Unlearn Simple
1.0.0
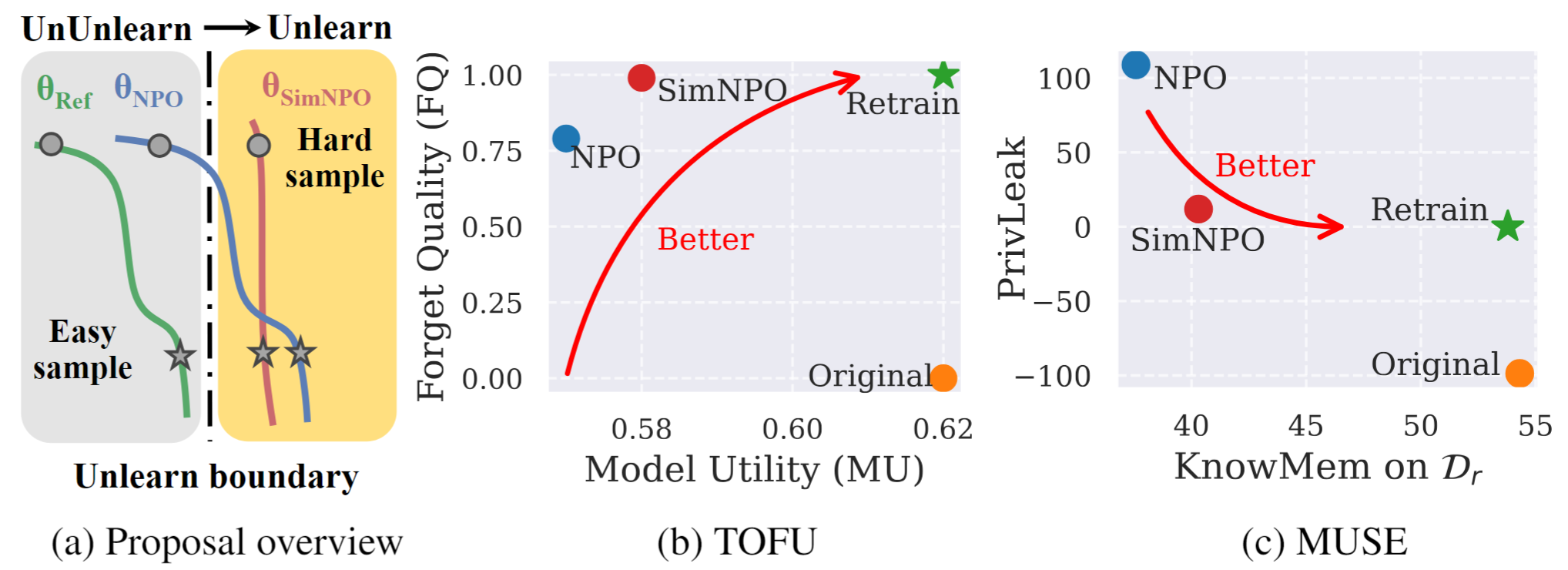 Figura 1: Visão geral e destaques sistemáticos do SIMNPO. |
Este é o repositório oficial de código para a simplicidade do artigo prevalece: repensando a otimização de preferência negativa para o desaprendimento de LLM.
Neste trabalho, abordamos o problema de desaprendizamento de Modelo de Linguagem Grande (LLM), com o objetivo de remover influências de dados indesejados e recursos de modelo associados ( por exemplo , dados protegidos por direitos autorais ou geração prejudicial de conteúdo), preservando os utilitários essenciais do modelo, sem a necessidade de recorrer do zero. Apesar da crescente necessidade de desaprendizar LLM, permanece falta uma estrutura de otimização de princípios. Para esse fim, revisitamos a abordagem de última geração, a otimização de preferência negativa (NPO) e identificamos a questão do viés do modelo de referência, que pode minar a eficácia do NPO, principalmente quando o desaprendizar esquece os dados de dificuldades variadas. Dado isso, propomos uma estrutura de otimização de desaprendizagem simples, mas eficaz, chamada SIMNPO , mostrando que a 'simplicidade' na remoção da dependência de um modelo de referência (através da lente da otimização de preferência simples) beneficia o desaprendimento. Também fornecemos informações mais profundas sobre as vantagens da SIMNPO, apoiadas por análise usando misturas de cadeias de Markov. Além disso, apresentamos extensos experimentos que validam a superioridade de Simnpo sobre linhas de base de desaprendizar existentes em benchmarks como tofu e musa e robustez contra ataques de relevo.
Para usar diretamente nosso modelo desaprendizado, consulte nossa coleção Huggingface:
@article{fan2024simplicity,
title={Simplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning},
author={Fan, Chongyu and Liu, Jiancheng and Lin, Licong and Jia, Jinghan and Zhang, Ruiqi and Mei, Song and Liu, Sijia},
journal={arXiv preprint arXiv:2410.07163},
year={2024}
}


