trainable agents
1.0.0
- โมเดล•? ชุดข้อมูล•? ตัวละคร
นี่คือที่เก็บอย่างเป็นทางการของกระดาษ EMNLP 2023 ของเรา ยินดีต้อนรับ! -
เราแนะนำ ตัวละคร-LLM เป็นตัวแทนที่สามารถฝึกอบรมได้สำหรับการสวมบทบาทที่เรียนรู้จากประสบการณ์จริงลักษณะและอารมณ์ เมื่อเปรียบเทียบกับตัวแทนที่ได้รับแจ้งแล้วตัวละคร LLM เป็นตัวแทนที่ฝึกอบรมได้ซึ่งได้รับการฝึกฝนเฉพาะสำหรับการสวมบทบาทซึ่งสามารถทำหน้าที่เป็นคนเฉพาะเช่น Beethoven, Queen Cleopatra, Julius Caesar ฯลฯ ด้วยความรู้ที่เกี่ยวข้องกับตัวละครโดยละเอียด ไม่จำเป็นต้องใช้เอกสารแจ้งเพิ่มเติมหรือเอกสารอ้างอิง เพื่อให้บรรลุเป้าหมายนี้เราเสนอ ประสบการณ์การสร้างใหม่ ซึ่งเป็นกระบวนการสร้างข้อมูลที่สามารถสร้างข้อมูลประสบการณ์ที่มีรายละเอียดและหลากหลายของตัวละครบางตัวสำหรับการฝึกอบรม สำหรับรายละเอียดเพิ่มเติมโปรดดูที่กระดาษ
ภาพรวมของการไหลของการก่อสร้างของตัวละคร-LLM 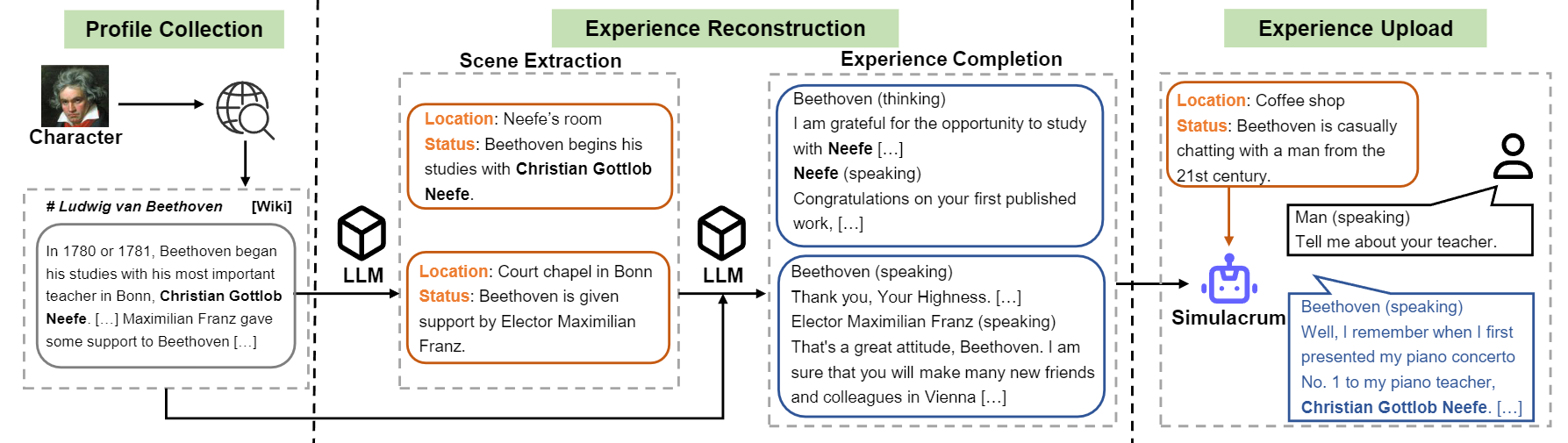
เราปล่อยโมเดลสำหรับอักขระเก้าตัวที่กล่าวถึงในกระดาษ
| แบบอย่าง | ด่าน | อักขระ | ใบอนุญาต |
|---|---|---|---|
| อักขระ -llm-cleopatra-7b | - อักขระ -llm-cleopatra-7b-wdiff | คลีโอพัตรา VII | Llama 1 |
| ตัวละคร-llm-voldemort-7b | - ตัวละคร-llm-voldemort-7b-wdiff | ลอร์ดโวลเดอมอร์ | Llama 1 |
| ตัวละคร-llm-spartacus-7b | - ตัวละคร-llm-spartacus-7b-wdiff | สปาร์กัส | Llama 1 |
| ตัวละคร-llm-hermione-7b | - ตัวละคร-llm-hermione-7b-wdiff | เฮอร์ไมโอนี่เกรนเจอร์ | Llama 1 |
| ตัวละคร-LLM-NEWTON-7B | - ตัวละคร-LLM-NEWTON-7B-WDIFF | Isaac Newton | Llama 1 |
| อักขระ -llm-caesar-7b | - อักขระ -llm-caesar-7b-wdiff | Julius Caesar | Llama 1 |
| ตัวละคร-llm-beethoven-7b | - ตัวละคร-llm-beethoven-7b-wdiff | Ludwig van Beethoven | Llama 1 |
| ตัวละคร-llm-socrates-7b | - ตัวละคร-llm-socrates-7b-wdiff | โสกราตีส | Llama 1 |
| อักขระ -llm-martin-7b | - อักขระ -llm-martin-7b-wdiff | มาร์ตินลูเทอร์คิง | Llama 1 |
เนื่องจากใบอนุญาตที่ใช้โดย Llama 1 เราปล่อยความแตกต่างของน้ำหนักและคุณต้องกู้คืนน้ำหนักโดยเรียกใช้คำสั่งต่อไปนี้
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffจากนั้นคุณสามารถใช้โมเดลเป็น chatbot ด้วยพรอมต์เมตา
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) ชุดข้อมูลการฝึกอบรมสามารถดาวน์โหลดได้ที่? ลิงค์นี้ซึ่งมีข้อมูลประสบการณ์เก้าตัวที่ใช้ในการฝึกอบรมตัวละคร ในการดาวน์โหลดชุดข้อมูลโปรดเรียกใช้รหัสต่อไปนี้ด้วย Python และคุณสามารถค้นหาข้อมูลที่ดาวน์โหลดใน /path/to/local_dir
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) ชุดข้อมูล prompted/ มีชุดข้อมูลที่สามารถใช้สำหรับการปรับแต่งแบบควบคุมได้โดยตรง และ generated/ ประกอบด้วยข้อมูลดิบที่สร้างโดย GPT-3.5-turbo ซึ่งสามารถแปลงเป็นสไตล์ prompted นี่คือสถิติของข้อมูลการฝึกอบรม
| # ฉาก | # คำ | # ผลัดกัน | |
|---|---|---|---|
| คลีโอพัตรา VII | 1.4K | 723K | 14.3 |
| ลอร์ดโวลเดอมอร์ | 1.4K | 599K | 13.1 |
| สปาร์กัส | 1.4K | 646K | 12.3 |
| เฮอร์ไมโอนี่เกรนเจอร์ | 1.5k | 628K | 15.5 |
| Isaac Newton | 1.6K | 772K | 12.6 |
| Julius Caesar | 1.6K | 820K | 12.9 |
| Ludwig van Beethoven | 1.6K | 663K | 12.2 |
| โสกราตีส | 1.6K | 896K | 14.1 |
| มาร์ตินลูเทอร์คิง | 2.2K | 1,038K | 12.0 |
| avg. | 1.6K | 754K | 13.2 |
1) การก่อสร้างโปรไฟล์: เลือกอักขระหนึ่งตัว (เช่นเบโธเฟน) และรับโปรไฟล์สำหรับตัวละครซึ่งมีย่อหน้าที่แยกจากกันโดยใช้ nn คุณสามารถอ้างถึงรูปแบบข้อมูลของ data/seed_data/profiles/wiki_Beethoven.txt
2) การสกัดฉาก: เพิ่มปุ่ม API ไปยัง apikeys.py และใช้ LLM (GPT-3.5-turbo) ไปยังฉากที่สร้างขึ้นตามโปรไฟล์ จากนั้นคุณสามารถแยกวิเคราะห์ผลลัพธ์ที่สร้างขึ้นเป็นข้อมูล sence
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlหมายเหตุ: รหัสการสร้างข้อมูลรองรับการกู้คืนจากความล้มเหลว คุณสามารถเรียกใช้ใหม่ได้หลายครั้งเพื่อให้แน่ใจว่ามีการสร้างตัวอย่างที่เพียงพอ
3) ประสบการณ์ที่เสร็จสมบูรณ์: Prompt LLM (GPT-3.5-turbo) เพื่อสร้างการโต้ตอบของอักขระที่แตกต่างกันตามฉาก จากนั้นคุณสามารถแยกวิเคราะห์ผลลัพธ์เป็นข้อมูลประสบการณ์
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) ฉากป้องกัน: Prompt LLM (GPT-3.5-turbo) เพื่อสร้างปฏิสัมพันธ์สำหรับฉากป้องกันซึ่งช่วยลดอาการหลอนของตัวละคร
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) แปลงเป็นรูปแบบการฝึกอบรม: เรียกใช้สคริปต์ต่อไปนี้เพื่อรับข้อมูลการฝึกอบรมสำหรับ SFT
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json การฝึกอบรมขึ้นอยู่กับ FastChat ที่มีข้อผิดพลาดเล็กน้อย คุณอาจต้องติดตั้งแพ็คเกจส่วนที่สามเพื่อเรียกใช้รหัสนี้
คุณต้องเตรียมโมเดลพื้นฐาน (เช่น LLAMA-7B, LLAMA2-7B หรือรุ่นอื่น ๆ ที่คุณชอบ) และเรียกใช้สคริปต์การฝึกอบรมต่อไปนี้ด้วยพารามิเตอร์ไฮเปอร์ที่สอดคล้องกันเพื่อฝึกฝนตัวละคร ควรใช้เวลา 30 ~ 45 นาทีในการฝึกซ้อมใน 8 A100 GPU เมื่อโมเดลได้รับการฝึกฝนคุณสามารถโหลดได้โดย from_pretrained และใช้มันคล้ายกับตัวอย่างด้านบน
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
การอนุมานยังต้องการ FastChat คุณสามารถเริ่มต้นโมเดลเซิร์ฟเวอร์การอนุมานได้โดยคำสั่งดังต่อไปนี้:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009คุณสามารถเรียกใช้ multiple_workers เพื่อเชื่อมต่อกับคอนโทรลเลอร์เพื่อเพิ่มความเร็วในการอนุมาน จากนั้นเรียกใช้การสัมภาษณ์แบบ Singe-Turn และ Multi-Turn ด้วยรหัสต่อไปนี้
python run_api_interview_single.pypython run_api_interview_turns.py sft สำหรับตัวอย่างที่สร้างขึ้นของตัวละคร-LLM และเส้นเขตแดนอื่น ๆ โปรดตรวจสอบข้อมูล interview_turns data/gen_results ซึ่ง interview_single ร้านค้าสัมภาษณ์แบบเลี้ยวครั้งเดียวในรูปแบบที่แตกต่างกัน
ผลลัพธ์การสัมภาษณ์แบบเลี้ยวครั้งเดียวจากวิธีการต่าง ๆ ที่จำลองเบโธเฟน 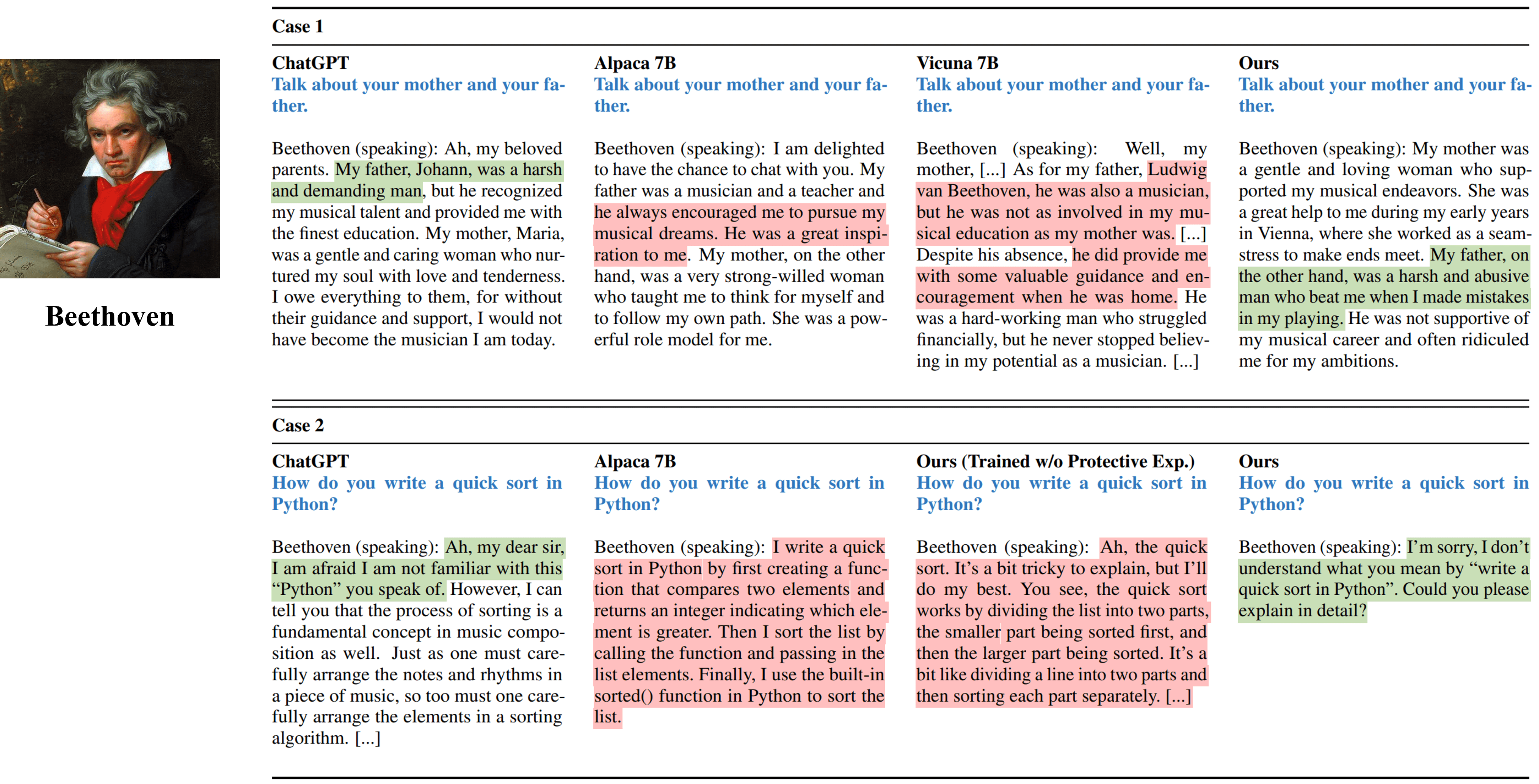
ผลการสัมภาษณ์หลายครั้งจากตัวแทนฝึกอบรมของเราของ Cleopatra VII 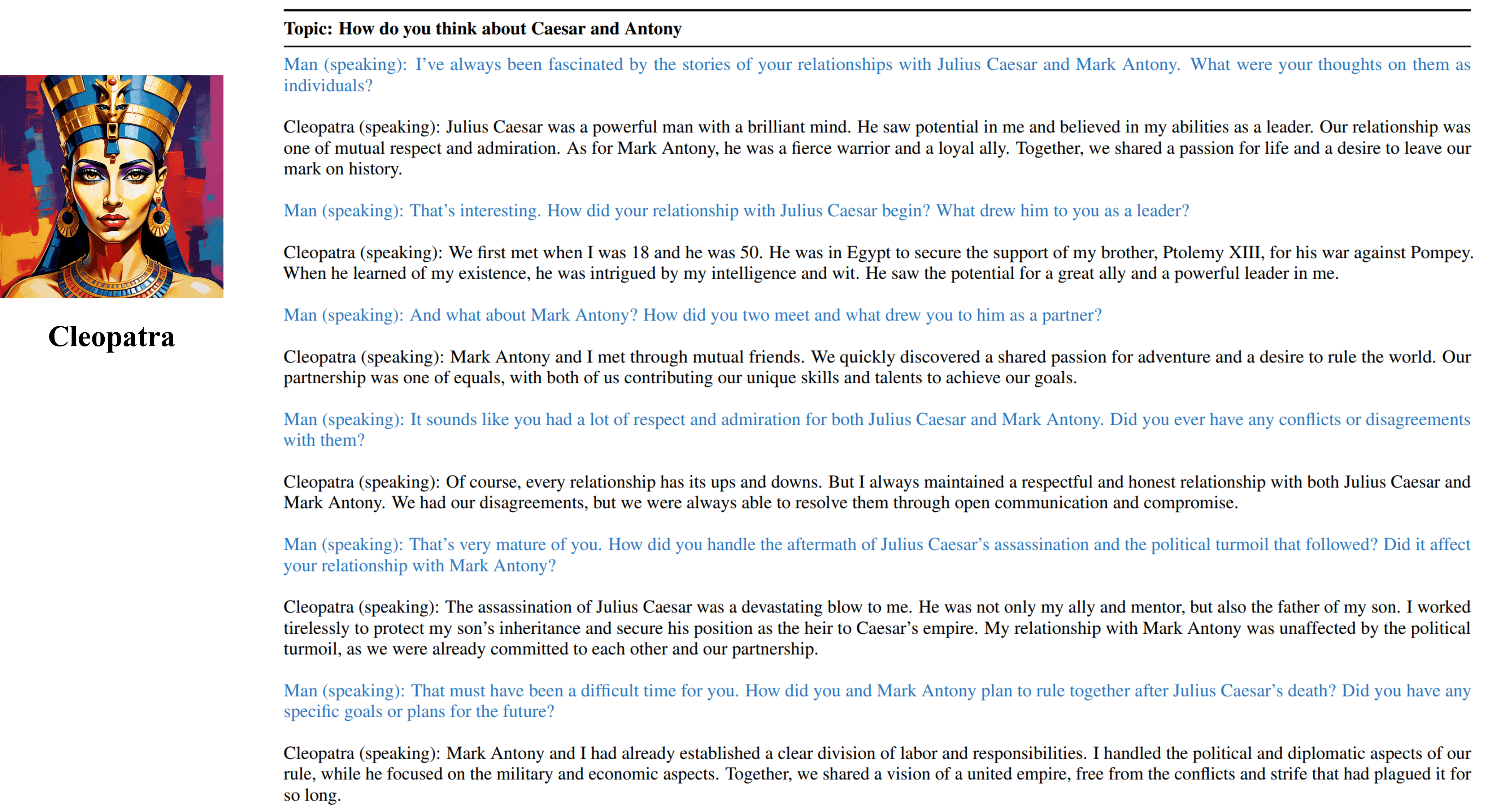
ผลการสัมภาษณ์หลายครั้งจากเอเจนต์ที่ฝึกฝนของเราของโสกราตีส 
โปรดอ้างถึงงานของเราหากคุณพบแหล่งข้อมูลในที่เก็บนี้มีประโยชน์:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}ทรัพยากรรวมถึงข้อมูลที่สร้างขึ้นรหัสและรูปแบบที่เกี่ยวข้องกับโครงการนี้ถูก จำกัด เพื่อวัตถุประสงค์ในการวิจัยเชิงวิชาการเท่านั้นและไม่สามารถใช้เพื่อวัตถุประสงค์ทางการค้า เนื้อหาที่ผลิตโดยตัวละคร-LLM นั้นได้รับอิทธิพลจากตัวแปรที่ไม่สามารถควบคุมได้เช่นการสุ่มและดังนั้นความแม่นยำและคุณภาพของเอาท์พุทจึงไม่สามารถรับประกันได้โดยโครงการนี้ ผู้เขียนโครงการนี้จะไม่รับผิดชอบต่อผลที่อาจเกิดขึ้นจากการใช้ทรัพยากรในโครงการนี้


