Unlearn Simple
1.0.0
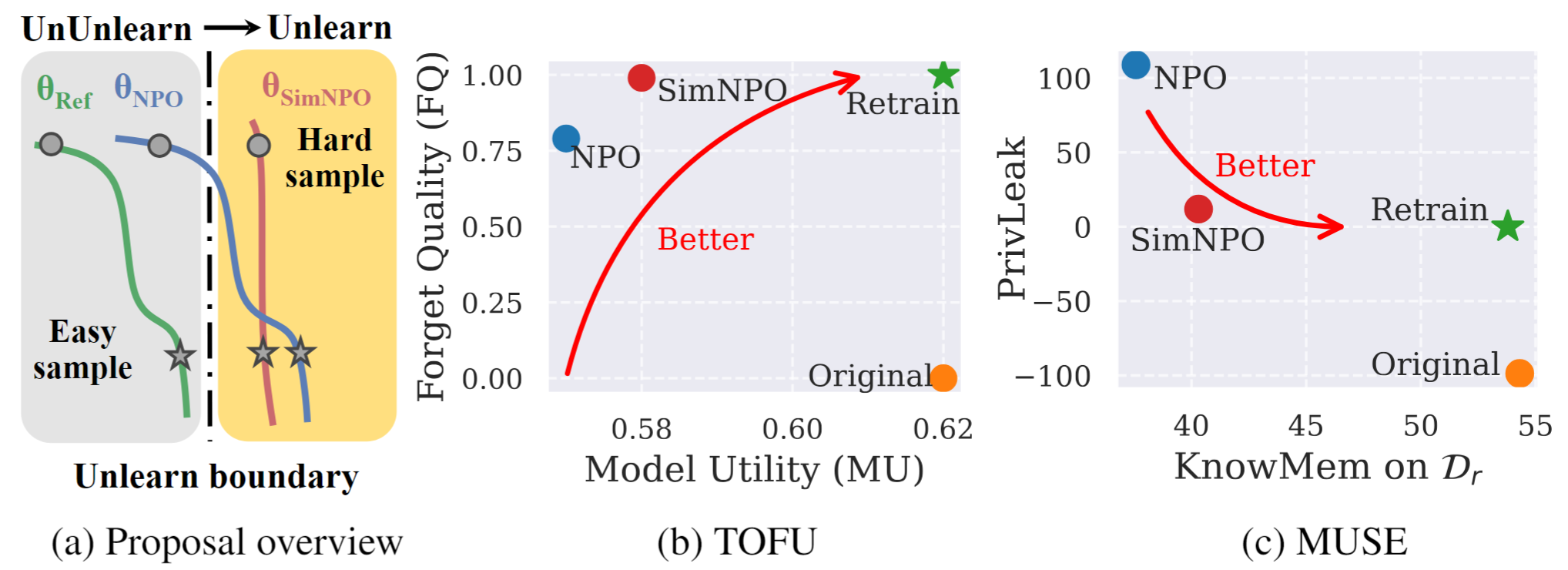 Gambar 1: Tinjauan sistematis dan eksperimen sorotan SIMNPO. |
Ini adalah repositori kode resmi untuk kesederhanaan kertas berlaku: Memikirkan kembali optimasi preferensi negatif untuk Unselarning LLM.
Dalam karya ini, kami membahas masalah model bahasa besar (LLM) yang tidak belajar, bertujuan untuk menghapus pengaruh data yang tidak diinginkan dan kemampuan model terkait ( misalnya , data yang dilindungi hak cipta atau pembuatan konten yang berbahaya) sambil mempertahankan utilitas model penting, tanpa perlu melatih kembali dari awal. Terlepas dari kebutuhan yang semakin meningkat untuk LLM, kerangka kerja optimasi berprinsip tetap kurang. Untuk tujuan ini, kami meninjau kembali pendekatan canggih, optimasi preferensi negatif (NPO), dan mengidentifikasi masalah bias model referensi, yang dapat merusak efektivitas NPO, terutama ketika tidak mengetahui data lupa dari berbagai kesulitan. Mengingat bahwa, kami mengusulkan kerangka optimasi yang tidak belajar sendiri yang sederhana namun efektif, yang disebut SIMNPO , menunjukkan bahwa 'kesederhanaan' dalam menghilangkan ketergantungan pada model referensi (melalui lensa optimasi preferensi sederhana) manfaat yang tidak diketahui. Kami juga memberikan wawasan yang lebih dalam tentang keuntungan Simnpo, didukung oleh analisis menggunakan campuran rantai Markov. Selain itu, kami menyajikan eksperimen ekstensif yang memvalidasi keunggulan Simnpo atas garis dasar yang tidak diketahui dalam tolok ukur seperti tahu dan muse, dan ketahanan terhadap serangan belajar kembali.
Untuk secara langsung menggunakan model kami yang tidak terpelajar, silakan merujuk ke koleksi HuggingFace kami:
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


