trainable agents
1.0.0
? Modelos •? Conjunto de dados •? Personagem-llm
Este é o repositório oficial do nosso artigo EMNLP 2023. Bem-vindo! ???
Introduzimos características-llms um agente treinável para interpretar papéis que aprende com experiências, características e emoções reais. Comparados aos agentes solicitados, os caracteres são agentes treináveis que são treinados especificamente para interpretar papéis, capazes de atuar como pessoas específicas, como Beethoven, Queen Cleopatra, Júlio César, etc., com conhecimento detalhado relacionado a caracteres e personalidades representativas de personagens. Nenhum documento de prompt ou referência adicional é necessário. Para conseguir isso, propomos a reconstrução da experiência , um processo de geração de dados que pode gerar dados detalhados e diversos de experiência de determinado caráter para o treinamento. Para mais detalhes, consulte o artigo.
Visão geral do fluxo de construção do caractere-llm. 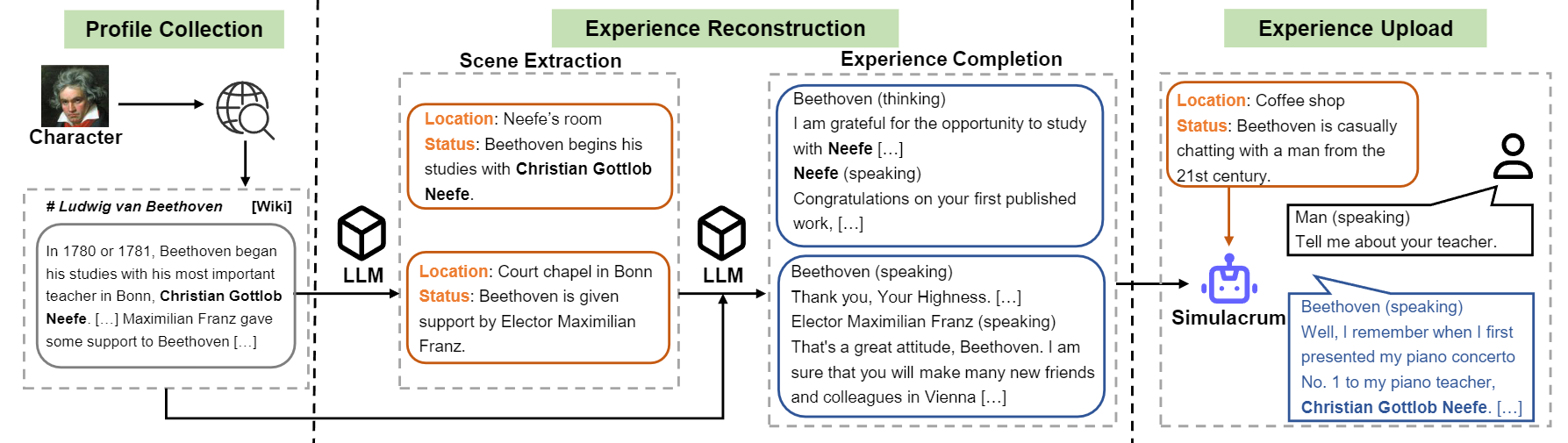
Lançamos o modelo para nove caracteres mencionados no artigo.
| Modelo | Ponto de verificação | Personagem | Licença |
|---|---|---|---|
| Caractere-llm-Cleopatra-7b | ? CARACTERION-LLM-CLEOPATRA-7B-WDIFF | Cleopatra VII | LLAMA 1 |
| Caracter-llm-Voldemort-7b | ? CARACTERION-LLM-VOLDEMORT-7B-WDIFF | Senhor Voldemort | LLAMA 1 |
| Caractere-llm-spartacus-7b | ? Personagem-llm-spartacus-7b-wdiff | Spartacus | LLAMA 1 |
| CARACTERION-LLM-HERMIONE-7B | ? CARACTERION-LLM-HERMIONE-7B-WDIFF | Hermione Granger | LLAMA 1 |
| Caracter-llm-Newton-7b | ? Caracter-llm-Newton-7b-wdiff | Isaac Newton | LLAMA 1 |
| Caractere-llm-caesar-7b | ? Caractere-llm-Caesar-7b-Wdiff | Julius Caesar | LLAMA 1 |
| Caractere-llm-beethoven-7b | ? Caractere-llm-beethoven-7b-wdiff | Ludwig Van Beethoven | LLAMA 1 |
| CARACTERION-LLM-Socrates-7b | ? CARACTERION-LLM-SOCRATES-7B-WDIFF | Sócrates | LLAMA 1 |
| Caractere-llm-martin-7b | ? CARACTERION-LLM-MARTIN-7B-WDIFF | Martin Luther King | LLAMA 1 |
Devido à licença usada pelo LLAMA 1, liberamos as diferenças de peso e você precisa recuperar os pesos executando o seguinte comando.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiffE então você pode usar o modelo como um chatbot com o meta prompt.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) Os conjuntos de dados de treinamento podem ser baixados? Este link, que contém nove caracteres, experimenta dados usados para treinar-llms de caracteres. Para baixar o conjunto de dados, execute o código a seguir com o Python e você pode encontrar os dados baixados em /path/to/local_dir .
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) O prompted/ contém conjuntos de dados que podem ser usados diretamente para ajustar fino supervisionado. E generated/ consiste em dados brutos que gerados pelo GPT-3.5-turbo, que podem ser convertidos em estilo prompted . Aqui estão as estatísticas dos dados de treinamento.
| # Cenas | # Palavras | # Gira | |
|---|---|---|---|
| Cleopatra VII | 1.4k | 723K | 14.3 |
| Senhor Voldemort | 1.4k | 599K | 13.1 |
| Spartacus | 1.4k | 646k | 12.3 |
| Hermione Granger | 1.5k | 628K | 15.5 |
| Isaac Newton | 1.6k | 772K | 12.6 |
| Julius Caesar | 1.6k | 820k | 12.9 |
| Ludwig Van Beethoven | 1.6k | 663k | 12.2 |
| Sócrates | 1.6k | 896k | 14.1 |
| Martin Luther King | 2.2k | 1.038k | 12.0 |
| Avg. | 1.6k | 754K | 13.2 |
1) Construção do perfil: Escolha um caractere (por exemplo, Beethoven) e obtenha algum perfil para o caractere, que contém parágrafos espalhados usando nn . Você pode se referir ao formato de dados de data/seed_data/profiles/wiki_Beethoven.txt
2) Extração de cena: Adicione as teclas API ao apikeys.py e use LLM (GPT-3.5-Turbo) para gerar cenas com base no perfil. Em seguida, você pode analisar os resultados gerados em dados do Sence.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonlNota: O código de geração de dados suporta a recuperação da falha. Você pode executá-lo várias vezes para garantir que amostras suficientes sejam geradas.
3) Conclusão da experiência: Prompt LLM (GPT-3.5-Turbo) para gerar interações de caracteres diferentes, dadas as cenas. Então você pode analisar os resultados em dados de experiência.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) Cena de proteção: Prompt LLM (GPT-3.5-Turbo) a gerar interações para cenas de proteção, o que ajuda a reduzir a alucinação de caráter.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) Converta em formato de treinamento: Execute o seguinte script para obter os dados de treinamento para a SFT.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json O treinamento é baseado no FastChat com um pequeno erro corrigido. Pode ser necessário instalar alguns pacotes de terceiros para executar este código.
Você precisa preparar o modelo básico (por exemplo, LLAMA-7B, LLAMA2-7B ou outros modelos que você gosta) e executar o seguinte script de treinamento com os hiper-parâmetros correspondentes para treinar características de características. Deve levar 30 a 45 minutos para treinar em 8 GPUs A100. Depois que o modelo é treinado, você pode carregá -lo por from_pretrained e usá -lo semelhante ao exemplo acima.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
A inferência também requer FastChat . Você pode iniciar o servidor de inferência do modelo seguindo os comandos:
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009Você pode executar vários model_workers para se conectar ao controlador para acelerar a inferência. E então, execute entrevistas com Singe-Turn e multi-turn com o código a seguir.
python run_api_interview_single.pypython run_api_interview_turns.py sft Para amostras geradas de caracteres e outras linhas de base, verifique data/gen_results , nos quais interview_single armazena entrevistas de uma volta única de diferentes modelos, enquanto interview_turns armazena os resultados das entrevistas com várias turnos.
Os resultados da entrevista única de diferentes métodos simulando Beethoven. 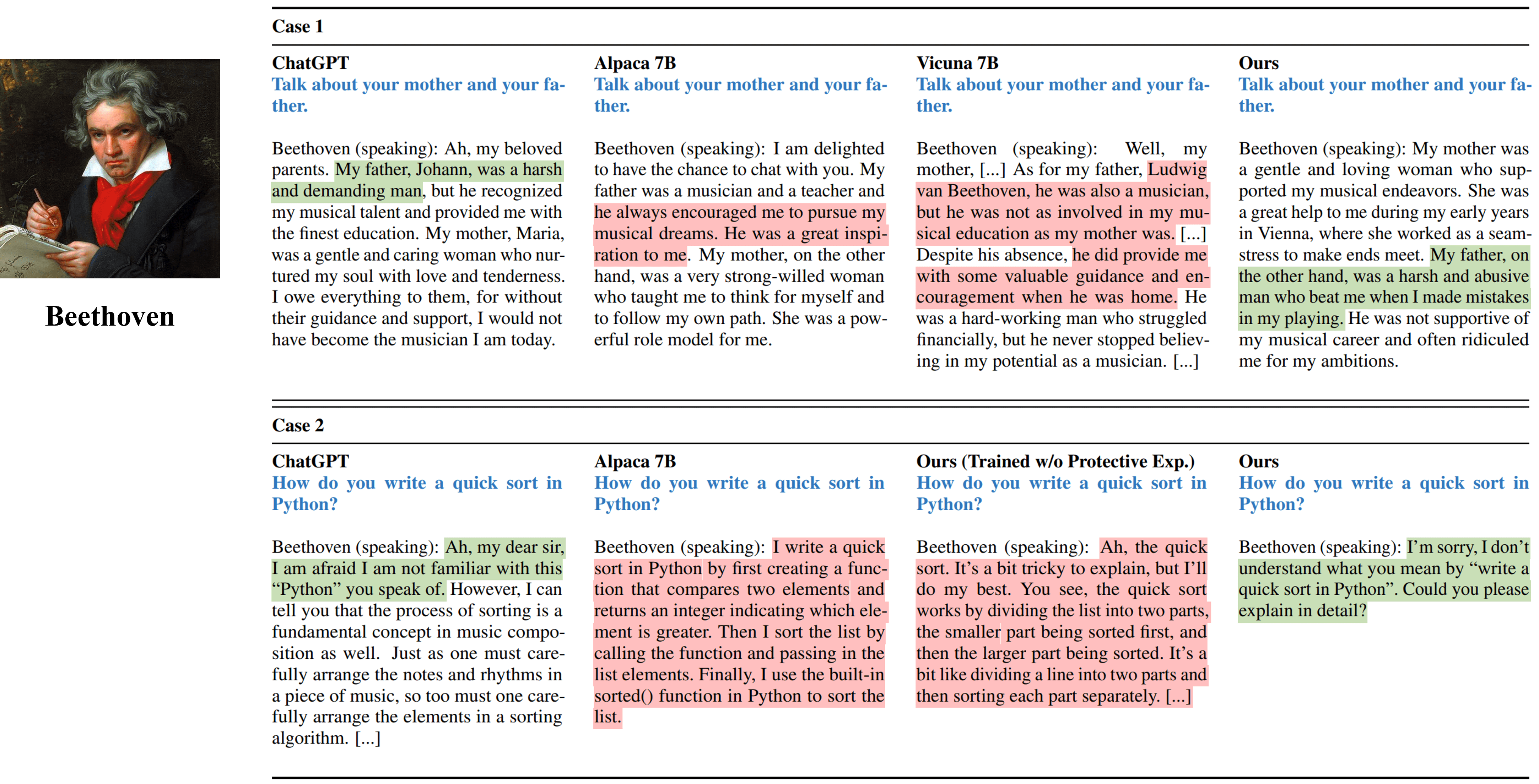
Os resultados da entrevista de várias turnos do nosso agente treinável de Cleópatra VII. 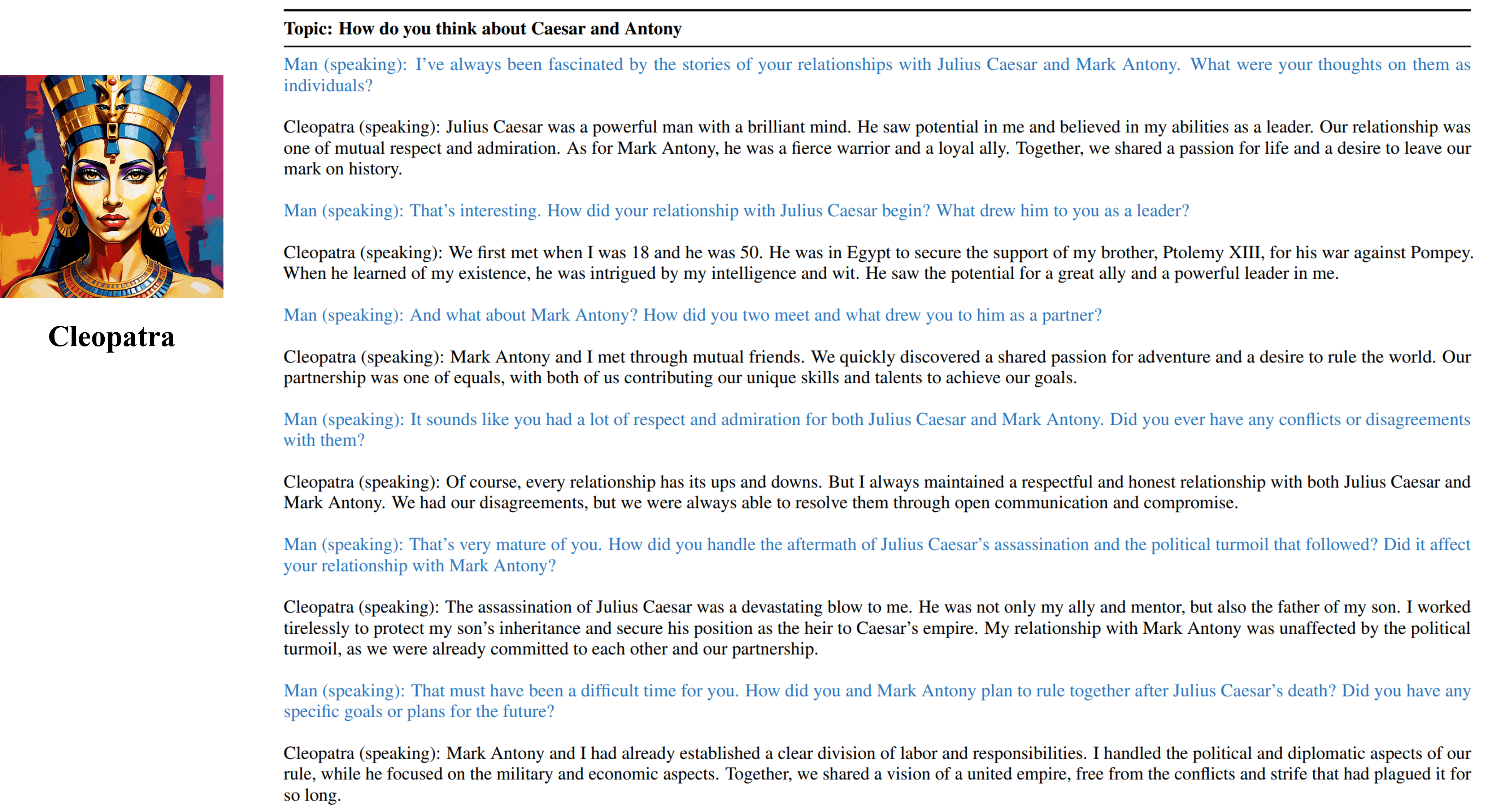
Os resultados da entrevista de várias turnos do nosso agente treinável de Sócrates. 
Cite nosso trabalho se você achou os recursos neste repositório útil:
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}Os recursos, incluindo dados, código e modelos gerados, associados a este projeto, são restritos apenas para fins de pesquisa acadêmica e não podem ser usados para fins comerciais. Os conteúdos produzidos pelo caractere-llms são influenciados por variáveis incontroláveis, como a aleatoriedade e, portanto, a precisão e a qualidade da saída não podem ser garantidas por este projeto. Os autores deste projeto não são responsáveis por possíveis consequências causadas pelo uso dos recursos neste projeto.


