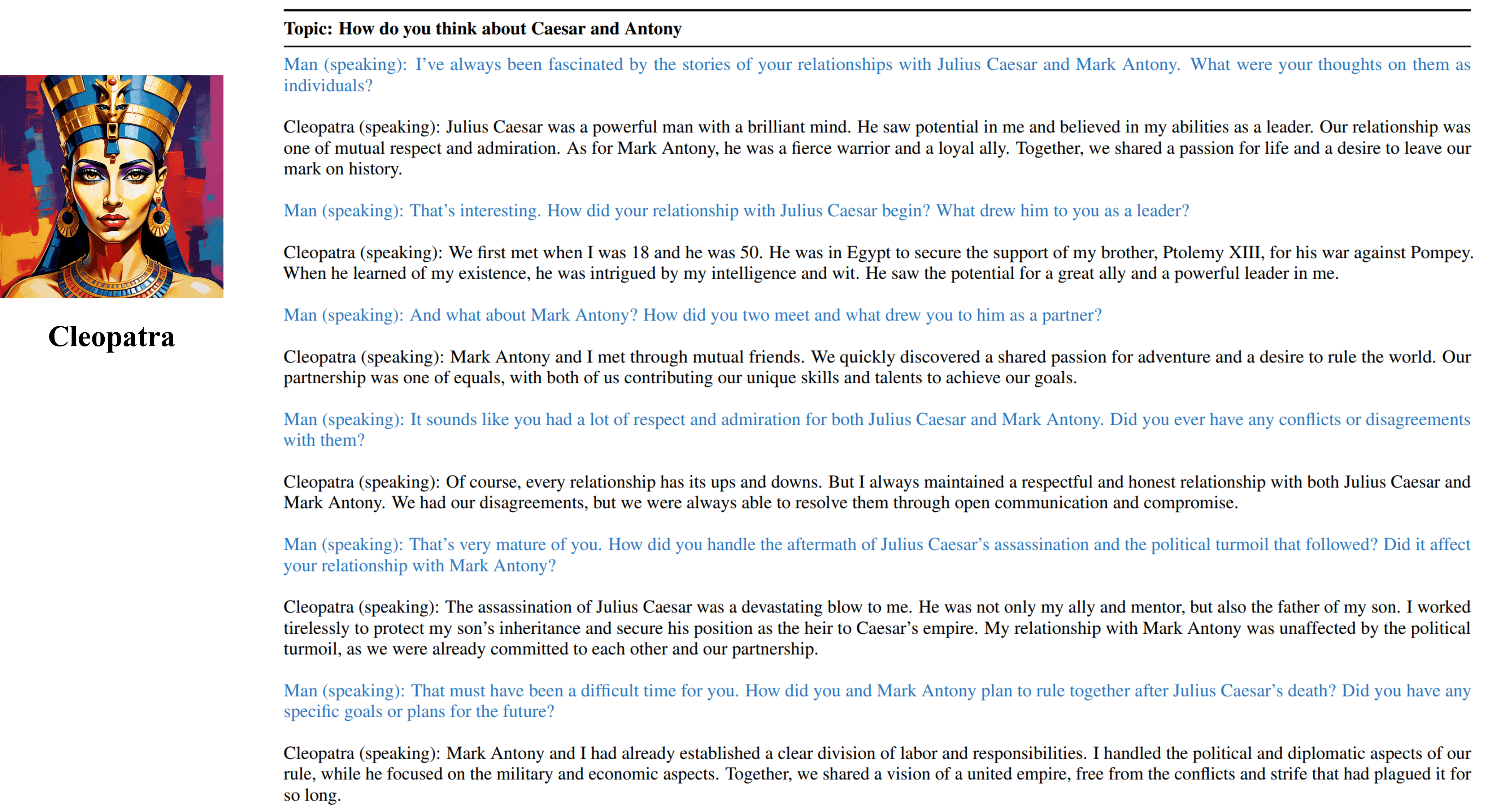
Multi-Turn-Interviewgänge von unserem trainierbaren Agenten von Sokrates. 
Bitte zitieren Sie unsere Arbeit, wenn Sie die Ressourcen in diesem Repository nützlich gefunden haben:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}Die mit diesem Projekt verbundenen Ressourcen, einschließlich generierter Daten, Code und Modelle, sind nur für akademische Forschungszwecke eingeschränkt und können nicht für kommerzielle Zwecke verwendet werden. Der von Charakter-LlMs erzeugte Inhalt wird durch unkontrollierbare Variablen wie Zufälligkeit beeinflusst, und daher kann die Genauigkeit und Qualität der Ausgabe durch dieses Projekt nicht garantiert werden. Die Autoren dieses Projekts sind nicht für potenzielle Konsequenzen verantwortlich, die durch die Verwendung der Ressourcen in diesem Projekt verursacht werden.


