Unlearn Simple
1.0.0
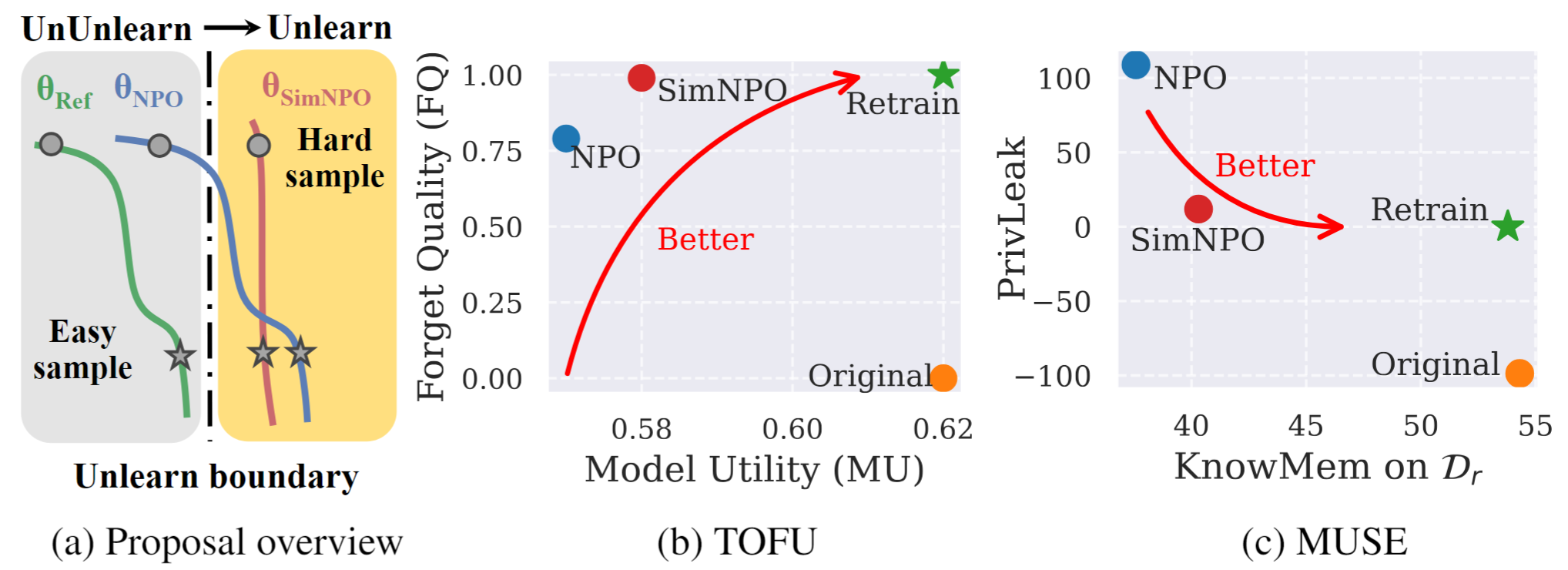 그림 1 : SIMNPO의 체계적인 개요 및 실험 하이라이트. |
이것은 종이 단순성에 대한 공식 코드 저장소입니다.
이 작업에서 우리는 원치 않는 데이터 영향과 관련 모델 기능 ( 예 : 저작권이있는 데이터 또는 유해한 컨텐츠 생성)을 제거하면서 필수 모델 유틸리티를 처음부터 재교육하지 않고 보존하는 대형 언어 모델 (LLM)의 문제를 해결합니다. LLM 학습에 대한 요구가 증가 함에도 불구하고 원칙적 최적화 프레임 워크는 여전히 부족합니다. 이를 위해 최첨단 접근 방식 인 NPO (Negative Preference Optimization)를 다시 방문하고, 특히 다양한 어려움의 데이터를 잊어 버릴 때 NPO의 효과를 훼손 할 수있는 참조 모델 바이어스 문제를 식별합니다. 이를 감안할 때, 우리는 SIMNPO 라는 간단하면서도 효과적인 무등 최적화 프레임 워크를 제안하여 (간단한 선호도 최적화의 렌즈를 통해) 기준 모델에 대한 의존을 제거 할 때 '단순성'이 학습에 이어질 수 있음을 보여줍니다. 또한 Markov 체인의 혼합물을 사용하여 분석을 통해 Simnpo의 장점에 대한 더 깊은 통찰력을 제공합니다. 또한, 우리는 두부 및 뮤즈와 같은 벤치 마크에서 기존의 무등증 기준에 대한 Simnpo의 우수성을 검증하는 광범위한 실험과 재 배우 공격에 대한 견고성을 제시합니다.
비 배우지 모델을 직접 사용하려면 Huggingface 컬렉션을 참조하십시오.
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


