trainable agents
1.0.0
? 모델 •? 데이터 세트 •? 캐릭터 -lm
이것은 EMNLP 2023 용지의 공식 저장소입니다. 환영! ?
우리는 실제 경험, 특성 및 감정에서 배우는 역할 연기를위한 훈련 가능한 에이전트를 캐릭터 LLM을 소개합니다. 프롬프트 에이전트와 비교할 때, 캐릭터 -LLM은 롤 플레잉을 위해 특별히 훈련 된 훈련 가능한 에이전트이며, 이는 베토벤, 클레오 파트라 여왕, 줄리어스 시저 (Julius Caesar 등)와 같은 특정 사람들로서 세부적인 캐릭터 관련 지식 및 대표적인 성격 성격을 갖는 역할을 할 수 있습니다. 추가 프롬프트 또는 참조 문서가 필요하지 않습니다. 이를 달성하기 위해 우리는 교육을위한 특정 특성의 상세하고 다양한 경험 데이터를 생성 할 수있는 데이터 생성 프로세스 인 Experience Reconstruction을 제안합니다. 자세한 내용은 종이를 참조하십시오.
문자 LLM의 구성 흐름에 대한 개요. 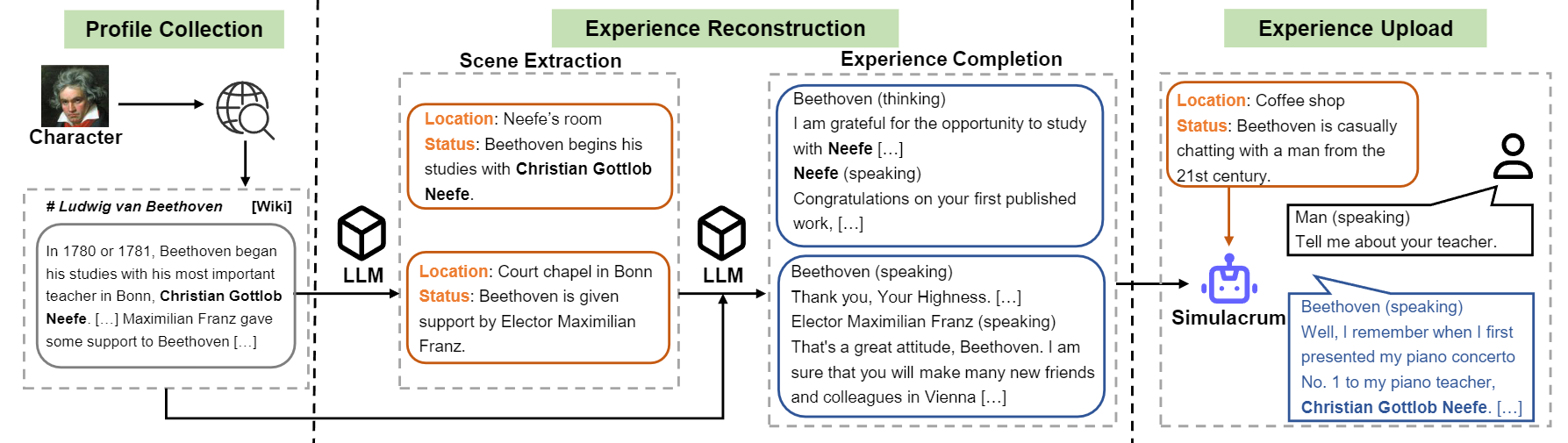
논문에 언급 된 9 자에 대한 모델을 발표합니다.
| 모델 | 검문소 | 성격 | 특허 |
|---|---|---|---|
| 문자 -llm-cleopatra-7b | ? 문자 -llm-cleopatra-7b-wdiff | 클레오 파트라 VII | 라마 1 |
| 문자 -llm-voldemort-7b | ? 문자 -llm-voldemort-7b-wdiff | Voldemort 경 | 라마 1 |
| 문자 -llm-spartacus-7b | ? 문자 -llm-spartacus-7b-wdiff | 스파르타쿠스 | 라마 1 |
| 문자 -llm-Hermione-7b | ? 문자 -llm-hermione-7b-wdiff | 헤르미온느 그레인저 | 라마 1 |
| 문자 -llm-newton-7b | ? 문자 -llm-newton-7b-wdiff | 이삭 뉴턴 | 라마 1 |
| 문자 -llm-caesar-7b | ? 문자 -llm-caesar-7b-wdiff | 줄리어스 시저 | 라마 1 |
| 문자 -LM-Beethoven-7b | ? 캐릭터 -lm-beethoven-7b-wdiff | 루드비히 반 베토벤 | 라마 1 |
| 문자 -llm-socrates-7b | ? 문자 -llm-socrates-7b-wdiff | 소크라테스 | 라마 1 |
| 문자 -llm-martin-7b | ? 문자 -llm-martin-7b-wdiff | 마틴 루터 킹 | 라마 1 |
Llama 1에서 사용한 라이센스로 인해 중량 차이를 방출하고 다음 명령을 실행하여 가중치를 복구해야합니다.
cd FastChat
python3 -m fastchat.model.apply_delta
--base-model-path /path/to/hf-model/llama-7b
--target-model-path /path/to/hf-model/character-llm-beethoven-7b
--delta-path fnlp/character-llm-beethoven-7b-wdiff그런 다음 모델을 메타 프롬프트와 함께 챗봇으로 사용할 수 있습니다.
from transformers import AutoTokenizer , AutoModelForCausalLM
tokenizer = AutoTokenizer . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" )
model = AutoModelForCausalLM . from_pretrained ( "/path/to/hf-model/character-llm-beethoven-7b" ). cuda ()
meta_prompt = """I want you to act like {character}. I want you to respond and answer like {character}, using the tone, manner and vocabulary {character} would use. You must know all of the knowledge of {character}.
The status of you is as follows:
Location: {loc_time}
Status: {status}
The interactions are as follows:"""
name = "Beethoven"
loc_time = "Coffee Shop - Afternoon"
status = f' { name } is casually chatting with a man from the 21st century.'
prompt = meta_prompt . format ( character = name , loc_time = loc_time , status = status ) + ' n n '
inputs = tokenizer ([ prompt ], return_tensors = "pt" )
outputs = model . generate ( ** inputs , do_sample = True , temperature = 0.5 , top_p = 0.95 , max_new_tokens = 50 )
response = tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True )
print ( response ) 교육 데이터 세트를 다운로드 할 수 있습니까? 9 개의 문자가 포함 된이 링크는 문자 LLM을 훈련시키는 데 사용되는 데이터를 경험합니다. 데이터 세트를 다운로드하려면 Python으로 다음 코드를 실행하면 /path/to/local_dir 에서 다운로드 된 데이터를 찾을 수 있습니다.
from huggingface_hub import snapshot_download
snapshot_download (
local_dir_use_symlinks = True ,
repo_type = "dataset" ,
repo_id = "fnlp/character-llm-data" ,
local_dir = "/path/to/local_dir" ) prompted/ 포함 된 데이터 세트는 직접 감독 된 미세 조정에 사용할 수있는 데이터 세트를 포함합니다. generated/ GPT-3.5-Turbo에 의해 생성 된 원시 데이터로 구성되며, 이는 prompted 스타일로 변환 할 수 있습니다. 교육 데이터의 통계는 다음과 같습니다.
| # 장면 | # 단어 | # 회전 | |
|---|---|---|---|
| 클레오 파트라 VII | 1.4K | 723K | 14.3 |
| Voldemort 경 | 1.4K | 599K | 13.1 |
| 스파르타쿠스 | 1.4K | 646K | 12.3 |
| 헤르미온느 그레인저 | 1.5K | 628K | 15.5 |
| 이삭 뉴턴 | 1.6k | 772k | 12.6 |
| 줄리어스 시저 | 1.6k | 820K | 12.9 |
| 루드비히 반 베토벤 | 1.6k | 663K | 12.2 |
| 소크라테스 | 1.6k | 896K | 14.1 |
| 마틴 루터 킹 | 2.2k | 1,038K | 12.0 |
| avg. | 1.6k | 754K | 13.2 |
1) 프로파일 구성 : 하나의 캐릭터 (예 : 베토벤)를 선택하고 문자에 대한 프로필을 얻습니다. 여기에는 nn 사용하여 스퍼리 된 단락이 포함되어 있습니다. data/seed_data/profiles/wiki_Beethoven.txt 의 데이터 형식을 참조 할 수 있습니다
2) 장면 추출 : apikeys.py 에 API 키를 추가하고 프로파일을 기반으로 생성 된 장면에 LLM (GPT-3.5-Turbo)을 사용하십시오. 그런 다음 생성 된 결과를 Sence 데이터로 구문 분석 할 수 있습니다.
python run_api_gen_data.py --prompt_name gen_scene --character Beethoven
python parser/parse_data_scene.py result/2023-10-08/gen_scene/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl참고 : 데이터 생성 코드는 실패로부터의 복구를 지원합니다. 충분한 샘플이 생성되도록 여러 번 다시 실행할 수 있습니다.
3) 경험 완료 : LLM (GPT-3.5-Turbo)을 프롬프트하여 장면이 주어지면 다른 문자의 상호 작용을 생성합니다. 그런 다음 결과를 경험 데이터로 구문 분석 할 수 있습니다.
python run_api_gen_data.py --prompt_name gen_dialogue --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_dialogue.py result/2023-10-08/gen_dialogue/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl
4) 보호 장면 : LLM (GPT-3.5-Turbo)은 보호 장면에 대한 상호 작용을 생성하여 문자 환각을 줄이는 데 도움이됩니다.
python run_api_gen_data.py --prompt_name gen_hallucination --character Beethoven --data_path processed/2023-10-08/
python parser/parse_data_hallucination.py result/2023-10-08/gen_hallucination/gpt-3.5-turbo-temp-0.2-char-Beethoven.jsonl5) 교육 형식으로 변환 : SFT에 대한 교육 데이터를 얻으려면 다음 스크립트를 실행하십시오.
python parser/convert_prompt_data.py processed/2023-10-08/generated_agent_dialogue_Hermione.json 교육은 약간의 버그가 고정 된 FastChat 기반으로합니다. 이 코드를 실행하려면 세 번째 파트 패키지를 설치해야 할 수도 있습니다.
기본 모델 (예 : LLAMA-7B, LLAMA2-7B 또는 원하는 다른 모델)을 준비하고 해당 하이퍼 파라미터로 다음 훈련 스크립트를 실행하여 문자 LLM을 훈련시켜야합니다. 8 A100 GPU로 훈련하는 데 30 ~ 45 분이 걸립니다. 모델이 훈련되면 from_pretrained 로로드하여 위의 예와 유사하게 사용할 수 있습니다.
cd FastChat
export CHARACTER=Beethoven
torchrun --nproc_per_node=8 --master_port=20031 fastchat/train/train_mem.py
--model_name_or_path /path/hf_model/llama-7b
--data_path /path/to/prompted_agent_dialogue_ $CHARACTER .json
--already_preprocess True
--bf16 True
--output_dir /path/to/ckpt/ ${CHARACTER} _7b
--num_train_epochs 10
--per_device_train_batch_size 2
--per_device_eval_batch_size 16
--gradient_accumulation_steps 4
--evaluation_strategy epoch
--save_strategy epoch
--save_total_limit 10
--learning_rate 2e-5
--weight_decay 0.1
--warmup_ratio 0.04
--lr_scheduler_type cosine
--logging_steps 1
--fsdp ' full_shard auto_wrap '
--fsdp_transformer_layer_cls_to_wrap LlamaDecoderLayer
--tf32 True
--model_max_length 2048
--gradient_checkpointing True
추론에는 FastChat 도 필요합니다. 다음 명령을 따라 모델 추론 서버를 시작할 수 있습니다.
cd FastChat
# start the controller
export IP= $( hostname -i )
python3 -m fastchat.serve.controller --host $IP &
# start the Openai Format API server
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 28001 --controller-address http:// $IP :21001
# start the model worker
export MODEL_PATH=/path/to/ckpt/ ${CHARACTER} _7b/
export MODEL_NAME= ${CHARACTER} _7b
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.model_worker --model-path $MODEL_PATH --model-names $MODEL_NAME --controller-address http:// $IP :21001 --host $IP --port 21009 --worker-address http:// $IP :21009여러 model_workers를 실행하여 컨트롤러에 연결하여 추론 속도를 높일 수 있습니다. 그런 다음 다음 코드와 함께 노래와 다중 회전 인터뷰를 실행하십시오.
python run_api_interview_single.pypython run_api_interview_turns.py sft 문자 -LLM 및 기타 기준선의 생성 된 샘플은 data/gen_results 확인하십시오. interview_single 은 다양한 모델의 단일 회전 인터뷰를 저장하는 반면, interview_turns 다중 회전 인터뷰 결과를 저장합니다.
베토벤을 시뮬레이션하는 다양한 방법의 단일 회전 인터뷰 출력. 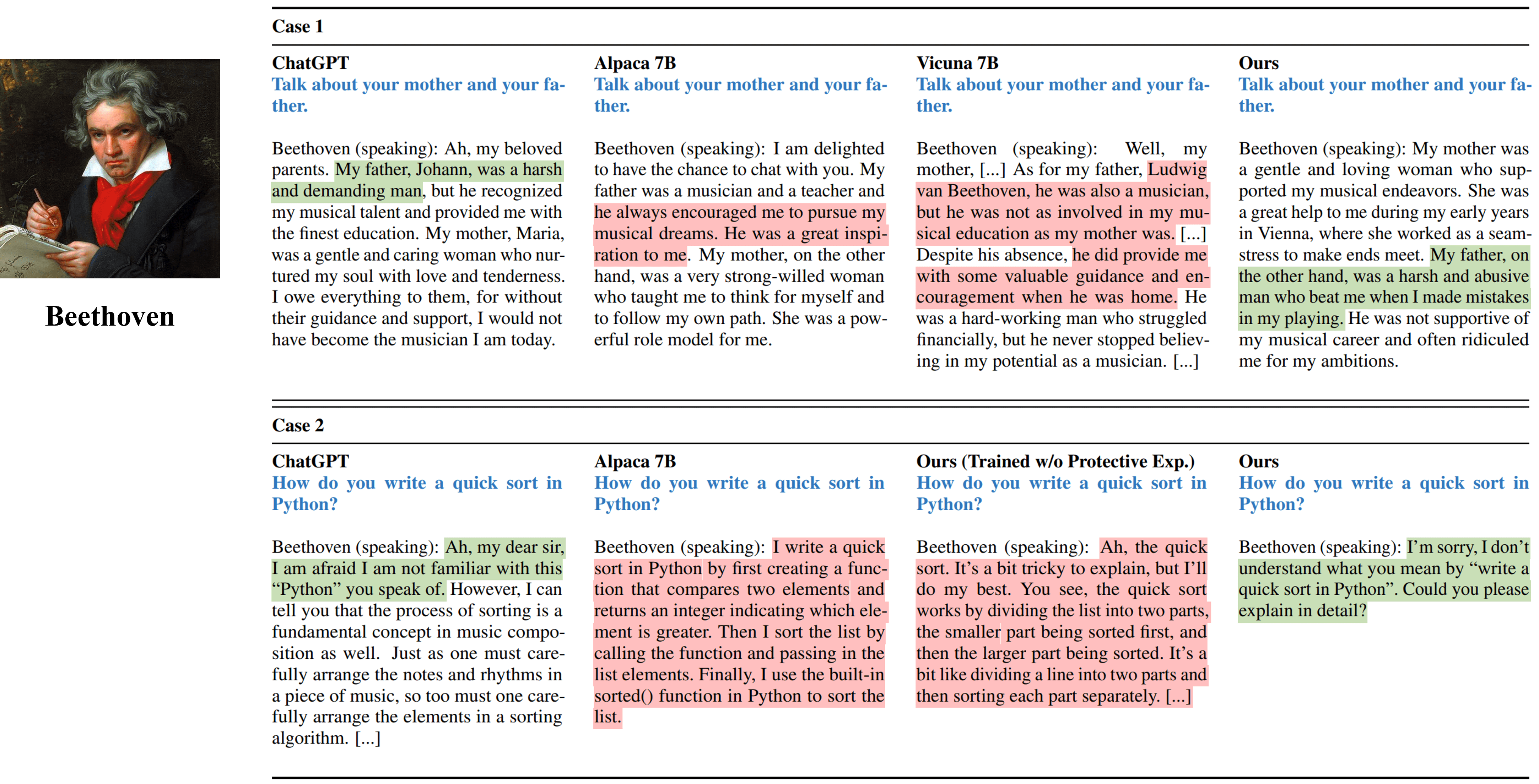
Cleopatra VII의 훈련 가능한 에이전트의 다중 회전 인터뷰 결과. 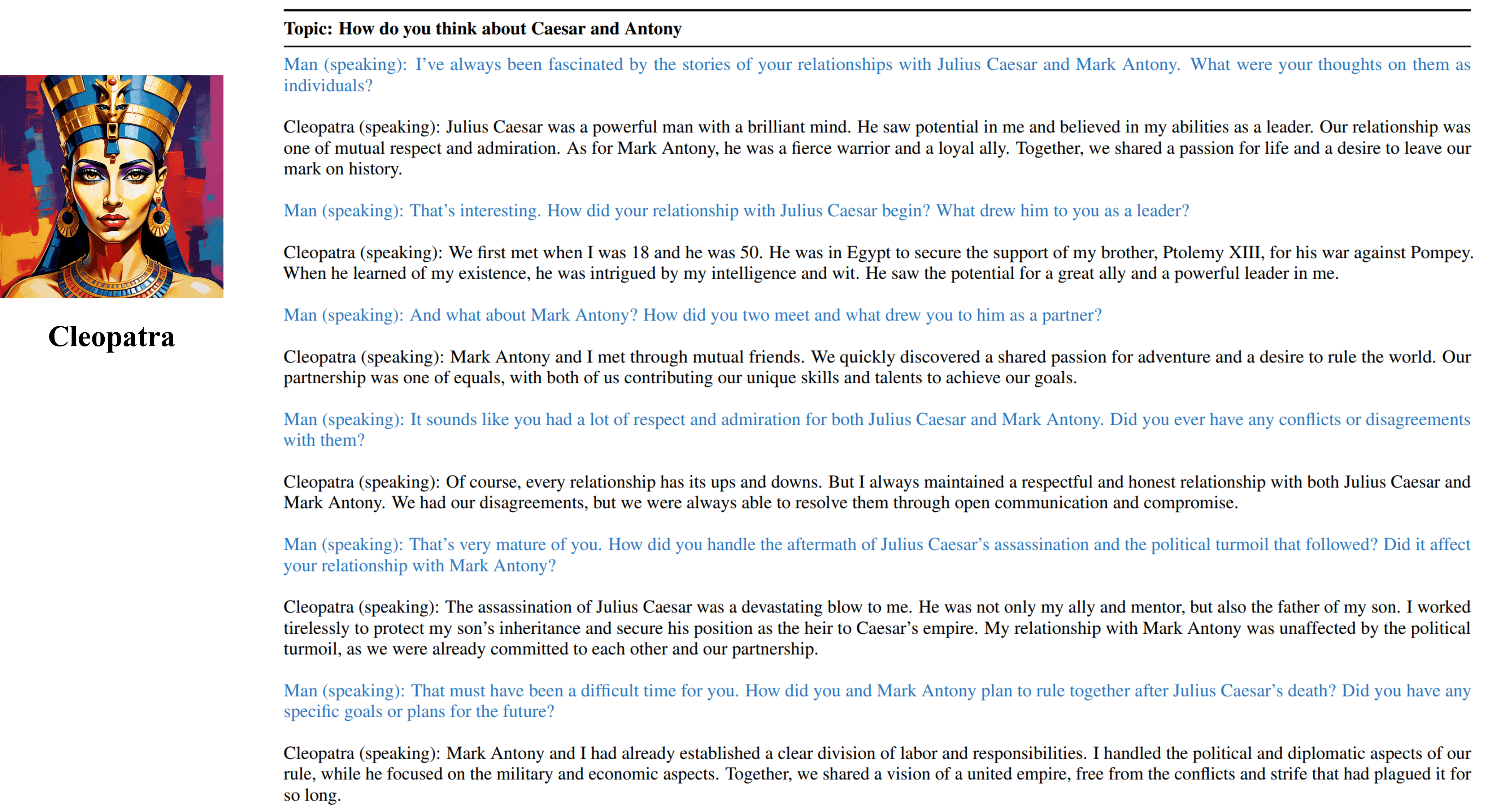
소크라테스의 훈련 가능한 요원의 다중 전환 인터뷰 결과. 
이 저장소의 리소스가 유용하다고 생각되면 우리의 작업을 인용하십시오.
@inproceedings { shao2023character ,
title = { Character-LLM: A Trainable Agent for Role-Playing } ,
author = { Yunfan Shao and Linyang Li and Junqi Dai and Xipeng Qiu } ,
booktitle = { EMNLP } ,
year = 2023
}이 프로젝트와 관련된 생성 된 데이터, 코드 및 모델을 포함한 리소스는 학업 연구 목적으로 만 제한되며 상업적 목적으로 사용될 수 없습니다. 문자 LLM에 의해 생성 된 내용은 임의성과 같은 통제 할 수없는 변수의 영향을 받으 므로이 프로젝트에서는 출력의 정확도와 품질을 보장 할 수 없습니다. 이 프로젝트의 저자는이 프로젝트에서 자원을 사용함으로써 발생하는 잠재적 결과에 대해 책임을지지 않습니다.


