Unlearn Simple
1.0.0
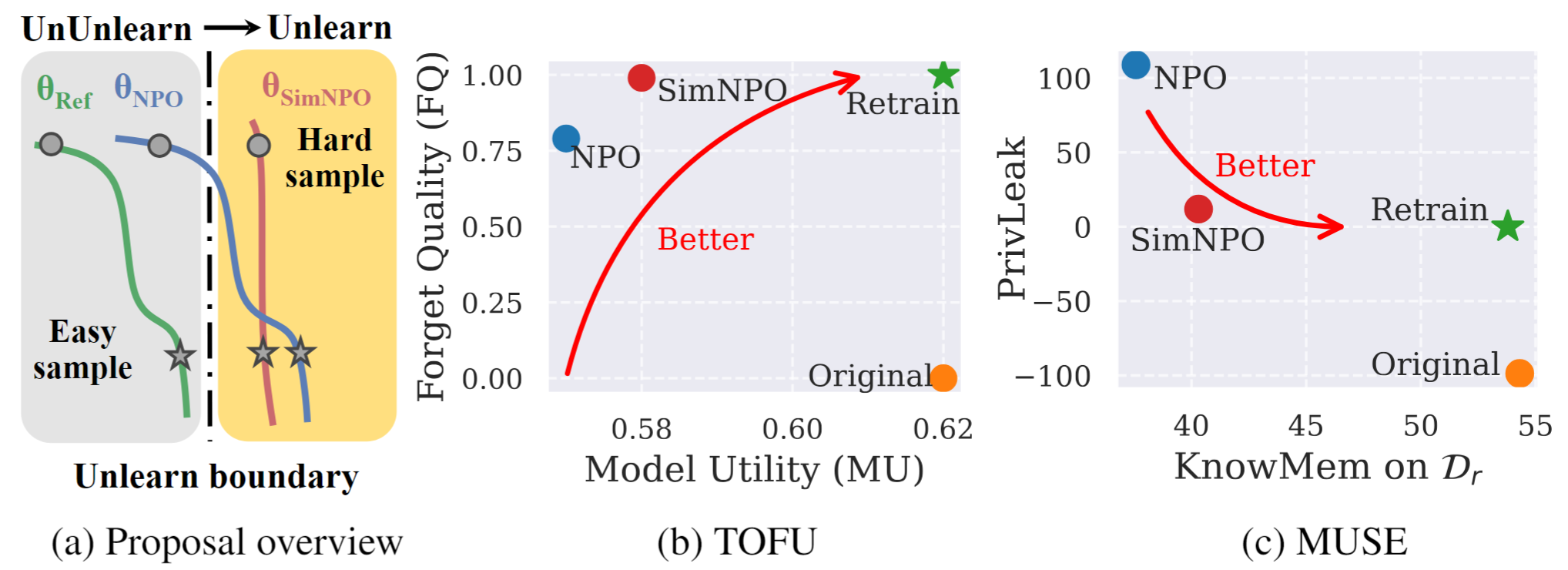 الشكل 1: نظرة عامة على نظرة عامة وتجربة من SIMNPO. |
هذا هو مستودع الكود الرسمي للبساطة الورقية يسود: إعادة التفكير في تحسين التفضيل السلبي لـ LLM غير التعبير.
في هذا العمل ، نتصدى لمشكلة نموذج اللغة الكبير (LLM) ، بهدف إزالة تأثيرات البيانات غير المرغوب فيها وقدرات النموذج المرتبطة ( على سبيل المثال ، البيانات المحمية بحقوق الطبع والنشر أو توليد المحتوى الضار) مع الحفاظ على الأدوات المساعدة النموذجية الأساسية ، دون الحاجة إلى إعادة التدريب من نقطة الصفر. على الرغم من الحاجة المتزايدة لإلغاء التعبير LLM ، لا يزال إطار التحسين المبدئي غير موجود. تحقيقًا لهذه الغاية ، نعيد النظر في المقاربة الحديثة ، وتحسين التفضيل السلبي (NPO) ، ونحدد مسألة تحيز النموذج المرجعي ، والتي يمكن أن تقوض فعالية NPO ، خاصة عندما تنسى بيانات الصعوبة المختلفة. بالنظر إلى ذلك ، نقترح إطارًا بسيطًا للتحسين غير الفعال والفعال ، يسمى SIMNPO ، مما يدل على أن "البساطة" في إزالة الاعتماد على نموذج مرجعي (من خلال عدسة تحسين التفضيلات البسيطة). نقدم أيضًا رؤى أعمق حول مزايا Simnpo ، بدعم من التحليل باستخدام مخاليط من سلاسل Markov. علاوة على ذلك ، نقدم تجارب واسعة النطاق التحقق من صحة تفوق Simnpo على خطوط الأساس غير المعروفة الحالية في معايير مثل التوفو وموس ، والمتانة ضد هجمات إعادة التعلم.
لاستخدام طرازنا غير المكتسب مباشرة ، يرجى الرجوع إلى مجموعة Huggingface الخاصة بنا:
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


