Unlearn Simple
1.0.0
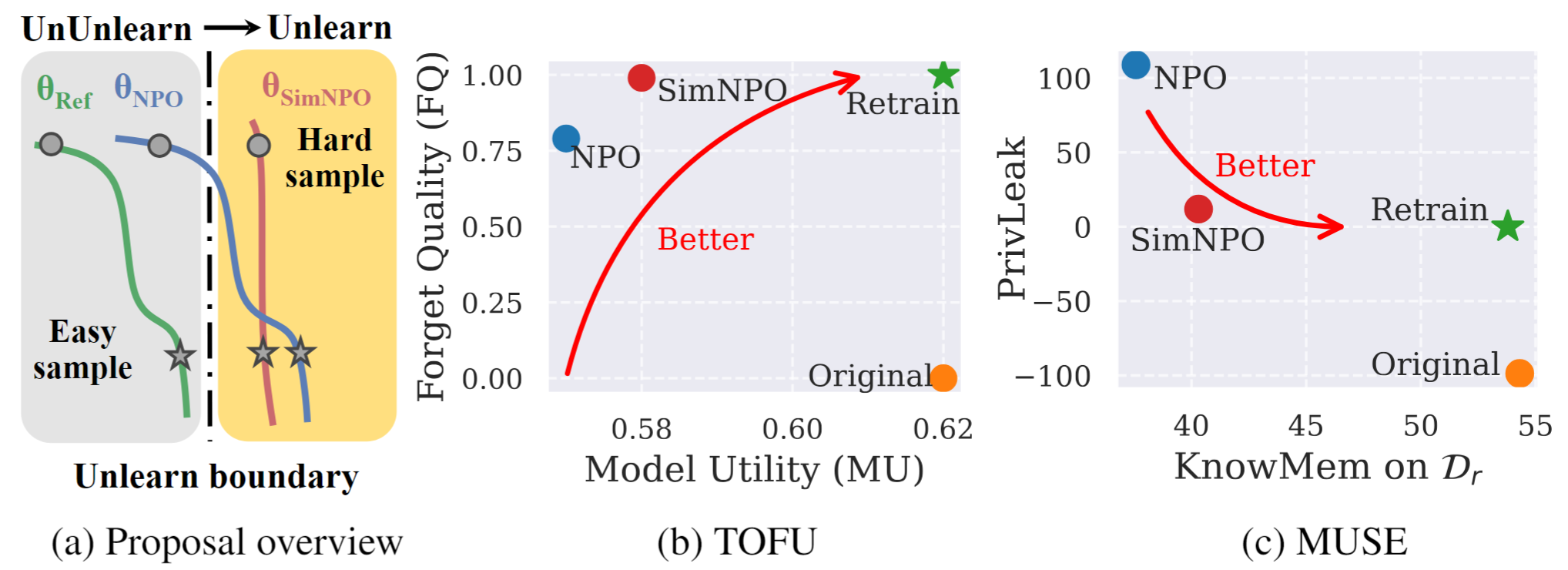 図1: Simnpoの系統的な概要と実験ハイライト。 |
これは、論文のシンプルさの公式コードリポジトリです。LLMの学習の否定的な好みの最適化を再考します。
この作業では、不要なデータの影響と関連するモデル機能(著作権で保護されたデータや有害なコンテンツ生成など)を削除しながら、ゼロからの再トレーニングを必要とせずに、不要なデータの影響と関連するモデル機能(著作権データまたは有害なコンテンツ生成)を削除することを目指して、大規模な言語モデル(LLM)の問題に対処します。 LLMの学習の必要性が高まっているにもかかわらず、原則的な最適化フレームワークには不足しています。この目的のために、最先端のアプローチ、否定的優先最適化(NPO)を再訪し、特にさまざまな難易度の忘れたデータを学習する場合にNPOの有効性を損なう可能性のある参照モデルバイアスの問題を特定します。それを考えると、 Simnpoと呼ばれるシンプルでありながら効果的な未学習の最適化フレームワークを提案し、参照モデルへの依存(単純な好みの最適化のレンズを介して)を削除する際の「シンプルさ」を示しています。また、マルコフチェーンの混合物を使用した分析によってサポートされているSimnpoの利点についてのより深い洞察も提供します。さらに、豆腐やミューズなどのベンチマークでの既存の未解決のベースラインに対するSimnpoの優位性を検証する広範な実験を提示し、再学習攻撃に対する堅牢性を示します。
未学習のモデルを直接使用するには、ハッグフェイスコレクションを参照してください。
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


