Human parity on machine translations
1.0.0
เทคนิคการเรียนรู้ของเครื่องจักรแบบดั้งเดิมสำหรับการจัดการการแปลได้เห็นการปรับปรุงศิลปะที่ยิ่งใหญ่ในช่วงไม่กี่ปีที่ผ่านมา อย่างไรก็ตามพวกเขายังคงดิ้นรนกับภาษาที่อยู่ห่างไกลกันบนต้นไม้ตระกูลภาษา ตัวอย่างเช่นภาษาอังกฤษและจีน/เกาหลี/ญี่ปุ่น
เนื่องจากธรรมชาติของทำไมแบบจำลองเหล่านี้จึงต้องดิ้นรนกับงานเหล่านี้ LLM สองภาษาสามารถประมาณมนุษย์สองภาษาในงานการแปลได้หรือไม่?
ขั้นตอนแรกของหลักสูตรคือการเลือกแบบจำลองสำหรับการทดสอบ มีแบบจำลองสองภาษาหรือหลายภาษาน้อยมากที่ได้รับการฝึกฝนในระดับที่เพียงพอและมีการแสดงข้อมูลการฝึกอบรมที่เท่ากันหรือใกล้เคียงกันสำหรับสองภาษาที่เป็นปัญหา ฉันขอขอบคุณทีมงานที่ Thudm สำหรับการฝึกอบรมและปล่อย GLM-130B ซึ่งเป็น LLM สองภาษาที่ได้รับการฝึกฝนเกี่ยวกับ 200 พันล้านโทเค็นแต่ละภาษาอังกฤษและจีน (รวม 400B) (https://github.com/thudm/glm-130b)
นี่คือโมเดลหลักที่ใช้สำหรับการทดสอบ ตัวอย่างมีให้ที่นี่-https://huggingface.co/spaces/thudm/glm-130b เนื่องจาก GLM-130B ไม่ได้เป็นคำสั่ง-finetuned ต้องใช้กลยุทธ์การแจ้งเตือนสองสามนัดหรือหนึ่งนัดสำหรับการแปล ในการทดสอบเบื้องต้นฉันสังเกตเห็นความสัมพันธ์บางอย่างในความซับซ้อนและคุณภาพของการแปลด้วยความซับซ้อนและคุณภาพของตัวอย่างการยิงไม่กี่ตัวอย่าง เป็นผลให้พรอมต์หนึ่งนัดของฉันรวมถึงข้อความสั้น ๆ และการแปลที่สอดคล้องกันจากหนังสือภาษาจีนแปลและเผยแพร่เป็นภาษาอังกฤษ
พรอมต์เดียวของฉันสำหรับ GLM-130B
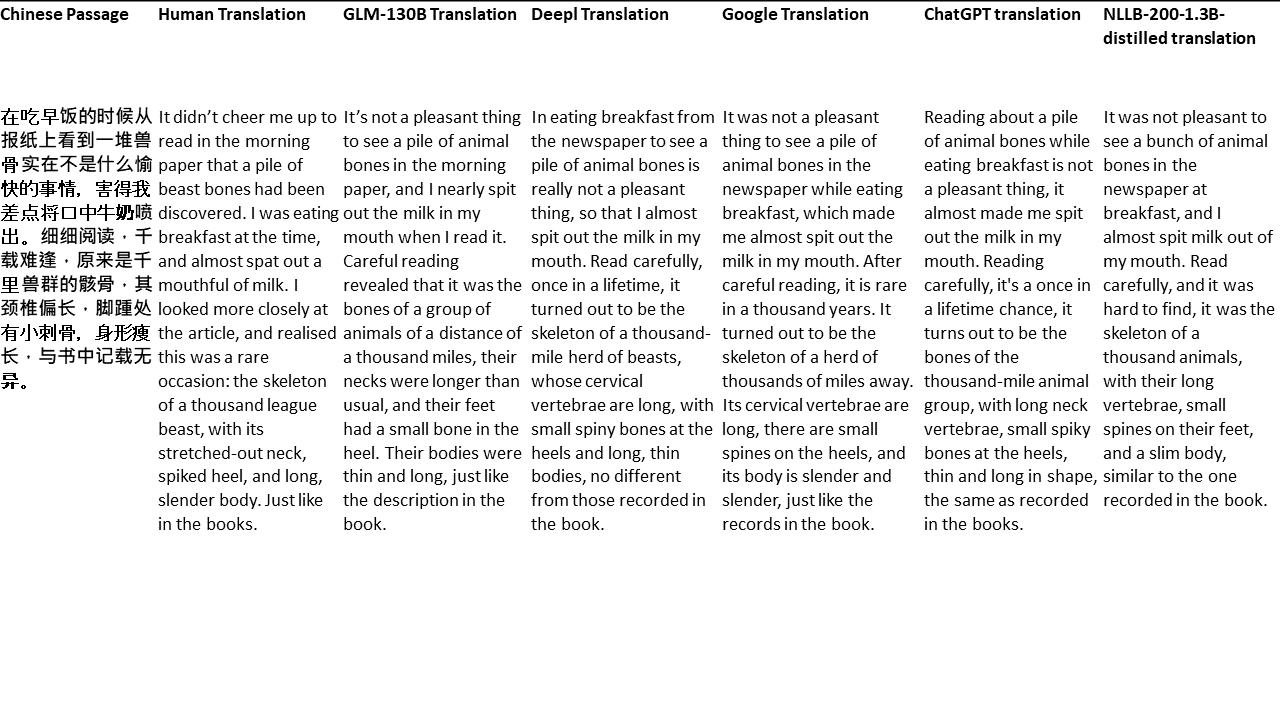
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]พารามิเตอร์เป็นค่าเริ่มต้นยกเว้นสำหรับ
เปิดโมเดล GPT ของ AI เป็นภาษาที่มีอคติภาษาอังกฤษมาก (~ 92.6% ภาษาอังกฤษตามจำนวนคำ) (https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_word_count.csv) อย่างไรก็ตามเนื่องจากความสามารถในภาษาเดียวดูเหมือนว่าจะมีความสามารถในภาษาอื่น ๆ ในระดับที่เพียงพอ (ในความสามารถหลายภาษาของรูปแบบภาษาอังกฤษขนาดใหญ่มาก https: //arxiv.org/abs/2108.13349) ฉันยังรวมการแปลบทสนทนาในการเปรียบเทียบ เนื่องจาก Chatgpt ได้รับการจัดตำแหน่งคำสั่งคำสั่งแปลง่าย ๆ ก็เพียงพอแล้ว คำแนะนำหรือตัวอย่างเฉพาะเพื่อจัดลำดับความสำคัญของความคล่องแคล่วและความลื่นไหลอาจให้ผลลัพธ์ที่ดีขึ้น
ไม่มีภาษาที่เหลืออยู่ข้างหลัง NLLB-200 จาก Meta ได้รับผลงานศิลปะที่ทันสมัยในการวัดมาตรฐานการแปลของเครื่องและเปรียบเทียบกัน
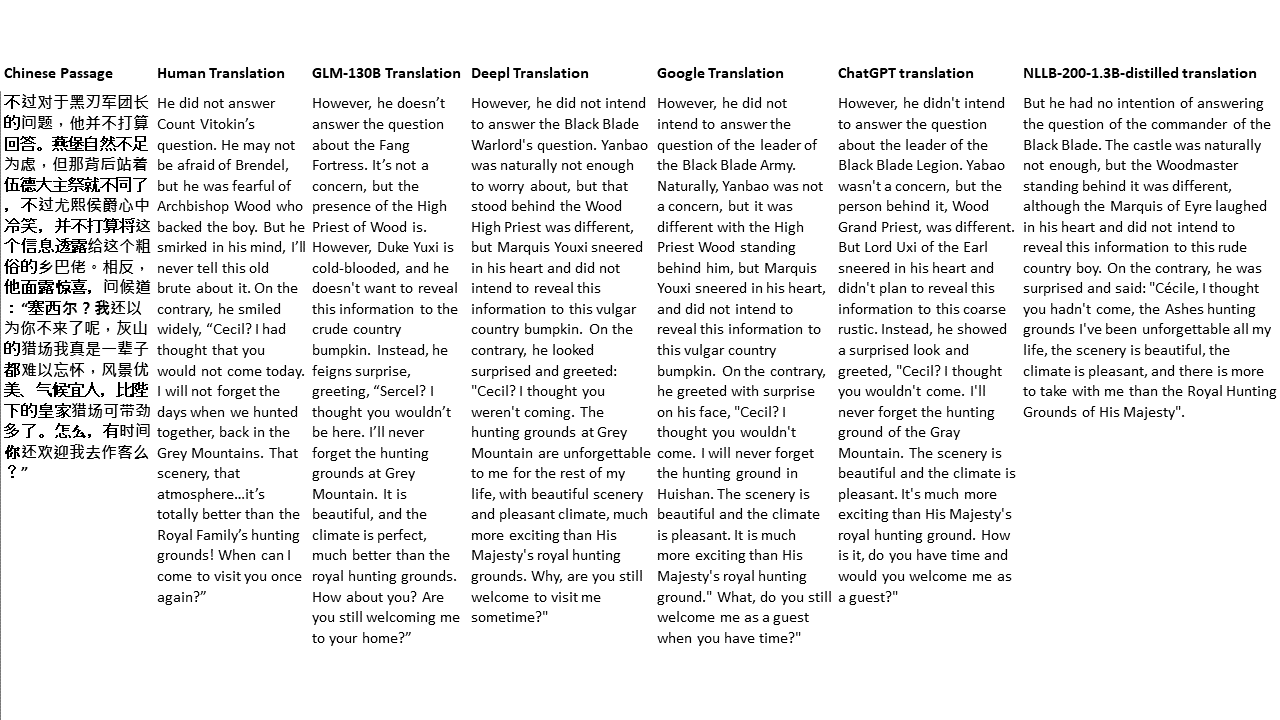
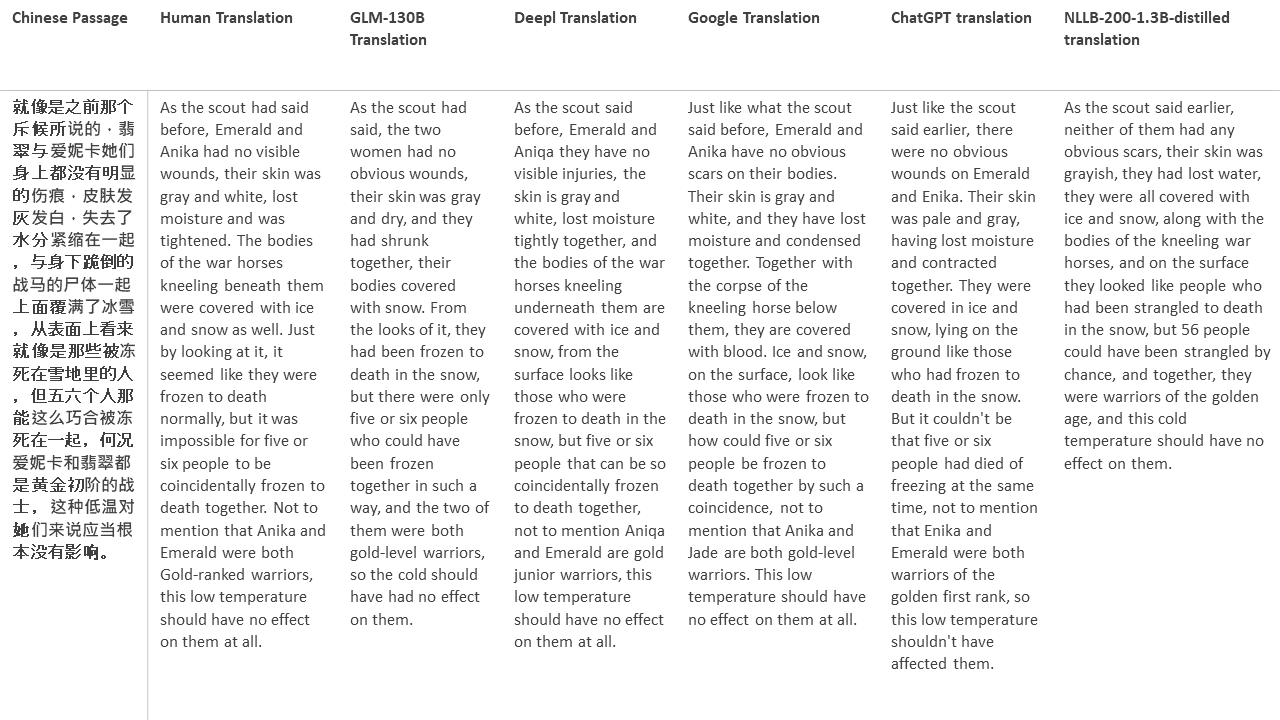
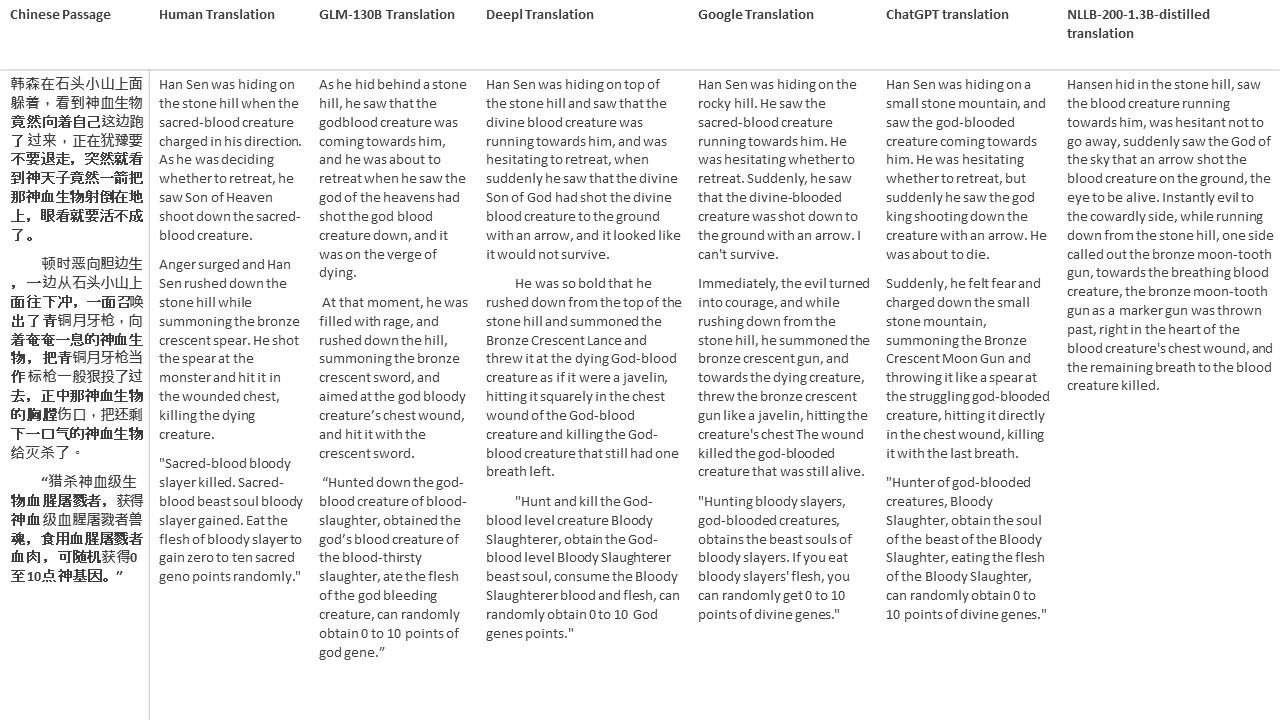
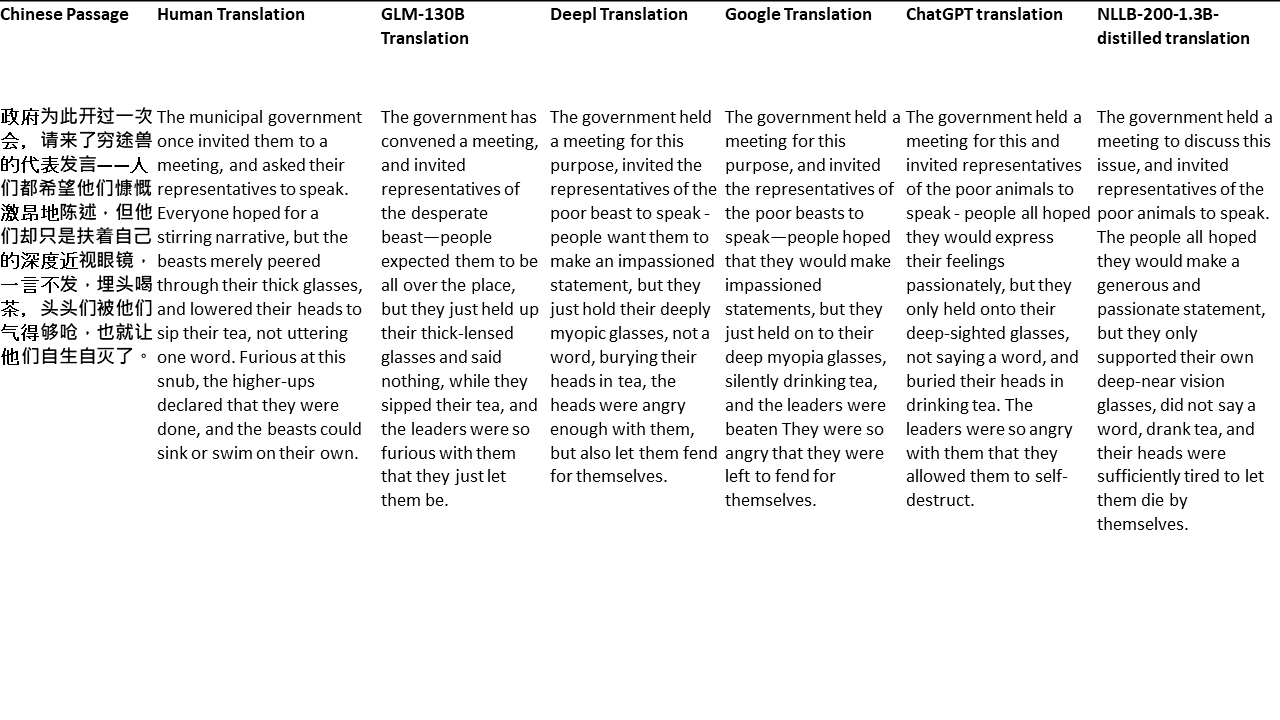
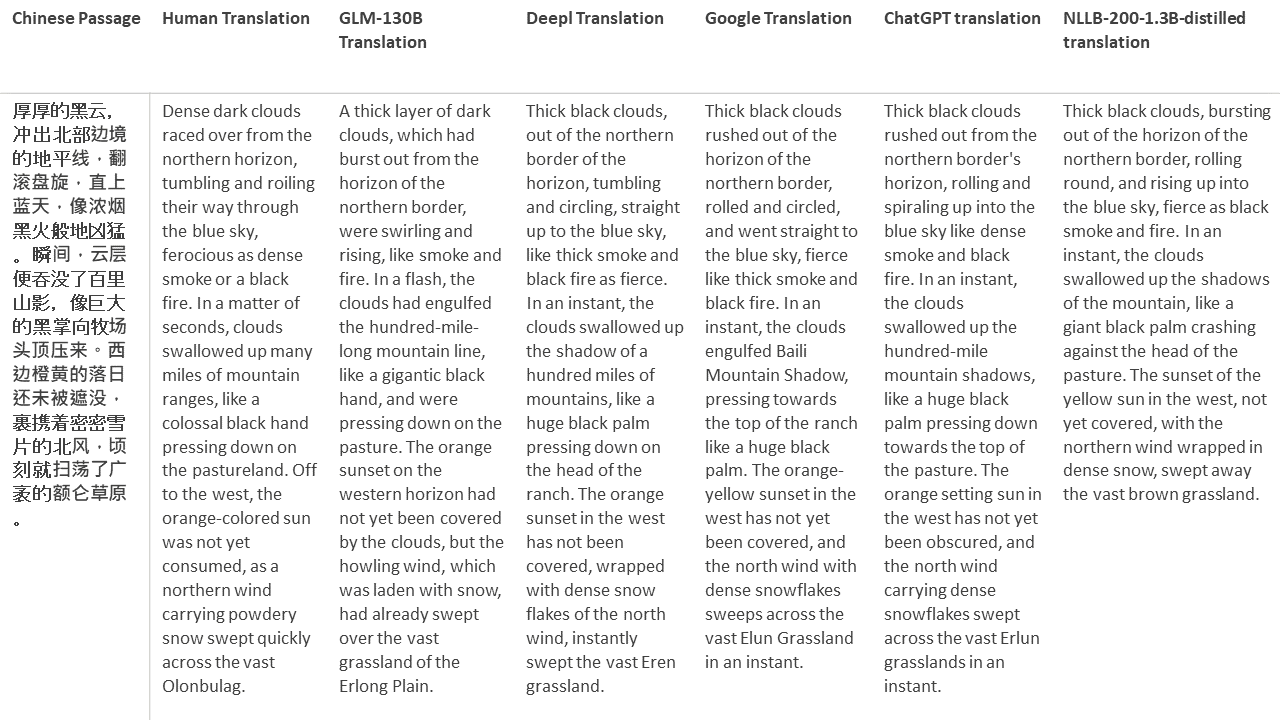
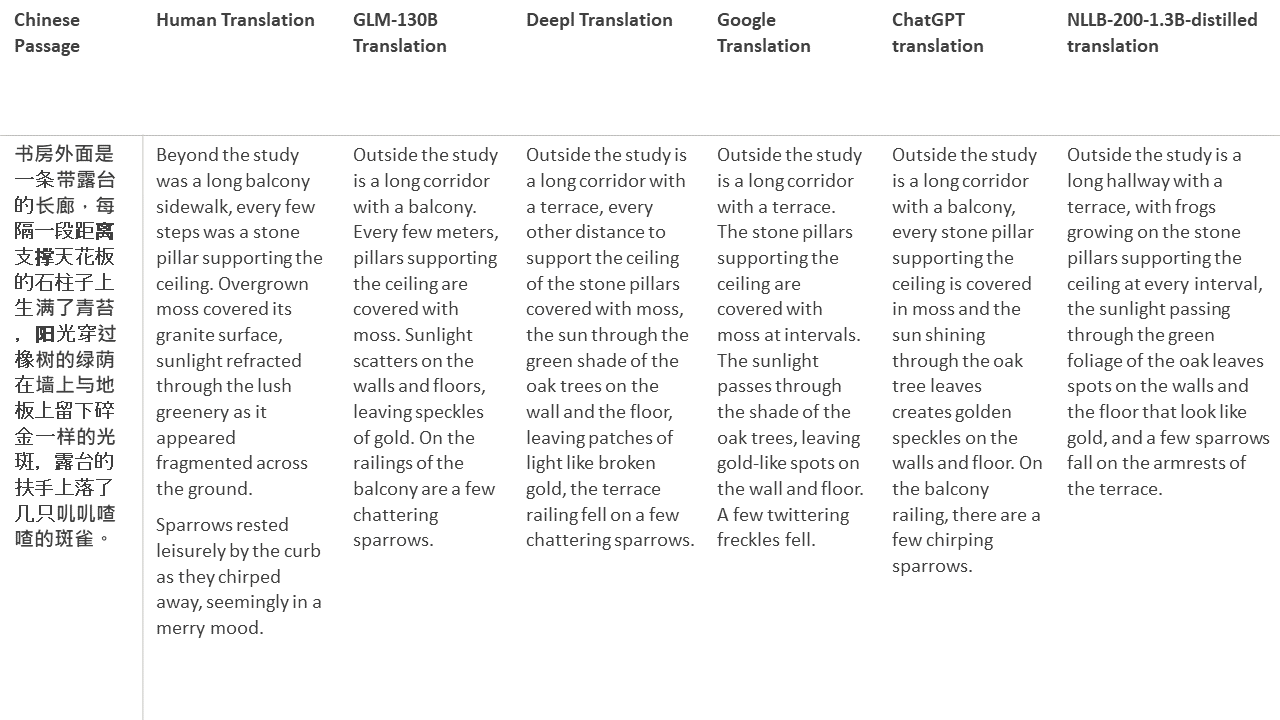
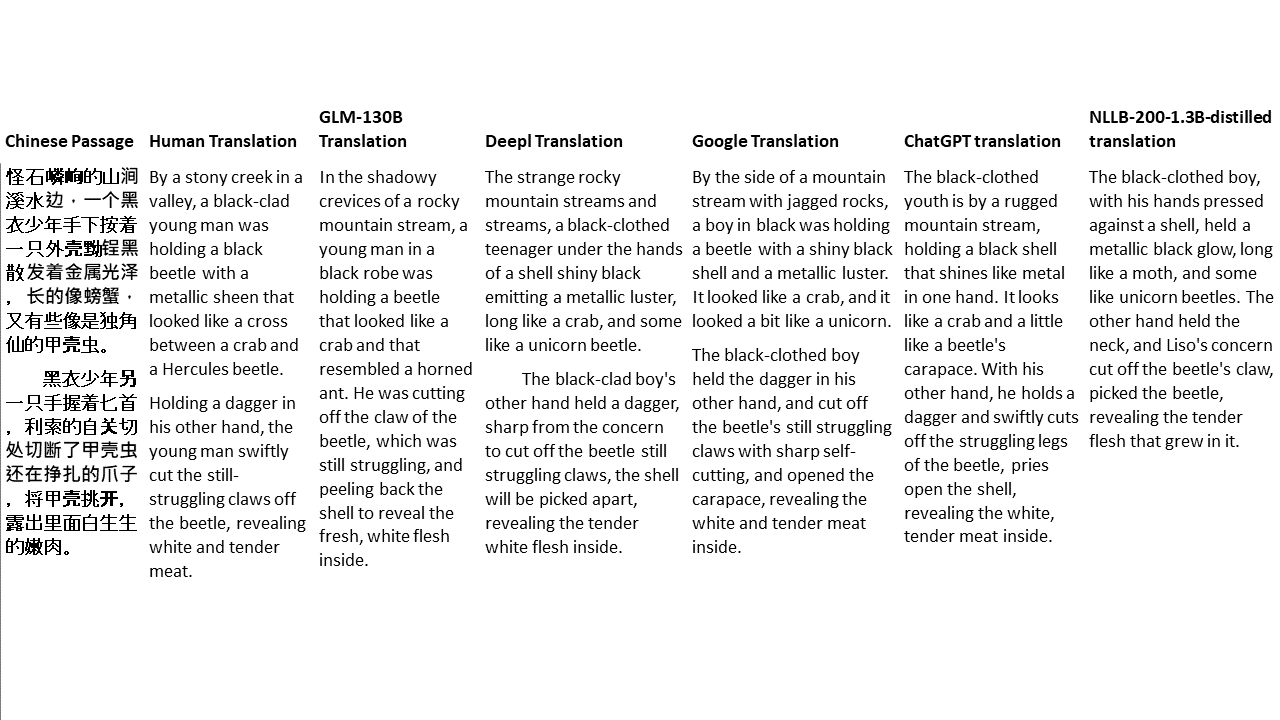
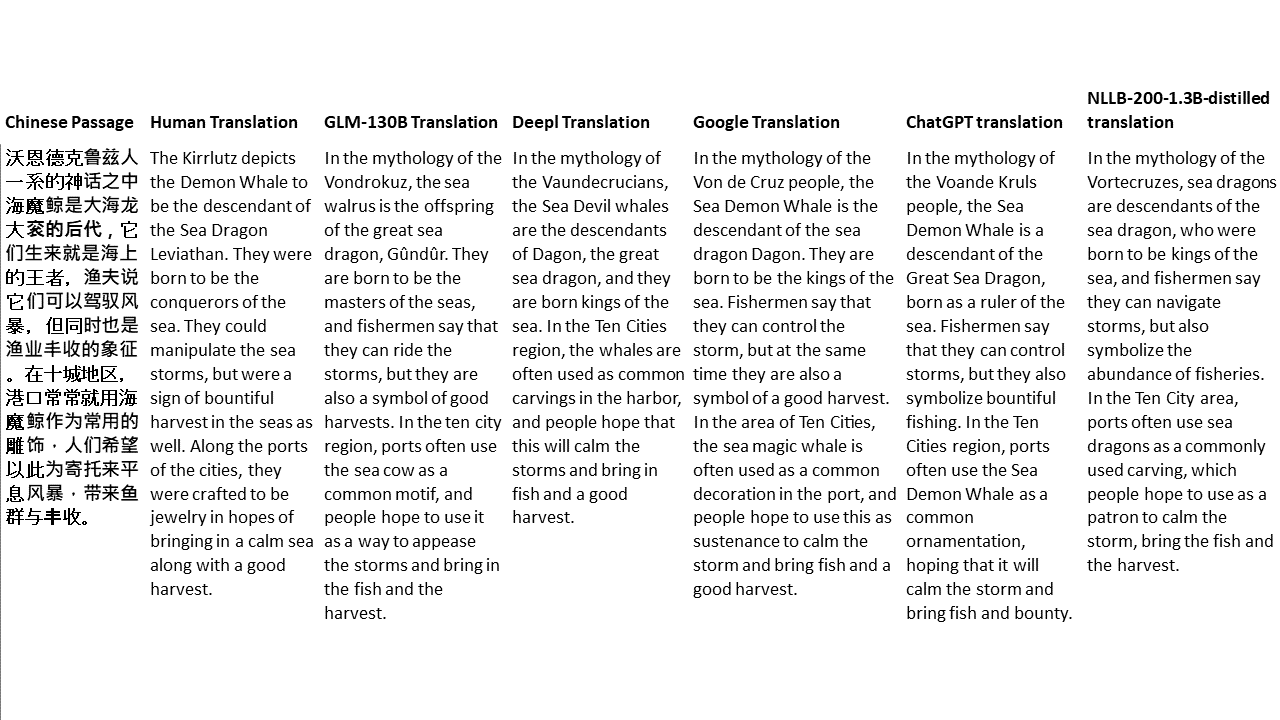
สำหรับการทดสอบของฉันฉันเลือกวรรณกรรมซึ่งเป็นโดเมนที่ยากโดยเฉพาะอย่างยิ่งสำหรับการแปลด้วยเครื่อง 21 ข้อความที่แปลด้วย GLM-130B และเปรียบเทียบกับ Deepl, Google Translate, CHATGPT และ NLLB-200-1.3B-Distilled ข้อความจะถูกสุ่มตัวอย่างจาก 5 นวนิยาย งานแต่งงานโดย Liu Xinwu, Strange Beasts of China โดย Yan Ge, The Amber Sword โดย Fei Yanfu, Wolf Totem โดย Jiang Rong และ Supergene ข้อความถูกเลือกโดยการสุ่ม พวกเขาไม่ได้เป็นเชอร์รี่หรือสร้างใหม่