Human parity on machine translations
1.0.0
在過去的幾年中,用於應對翻譯的傳統機器學習技術已經看到了很大的技術改進。但是,他們仍然在語言家族樹上相距甚遠的語言。例如,英語和中文/韓語/日語。
由於這些模型為何處理這些任務的本質(無法推斷上下文,瘋狂的語法等),我想知道在多語言語料庫中訓練的足夠規模的鑑定的大語言模型(LLM)將如何執行。雙語LLM可以在翻譯任務上近似雙語人嗎?
當然,第一步是選擇一個測試模型。很少有雙語或多語言模型都經過足夠的規模訓練,並且對所討論的兩種語言具有相同或接近平等的培訓數據表示。我感謝Thudm的團隊培訓和發布GLM-130B,這是一家雙語LLM,對英語和中文的2000億個代幣進行了培訓(總計400B)。 (https://github.com/thudm/glm-130b)。
這是用於測試的主要模型。此處可用的演示-https://huggingface.co/spaces/thudm/glm-130b,因為GLM-130B未經指導,需要進行幾聲或單次彈藥提示策略進行翻譯策略。在初步測試中,我注意到翻譯的複雜性和質量與少數拍攝示例的複雜性和質量的相關性。結果,我的一次性提示包括簡短的段落和一本用英語翻譯和出版的中文書中的相應翻譯。
我對GLM-130b的一擊提示
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]參數默認除外
打開AI的GPT模型具有多種語言,具有極端的英語偏見(〜92.6%的英語,單詞計數)(https://github.com/openai/gpt-3/blob/master/master/master/dataset_statistics/languages/languages_by_by_by_by_word_count.csv)。但是,由於一種語言的能力似乎使其他語言的能力以足夠規模的LLM流血(在非常大的英語語言模型的多語言能力上,https://arxiv.org/abs/2108.13349),我還包括比較中的chatgpt translions。由於Chatgpt是按照指令對準的,因此一個簡單的翻譯命令就足夠且使用了。特定的說明或示例以優先考慮流利性和流動性,可能會產生更好的結果。
沒有留下的語言,Meta的NLLB-200在機器翻譯基准上實現了最先進的結果,並且也進行了比較。
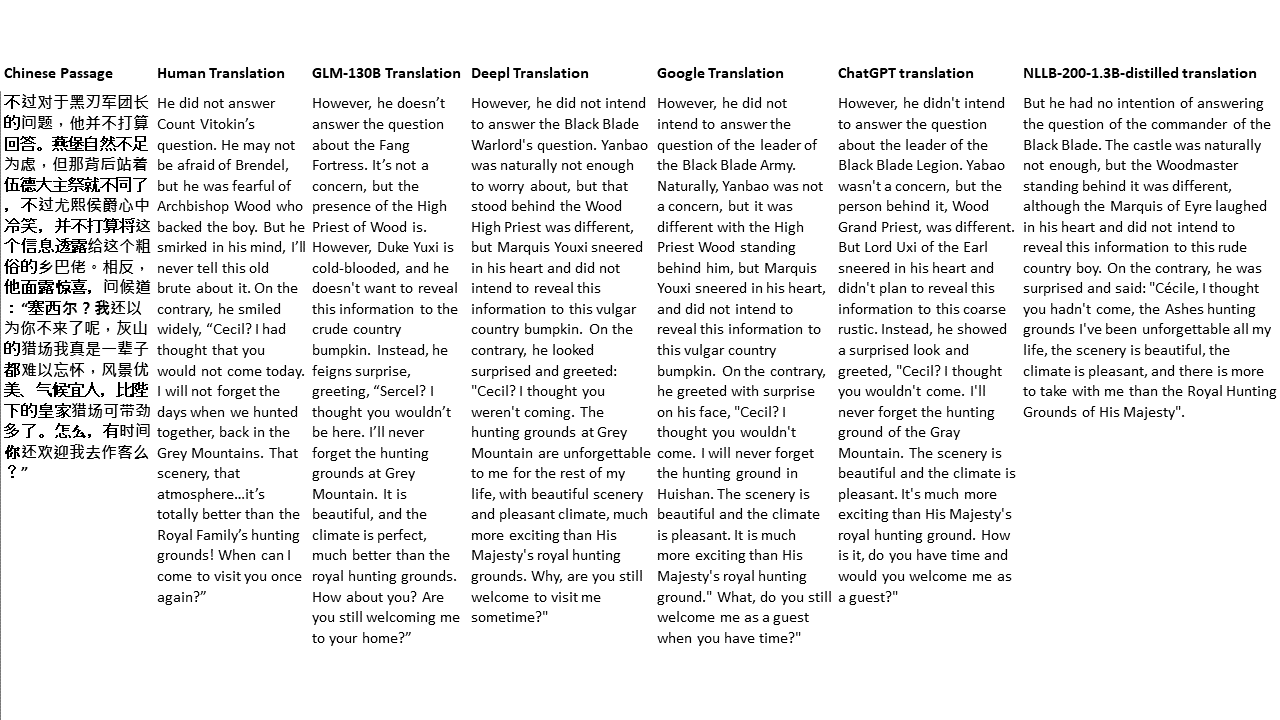
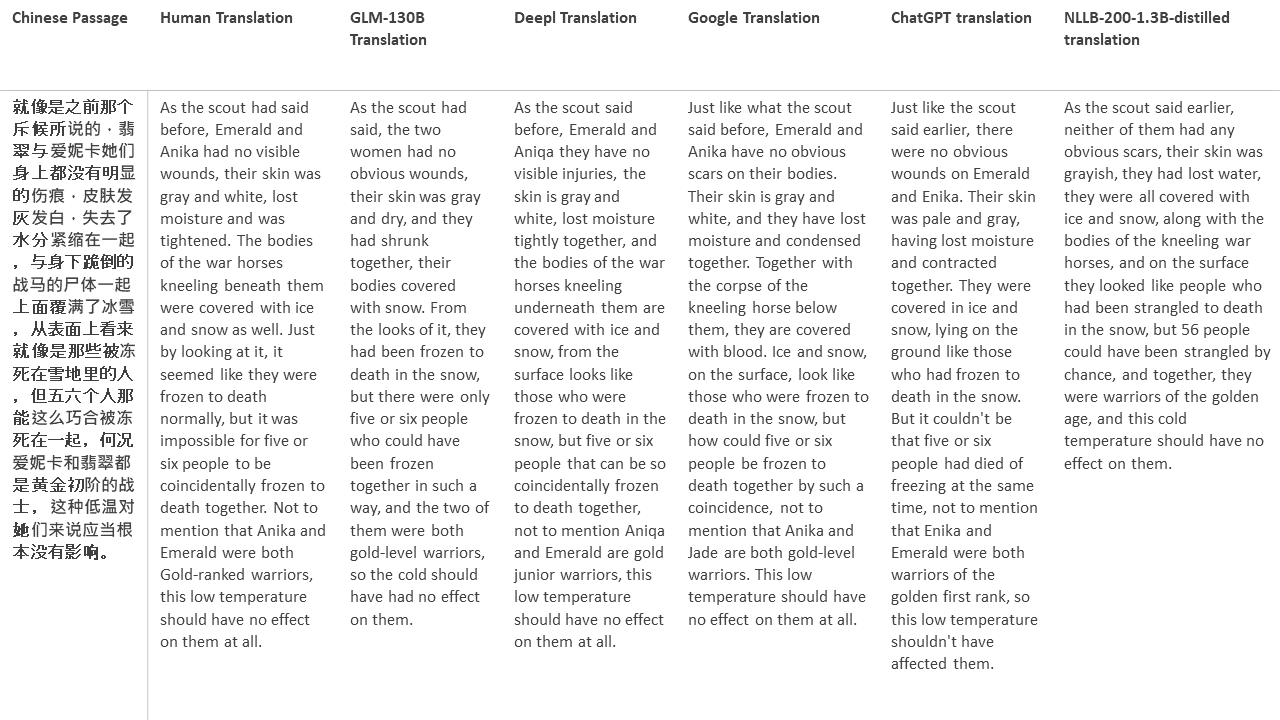
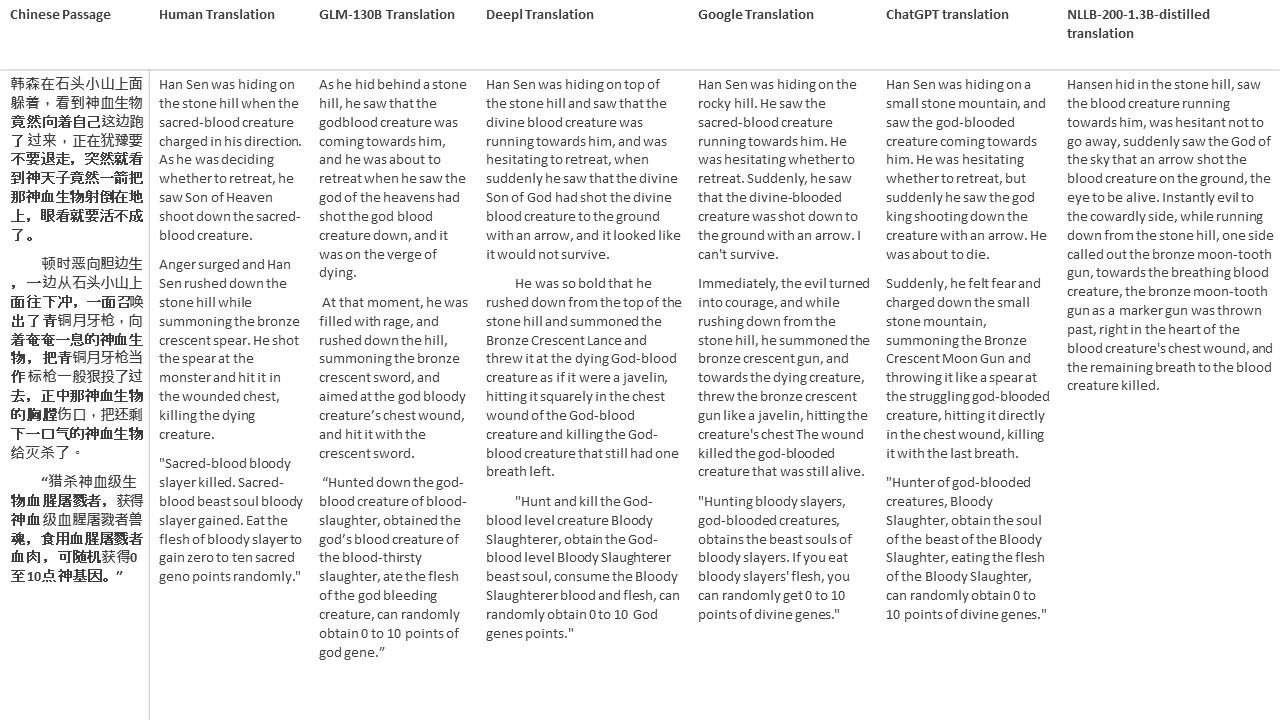
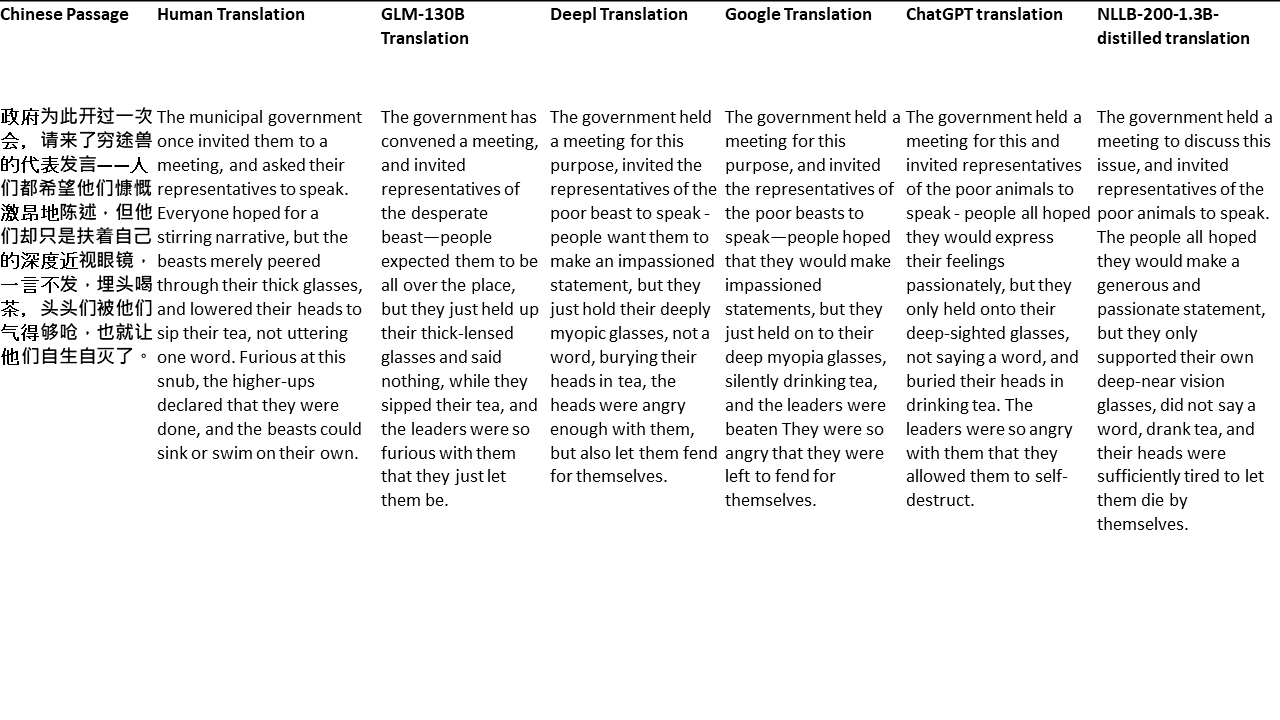
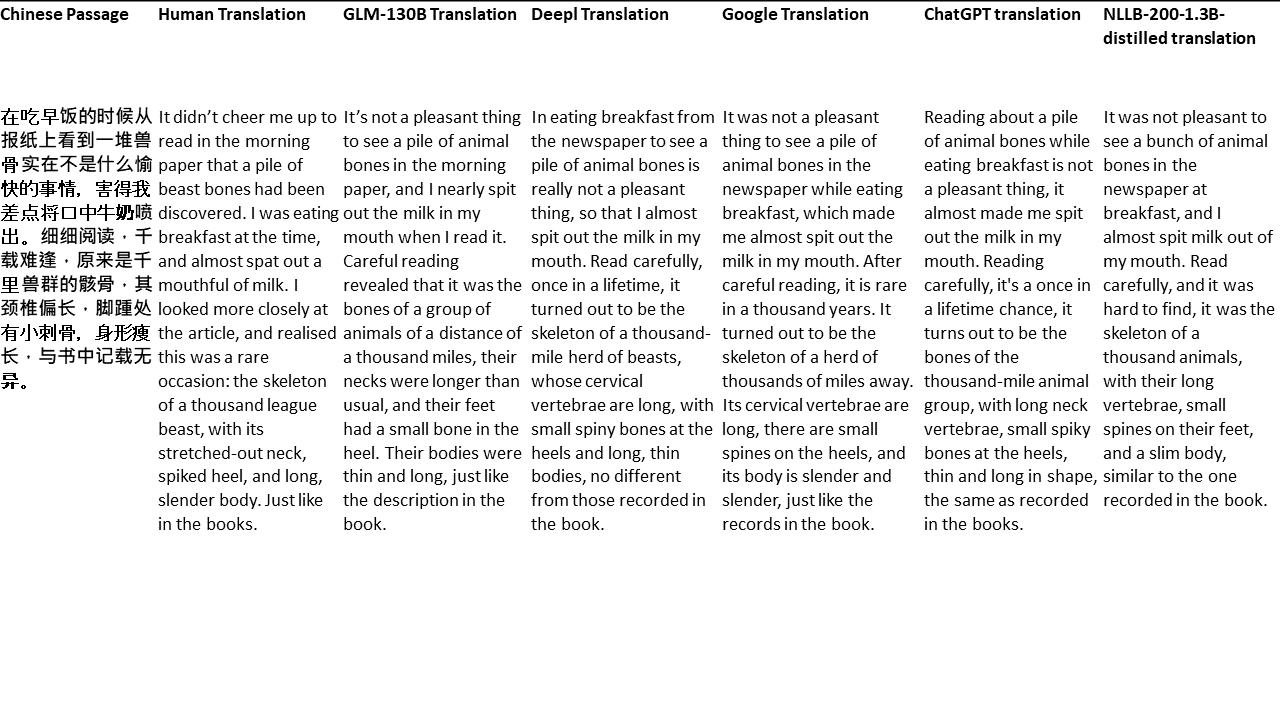
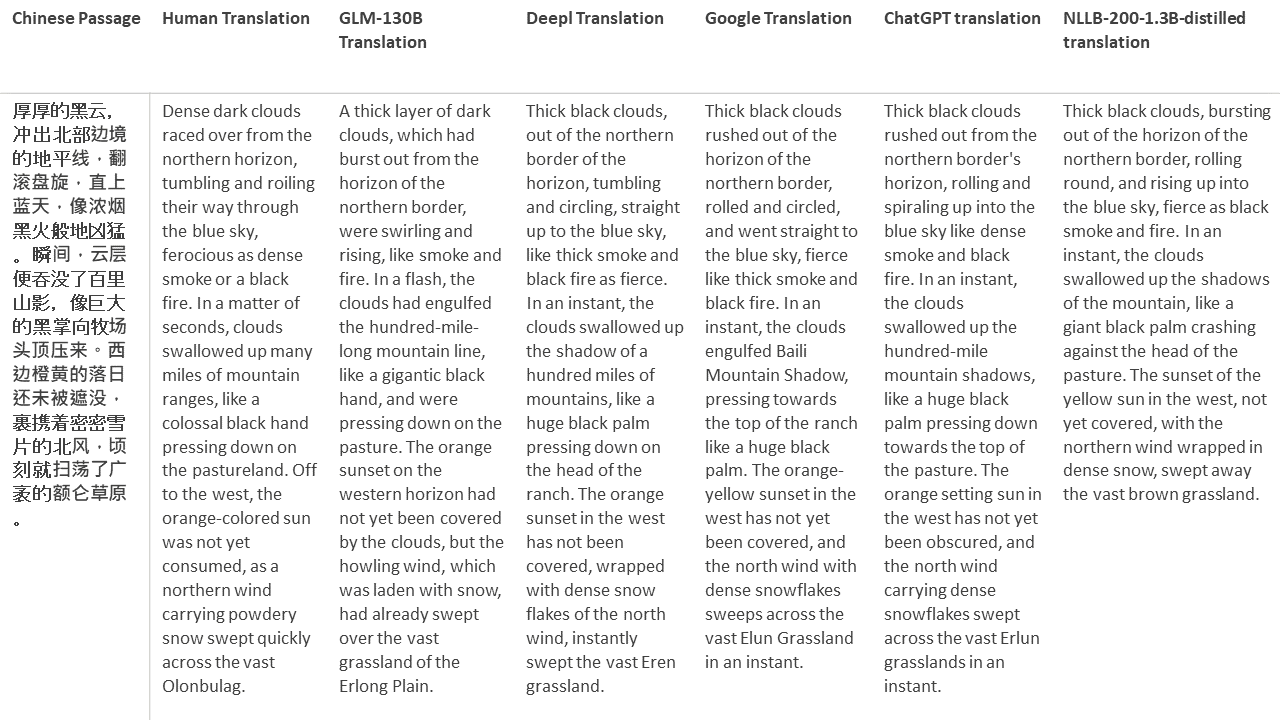
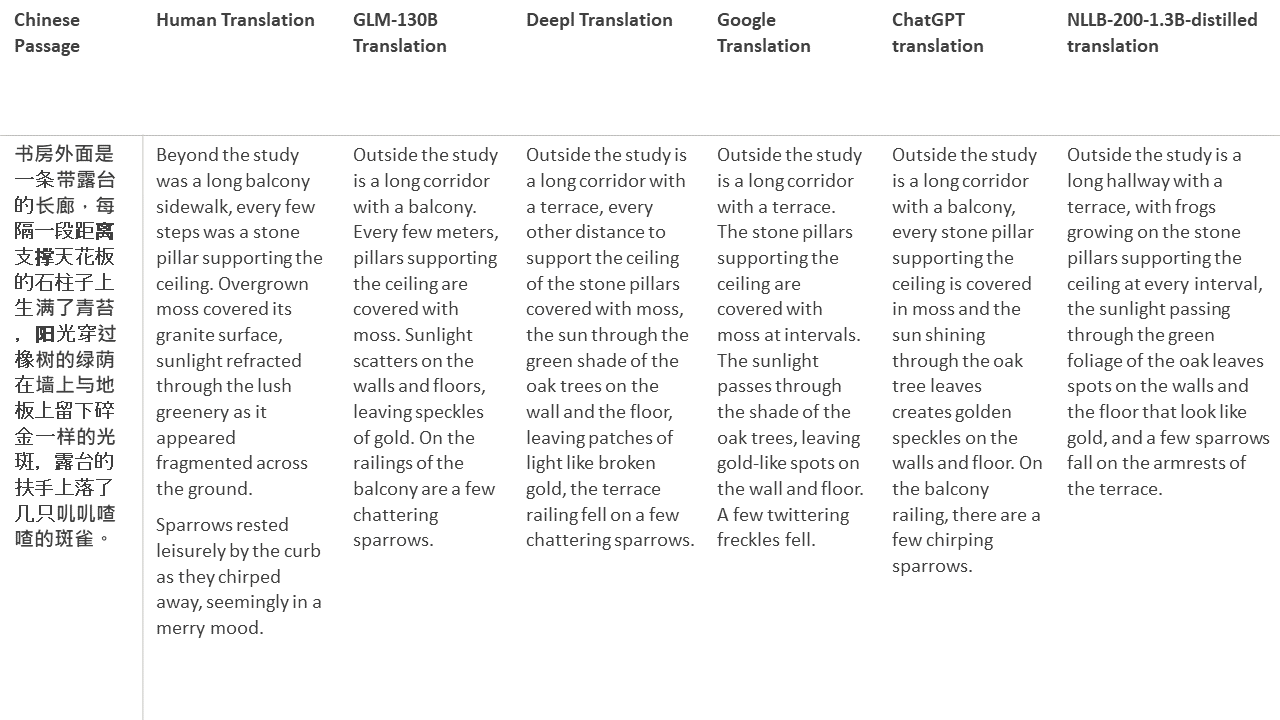
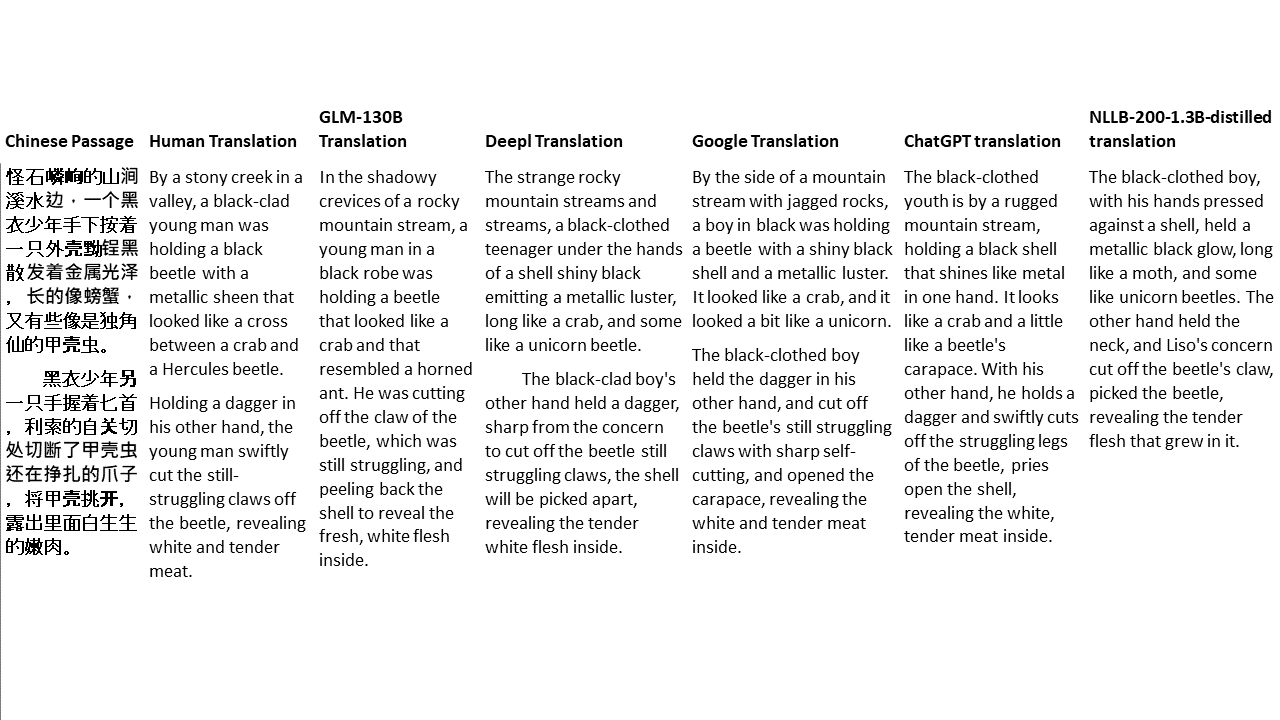
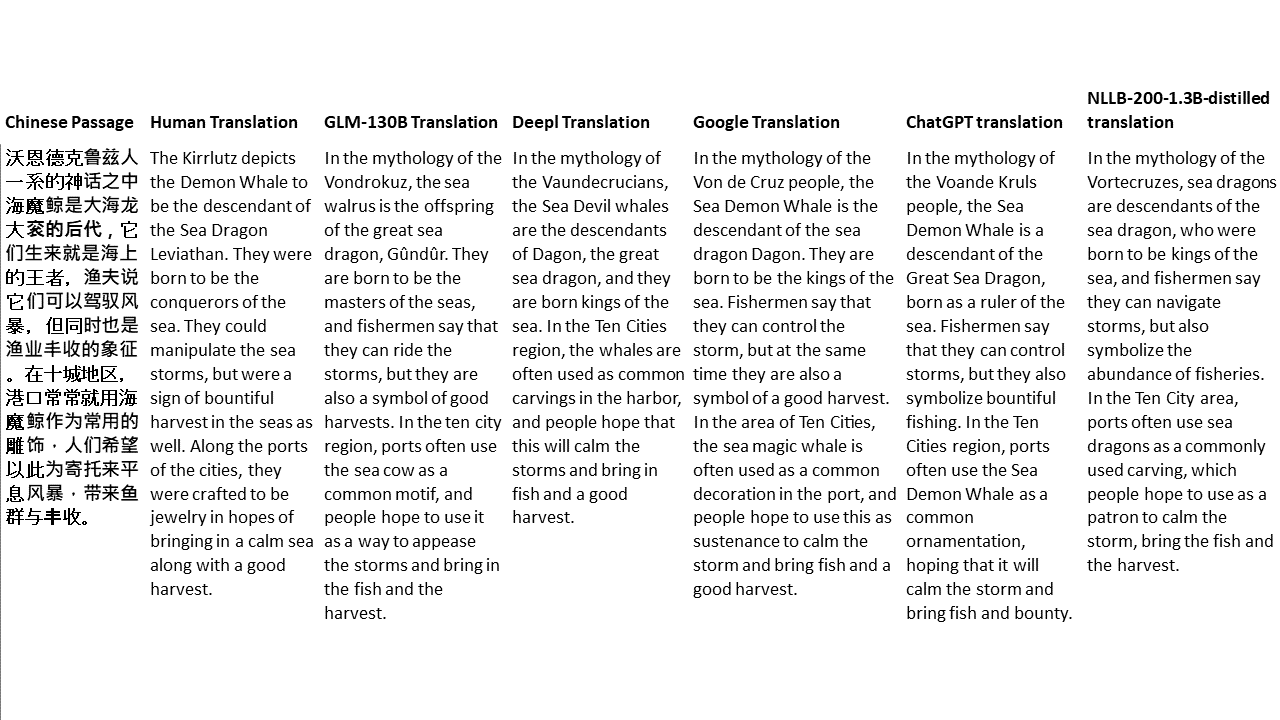
對於我的測試,我選擇了文獻,這是機器翻譯的特別困難領域。 21段落用GLM-130B翻譯,並與Deepl,Google Translate,Chatgpt和NLLB-200-1.3B延伸。這些段落是從5個小說中取樣的。 Liu Xinwu舉行的婚禮,Yan GE的《奇怪的野獸》,Fei Yanfu的《琥珀之劍》,《江圖騰》和《超級》。這些段落是隨機選擇的。他們沒有被挑選或再生。