Unlearn Simple
1.0.0
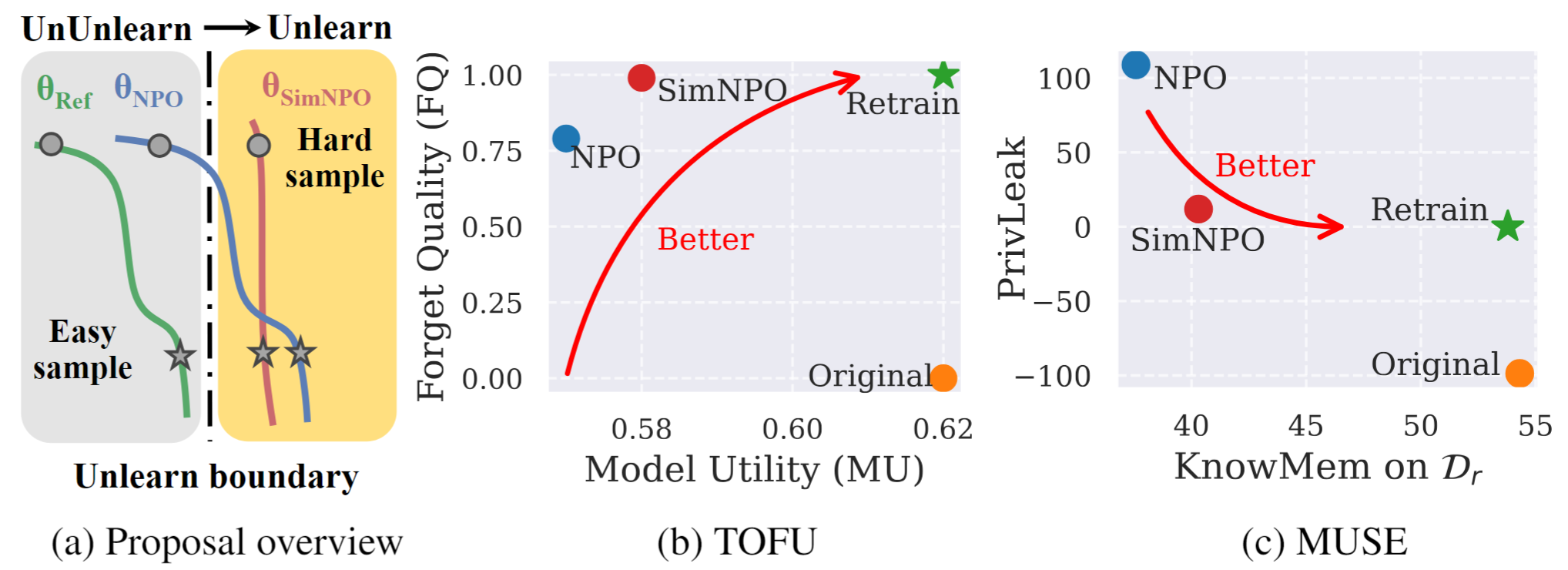 圖1: SIMNPO的系統概述和實驗亮點。 |
這是論文簡單性的官方代碼存儲庫:重新考慮對LLM學習的負面偏好優化。
在這項工作中,我們解決了大語模型(LLM)學習的問題,旨在消除不必要的數據影響和相關的模型功能(例如,受版權保護的數據或有害內容產生),而無需從划痕中重新審議。儘管越來越需要LLM學習,但仍缺乏原則上的優化框架。為此,我們重新審視了最新方法,負偏好優化(NPO),並確定參考模型偏見的問題,這可能會破壞NPO的有效性,尤其是在忘記忘記困難的忘記數據時。鑑於這一點,我們提出了一個簡單而有效的學習優化框架,稱為SIMNPO ,表明在消除對參考模型的依賴(通過簡單優先優化的鏡頭)上的“簡單性”上未學習。我們還通過使用馬爾可夫鏈的混合物來支持Simnpo的優勢的更深入的見解。此外,我們提出了廣泛的實驗,以驗證Simnpo優於豆腐和繆斯等基準中現有的未學習基準,以及可抵抗重新學習攻擊的魯棒性。
要直接使用我們的未學習模型,請參閱我們的擁抱面集合:
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


