Human parity on machine translations
1.0.0
Teknik pembelajaran mesin tradisional untuk menangani terjemahan telah melihat peningkatan kondisi seni dalam beberapa tahun terakhir. Namun, mereka masih berjuang dengan bahasa yang berjauhan di pohon keluarga bahasa. Misalnya, Inggris dan Cina/Korea/Jepang.
Karena sifat mengapa model -model ini bergumul dengan tugas -tugas ini (ketidakmampuan untuk mengekstrapolasi konteks, tata bahasa yang sangat tidak cocok dll), saya bertanya -tanya bagaimana model bahasa besar pretrained (LLM) pada skala yang cukup terlatih pada korpora multibahasa akan dilakukan. Bisakah seorang bilingual LLM mendekati manusia bilingual pada tugas terjemahan?
Langkah pertama tentu saja adalah memilih model untuk pengujian. Ada sangat sedikit model bilingual atau multibahasa yang keduanya dilatih pada skala yang cukup dan memiliki representasi data pelatihan yang sama atau hampir sama untuk dua bahasa yang bersangkutan. Saya berterima kasih kepada tim di Thudm untuk melatih dan merilis GLM-130B, sebuah LLM dwibahasa yang dilatih pada 200 miliar token masing-masing bahasa Inggris dan Cina (total 400B). (https://github.com/thudm/glm-130b).
Ini adalah model utama yang digunakan untuk pengujian. Demo Tersedia Di Sini-https://huggingface.co/spaces/thudm/glm-130b Karena GLM-130B tidak perlu diselenggarakan, diperlukan strategi yang diminta untuk terjemahan. Dalam tes pendahuluan, saya melihat beberapa korelasi dalam kompleksitas dan kualitas terjemahan dengan kompleksitas dan kualitas beberapa contoh tembakan. Akibatnya, prompt satu-shot saya termasuk bagian pendek dan terjemahan yang sesuai dari buku Cina yang diterjemahkan dan diterbitkan dalam bahasa Inggris.
Prompt One-Shot saya untuk GLM-130B
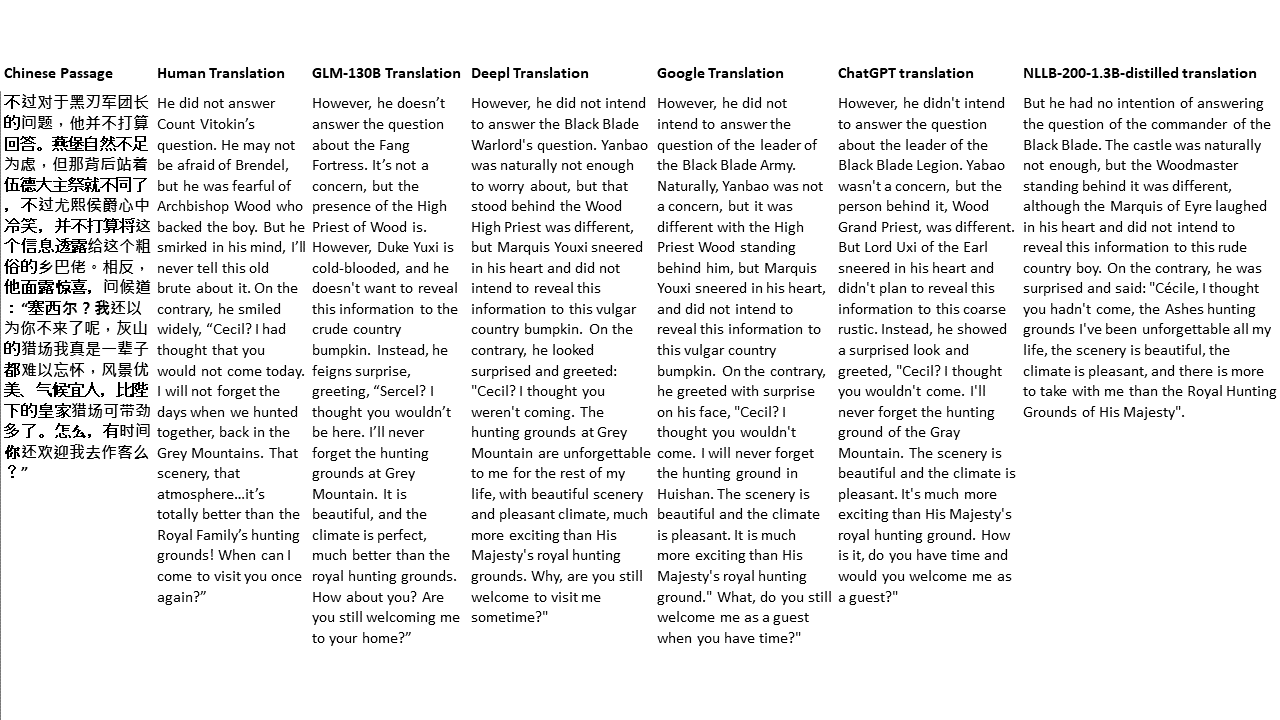
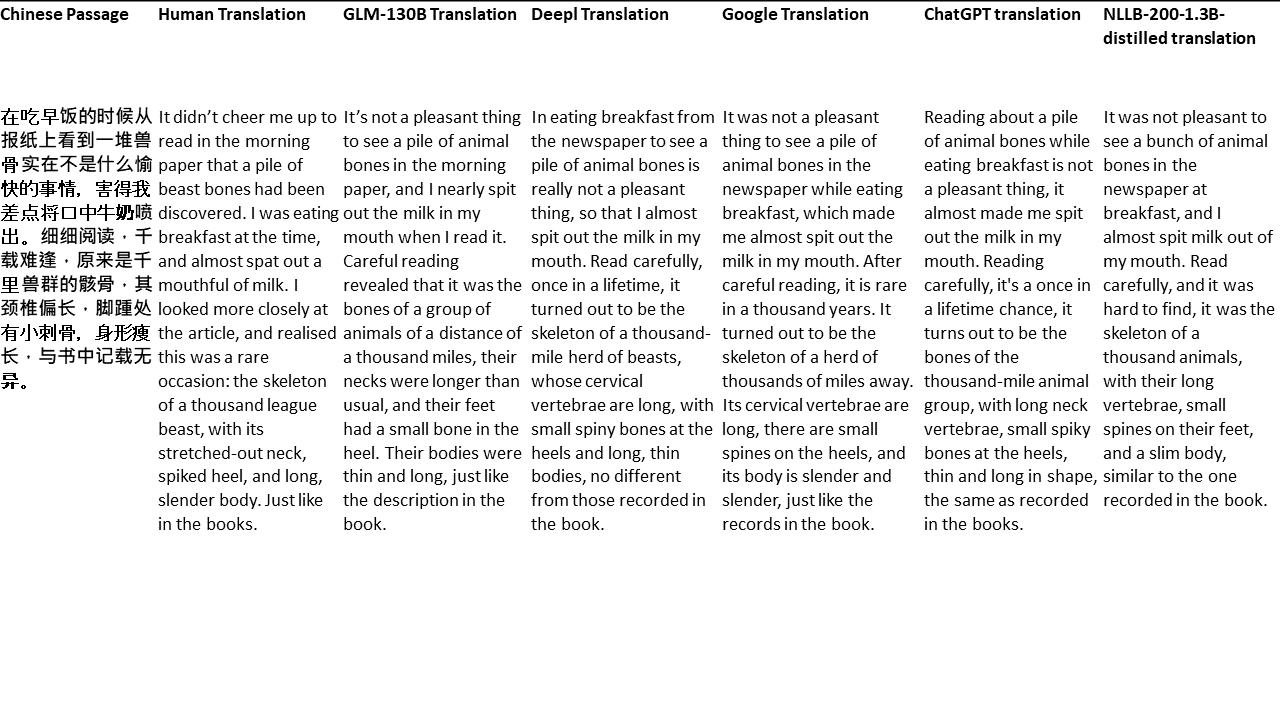
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]Parameter default kecuali
Model GPT Open AI bersifat multibahasa dengan bias bahasa Inggris yang ekstrem (~ 92,6% bahasa Inggris dengan jumlah kata) (https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_word_count.csv). Namun, karena kompetensi dalam satu bahasa tampaknya berdarah ke dalam kompetensi dalam bahasa lain dalam LLM dengan skala yang cukup (pada kemampuan multibahasa dari model bahasa Inggris skala besar-besar-https: //arxiv.org/abs/2108.13349), saya juga termasuk terjemahan chatgpt dalam perbandingan. Karena chatgpt selaras instruksi, perintah terjemahan sederhana sudah cukup dan digunakan. Instruksi atau contoh spesifik untuk memprioritaskan kelancaran dan fluiditas dapat menghasilkan hasil yang lebih baik.
Tidak ada bahasa yang tertinggal, NLLB-200 dari meta yang dicapai hasil canggih pada tolok ukur terjemahan mesin dan juga dibandingkan.
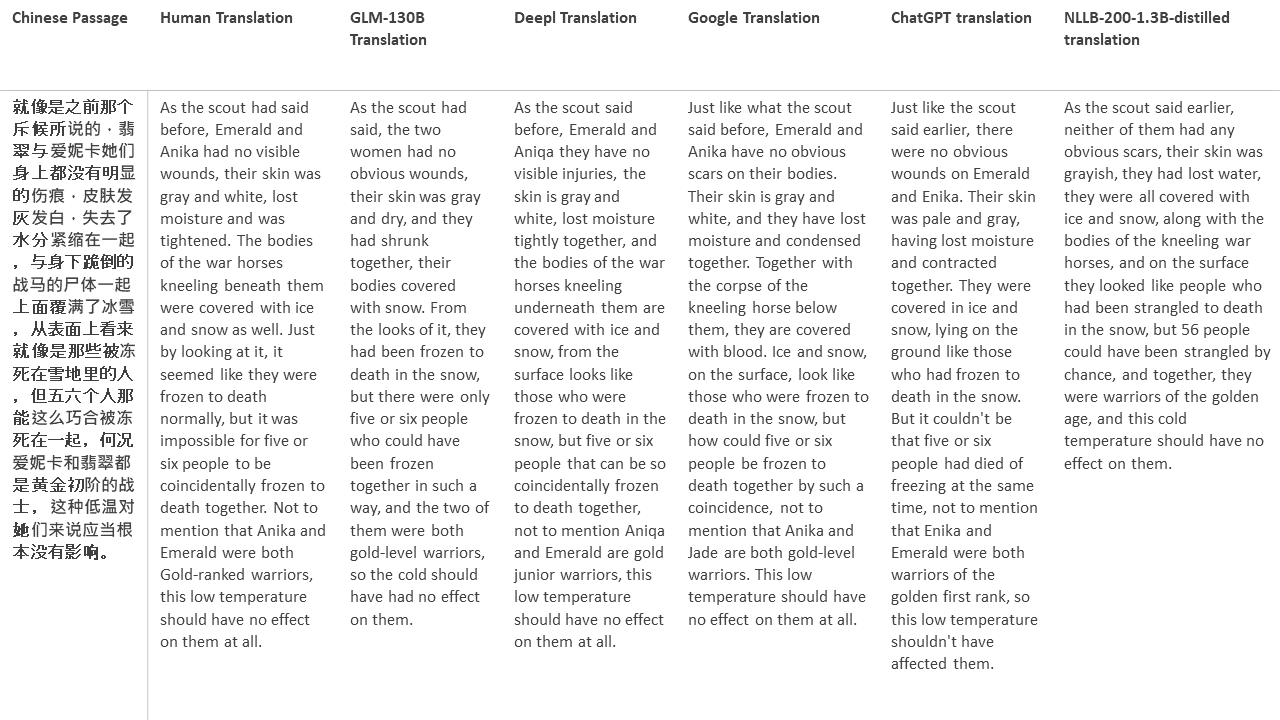
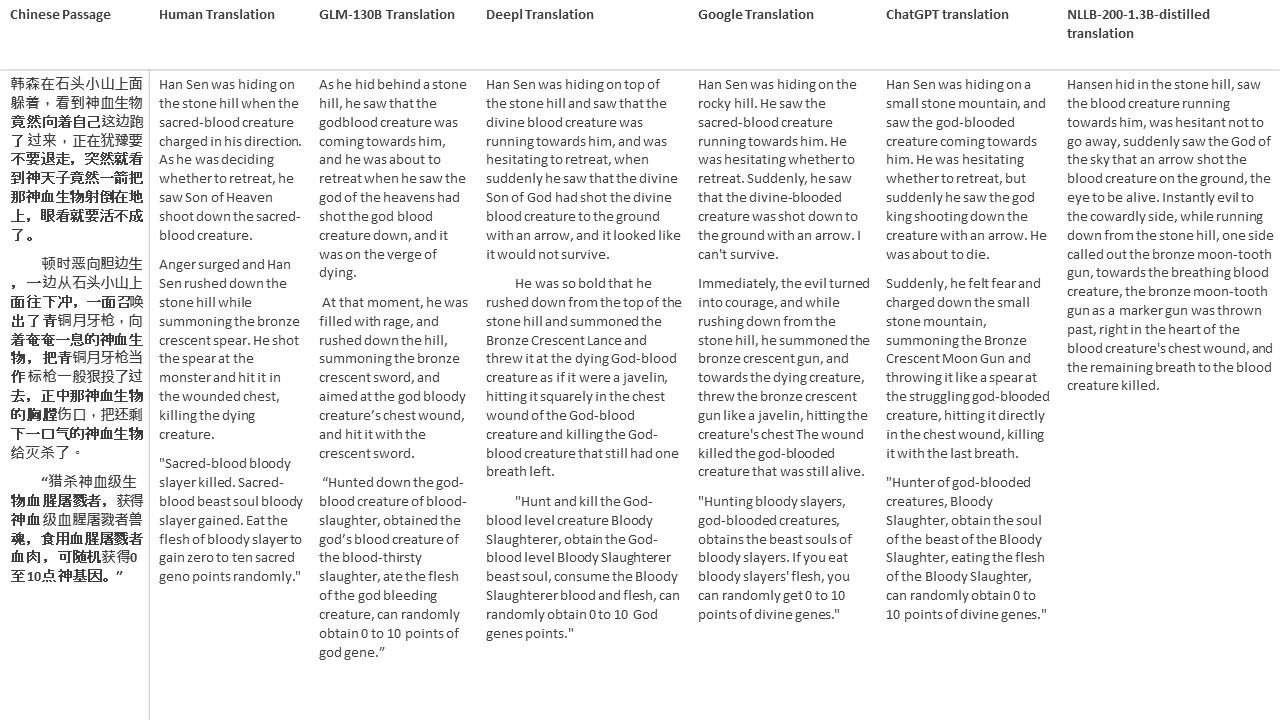
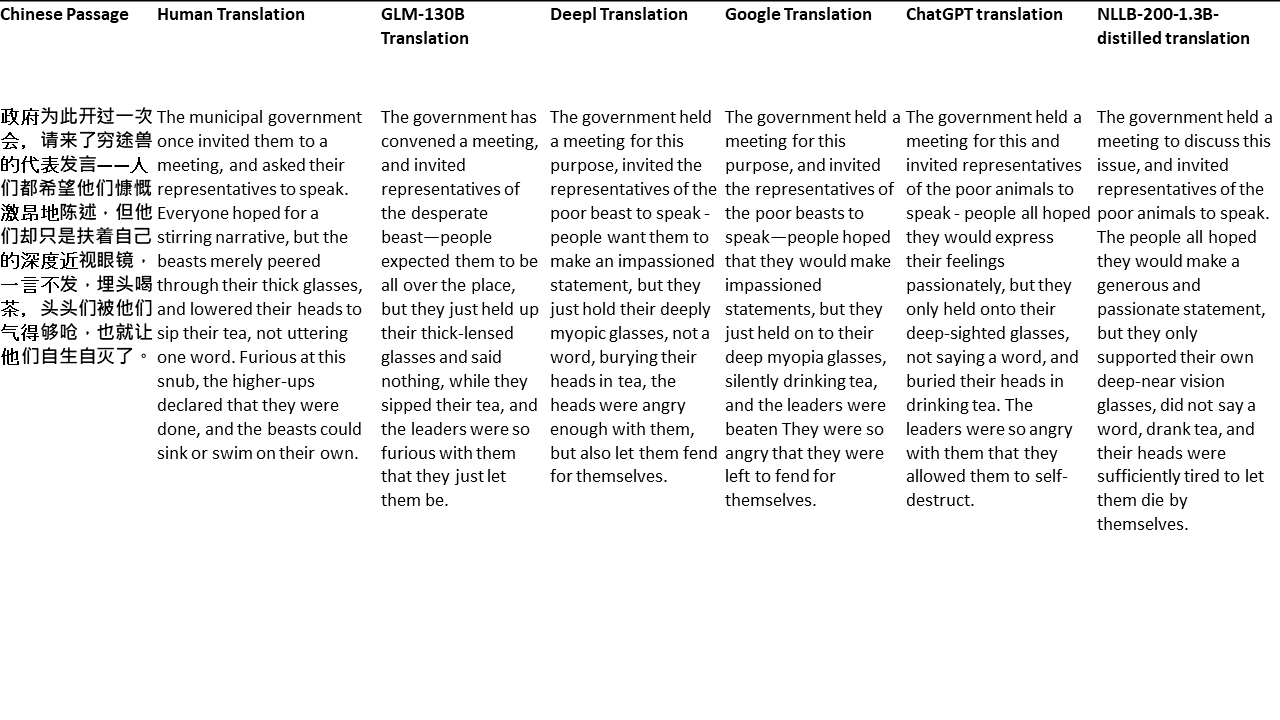
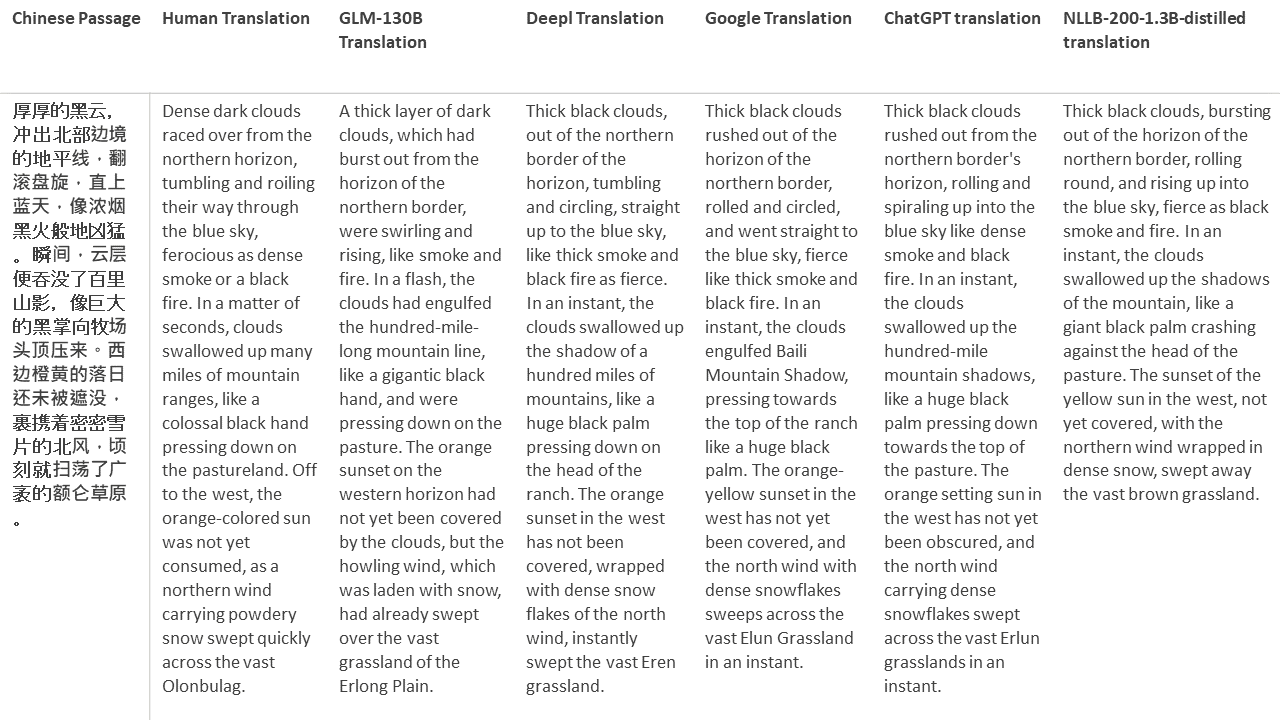
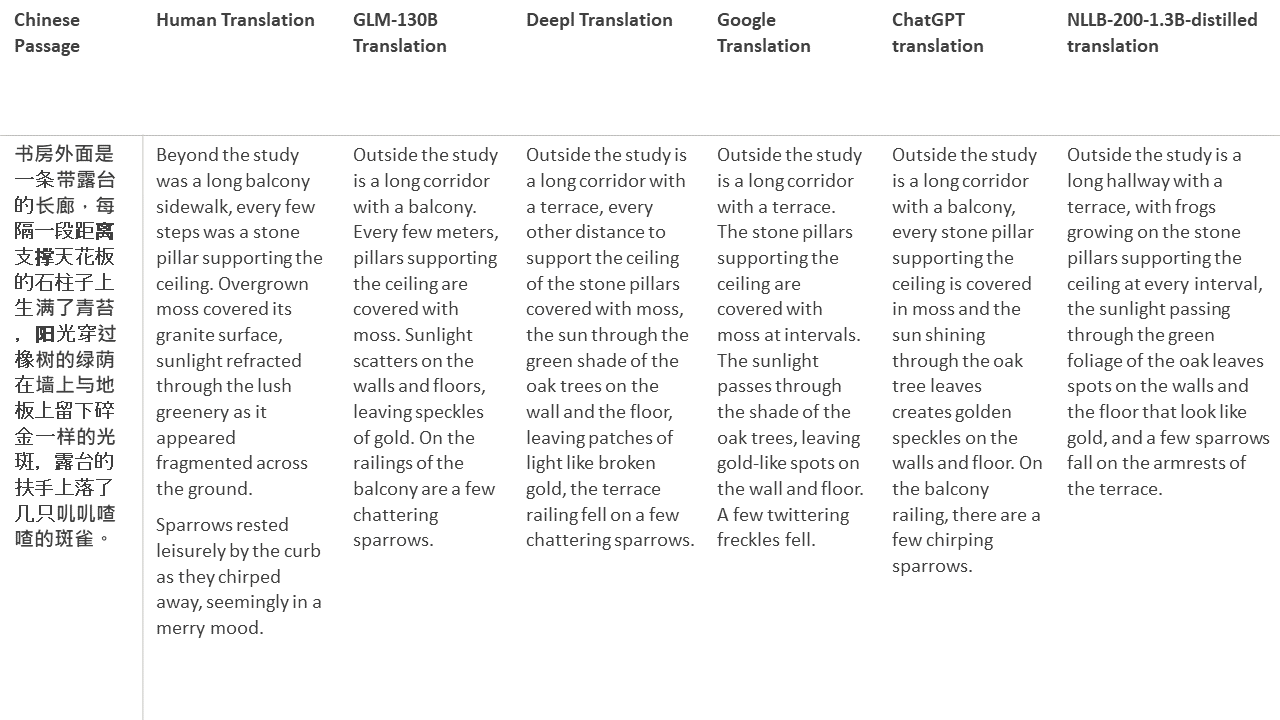
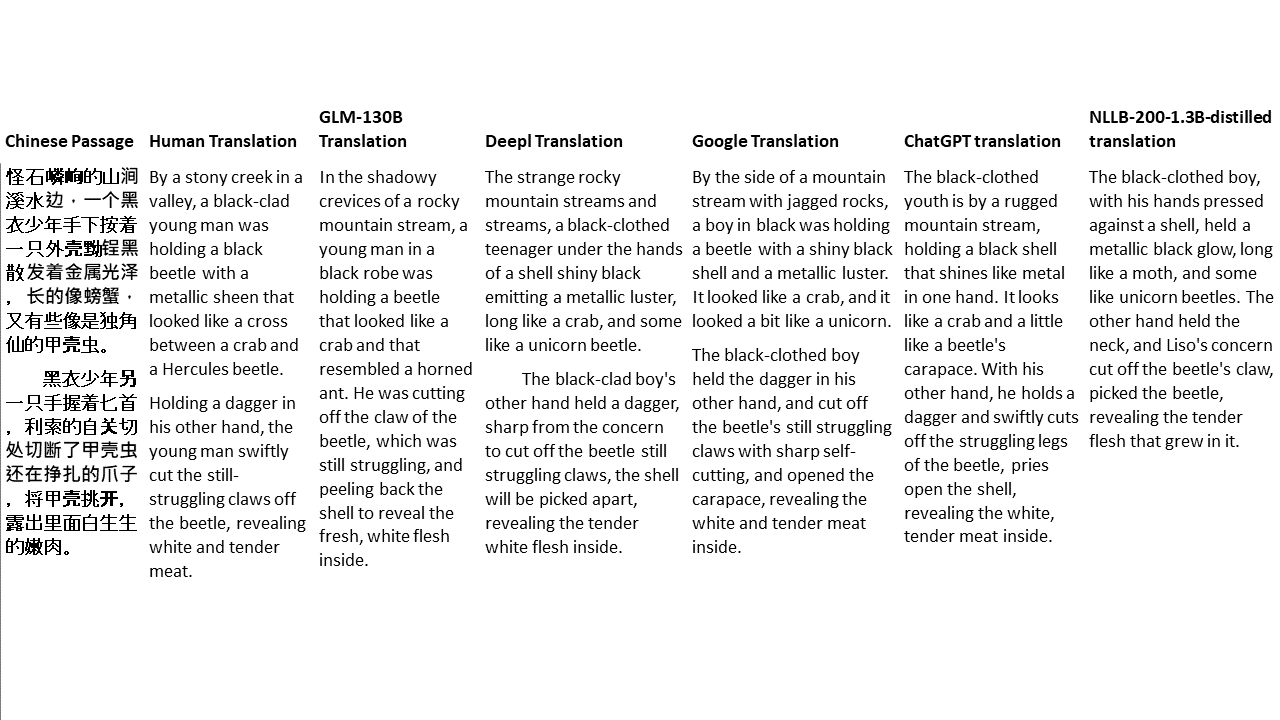
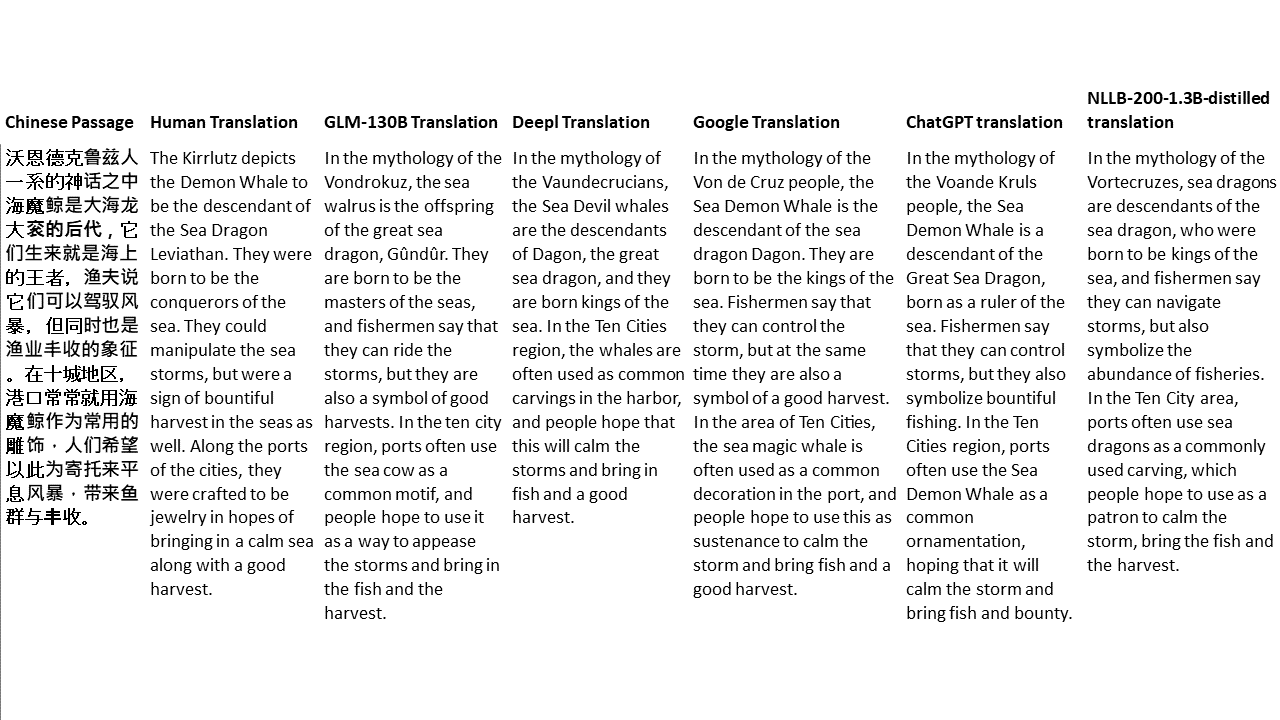
Untuk tes saya, saya memilih literatur, domain yang sangat sulit untuk terjemahan mesin. 21 bagian yang diterjemahkan dengan GLM-130B dan dibandingkan dengan Deepl, Google Translate, ChatGPT dan NLLB-200-1.3B-Distilled. Bagian -bagian ini diambil sampelnya dari 5 novel. Pesta Pernikahan oleh Liu Xinwu, binatang buas dari China oleh Yan Ge, The Amber Sword oleh Fei Yanfu, Wolf Totem oleh Jiang Rong dan Supergene. Bagian -bagian tersebut dipilih secara acak. Mereka tidak dipilih atau diregenerasi.