Unlearn Simple
1.0.0
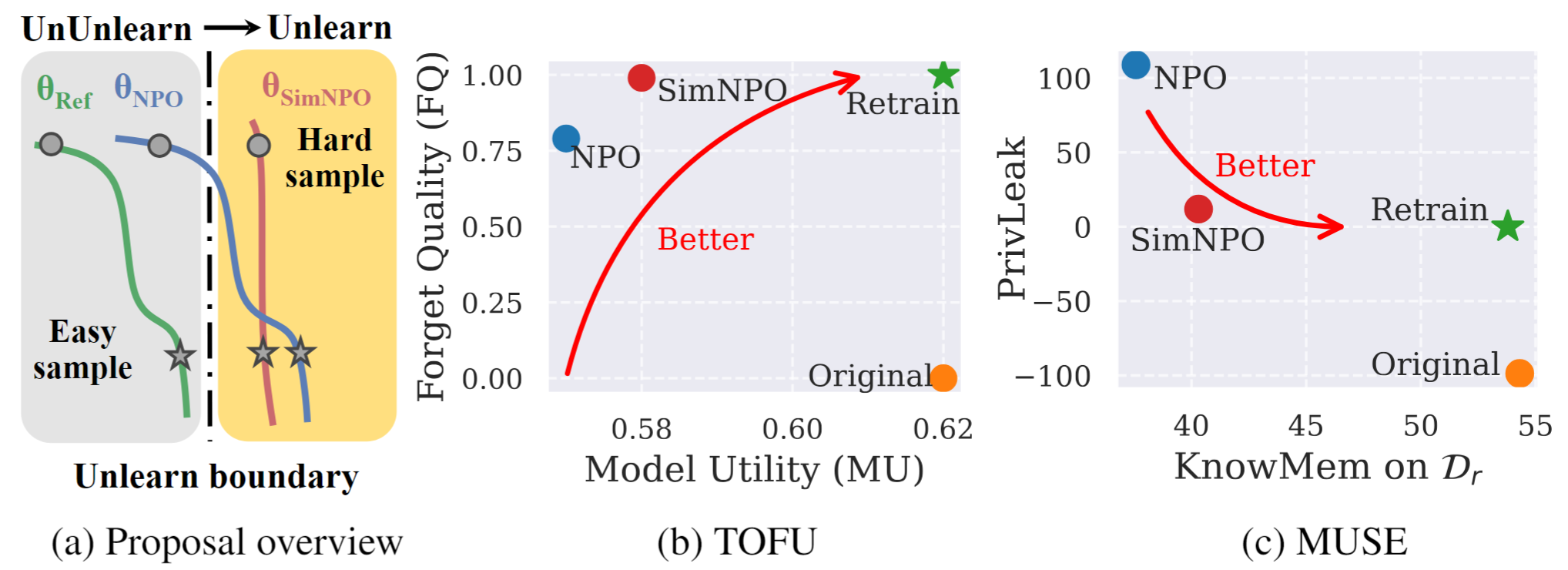 รูปที่ 1: ภาพรวมอย่างเป็นระบบและไฮไลต์การทดลองของ SIMNPO |
นี่คือที่เก็บรหัสอย่างเป็นทางการสำหรับความเรียบง่ายของกระดาษที่เหนือกว่า: ทบทวนการเพิ่มประสิทธิภาพการตั้งค่าเชิงลบสำหรับ LLM ที่ไม่ได้เรียนรู้
ในงานนี้เราจัดการกับปัญหาของรูปแบบภาษาขนาดใหญ่ (LLM) ที่ไม่ได้รับการหาเงินโดยมีวัตถุประสงค์เพื่อลบอิทธิพลของข้อมูลที่ไม่พึงประสงค์และความสามารถของโมเดลที่เกี่ยวข้อง ( เช่น ข้อมูลที่มีลิขสิทธิ์หรือการสร้างเนื้อหาที่เป็นอันตราย) ในขณะที่รักษายูทิลิตี้แบบจำลองที่จำเป็นโดยไม่จำเป็นต้องฝึกใหม่ แม้จะมีความต้องการที่เพิ่มขึ้นสำหรับ LLM ที่ไม่เข้าใจ แต่กรอบการเพิ่มประสิทธิภาพหลักการยังขาดอยู่ ด้วยเหตุนี้เราจึงทบทวนวิธีการที่ทันสมัยการเพิ่มประสิทธิภาพการตั้งค่าเชิงลบ (NPO) และระบุปัญหาของอคติโมเดลอ้างอิงซึ่งอาจบ่อนทำลายประสิทธิภาพของ NPO โดยเฉพาะอย่างยิ่งเมื่อไม่ได้รับข้อมูลลืมข้อมูลของความยากลำบากที่แตกต่างกัน ระบุว่าเราเสนอกรอบการเพิ่มประสิทธิภาพที่ง่าย แต่มีประสิทธิภาพ แต่มีประสิทธิภาพที่เรียกว่า SIMNPO แสดงให้เห็นว่า 'ความเรียบง่าย' ในการลบการพึ่งพาในรูปแบบการอ้างอิง (ผ่านเลนส์ของการเพิ่มประสิทธิภาพการตั้งค่าง่าย ๆ ) เป็นประโยชน์อย่างไม่เป็นทางการ นอกจากนี้เรายังให้ข้อมูลเชิงลึกที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับข้อได้เปรียบของ Simnpo ซึ่งได้รับการสนับสนุนโดยการวิเคราะห์โดยใช้ส่วนผสมของโซ่มาร์คอฟ นอกจากนี้เรายังนำเสนอการทดลองที่ครอบคลุมการตรวจสอบความเหนือกว่าของ Simnpo เหนือเส้นขอบฟ้าที่ไม่ได้เรียนรู้ที่มีอยู่ในเกณฑ์มาตรฐานเช่นเต้าหู้และ Muse และความทนทานต่อการโจมตีซ้ำ
หากต้องการใช้โมเดลที่ไม่ได้เรียนโดยตรงของเราโปรดดูคอลเลกชัน HuggingFace ของเรา:
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


