Human parity on machine translations
1.0.0
翻訳に取り組むための伝統的な機械学習技術は、ここ数年で最先端の大きな改善を見てきました。しかし、彼らはまだ言語の家系図ではるかに離れている言語と格闘しています。たとえば、英語と中国語/韓国/日本語。
これらのモデルがこれらのタスクと格闘する理由の性質上(コンテキストを外挿することができず、文法の不一致など)、多言語で訓練された十分なスケールの前提条件の大規模な言語モデル(LLM)がどのように機能するのか疑問に思いました。バイリンガルLLMは、翻訳タスクでバイリンガルの人間を近似できますか?
もちろん、最初のステップは、テストのモデルを選択することでした。十分なスケールでトレーニングされており、問題の2つの言語のトレーニングデータ表現が等しいか、ほぼ等しいバイリンガルモデルまたは多言語モデルはほとんどありません。 Thudmのチームに、GLM-130Bのトレーニングとリリースをしてくれたことに感謝します。GLM-130Bは、英語と中国語のそれぞれ2,000億トークン(合計400B)でトレーニングされたバイリンガルLLMです。 (https://github.com/thudm/glm-130b)。
これは、テストに使用される主なモデルです。ここで入手できます-https://huggingface.co/spaces/thudm/glm-130b glm-130bは命令finetunedではないため、翻訳のためのいくつかのショットまたはワンショットのプロンプト戦略が必要です。予備的なテストでは、翻訳の複雑さと品質にいくつかの相関関係があることに気付きました。その結果、私のワンショットプロンプトには、短いパッセージと、英語で翻訳および公開された中国の本からの対応する翻訳が含まれています。
GLM-130Bのワンショットプロンプト
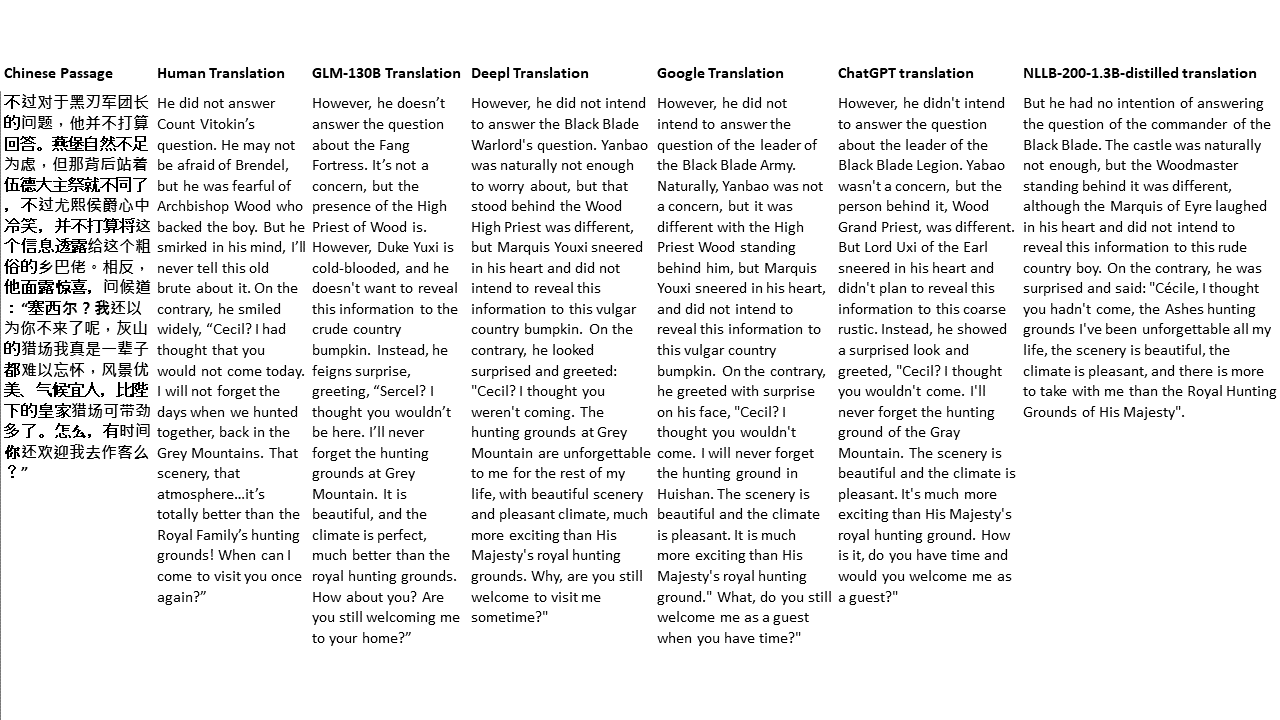
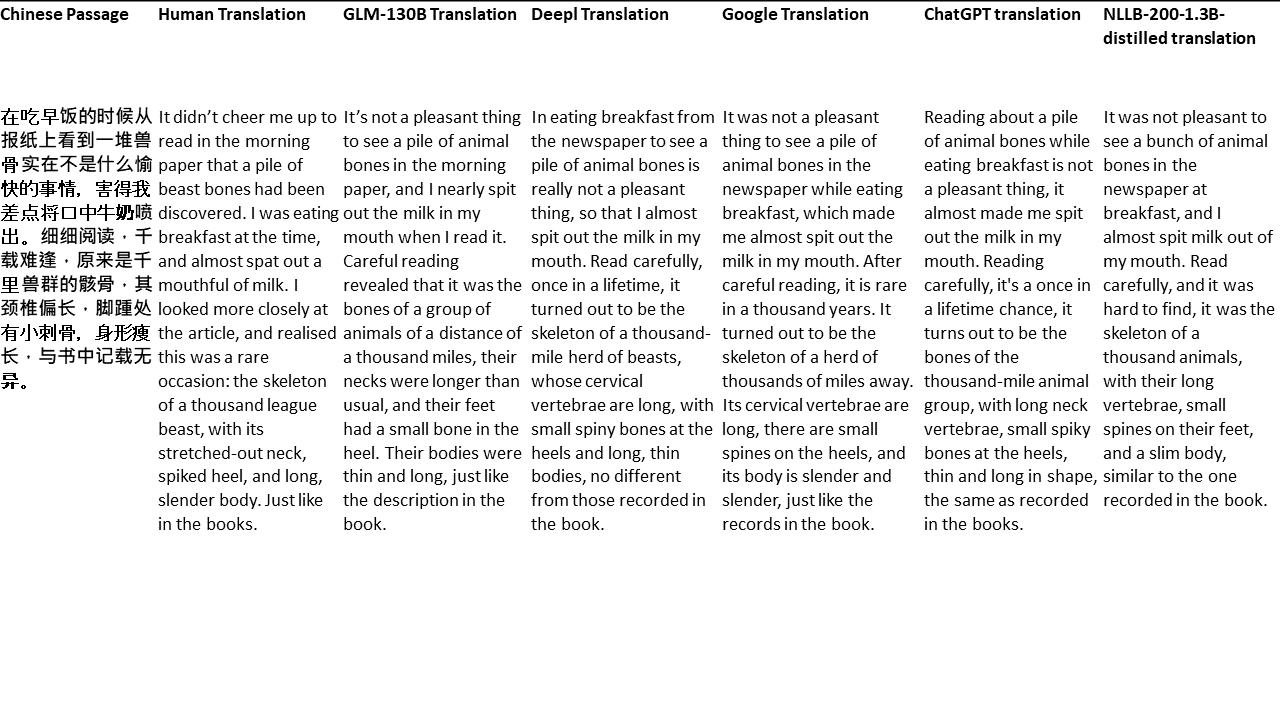
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]パラメーターは、以外のデフォルトです
オープンAIのGPTモデルは、極端な英語のバイアス(ワードカウントごとに〜92.6%英語)を備えた多言語です(https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_word_count.csv)。ただし、ある言語での能力は、十分なスケールのLLM(非常に大規模な英語モデルの多言語能力であるhttps://arxiv.org/abs/2108.13349)で他の言語の能力に溶け込んでいるように見えるため、比較にchatgpt翻訳も含めます。 ChatGptは命令に合わせて整理されているため、単純な翻訳コマンドで十分で使用されています。流encyさと流動性に優先順位を付けるための特定の指示または例は、より良い結果をもたらす可能性があります。
残された言語はありません。MetaのNLLB-200は、機械翻訳ベンチマークで最先端の結果を達成し、比較しています。
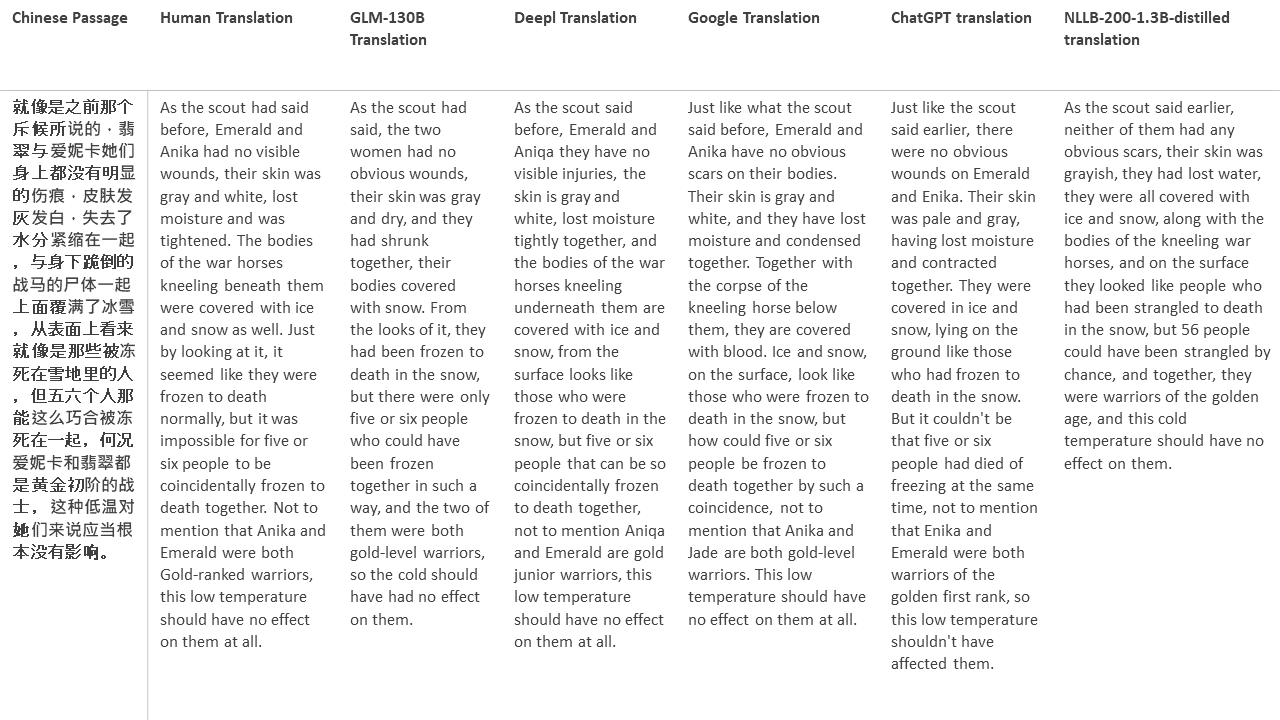
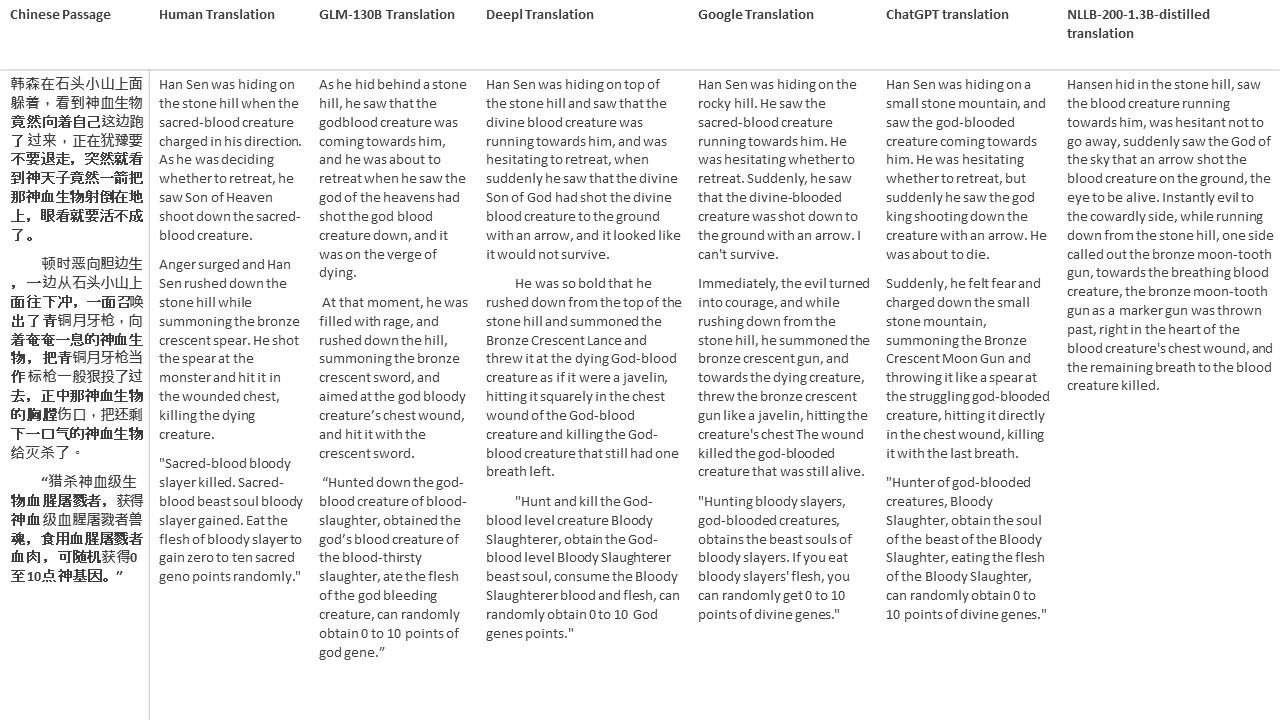
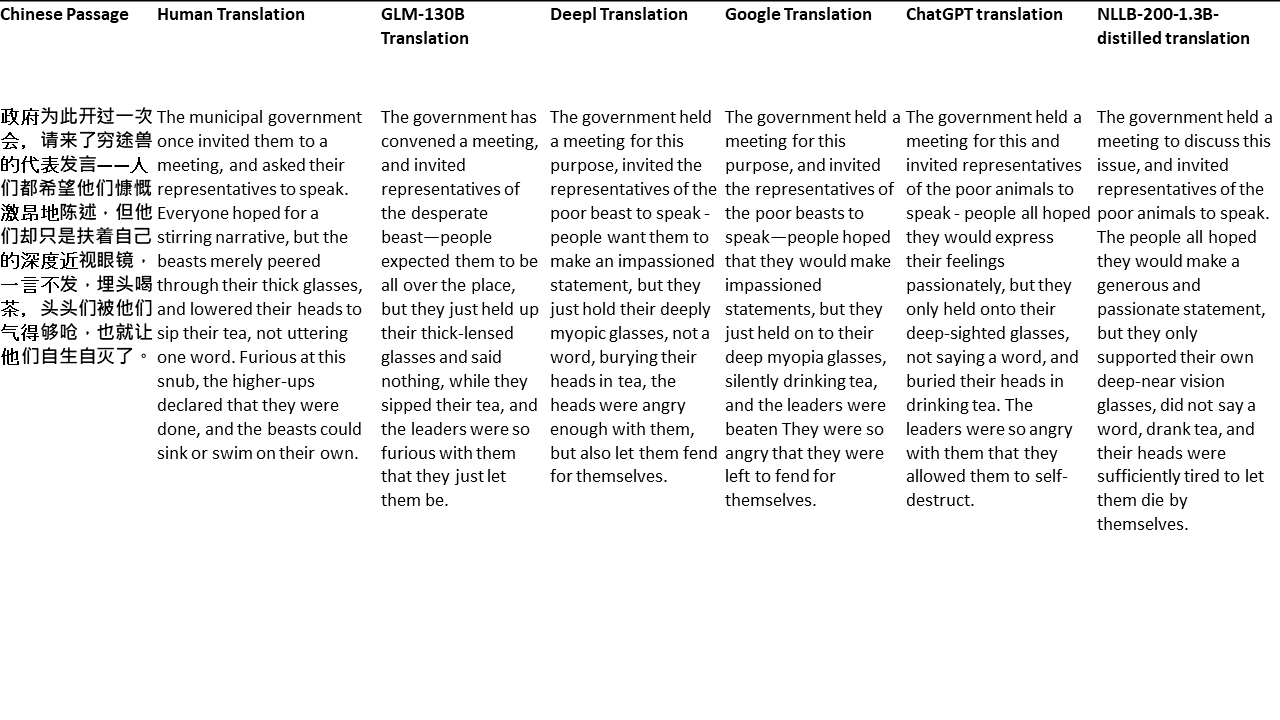
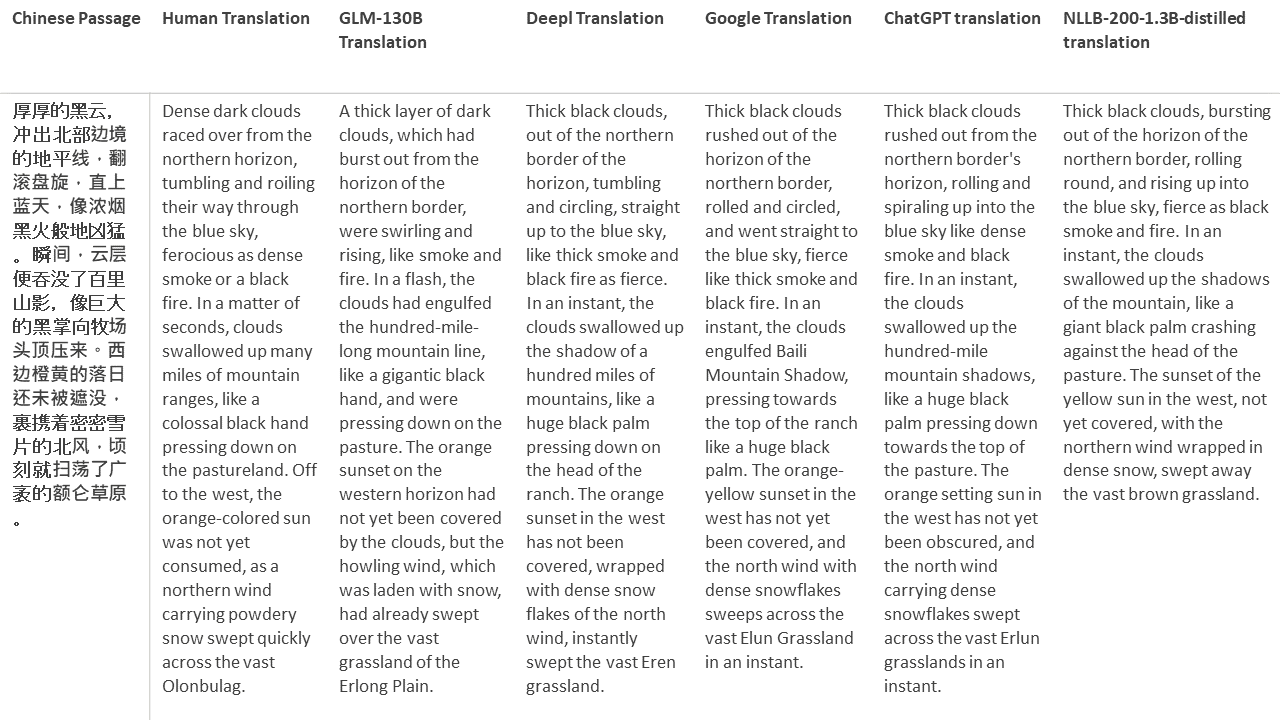
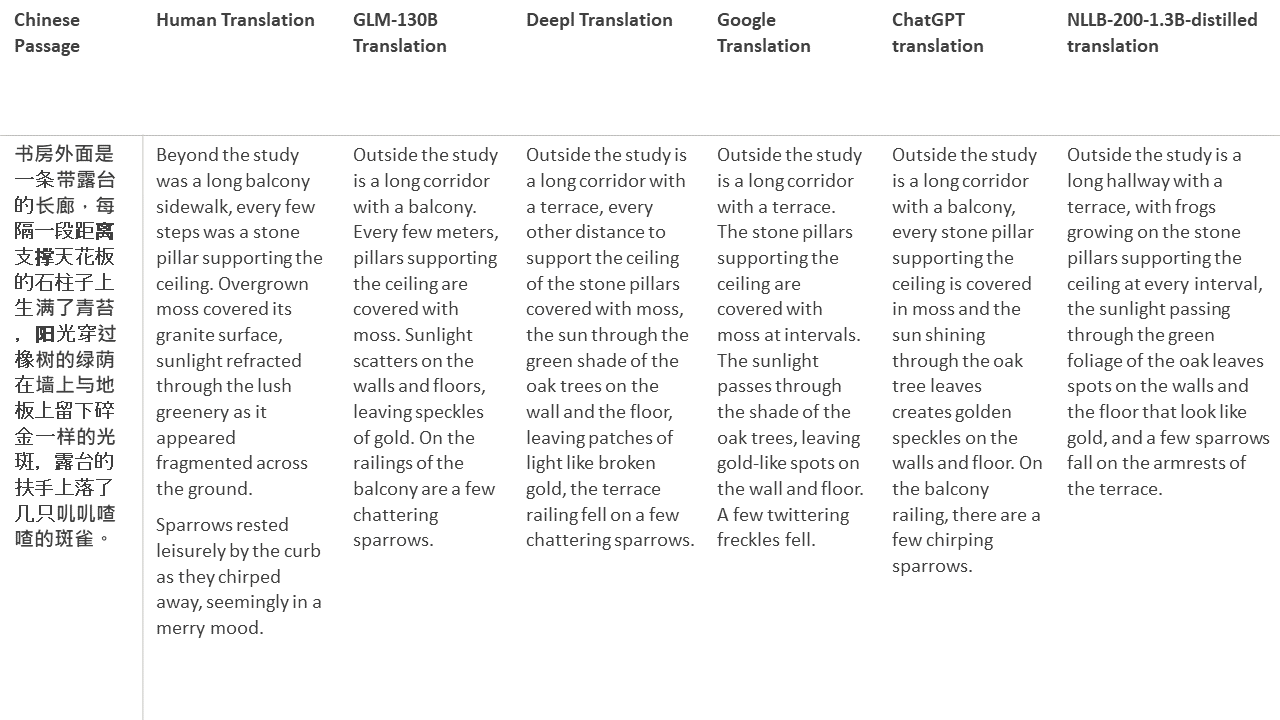
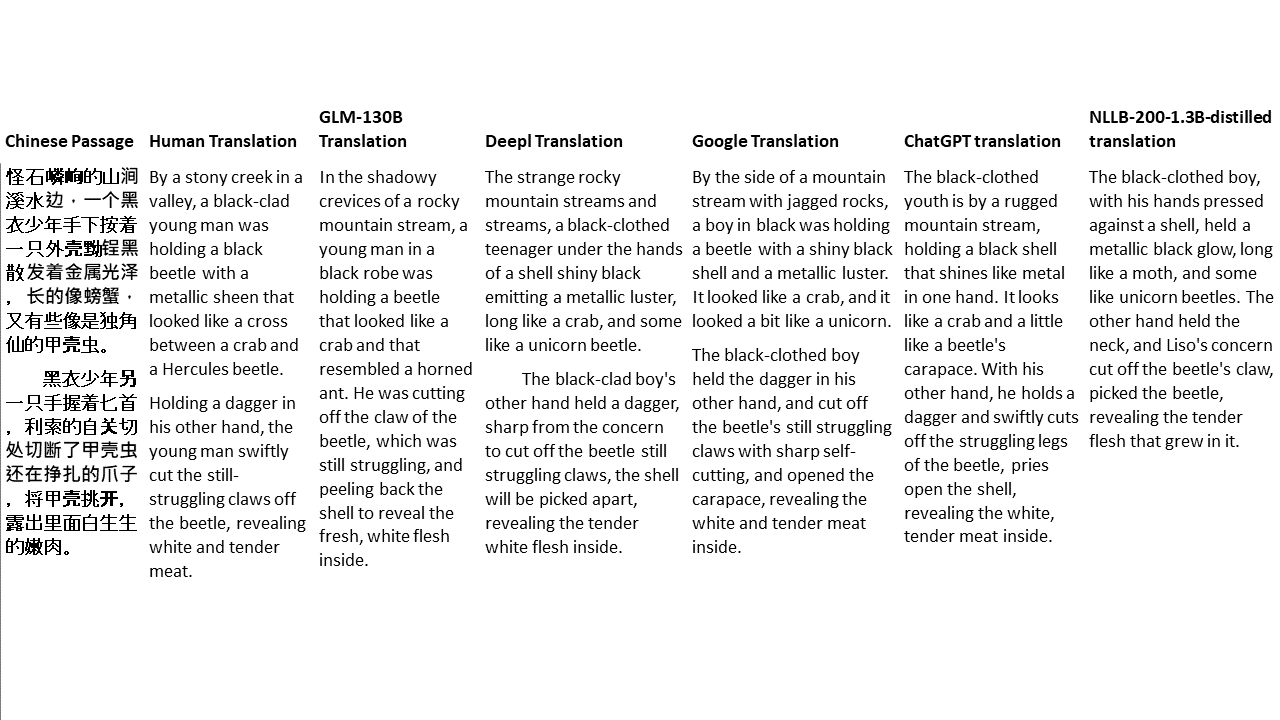
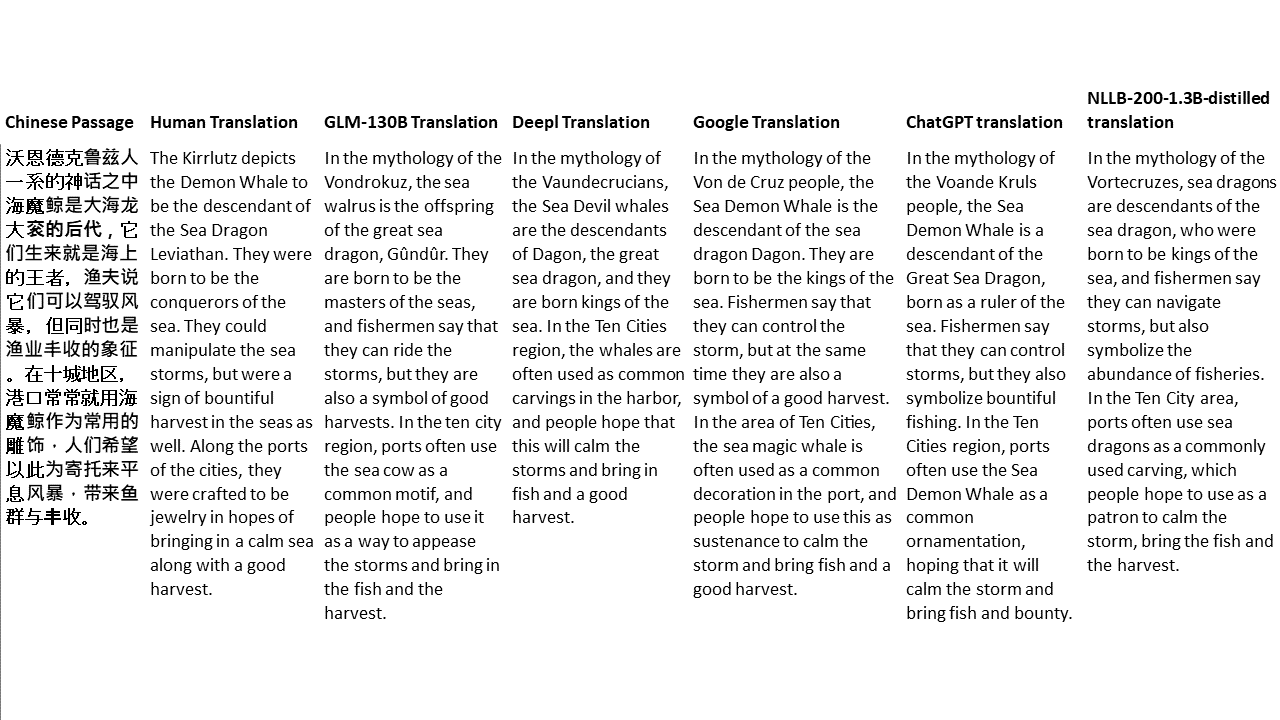
私のテストでは、機械翻訳のために特に難しいドメインである文学を選びます。 GLM-130Bで翻訳され、Deepl、Google Translate、ChatGPT、NLLB-200-1.3Bが拡張した21のパッセージ。パッセージは5つの小説からサンプリングされます。 Liu Xinwuによる結婚式のパーティー、Yan Geによる中国の奇妙な獣、Fei YanfuによるAmber Sword、Jiang RongとSupergeneのWolf Totem。通路はランダムに選択されます。彼らはチェリーピックや再生されていません。