Human parity on machine translations
1.0.0
Traditionelle Techniken für maschinelles Lernen zur Bekämpfung der Übersetzung haben in den letzten Jahren große Stand der Kunstverbesserungen verzeichnet. Sie kämpfen jedoch immer noch mit Sprachen, die sich auf dem Sprachstammbaum weit auseinander befinden. Zum Beispiel Englisch und Chinesisch/Koreanisch/Japanisch.
Aufgrund der Natur, warum diese Modelle mit diesen Aufgaben zu kämpfen haben (Unfähigkeit, den Kontext, eine wild nicht übereinstimmende Grammatik usw. zu extrapolieren), fragte ich mich, wie ein vorgezogenes großes Sprachmodell (LLM) in ausreichendem Maßstab auf mehrsprachigen Korpora geschult wurde. Könnte ein zweisprachiger LLM einen zweisprachigen Menschen bei Übersetzungsaufgaben annähern?
Der erste Schritt bestand natürlich darin, ein Modell zum Testen zu wählen. Es gibt nur sehr wenige zweisprachige oder mehrsprachige Modelle, die beide in ausreichendem Maßstab geschult sind und für die beiden fraglichen Sprachen gleich oder nahezu gleicher Trainingsdatendatenrepräsentation aufweisen. Ich danke dem Team von Thudm für das Training und die Veröffentlichung von GLM-130B, einem zweisprachigen LLM, der auf jeweils 200 Milliarden Token von Englisch und Chinesen trainiert wurde (insgesamt 400B). (https://github.com/thudm/glm-130b).
Dies ist das Hauptmodell, das zum Testen verwendet wird. Demo hier verfügbar-https://huggingface.co/spaces/thudm/glm-130b Da GLM-130b nicht unterrichtsfinetoniert ist, sind nur wenige Shots oder One-Shot-Aufforderungstrategien für Übersetzungen erforderlich. In vorläufigen Tests stelle ich eine gewisse Korrelation in der Komplexität und Qualität von Übersetzungen mit der Komplexität und Qualität einiger Schussbeispiele fest. Infolgedessen enthält meine Ein-Schuss-Eingabeaufforderung eine kurze Passage und eine entsprechende Übersetzung eines chinesischen Buches, das in englischer Sprache übersetzt und veröffentlicht wurde.
Meine One-Shot-Eingabeaufforderung für GLM-130B
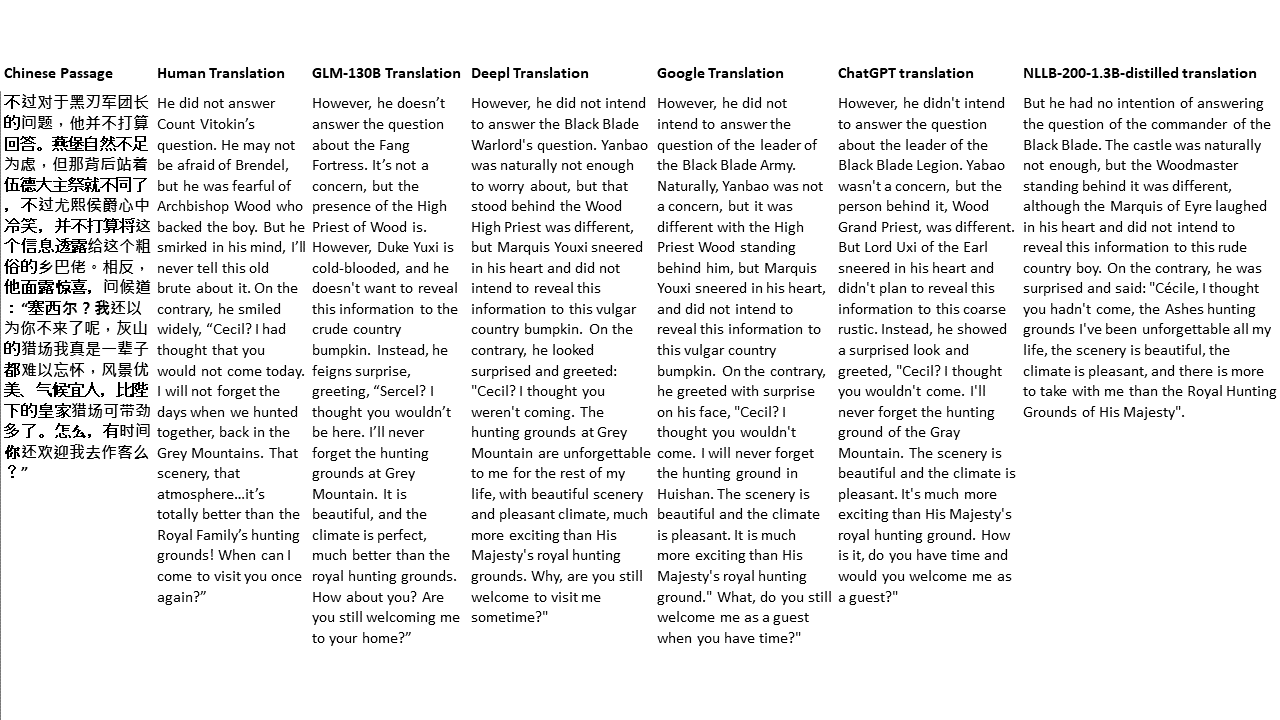
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]Parameter sind Standard ausgesehen von Ausnahme
Open AIs GPT-Modelle sind mehrsprachig mit einer extremen englischen Voreingenommenheit (~ 92.6% Englisch nach Wortanzahl) (https://github.com/openai/gpt-3/blob/master/dataset_statistics/glangages_by_word_count.csv). Da die Kompetenz in einer Sprache in anderen Sprachen in einem LLM aus ausreichendem Maßstab in die Kompetenz zu bleiten scheint (über die mehrsprachigen Funktionen von englischen Sprachmodellen in englischer Sprache-Https: //arxiv.org/abs/2108.13349), schließe ich auch Chatgpt-Übersetzungen in die Vergleiche ein. Da ChatGPT eine Anweisung ausgerichtet ist, ist ein einfacher Übersetzungsbefehl ausreichend und verwendet. Spezifische Anweisungen oder Beispiele zur Priorisierung von Flüssigkeit und Fluidität können zu besseren Ergebnissen führen.
Keine Sprache zurückgelassen, NLLB-200 aus Meta erreichte hochmoderne Ergebnisse zu maschinellen Übersetzungsbenchmarks und wird ebenfalls verglichen.
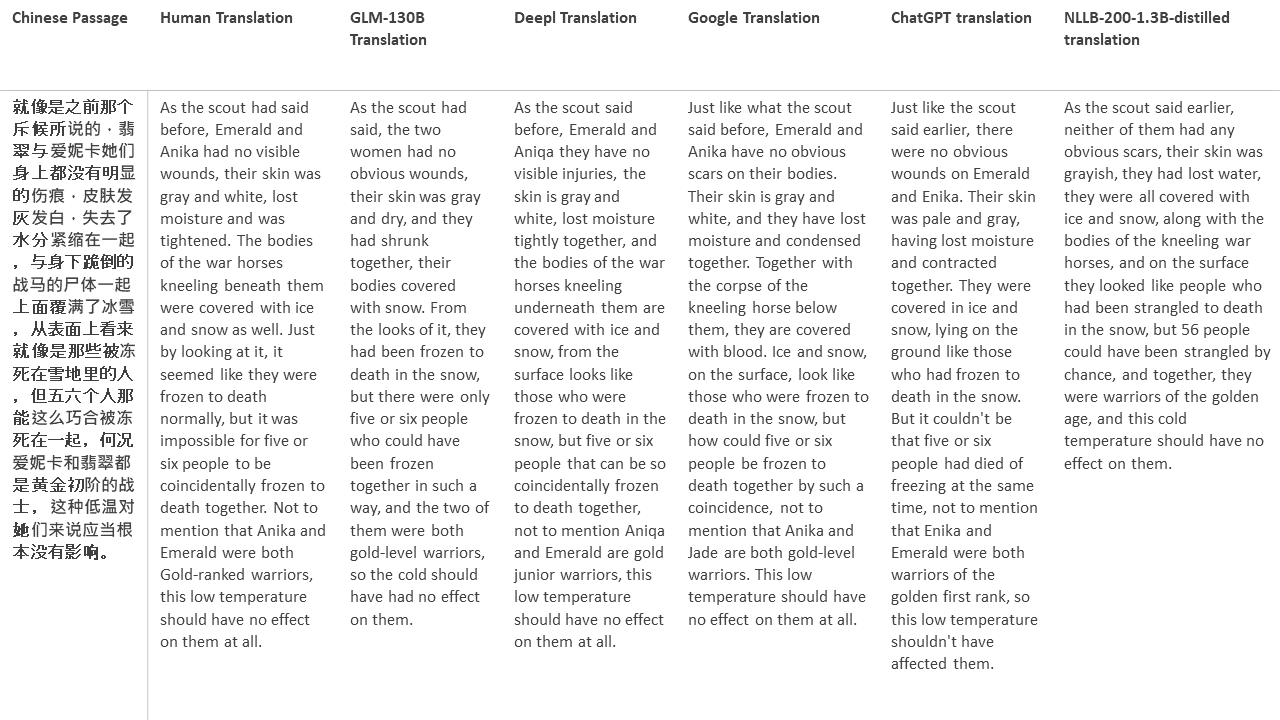
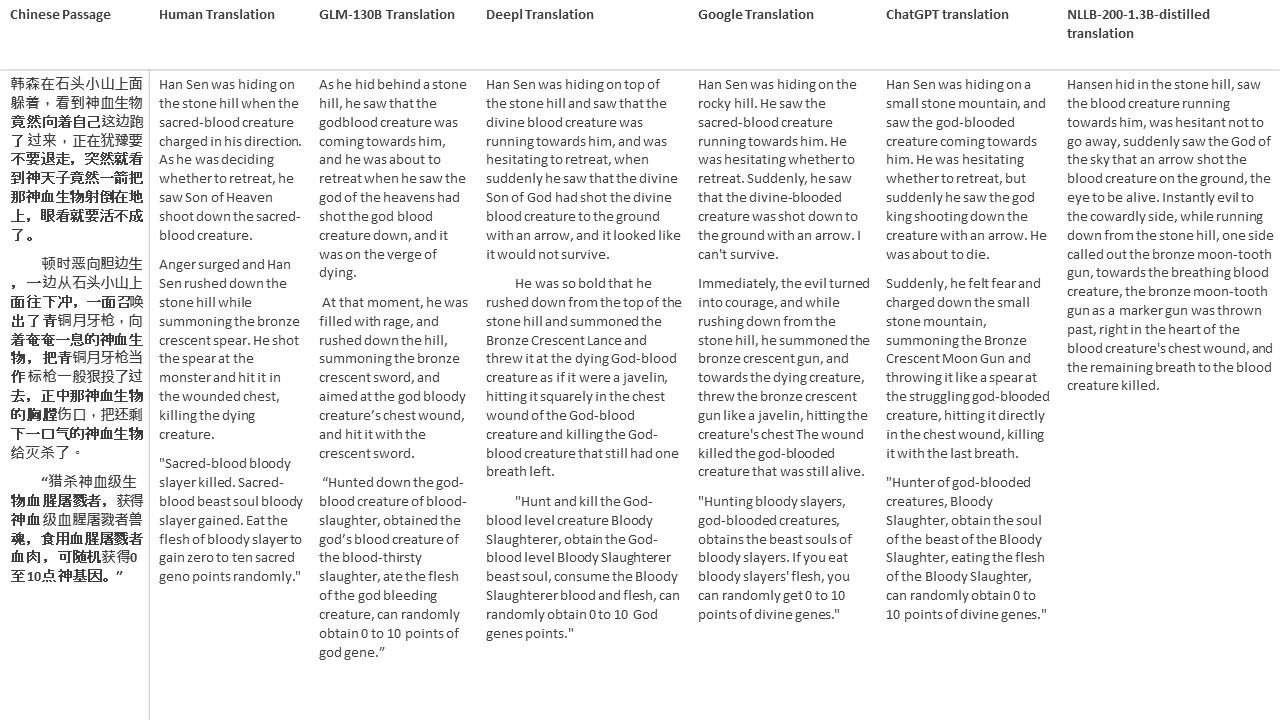
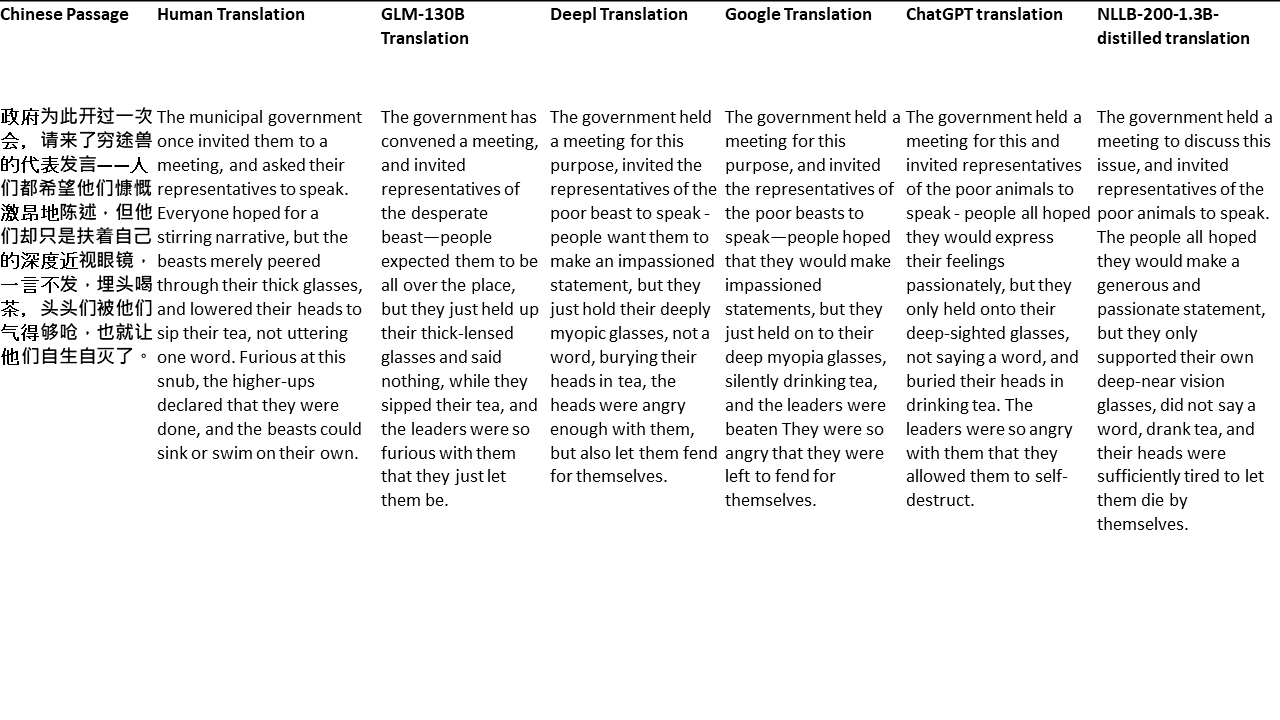
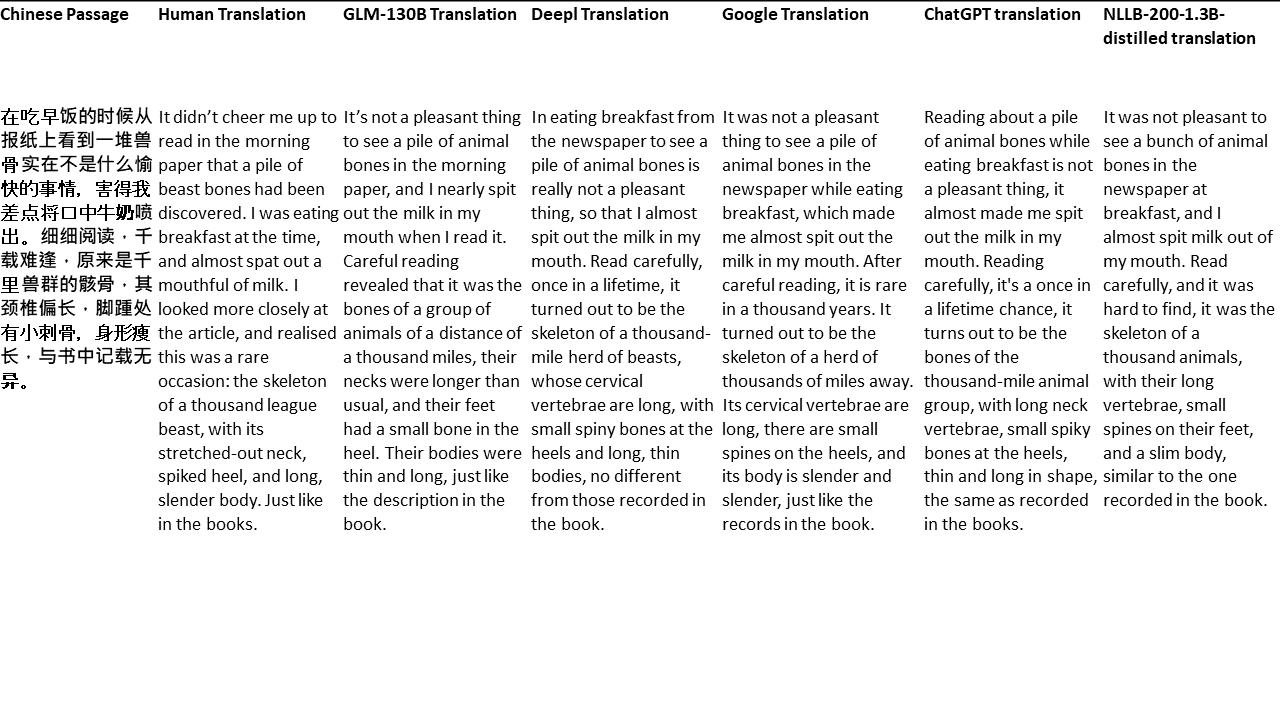
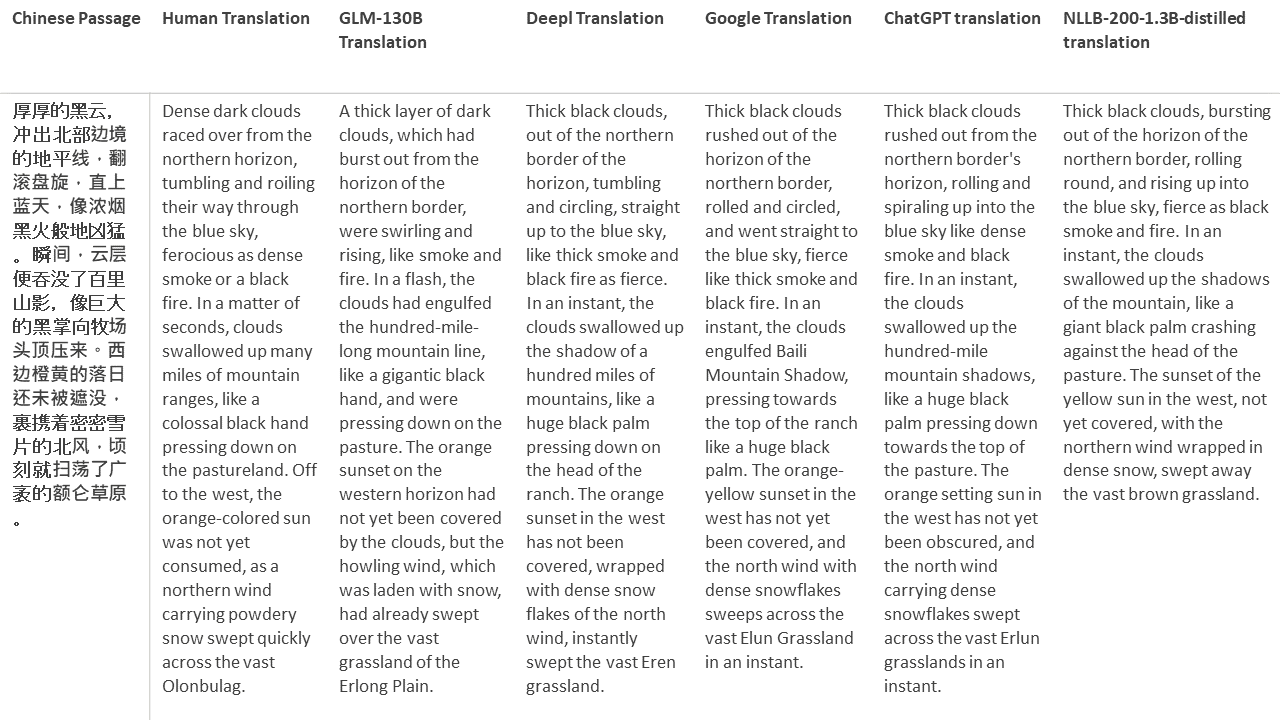
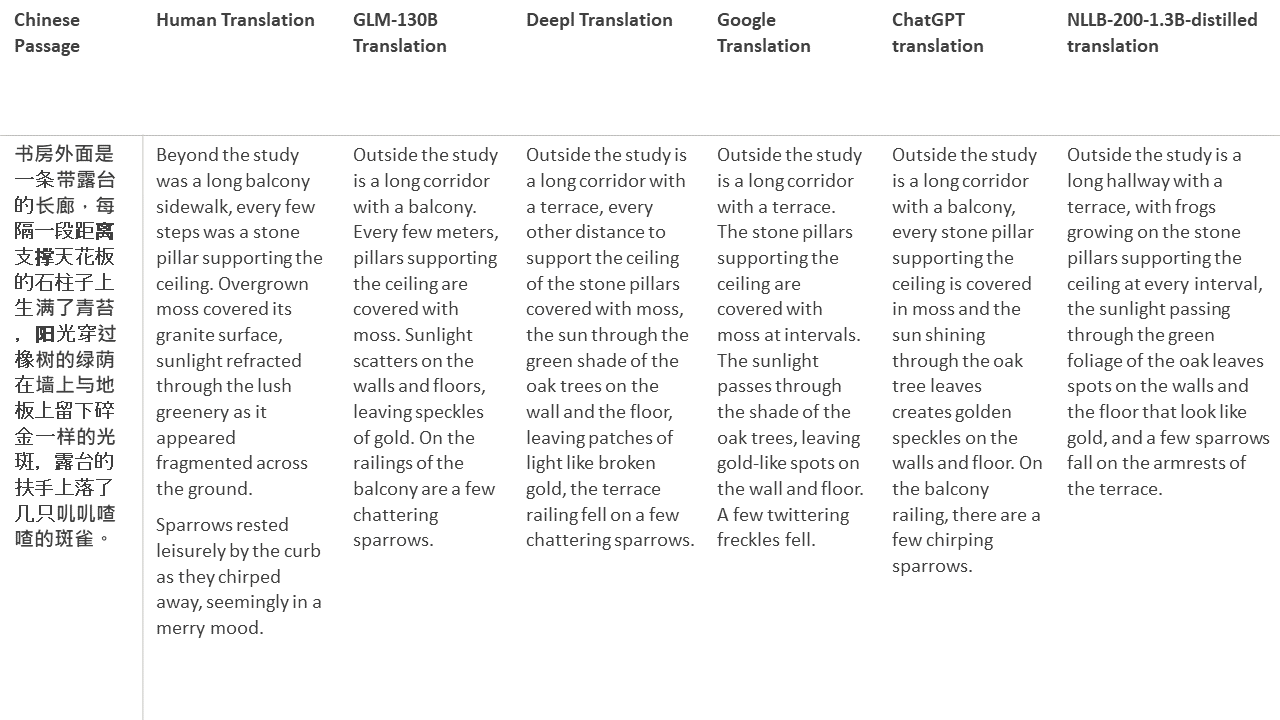
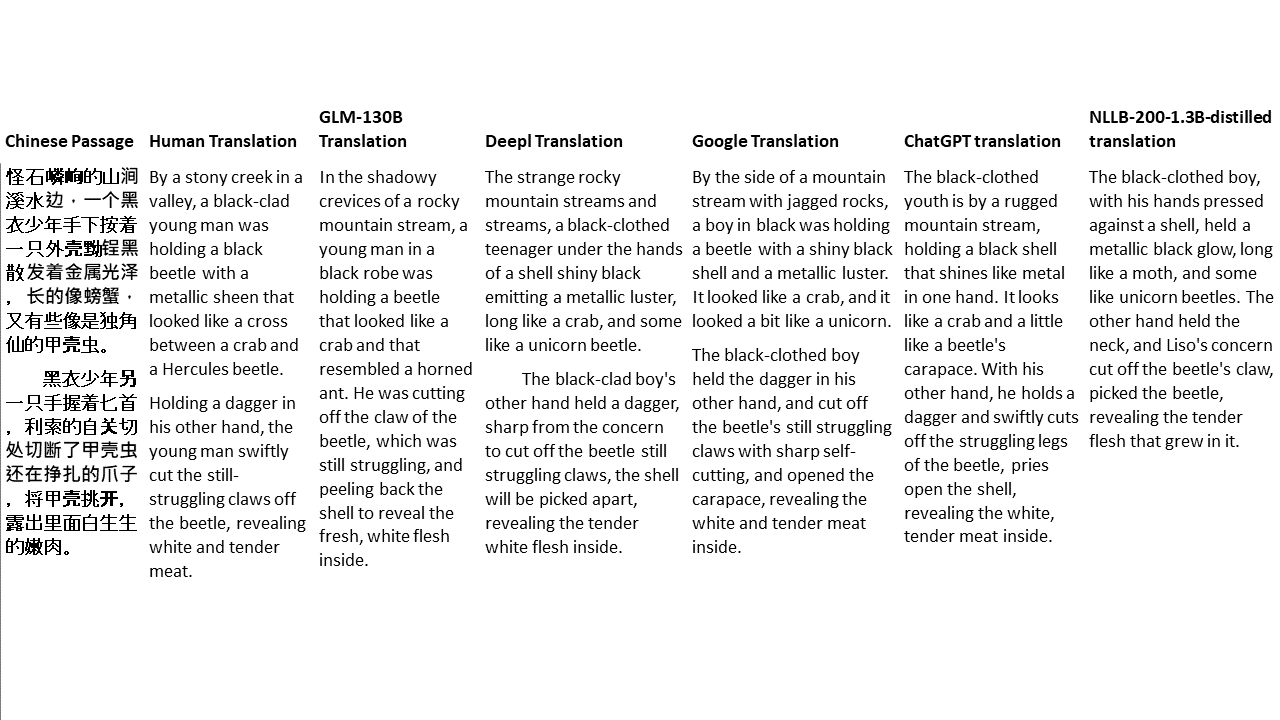
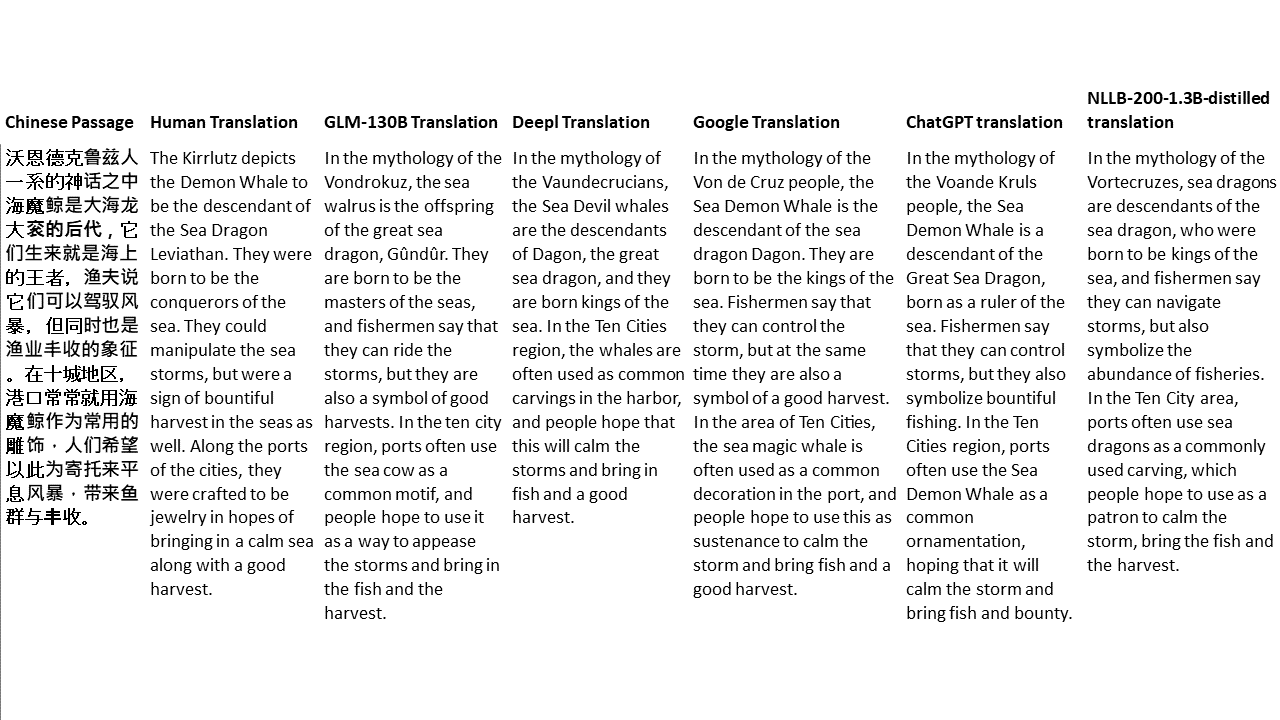
Für meine Tests wähle ich Literatur aus, eine besonders schwierige Domäne für die maschinelle Übersetzung. 21 Passagen übersetzt mit GLM-130B und verglichen mit Deeptl, Google Translate, ChatGPT und NLLB-200-1.3b destilliert. Die Passagen stammen aus 5 Romanen. Die Hochzeitsfeier von Liu Xinwu, seltsame Tiere Chinas von Yan Ge, The Amber Sword von Fei Yanfu, Wolf Totem von Jiang Rong und Supergene. Die Passagen werden zufällig ausgewählt. Sie sind nicht kirschend oder regeneriert.