Human parity on machine translations
1.0.0
As técnicas tradicionais de aprendizado de máquina para enfrentar a tradução vieram grandes melhorias na arte nos últimos anos. No entanto, eles ainda lutam com idiomas que estão distantes na árvore genealógica do idioma. Por exemplo, inglês e chinês/coreano/japonês.
Devido à natureza de por que esses modelos lutam com essas tarefas (incapacidade de extrapolar o contexto, gramática extremamente incompatível, etc.), me perguntei como um modelo de linguagem grande (LLM) pré -treinado em escala suficiente treinada em corpora multilíngue. Um LLM bilíngue poderia aproximar um humano bilíngue nas tarefas de tradução?
O primeiro passo, é claro, foi escolher um modelo para teste. Existem muito poucos modelos bilíngues ou multilíngues que são treinados em escala suficiente e têm representação de dados de treinamento igual ou quase igual para os dois idiomas em questão. Agradeço à equipe da Thudm por treinar e lançar o GLM-130B, um LLM bilíngue treinado em 200 bilhões de tokens, cada um de inglês e chinês (total de 400b). (https://github.com/thudm/glm-130b).
Este é o modelo principal usado para teste. Demonstração disponível aqui-https://huggingface.co/spaces/thudm/glm-130b porque o GLM-130B não é necessário instrução-finetuned, é necessária uma estratégia de poucos ou shot para traduções para traduções. Em testes preliminares, noto alguma correlação na complexidade e na qualidade das traduções com a complexidade e a qualidade de poucos exemplos de tiro. Como resultado, meu prompt de um tiro inclui uma passagem curta e uma tradução correspondente de um livro chinês traduzido e publicado em inglês.
Meu prompt de um tiro para GLM-130B
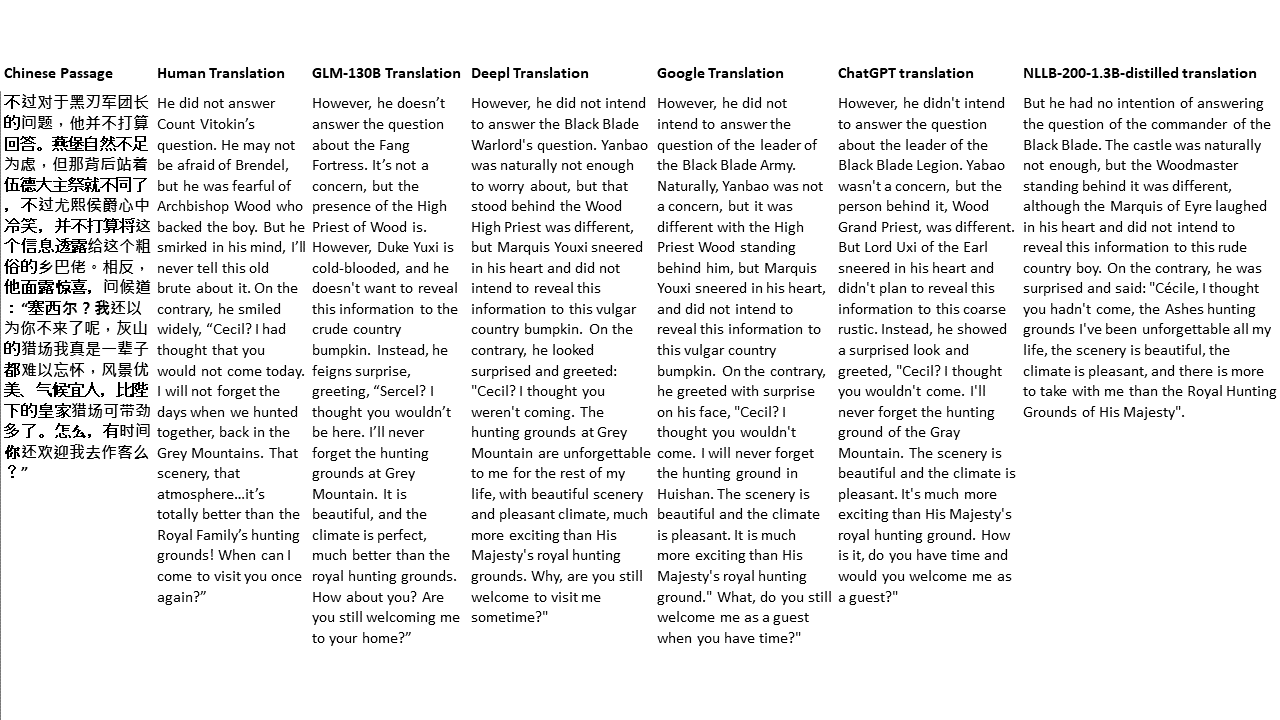
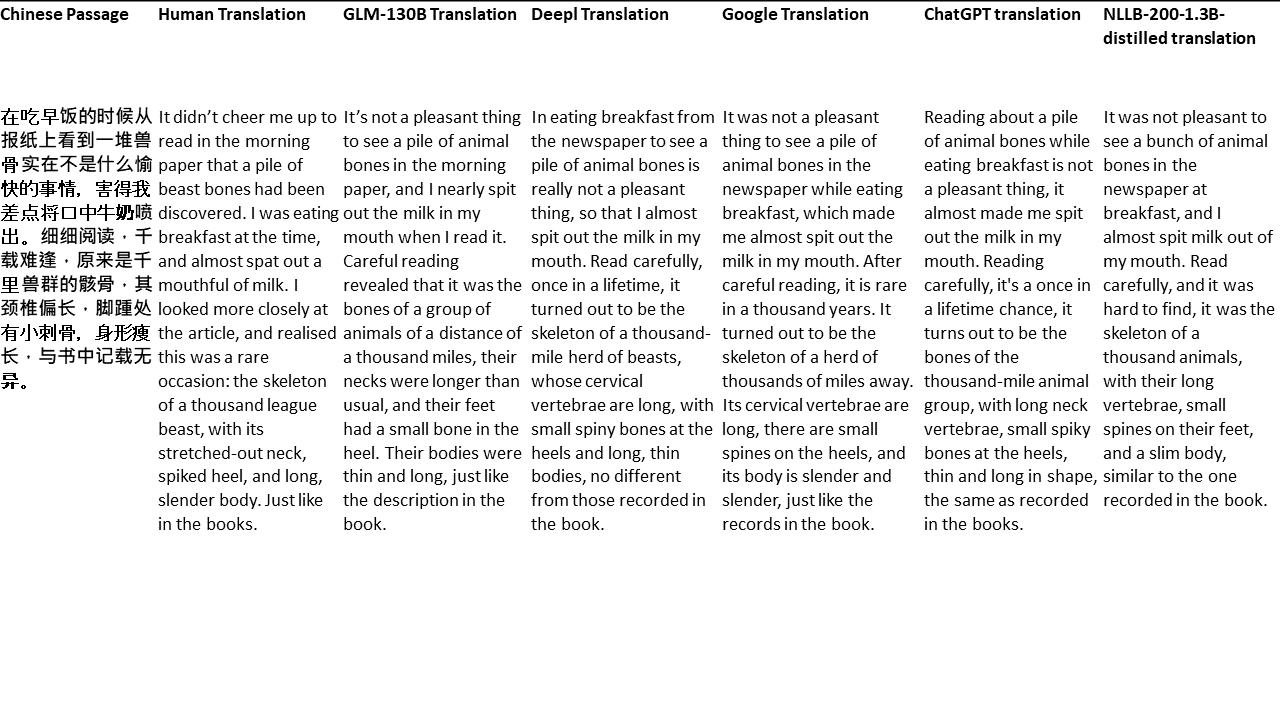
Chinese: 同北京许许多多同龄的老市民一样,薛大娘现在绝不是一个真正迷信的人,她知道迷信归根结蒂都是瞎掰,遇上听人讲述哪里有个老太太信神信鬼闹出乱子,她还会真诚地拍著大腿笑著说几句嘲讽的话;但她又同许许多多同龄的老市民一样,内心还揣著个求吉利的想法。
English: Like many Beijingers her age, she isn’t really superstitious—when you come right down to it, it’s just a bunch of random nonsense. Stories of old ladies fussing about visits from gods or ghosts have her slapping her thigh and making some cutting remark. Yet, also like many Beijingers her age, she has her own ideas about summoning good luck.
Chinese: Chinese text to translate
English: [gMASK]Os parâmetros são padrão, exceto para
Os modelos GPT da IA são multilíngues com um viés de inglês extremo (~ 92,6% em inglês por contagem de palavras) (https://github.com/openai/gpt-3/blob/master/dataset_statistics/languages_by_word_count.csv). No entanto, como a competência em um idioma parece sangrar na competência em outros idiomas em um LLM de escala suficiente (nas capacidades multilíngues de modelos de língua inglesa em larga escala: //arxiv.org/abs/2108.13349), também incluo traduções de chatgpt nas comparações. Como o ChatGPT é alinhado a instruções, um comando simples de tradução é suficiente e usado. Instruções ou exemplos específicos para priorizar a fluência e a fluidez podem produzir melhores resultados.
Nenhum idioma deixado para trás, o NLLB-200 da Meta alcançado de última geração dos resultados da arte nos benchmarks de tradução da máquina e também é comparado.
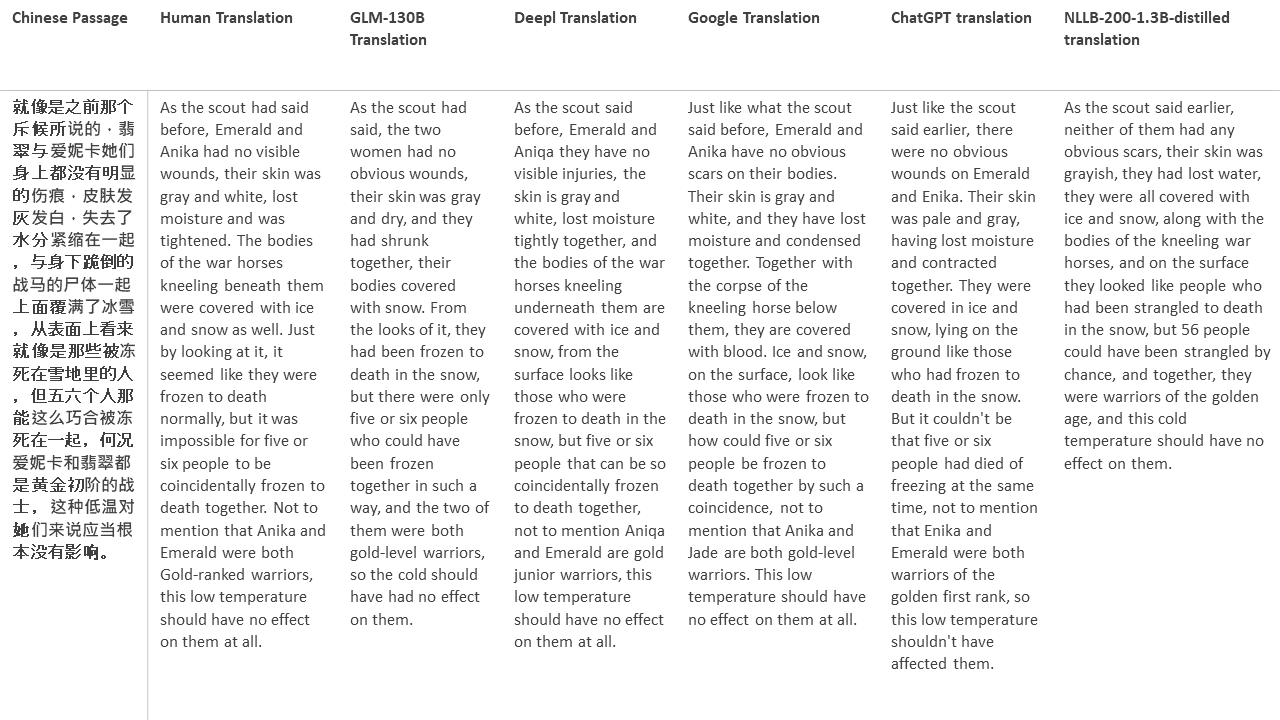
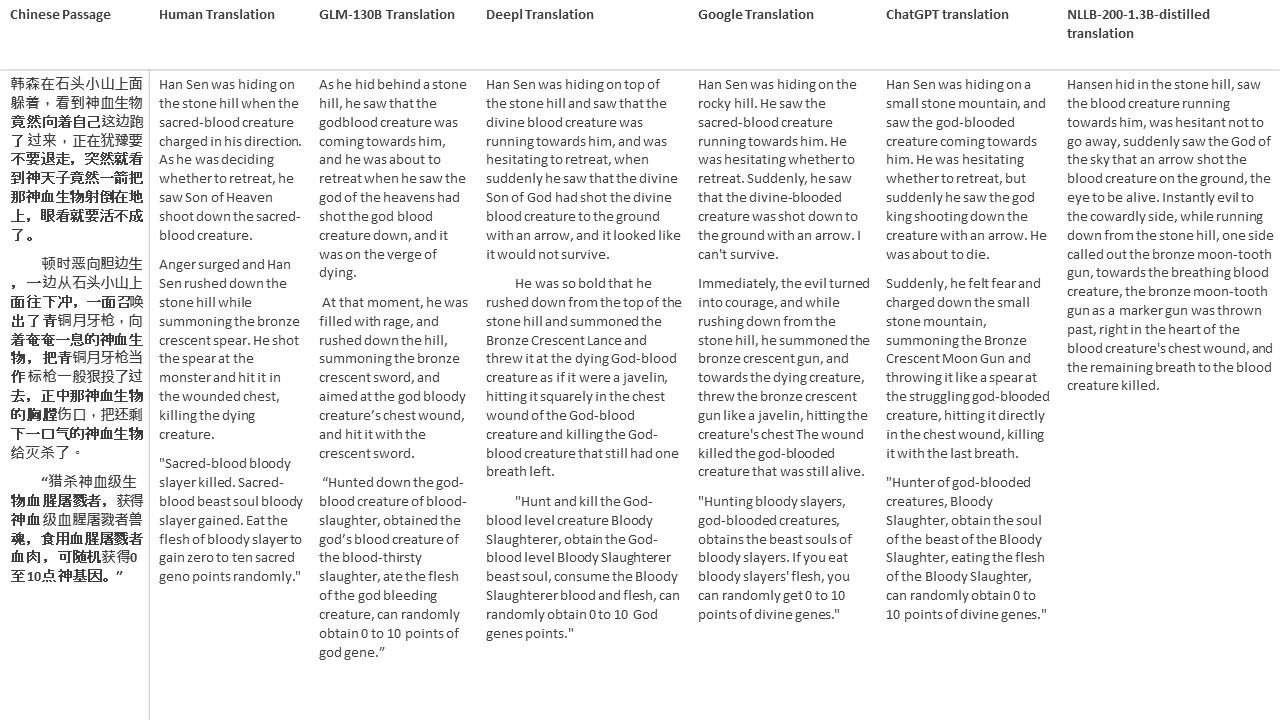
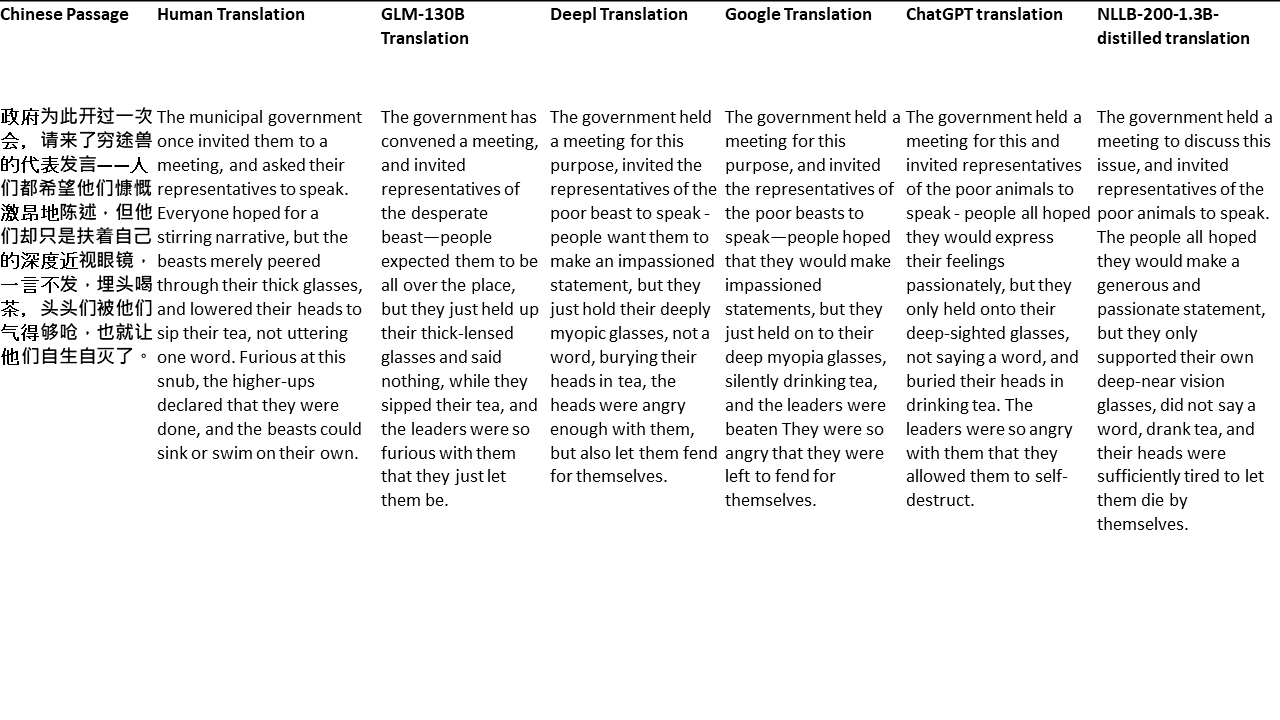
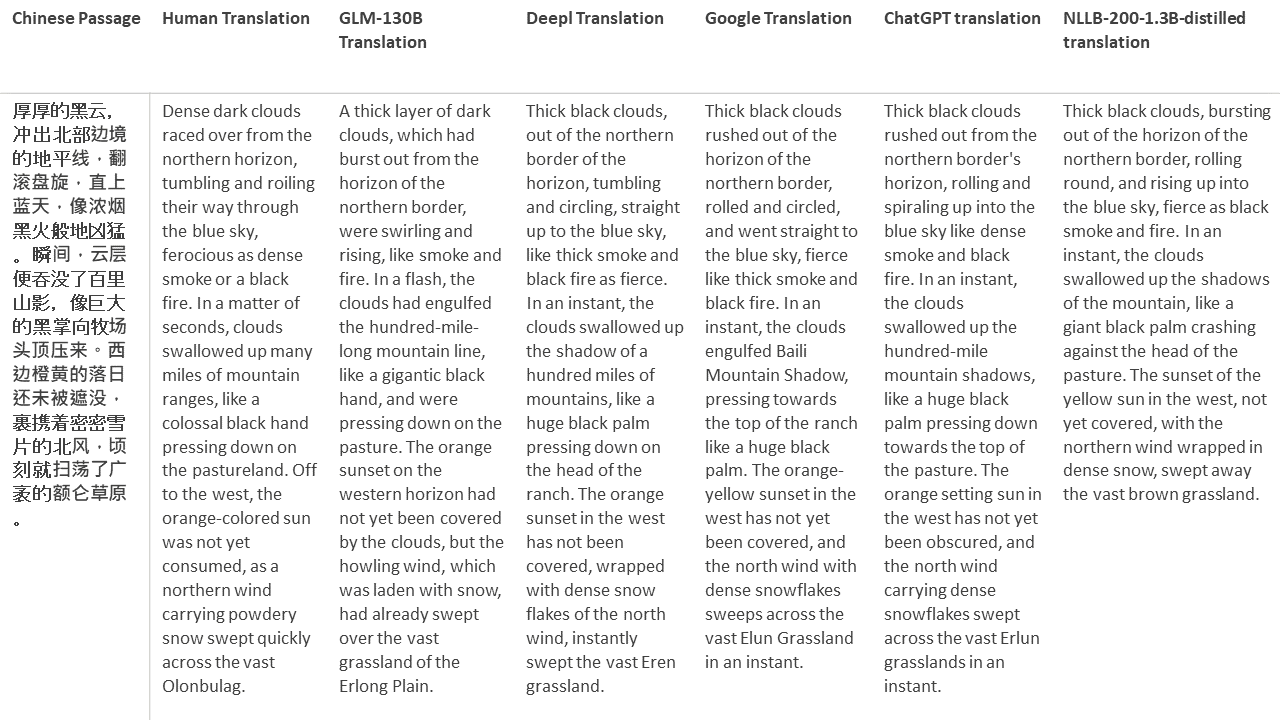
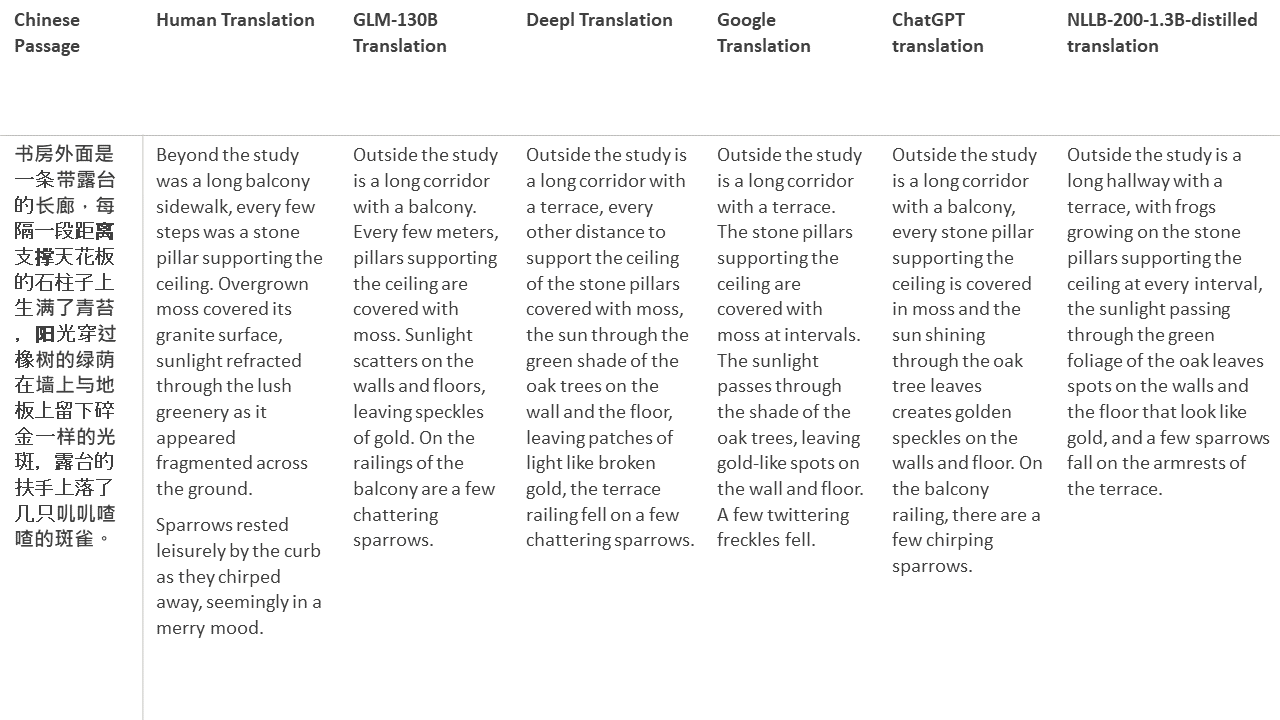
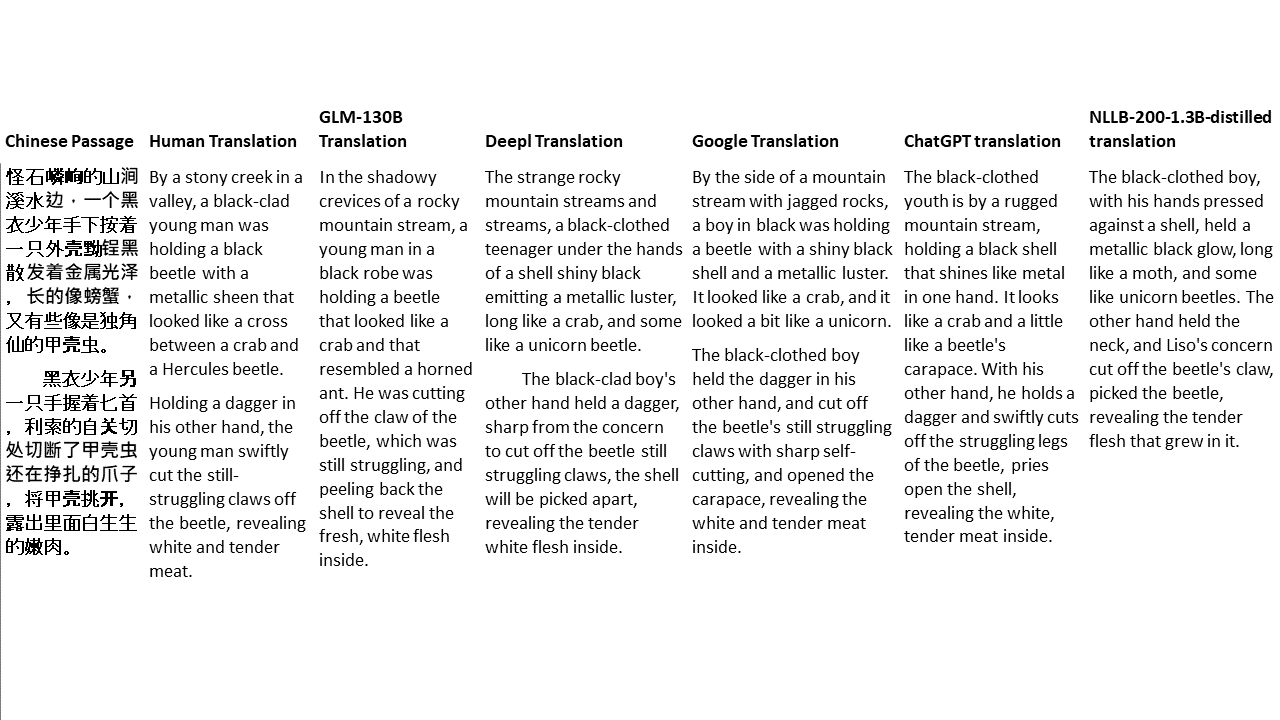
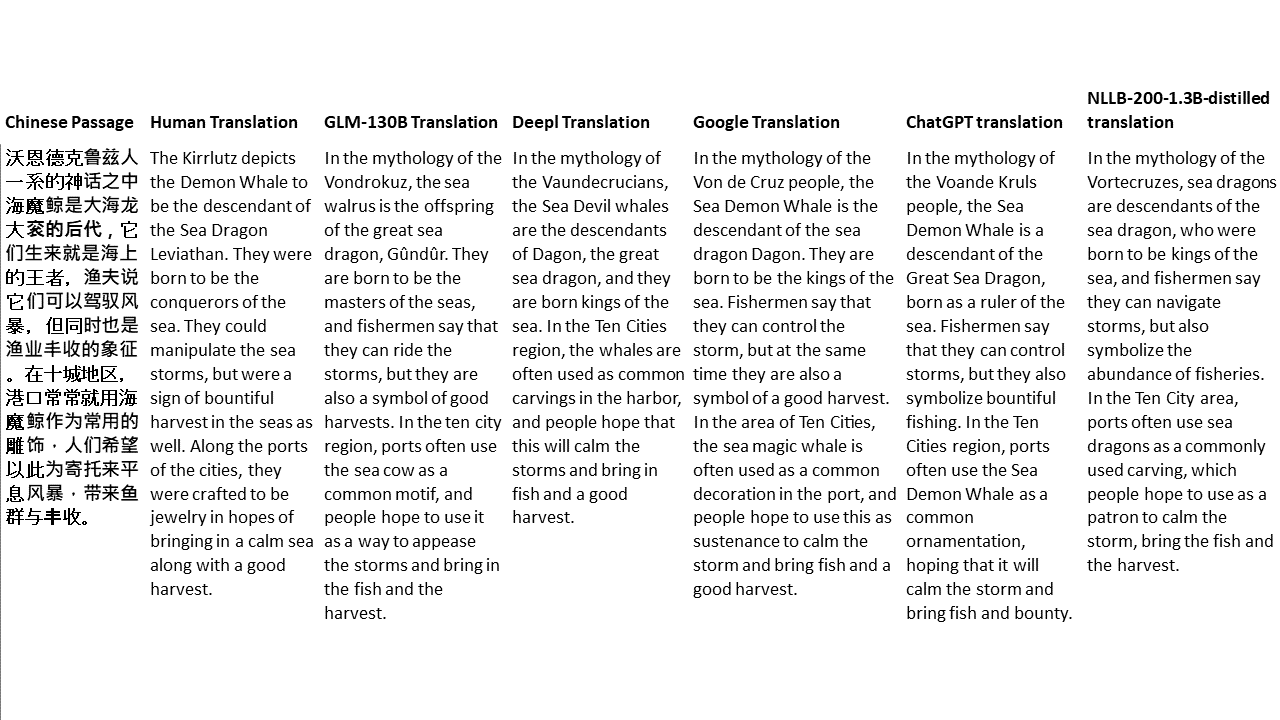
Para meus testes, escolho literatura, um domínio especialmente difícil para a tradução da máquina. 21 passagens traduzidas com GLM-130B e comparadas com Deepl, Google Translate, ChatGPT e NLLB-200-1.3b-Distilled. As passagens são amostradas em 5 romances. A festa de casamento de Liu Xinwu, bestas estranhas da China por Yan Ge, The Amber Sword de Fei Yanfu, Wolf Totem de Jiang Rong e Supergene. As passagens são escolhidas aleatoriamente. Eles não são cobertos de cerejeira ou regenerados.