LLM Pruner
1.0.0
LLM-Pruner:關於大語言模型的結構修剪[ARXIV]
Xinyin MA,Gongfan Fang,Xinchao Wang
新加坡國立大學
.from_pretrained()加載模型。 加入我們的微信小組聊天:
pip install -r requirement.txt
bash script/llama_prune.sh
該腳本將用修剪20%的參數壓縮Llama-7b模型。所有預訓練的模型和數據集將自動下載,因此您無需手動下載資源。首次運行此腳本時,它將需要一些時間才能下載模型和數據集。
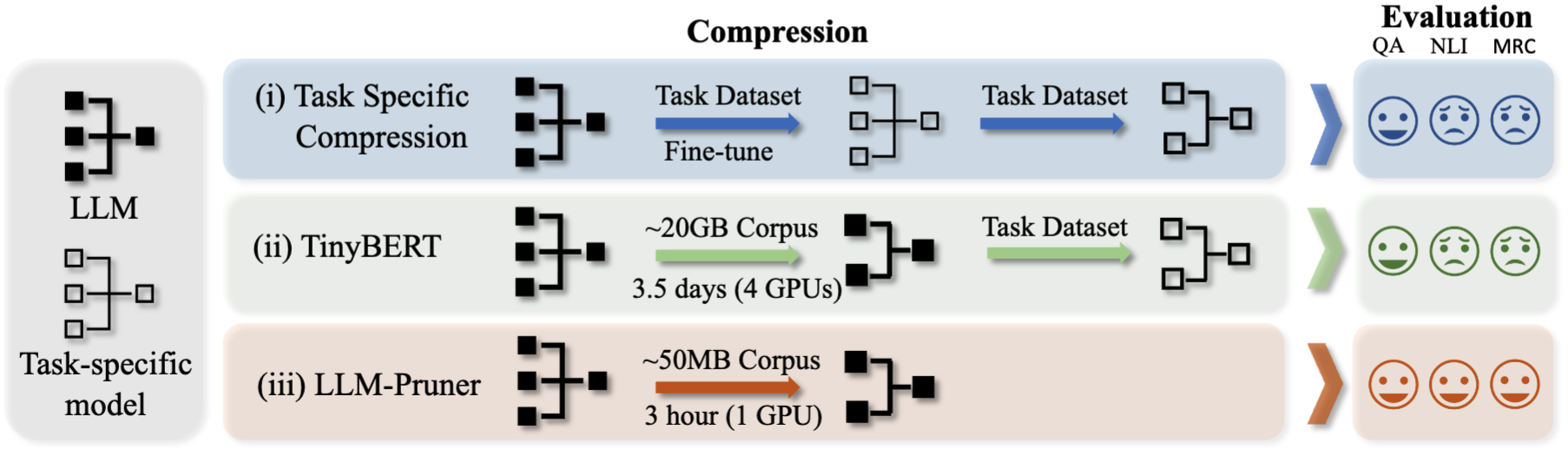
它需要三個步驟才能修剪LLM:
修剪和訓練後修剪後,我們遵循LM評估 - 進行評估。
? Llama/Llama-2修剪約20%的參數已修剪:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
參數:
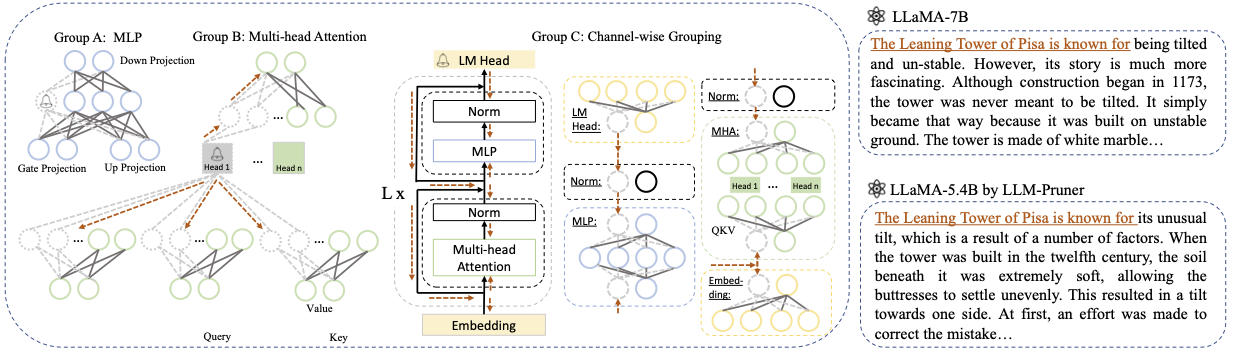
Base model :從Llama或Llama-2中選擇基本模型,然後將pretrained_model_name_or_path _model_name_or_path傳遞到--base_model 。該模型名稱用於AutoModel.from_pretrained加載預訓練的LLM。例如,如果要使用具有130億個參數的Llama-2,則將meta-llama/Llama-2-13b-hf傳遞到--base_model 。Pruning Strategy :使用相應的命令選項在塊,頻道或層修剪之間進行選擇:{-block_wise},{ - channel_wise},{ - layer_wise-layer_wise -layer-layer number_of_layers}。對於塊修剪,請指定要修剪的開始和端層。通過渠道修剪不需要額外的論點。對於圖層修剪,請使用-Layer number_of_layers指定修剪後要保留的所需層數。Importance Criterion :使用-pruner_type參數從L1,L2,隨機或Taylor中進行選擇。對於Taylor Pruner,請選擇以下選項之一:vectorize,param_second,param_first,param_mix。默認情況下,使用param_mix,結合了近似的二階Hessian和一階梯度。如果使用L1,L2或隨機,則無需額外的參數。Pruning Ratio :指定組的修剪比。它與參數的修剪速率不同,因為將組作為最小單元去除。Device和Eval_device :可以在不同的設備上執行修剪和評估。基於泰勒的方法需要在修剪過程中向後計算,這可能需要大量的GPU RAM。我們的實施使用CPU來進行重要的估計(也支持GPU,簡單地使用 - 設備CUDA)。 eval_device用於測試修剪模型。 如果您想嘗試Vicuna,請指定參數--base_model到達Vicuna重量的路徑。請關注https://github.com/lm-sys/fastchat獲得Vicuna重量。
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
有關更多詳細信息,請參閱示例/Baichuan
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
確保將PATH_TO_PRUNE_MODEL替換為步驟1中修剪模型的路徑,然後用要保存調諧模型的所需位置替換PATH_TO_SAVE_TUNE_MODEL 。
提示:不建議在Float16中訓練Llama-2,並且眾所周知會產生NAN;因此,該模型應在Bfloat16中進行訓練。
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
對於修剪模型,只需使用以下命令加載模型即可。
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
由於修剪模型中模塊之間的配置不同,在修剪模型中,某些層可能具有更大的寬度,而其他層的修剪較大,因此使用.from_pretrained() (通過擁抱面孔)加載模型是不切實際的。目前,我們使用torch.save存儲修剪模型。
由於修剪模型在每一層中具有不同的配置,就像某些圖層可能更寬,但有些層的修剪得多,因此該模型無法在擁抱面中加載.from_pretrained() 。當前,我們只需使用torch.save來保存修剪模型和torch.load 。負載即可加載修剪的模型。
我們提供了一個簡單的腳本來使用帶有培訓後培訓的預訓練 /修剪模型 /修剪模型進行基因文本。
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
以上說明將在本地部署您的LLMS。
為了評估修剪模型的性能,我們遵循LM評估 - 評估模型:
lm-evaluation-harness的輸入要求。從訓練後步驟中調整的檢查點將以以下格式保存: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
通過以下命令安排文件:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
如果要評估checkpoint-200 ,則將Epoch等於200的export epoch=200 。
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
在這裡,用保存修剪模型和調諧模型的路徑替換PATH_TO_PRUNE_MODEL和PATH_TO_SAVE_TUNE_MODEL ,而PATH_OR_NAME_TO_BASE_MODEL用於加載基本模型的配置文件。
[UPDATE]:如果您想使用調諧檢查點評估修剪模型,我們將上傳腳本以簡單地評估過程。只需使用以下命令:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
在命令中替換模型的必要信息。如果您想在一個命令中評估幾個檢查點,則最終的習慣是在不同的時期迭代。例如:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
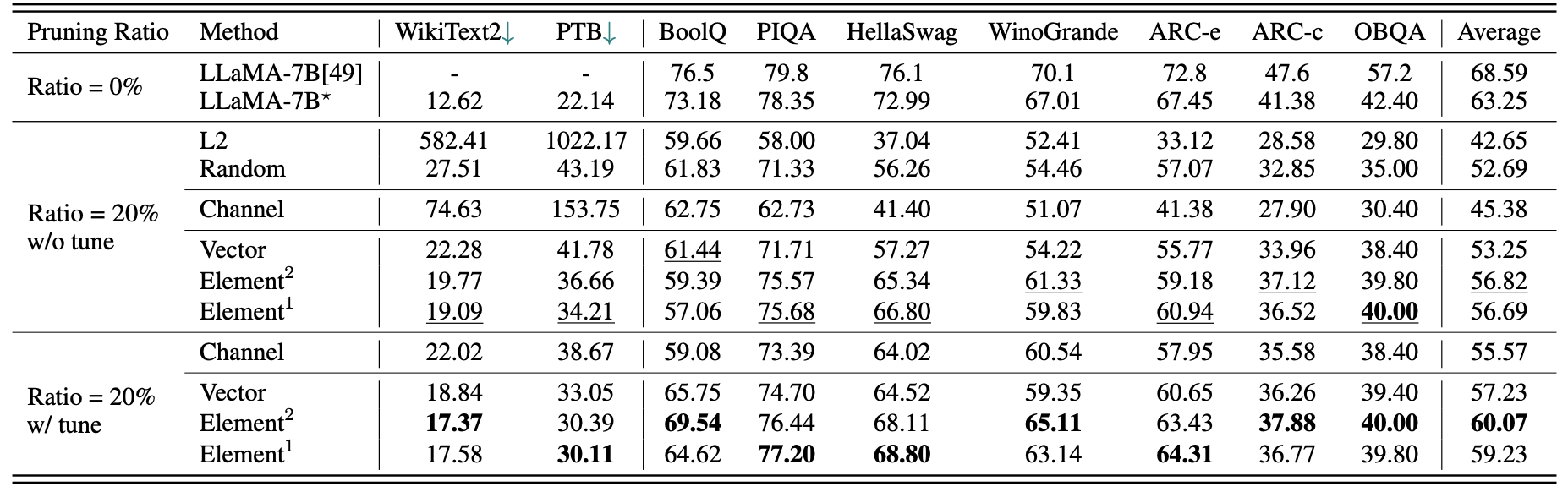
Llama-7b的簡短定量結果:
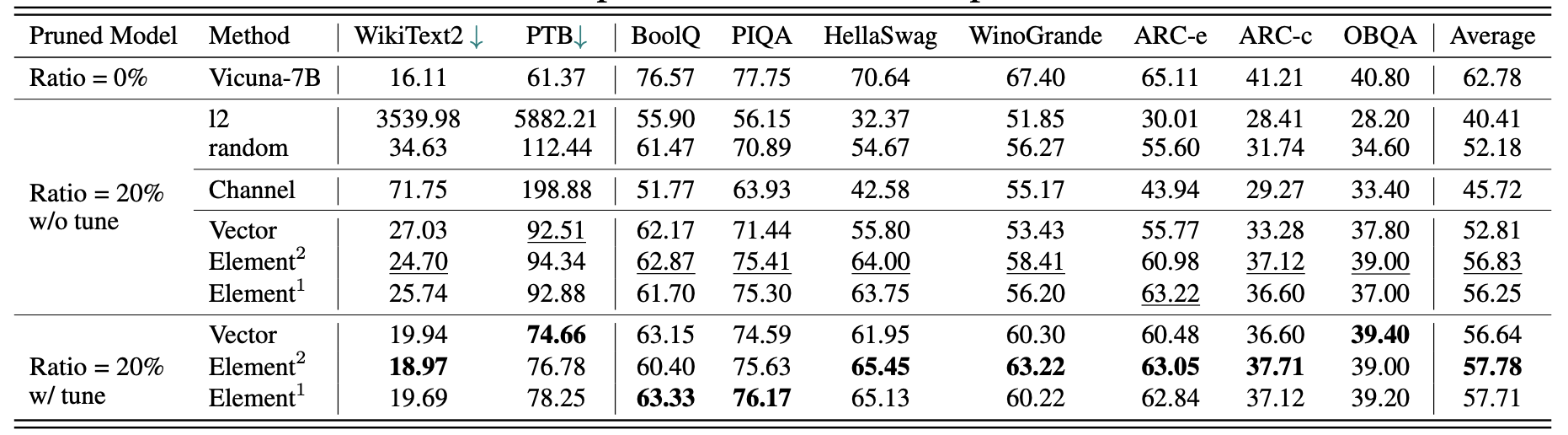
Vicuna-7b的結果:
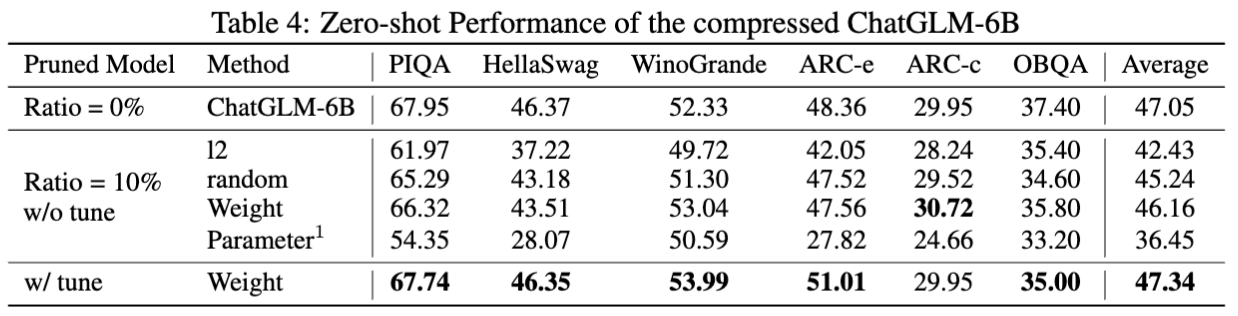
CHATGLM-6B的結果:
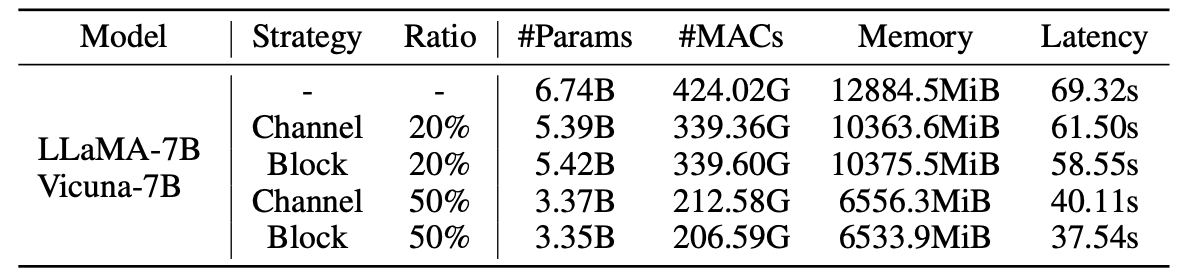
修剪模型的統計數據:
LLM-Pruner的結果為259萬樣品:
| 修剪比率 | #param | 記憶 | 潛伏期 | 加速 | 布爾克 | piqa | Hellaswag | Winogrande | 弧 | 弧 | OBQA | 平均的 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama-7b | 6.74b | 12884.5MIB | 69.32 | 1倍 | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| 與羊駝(50k)的駱駝5.4b | 5.47b | 10488.4mib | 58.55 | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| Lamini(259m) | 5.47b | 10488.4mib | 58.55 | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
可以在論文中找到更多結果。
| 原始型號 | 輸出 | 修剪模型 | 輸出 |
|---|---|---|---|
| Llama-7b | 宇宙是存在的全部空間,時間,物質和能量。它包括所有物質和能量,無論是否可見,實際上整個宇宙都是看不見的。關於其起源和最終命運的理論很多... | Llama-5.4b | 宇宙是存在的全部空間,時間,物質和能量。構成物理學的法律 - 電子原子,吸引其他物體的磁鐵,繞太陽繞行的行星 - 一直保持一致... |
| Vicuna-7b | 建立iOS應用程序的10個步驟:1。研究和發展這個想法。 2。確定要使用的平台(iOS,Android或兩者)。 3。制定計劃和預算。 4.僱用一個開發人員團隊。 5。設計用戶界面(UI)。 6。開髮用戶界面(UI)。 7。在應用程序上進行測試和迭代。 8。將應用程序提交到應用商店。 9.優化應用程序的性能和用戶體驗(UX)。 10。市場並推廣該應用程序。 | Vicuna-5.4b | 構建iOS應用程序的10個步驟:1。計劃您的應用程序:確定應該做什麼,它的外觀以及構建它的成本。 2.僱用開發人員:良好的iOS開發人員將幫助您設計用戶界面,創建應用程序並確保它不含錯誤。 3。創建一個用戶界面:這是魔術發生的地方。您應用程序的用戶界面將在這一點上進行設計和嘲笑... |
| chatglm-6b | 寫一首關於愛與和平的詩。在人生的喧囂中,我發現你的愛是一個舒緩的和平。這種感覺無法傳達,這種聯繫是無法遠距離的。憑著你的微笑,你的眼睛,你的擁抱,我感到只有你才能給予的歸屬感。這是一種永遠持續的愛,一種不能失敗的愛... | chatglm-5.6b | 寫一首關於愛與和平的詩。愛與和平,這兩個奇妙的事情我的心中純淨而無盡的慾望,我必須尋求很長一段時間,我知道。 |
由於該項目中使用的模型和存儲庫的版本變化,我們列出了一些已知版本問題以及重現我們方法所需的特定版本:
如果您覺得這個項目有用,請引用
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


