Human parity on machine translations
1.0.0
Las técnicas tradicionales de aprendizaje automático para abordar la traducción han visto grandes mejoras de última generación en los últimos años. Sin embargo, todavía luchan con idiomas que están muy separados en el árbol genealógico del idioma. Por ejemplo, inglés y chino/coreano/japonés.
Debido a la naturaleza de por qué estos modelos luchan con estas tareas (incapacidad para extrapolar el contexto, gramática tremendamente desajustada, etc.), me pregunté cómo funcionaría un modelo de lenguaje grande previamente prenado (LLM) a escala suficiente entrenada en corpus multilingües. ¿Podría un LLM bilingüe aproximar a un humano bilingüe en las tareas de traducción?
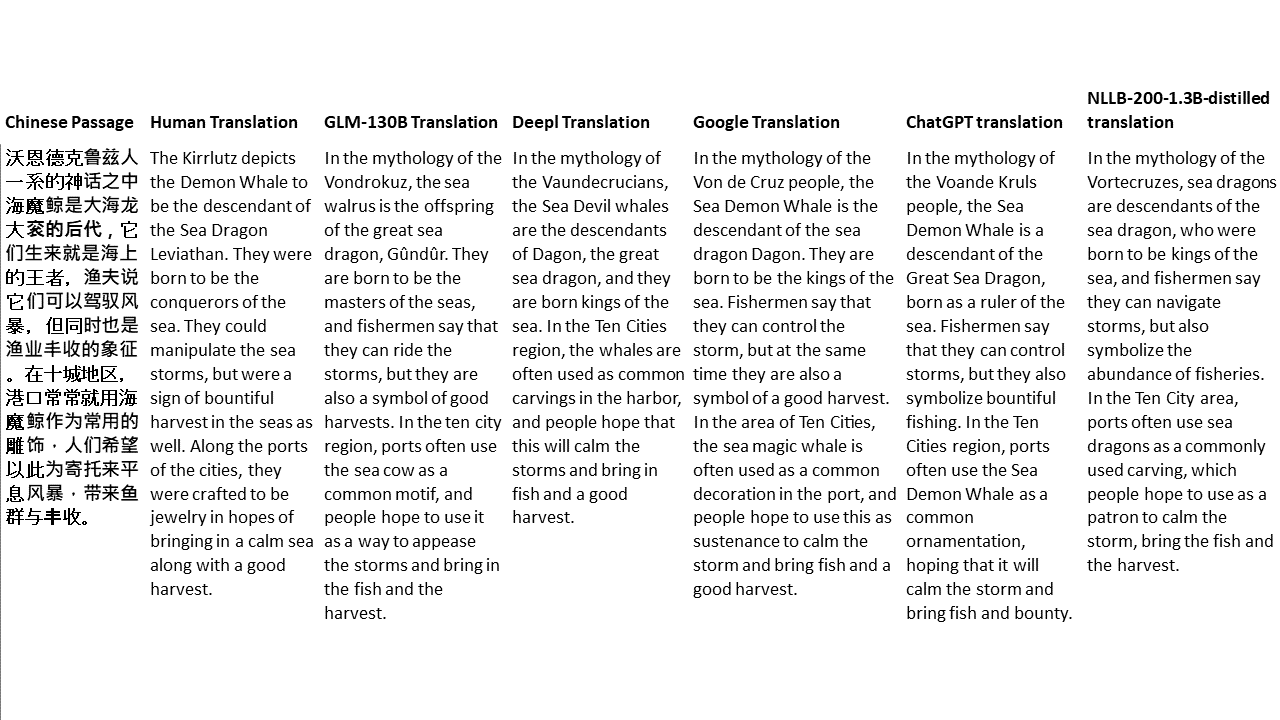
El primer paso, por supuesto, fue elegir un modelo para las pruebas. Hay muy pocos modelos bilingües o multilingües que están entrenados a escala suficiente y que tienen una representación de datos de entrenamiento igual o casi igual para los dos idiomas en cuestión. Agradezco al equipo de Thudm por entrenar y lanzar GLM-130B, un LLM bilingüe entrenado en 200 mil millones de tokens cada uno de inglés y chino (400B total). (https://github.com/thudm/glm-130b).
Este es el modelo principal utilizado para las pruebas. Demo disponible aquí-https://huggingface.co/spaces/thudm/glm-130b porque GLM-130B no es necesario instrucciones, se requiere una estrategia de pocos disparos o de indicación de una sola vez para las traducciones. En las pruebas preliminares, noto cierta correlación en la complejidad y calidad de las traducciones con la complejidad y calidad de pocos ejemplos de disparos. Como resultado, mi mensaje de un solo disparo incluye un pasaje corto y una traducción correspondiente de un libro chino traducido y publicado en inglés.
Mi indicador único para GLM-130B
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]Los parámetros son predeterminados excepto para
Los modelos GPT Open AI son multilingües con un sesgo inglés extremo (~ 92.6% inglés por recuento de palabras) (https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_word_count.csv). Sin embargo, dado que la competencia en un idioma parece sangrar en la competencia en otros idiomas en una LLM de escala suficiente (en las capacidades multilingües de modelos de idiomas en inglés a gran escala https: //arxiv.org/abs/2108.13349), también incluyo traducciones de chatgpt en las comparaciones. Como ChatGPT está alineado con instrucciones, un comando de traducción simple es suficiente y usado. Las instrucciones o ejemplos específicos para priorizar la fluidez y la fluidez pueden generar mejores resultados.
No queda ningún idioma, NLLB-200 de Meta logró resultados de última generación en puntos de referencia de traducción automática y también se compara.
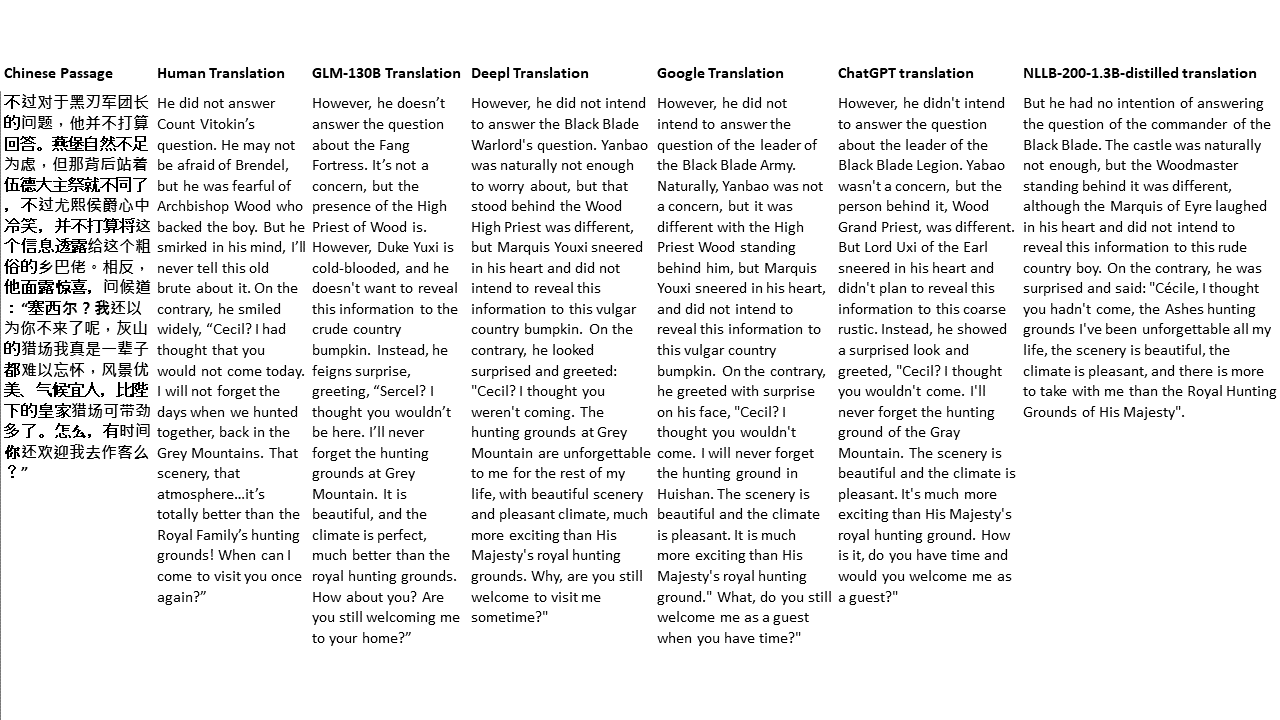
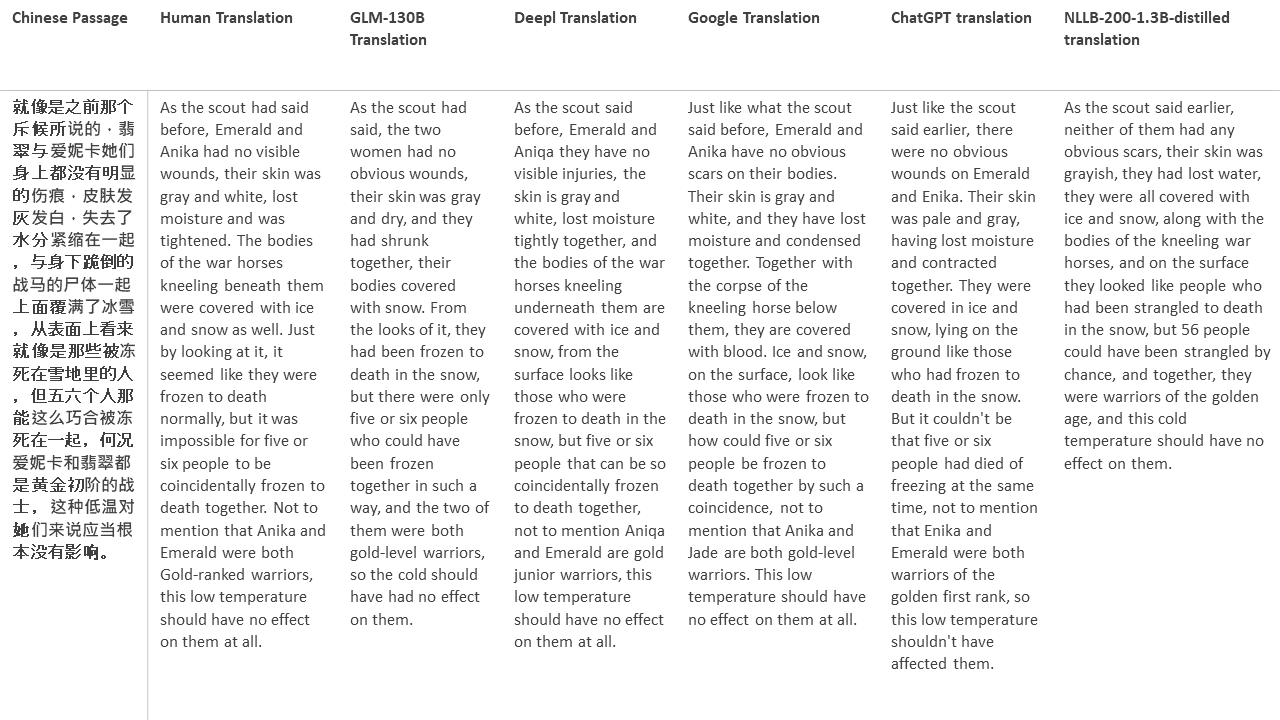
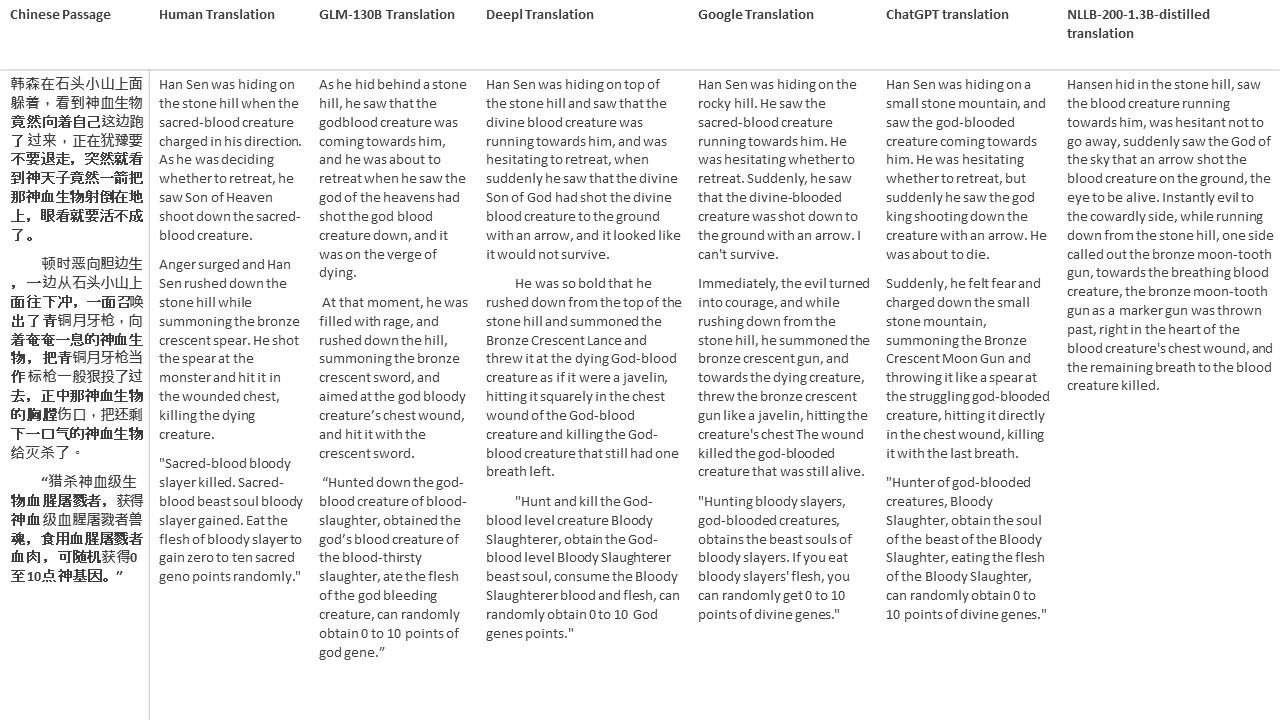
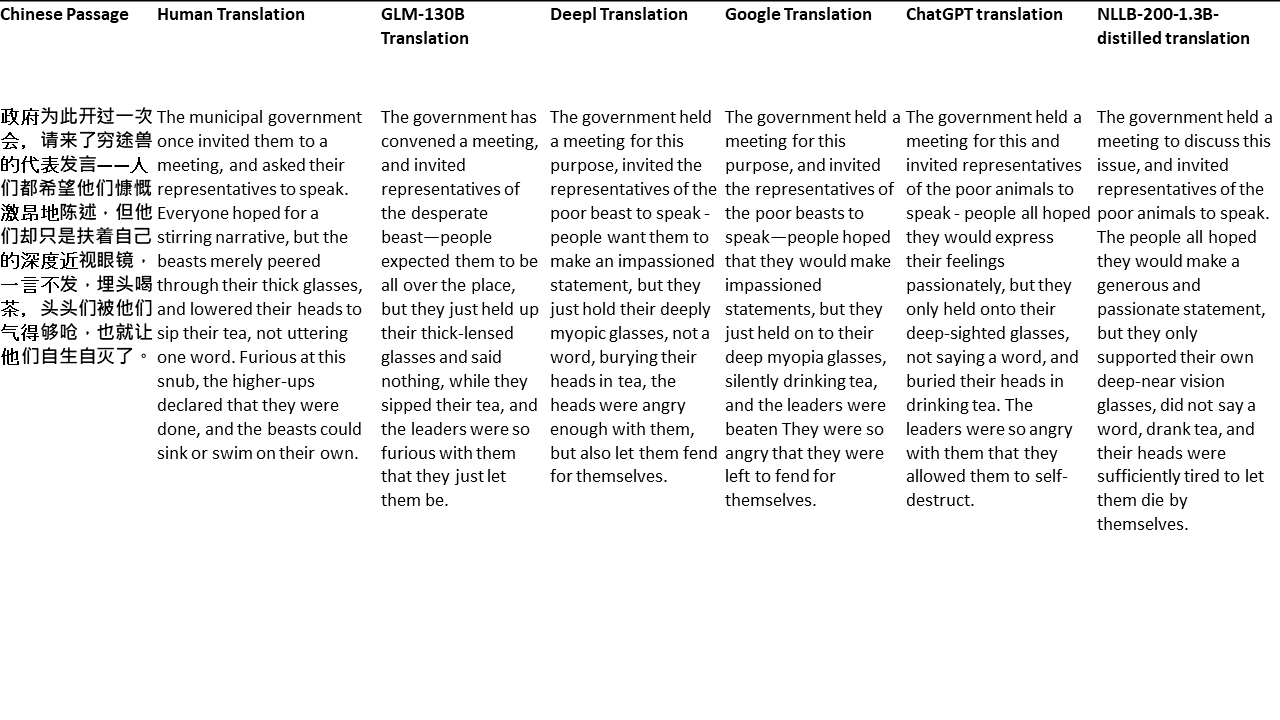
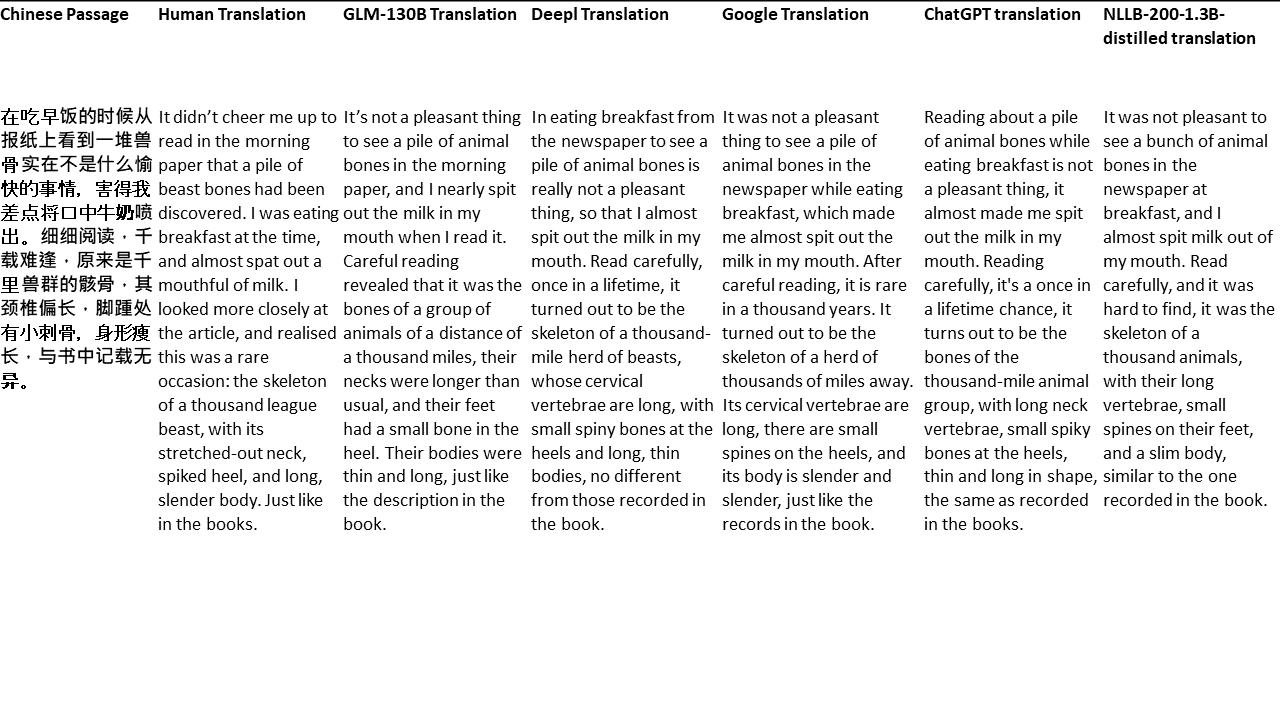
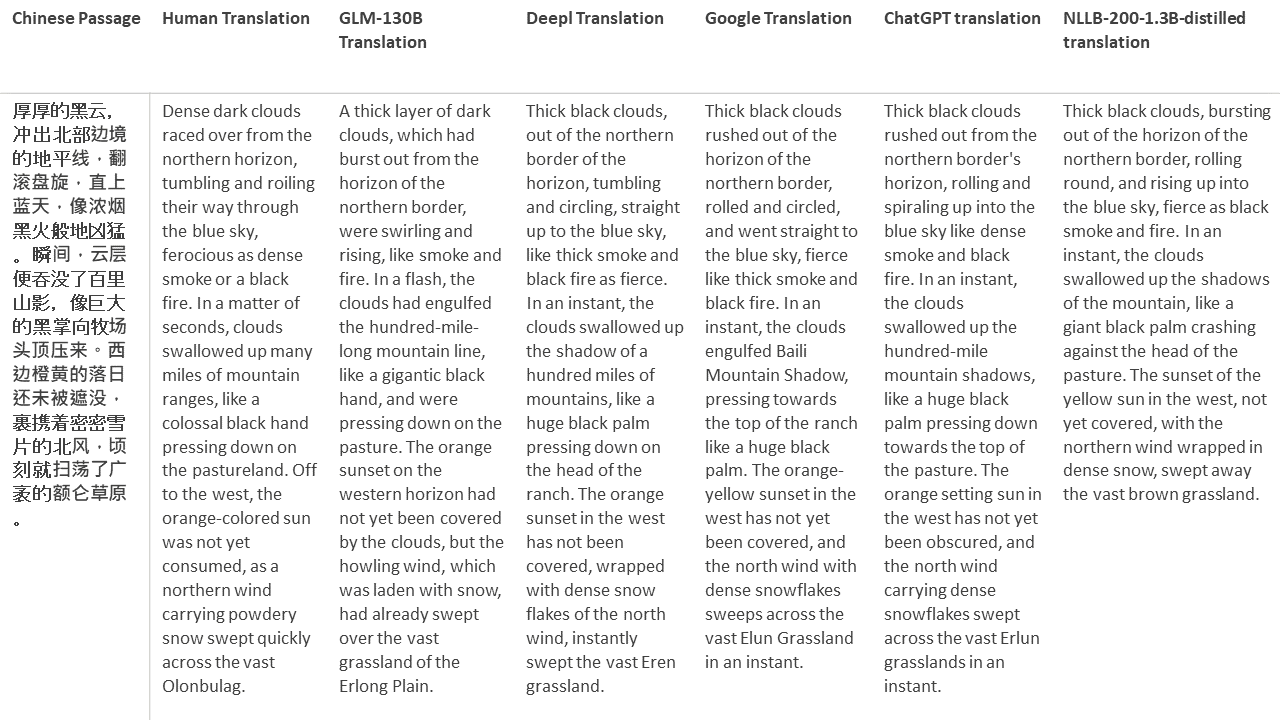
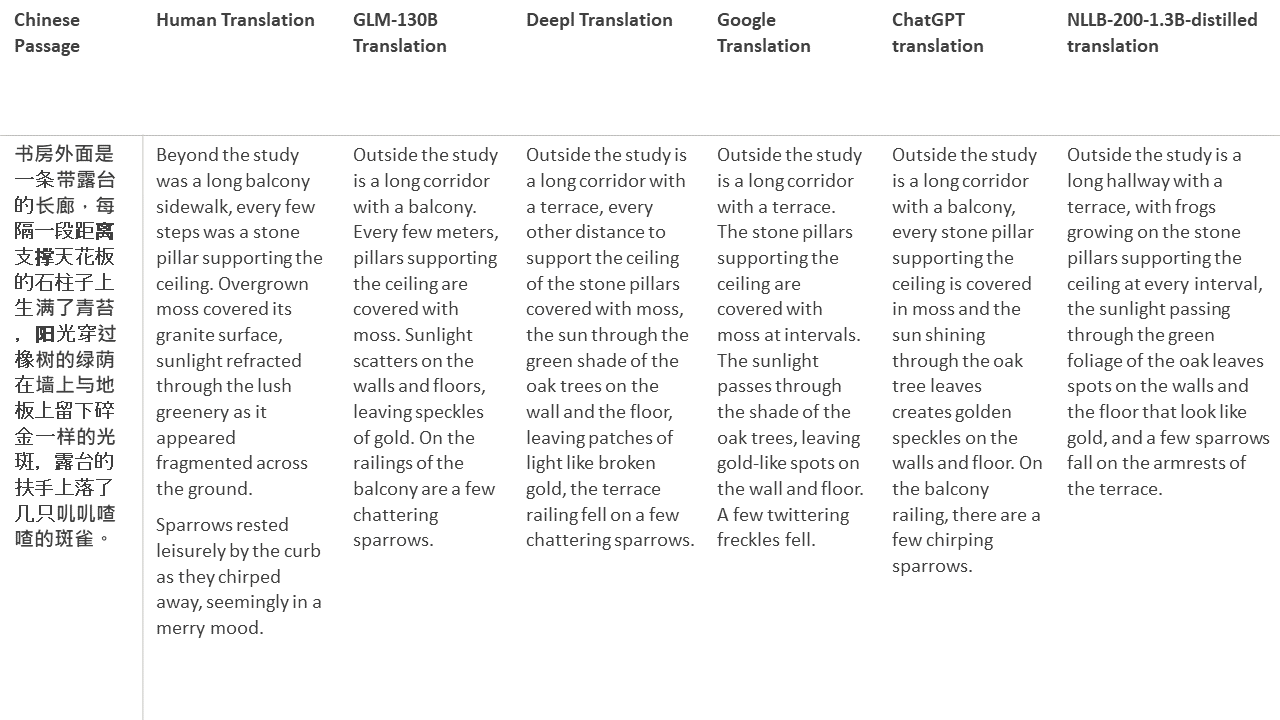
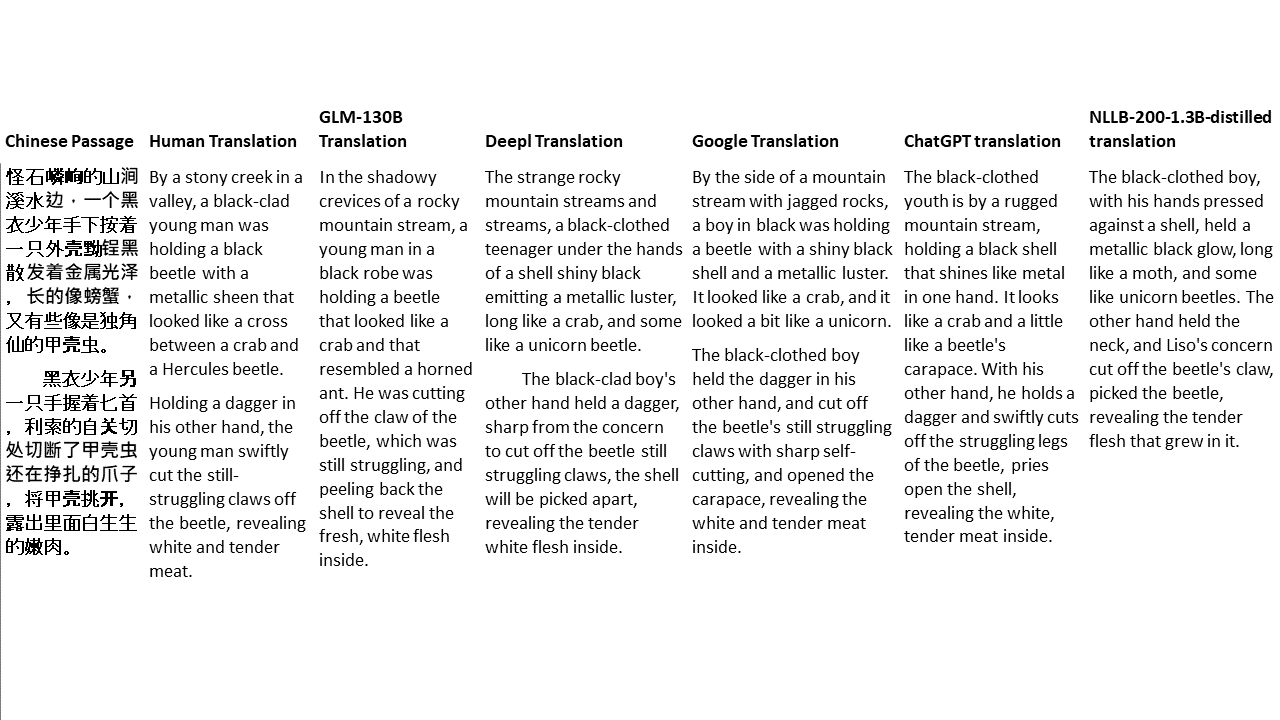
Para mis pruebas, elijo literatura, un dominio especialmente difícil para la traducción automática. 21 pasajes traducidos con GLM-130B y comparados con DeepL, Google Translate, CHATGPT y NLLB-200-1.3B desenterrado. Los pasajes se muestrean de 5 novelas. La fiesta de bodas de Liu Xinwu, Strange Beasts of China de Yan Ge, The Amber Sword de Fei Yanfu, Wolf Totem de Jiang Rong y Supergene. Los pasajes se eligen al azar. No se seleccionan ni se regeneran.