Human parity on machine translations
1.0.0
Les techniques traditionnelles d'apprentissage automatique pour lutter contre la traduction ont connu une grande amélioration de la pointe de l'art au cours des dernières années. Cependant, ils luttent toujours avec des langues éloignées de l'arbre généalogique des langues. Par exemple, anglais et chinois / coréen / japonais.
En raison de la nature de la raison pour laquelle ces modèles luttent avec ces tâches (incapacité à extrapoler le contexte, une grammaire sauvage, etc.), je me demandais comment un modèle de grande langue pré-entraîné (LLM) à une échelle suffisante formés sur les corpus multilingues se produirait. Un LLM bilingue pourrait-il approximer un humain bilingue sur les tâches de traduction?
La première étape a bien sûr été de choisir un modèle de test. Il existe très peu de modèles bilingues ou multilingues qui sont tous deux formés à une échelle suffisante et ont une représentation de données de formation égale ou presque égale pour les deux langues en question. Je remercie l'équipe de Thudm pour la formation et la sortie du GLM-130b, un LLM bilingue formé sur 200 milliards de jetons chacun d'anglais et de chinois (400b au total). (https://github.com/thudm/glm-130b).
Il s'agit du modèle principal utilisé pour les tests. Demo disponible ici - https://huggingface.co/spaces/thudm/glm-130b parce que GLM-130B n'est pas d'instruction-fintuned, une stratégie d'incitation à quelques coups ou à un coup pour des traductions est nécessaire. Dans les tests préliminaires, je remarque une certaine corrélation dans la complexité et la qualité des traductions avec la complexité et la qualité de quelques exemples de tir. En conséquence, mon invite à un coup comprend un court passage et une traduction correspondante d'un livre chinois traduit et publié en anglais.
Mon invite à un coup pour GLM-130B
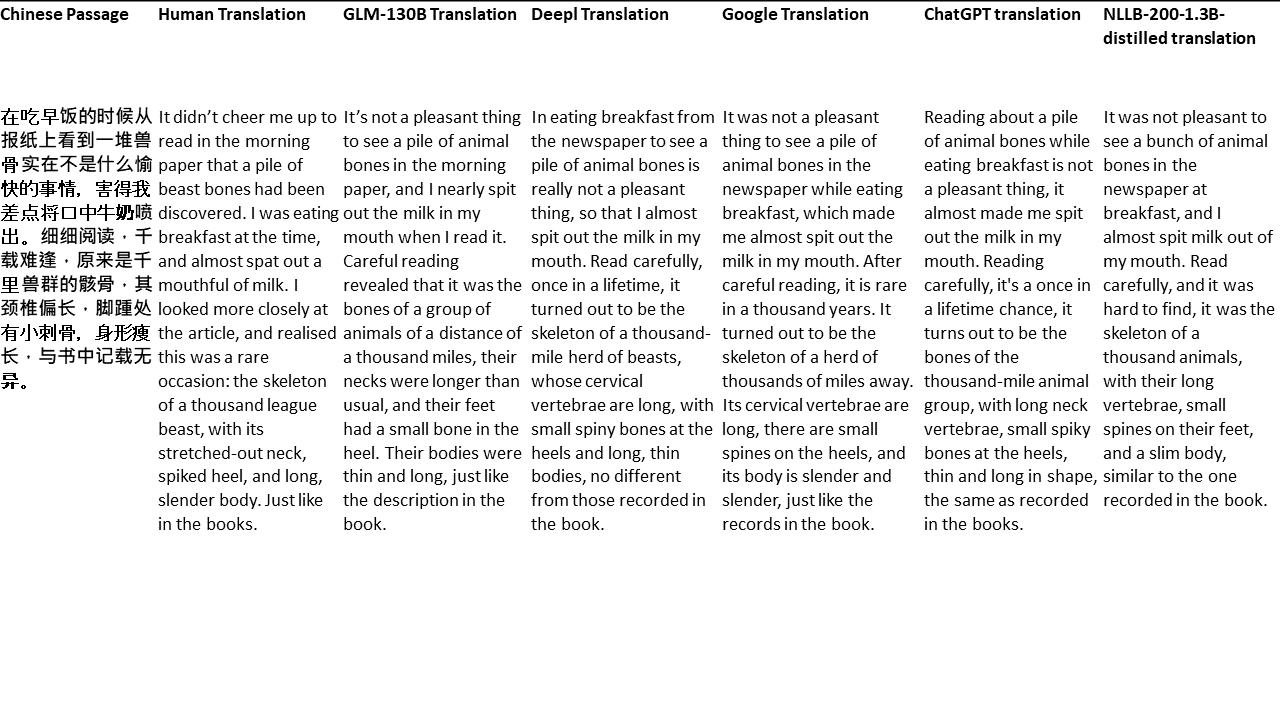
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]Les paramètres sont par défaut, sauf
Les modèles GPT d'Open AI sont multilingues avec un biais anglais extrême (~ 92,6% anglais par Word Count) (https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_word_count.csv). Cependant, puisque la compétence dans une langue semble saigner en compétence dans d'autres langues dans une LLM d'une échelle suffisante (sur les capacités multilingues de modèles de langue anglaise à très grande échelle-https: //arxiv.org/abs/2108.13349), j'inclut également les traductions de chatpt dans les comparaisons. Comme Chatgpt est aligné par l'instruction, une commande simple traduisée est suffisante et utilisée. Des instructions ou des exemples spécifiques pour hiérarchiser la maîtrise et la fluidité peuvent donner de meilleurs résultats.
Aucune langue laissée derrière, NLLB-200 de Meta a obtenu des résultats de pointe sur les références de traduction automatique et est également comparé.
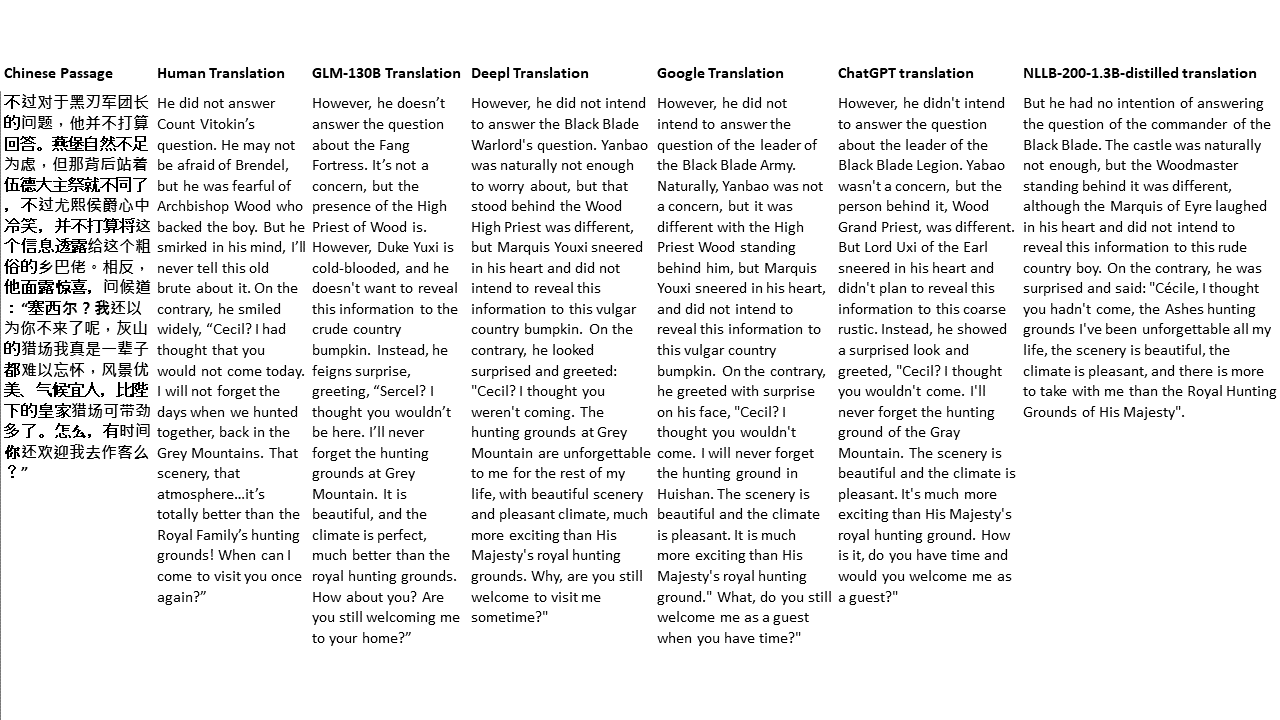
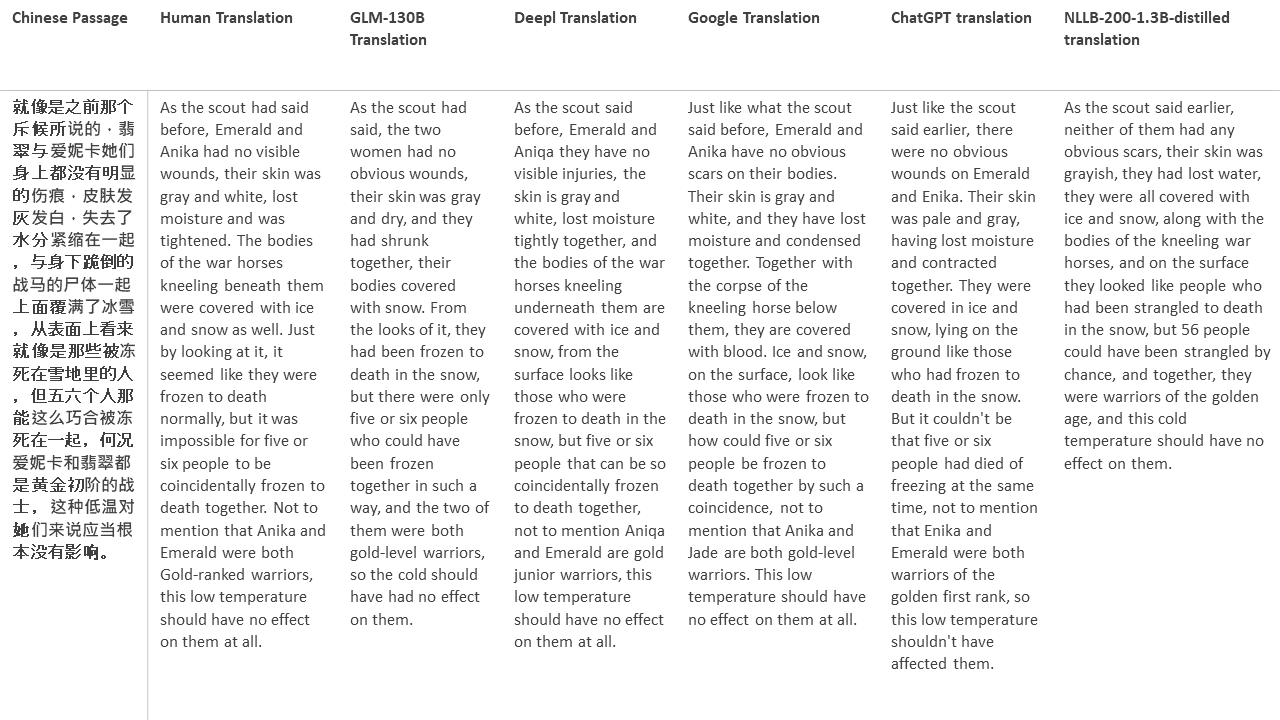
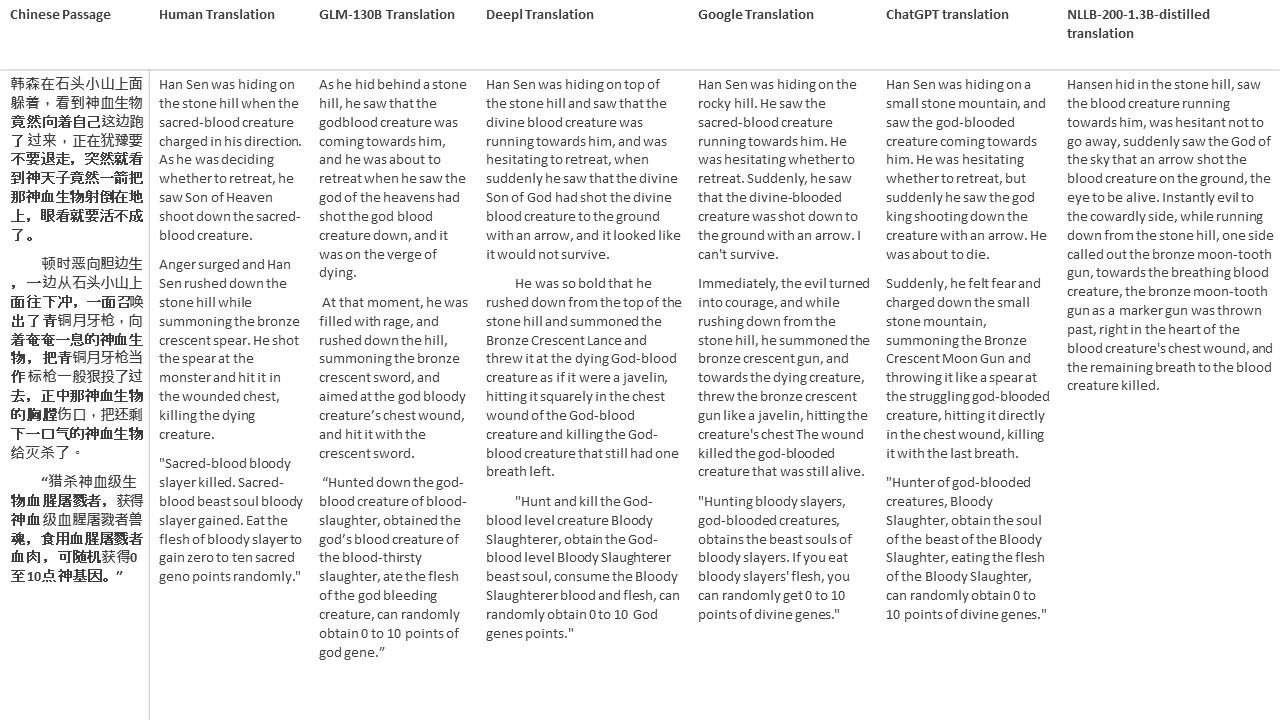
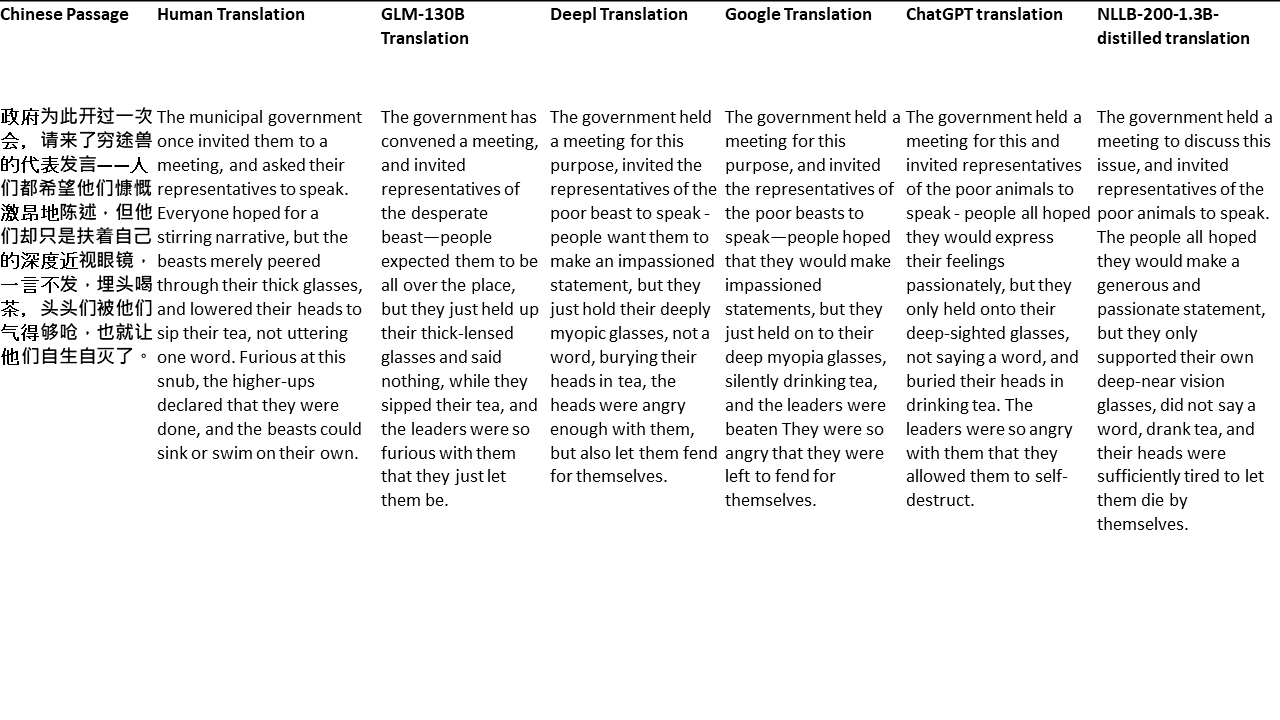
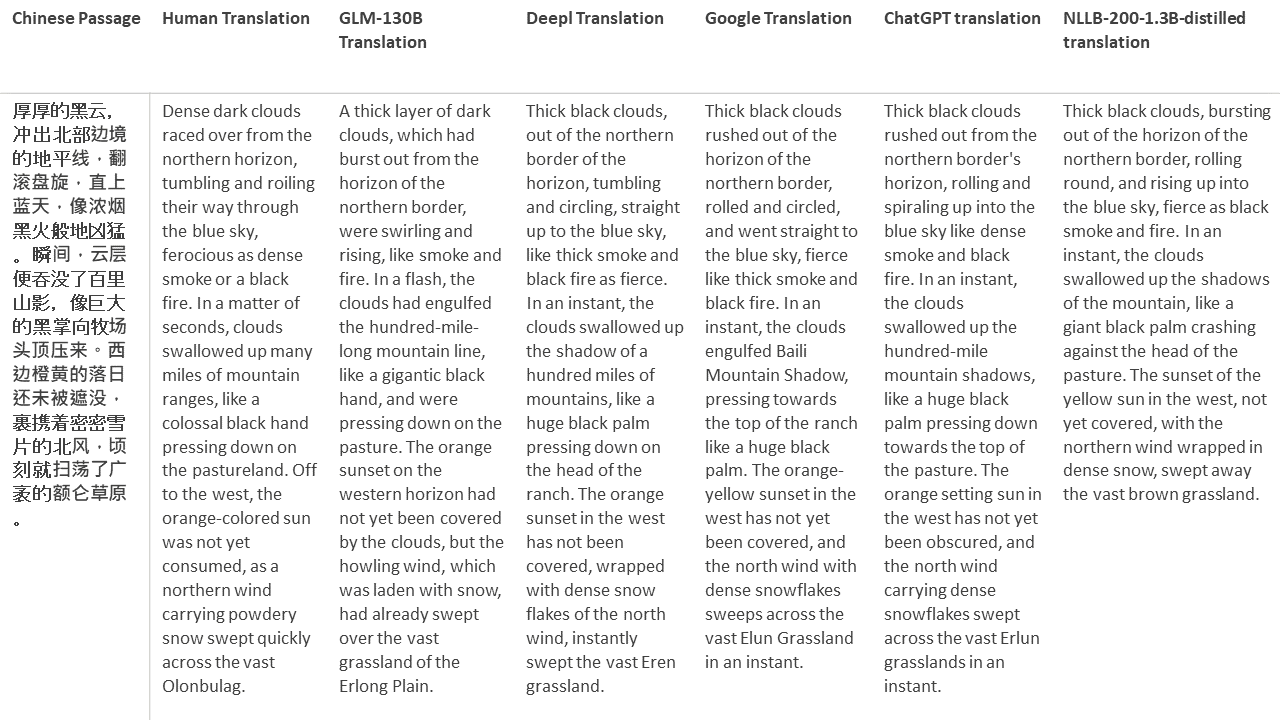
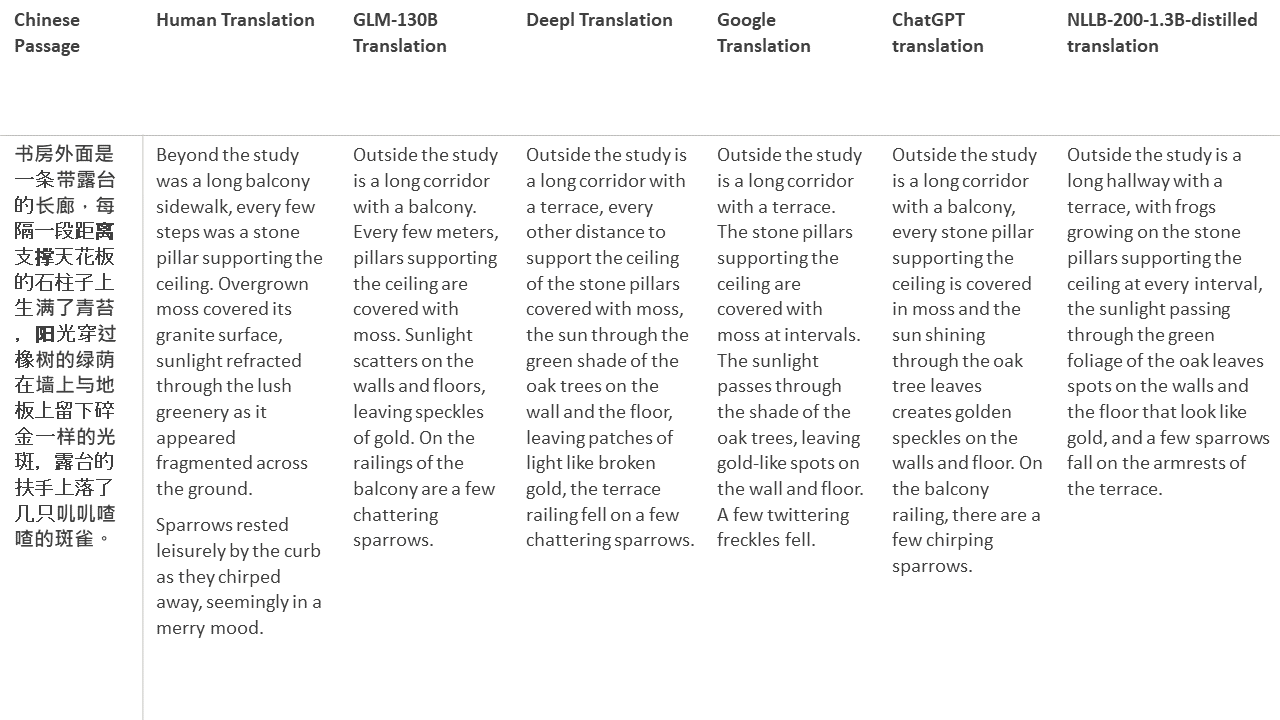
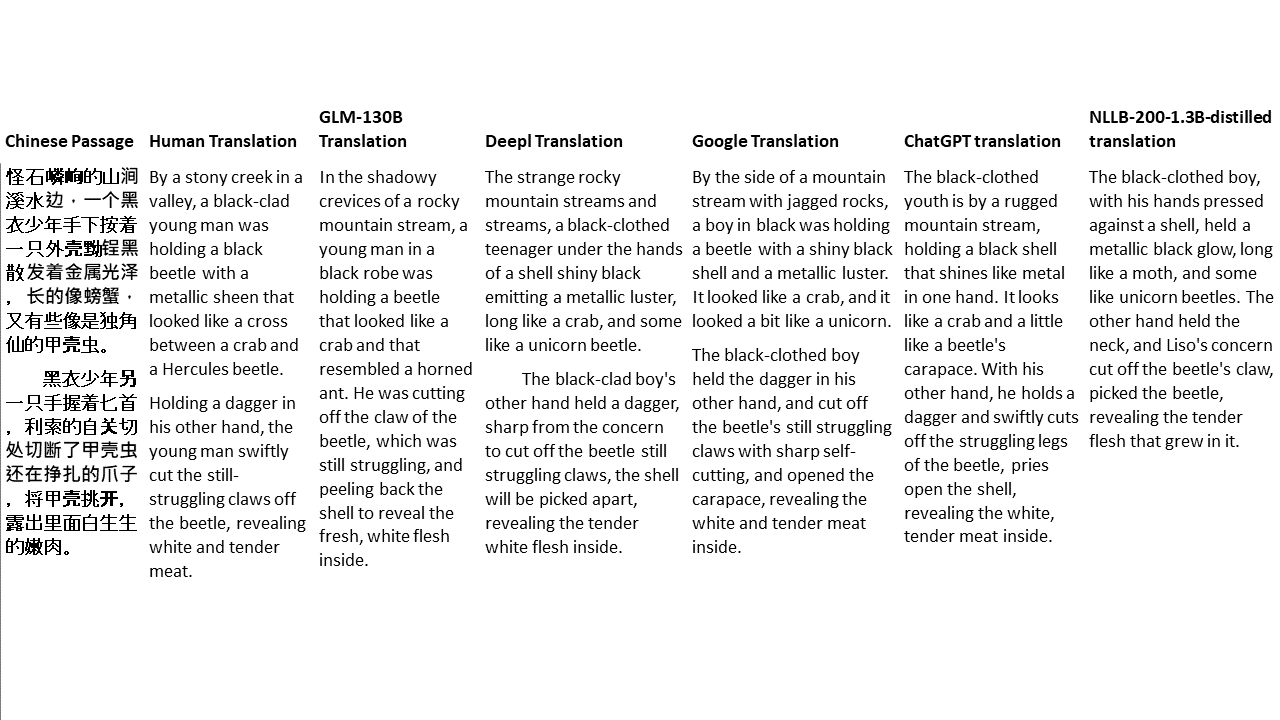
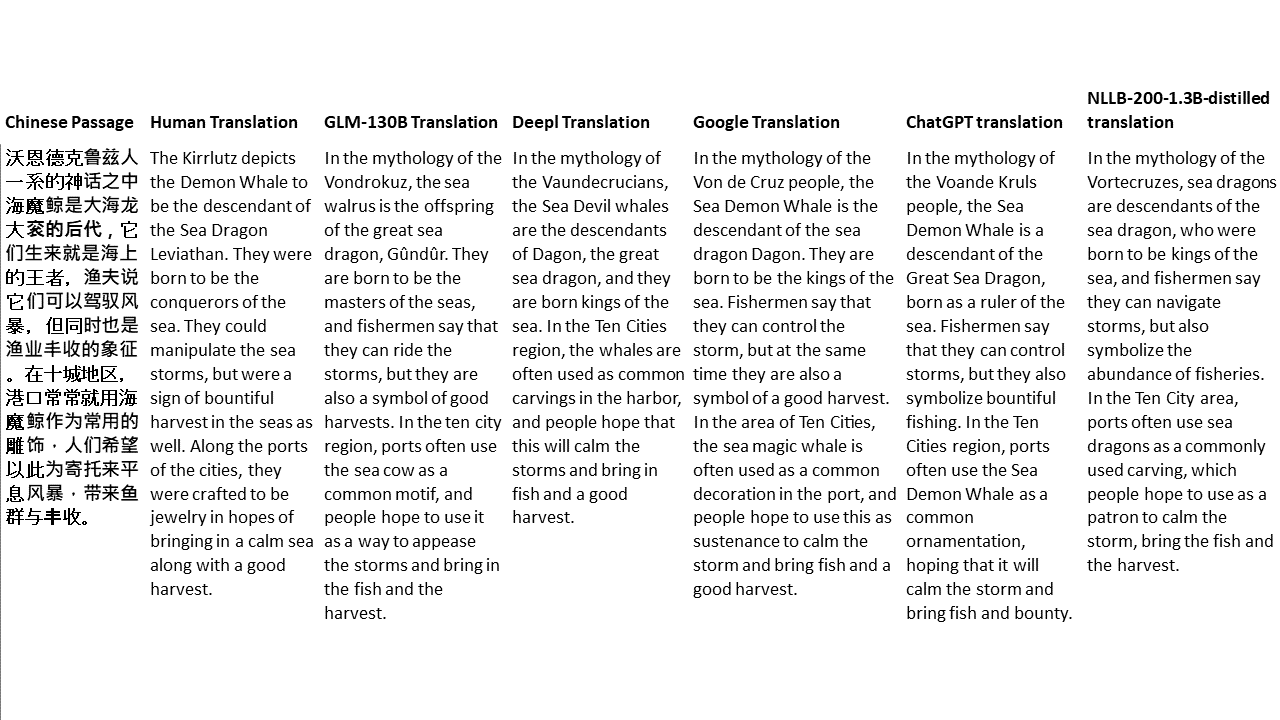
Pour mes tests, je choisis la littérature, un domaine particulièrement difficile pour la traduction automatique. 21 passages traduits avec GLM-130B et comparés avec Deepl, Google Translate, Chatgpt et NLLB-200-1.3B-distillé. Les passages sont échantillonnés à partir de 5 romans. La fête de mariage de Liu Xinwu, Strange Beasts of China par Yan Ge, The Amber Sword de Fei Yanfu, Wolf Totem par Jiang Rong et Supergene. Les passages sont choisis au hasard. Ils ne sont ni éprouvés ni régénérés.