Unlearn Simple
1.0.0
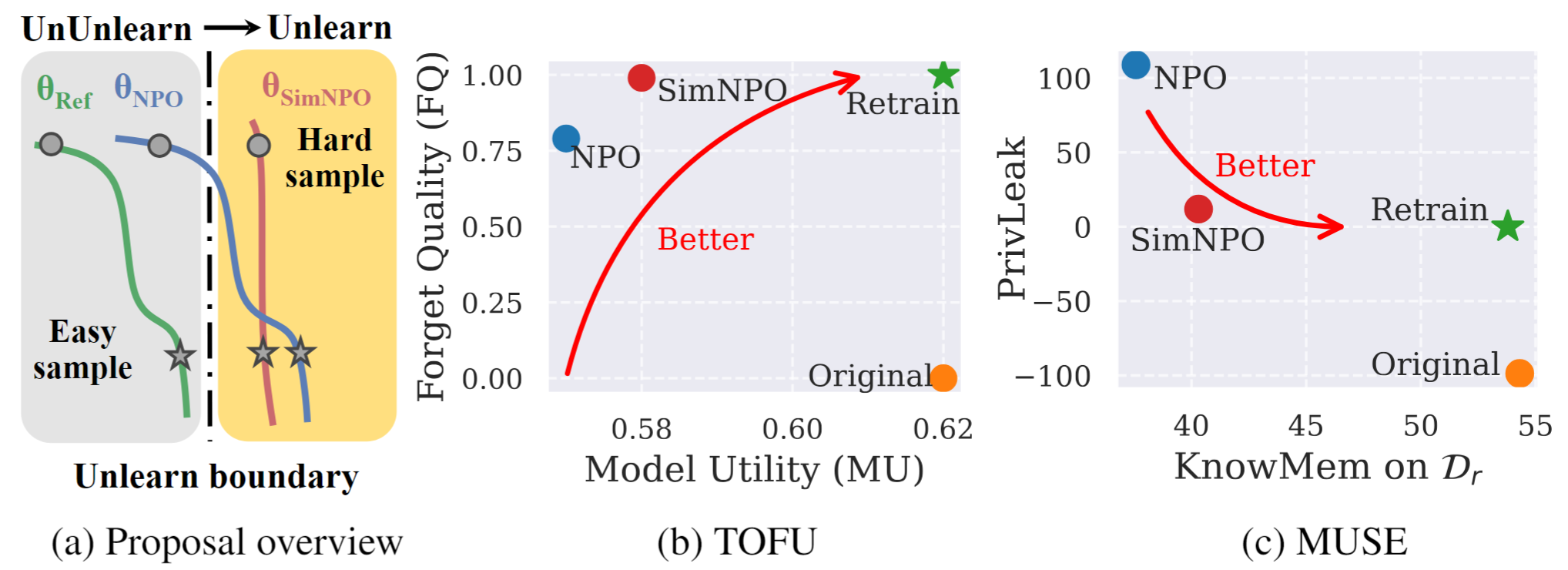 Рисунок 1: Систематический обзор и экспериментальные выделения SIMNPO. |
Это официальный репозиторий кода для простоты бумаги. Преобладает: переосмысление оптимизации негативных предпочтений для LLM.
В этой работе мы решаем проблему модели крупной языковой модели (LLM), стремящейся удалить нежелательные данные данных и связанные с ними возможности модели ( например , данные об авторском праве или вредное содержание) при сохранении утилиты основной модели, без необходимости переподготовки с нуля. Несмотря на растущую потребность в отключении LLM, принципиальная структура оптимизации по -прежнему не хватает. С этой целью мы пересматриваем современный подход, оптимизация отрицательных предпочтений (NPO) и определяем проблему смещения эталонной модели, которая может подорвать эффективность NPO, особенно при снятии сведения о том, чтобы забыть данные о различной сложности. Учитывая это, мы предлагаем простую, но эффективную структуру оптимизации отучки, называемая SIMNPO , показывающая, что «простота» при удалении зависимости от эталонной модели (через призму простой оптимизации предпочтений). Мы также даем более глубокое понимание преимуществ Simnpo, поддерживаемых анализом с использованием смесей цепочек Маркова. Кроме того, мы представляем обширные эксперименты, подтверждающие превосходство Simnpo по поводу существующих базовых показателей, таких как тофу и Muse, и устойчивость к атакам.
Чтобы непосредственно использовать нашу незамученную модель, пожалуйста, обратитесь к нашей коллекции HuggingFace:
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


