LLM Pruner
1.0.0
LLM-PRUNER: Sur l'élagage structurel des modèles de grands langues [ArXIV]
Xinyin MA, Gongfan Fang, Xinchao Wang
Université nationale de Singapour
.from_pretrained() pour charger le modèle. Rejoignez notre groupe WeChat pour une conversation:
pip install -r requirement.txt
bash script/llama_prune.sh
Ce script compresserait le modèle LLAMA-7B avec des paramètres ~ 20% élagués. Tous les modèles pré-formés et l'ensemble de données seraient automatiquement téléchargés, vous n'avez donc pas besoin de télécharger manuellement la ressource. Lors de l'exécution de ce script pour la première fois, il faudra du temps pour télécharger le modèle et l'ensemble de données.
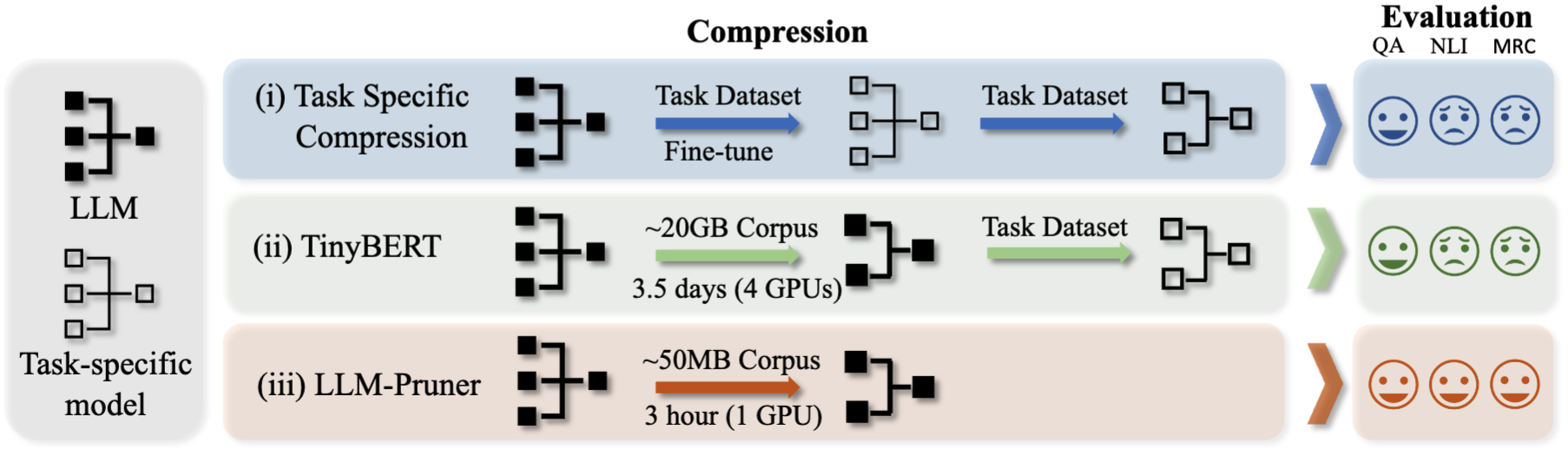
Il faut trois étapes pour tailler un LLM:
Après élagage et post-formation, nous suivons le grain d'évaluation LM pour l'évaluation.
? LLAMA / LLAMA-2 Élagage avec ~ 20% de paramètres élagués:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
Arguments:
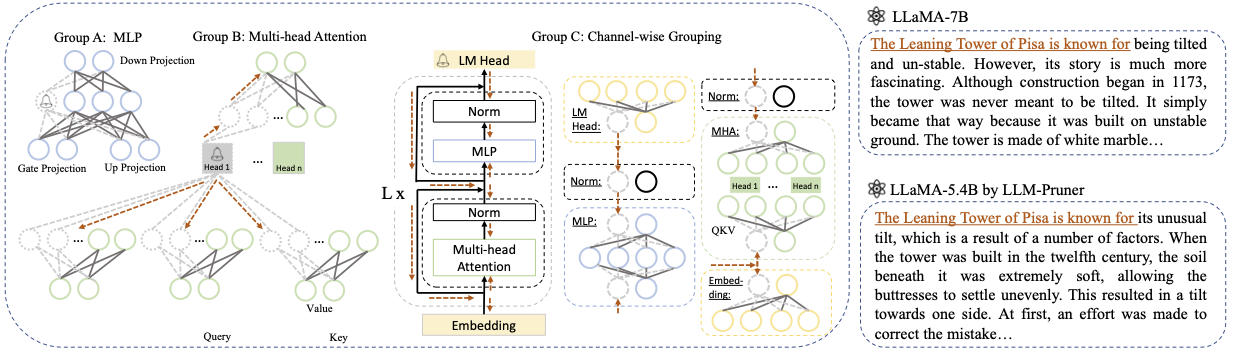
Base model : choisissez le modèle de base par rapport à lama ou llama-2 et passez le pretrained_model_name_or_path à --base_model . Le nom du modèle est utilisé pour AutoModel.from_pretrained pour charger le LLM pré-formé. Par exemple, si vous souhaitez utiliser le lama-2 avec 13 milliards de paramètres, passez meta-llama/Llama-2-13b-hf à --base_model .Pruning Strategy : choisissez entre l'élagage de la commande, du canal, ou de la couche à l'aide des options de commande respectives: {--block_wise}, {--channel_wise}, {--Layer_Wise --Layer Number_Of_Layers}. Pour l'élagage par bloc, spécifiez les couches de démarrage et de fin à élaguement. L'élagage par canal ne nécessite pas d'arguments supplémentaires. Pour l'élagage des calques, utilisez - Layer Number_Of_Layers pour spécifier le nombre de couches souhaité à conserver après l'élagage.Importance Criterion : Sélectionnez parmi L1, L2, Random ou Taylor en utilisant l'argument --pruner_type. Pour le Taylor Pruneur, choisissez l'une des options suivantes: Vectorize, param_second, param_first, param_mix. Par défaut, param_mix est utilisé, qui combine le gradient de Hessian et de premier ordre approximatif. Si vous utilisez L1, L2 ou Random, aucun argument supplémentaire n'est requis.Pruning Ratio : spécifie le rapport d'élagage des groupes. Il diffère du taux d'élagage des paramètres, car les groupes sont supprimés en tant qu'unités minimales.Device et Eval_device : l'élagage et l'évaluation peuvent être effectués sur différents appareils. Les méthodes basées sur Taylor nécessitent un calcul en arrière pendant l'élagage, qui peut nécessiter un RAM GPU significatif. Notre implémentation utilise l'estimation du CPU pour l'importance (prend également en charge GPU, utilisez simplement --device CUDA). EVAL_DEVICE est utilisé pour tester le modèle taillé. Si vous souhaitez essayer Vicuna, veuillez spécifier l'argument --base_model sur le chemin du poids de vicuna. Veuillez suivre https://github.com/lm-sys/fastchat pour obtenir des poids de vicuna.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
Veuillez vous référer à l'exemple / Baichuan pour plus de détails
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
Assurez-vous de remplacer PATH_TO_PRUNE_MODEL par le chemin du modèle vers le modèle élagué à l'étape 1, et remplacez PATH_TO_SAVE_TUNE_MODEL par l'emplacement souhaité où vous souhaitez enregistrer le modèle réglé.
Astuce : Training Llama-2 dans Float16 n'est pas recommandé et est connu pour produire NAN; En tant que tel, le modèle doit être formé à BFLOAT16.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
Pour le modèle Prune, utilisez simplement la commande suivante pour charger votre modèle.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
En raison des différentes configurations entre les modules du modèle élagué, où certaines couches peuvent avoir une largeur plus grande tandis que d'autres ont subi plus d'élagage, il devient peu pratique de charger le modèle en utilisant le .from_pretrained() comme fourni par la face de câlins. Actuellement, nous utilisons le torch.save pour stocker le modèle élagué.
Étant donné que le modèle taillé a une configuration différente dans chaque couche, comme certaines couches peuvent être plus larges, mais certaines couches ont été plus taillées, le modèle ne peut pas être chargé de .from_pretrained() Actuellement, nous utilisons simplement le torch.save pour enregistrer le modèle élagué et torch.load pour charger le modèle élagué.
Nous fournissons un script simple pour générer des textes à l'aide de modèles pré-formés / élagués / modèles élagués avec post-formation.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
Les instructions ci-dessus déploieront votre LLMS localement.
Pour évaluer les performances du modèle taillé, nous suivons le grain d'évaluation LM pour évaluer le modèle:
lm-evaluation-harness . Le point de contrôle réglé à partir de l'étape post-formation serait sauvegarder dans le format suivant: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
Organiser les fichiers par les commandes suivantes:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
Si vous souhaitez évaluer le checkpoint-200 , définissez les égaux Epoch sur 200 par export epoch=200 .
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
Ici, remplacez PATH_TO_PRUNE_MODEL et PATH_TO_SAVE_TUNE_MODEL par le chemin que vous enregistrez le modèle élagué et le modèle réglé, et PATH_OR_NAME_TO_BASE_MODEL consiste à charger le fichier de configuration du modèle de base.
[MISE À JOUR]: Nous téléchargeons un script sur le processus d'évaluation simplement si vous souhaitez évaluer le modèle taillé avec le point de contrôle réglé. Utilisez simplement la commande suivante:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
Remplacez les informations nécessaires de votre modèle dans la commande. Le dernier est habitué à parcourir différentes époques si vous souhaitez évaluer plusieurs points de contrôle dans une commande. Par exemple:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
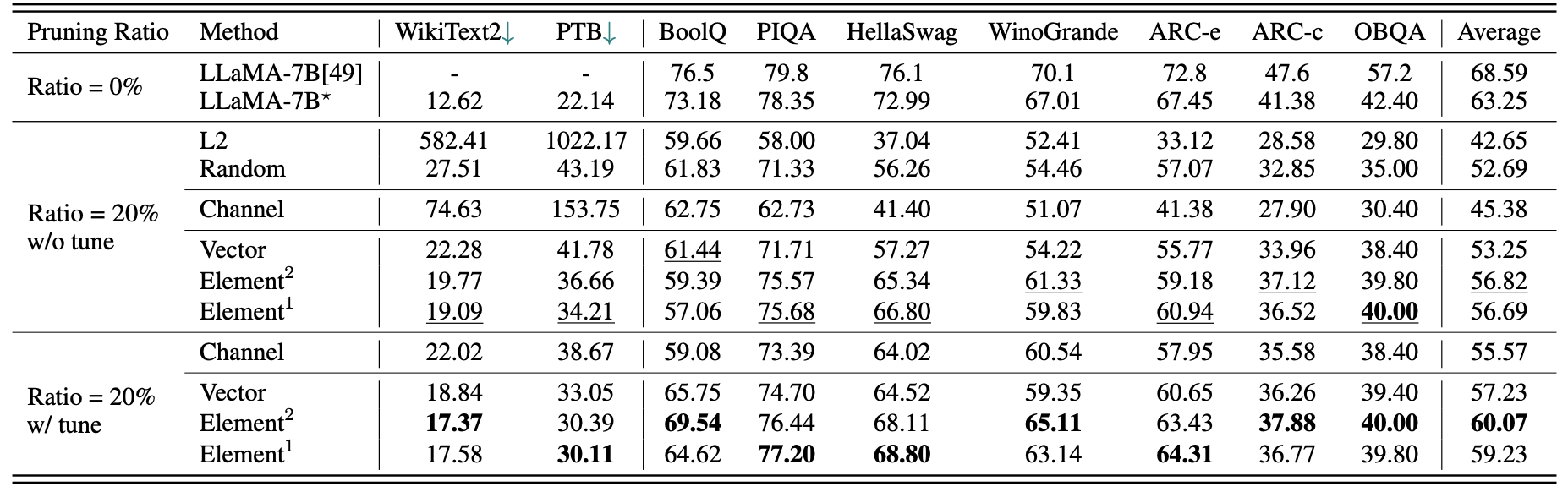
Un bref résultat quantitatif pour LLAMA-7B:
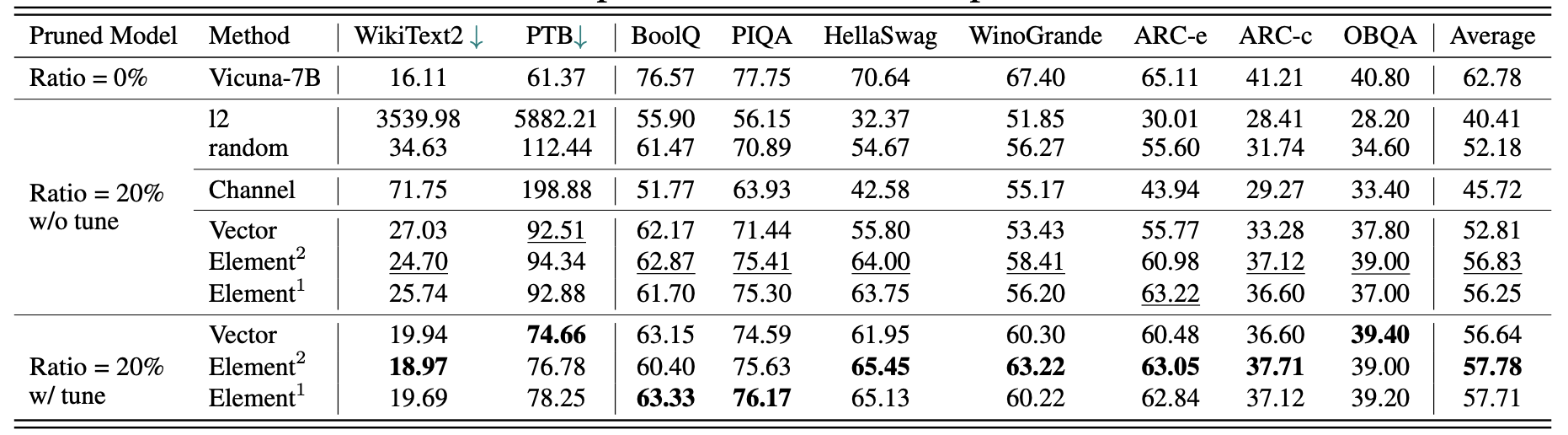
Les résultats pour vicuna-7b:
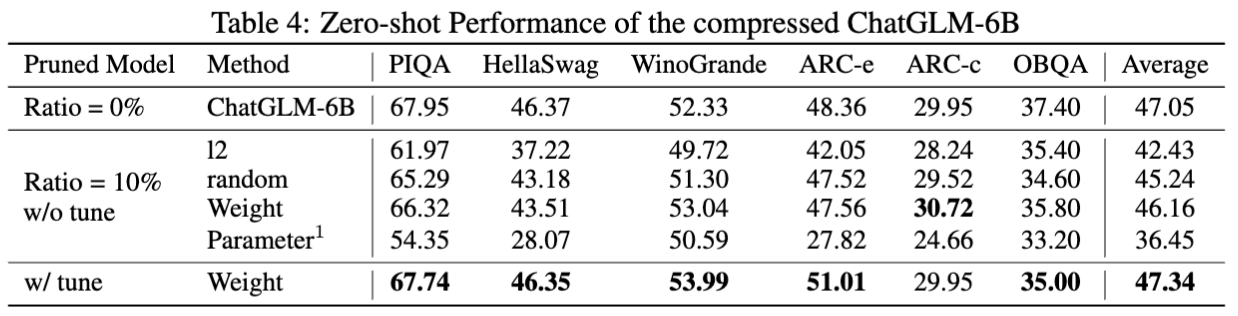
Les résultats de chatGLM-6B:
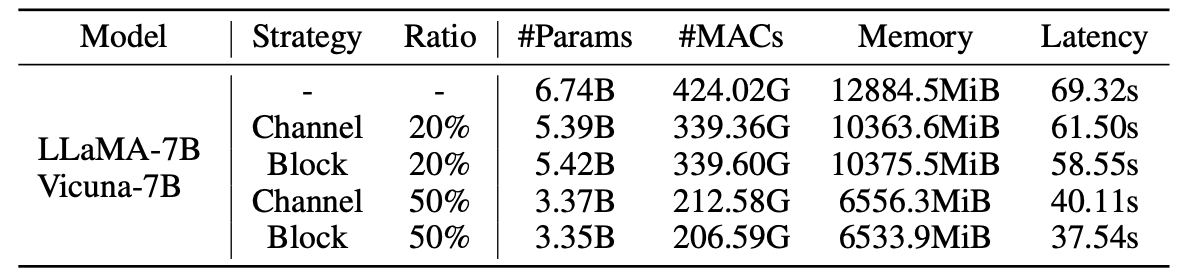
Statistiques pour les modèles élagués:
Résultats de LLM-Prener avec des échantillons de 2,59 m:
| Ratio d'élagage | #Param | Mémoire | Latence | Accélération | Boolq | Piqa | Hellaswag | Winogrande | Arc-e | Arc-c | Obqa | Moyenne |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lama-7b | 6.74b | 12884.5mib | 69.32 | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| LLAMA-5.4B avec alpaga (50k) | 5.47b | 10488.4mib | 58,55 | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| Lama-5.4b avec lamini (2,59 m) | 5.47b | 10488.4mib | 58,55 | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70,62 | 40.70 | 38.80 | 62.36 |
Plus de résultats peuvent être trouvés dans le document.
| Modèle d'origine | Sortir | Modèle élaqué | Sortir |
|---|---|---|---|
| Lama-7b | L'univers est l'intégralité de l'espace, du temps, de la matière et de l'énergie qui existe. Il comprend toute la matière et l'énergie, qu'elle soit visible ou non, et en fait l'univers entier est invisible. Il existe de nombreuses théories concernant son origine et son sort ultime ... | Lama-5.4b | L'univers est l'intégralité de l'espace, du temps, de la matière et de l'énergie qui existe. Les lois qui composent la physique - les électrons en orbite des atomes, les aimants attirant d'autres objets, les planètes en orbite autour du soleil - ont été cohérentes sur ... |
| Vicuna-7b | 10 étapes pour créer une application iOS: 1. Recherchez et développez l'idée. 2. Décidez de la plate-forme que vous souhaitez utiliser (iOS, Android, ou les deux). 3. Créez un plan et un budget. 4. Embaucher une équipe de développeurs. 5. Concevoir l'interface utilisateur (UI). 6. Développer l'interface utilisateur (UI). 7. Tester et itérer sur l'application. 8. Soumettez l'application à l'App Store. 9. Optimiser l'application pour les performances et l'expérience utilisateur (UX). 10. Market et promouvoir l'application. | Vicuna-5.4b | 10 étapes pour créer une application iOS: 1. Planifiez votre application: Décidez ce qu'elle devrait faire, à quoi il ressemblera et ce qu'il en coûtera pour le construire. 2. Embaucher un développeur: un bon développeur iOS vous aidera à concevoir l'interface utilisateur, à créer l'application et à vous assurer qu'elle est sans bug. 3. Créez une interface utilisateur: c'est là que la magie se produit. L'interface utilisateur de votre application sera conçue et moquée à ce stade ... |
| Chatglm-6b | Écrivez une poésie sur l'amour et la paix. Au milieu de l'agitation de la vie, je trouve votre amour apaisant. C'est un sentiment qui ne peut pas être transmis, une connexion qui ne peut pas être éloignée. Avec votre sourire, vos yeux, votre étreinte, je ressens un sentiment d'appartenance que vous seul pouvez donner. C'est un amour qui dure éternellement, un amour qui ne peut pas être la défaite ... | Chatglm-5.6b | Écrivez une poésie sur l'amour et la paix. L'amour et la paix, deux choses aussi merveilleuses un désir pur et sans fin dans mon cœur et les deux, je dois chercher un temps très, je sais .. amour, je sais, est un sentiment d'être un partenaire parfait, dans tous les sens et la paix, j'en ai besoin, tant, un jour très loin, mon cœur ira .. |
En raison des changements dans les versions des modèles et des repos utilisés dans ce projet, nous avons énuméré certains problèmes de version connus et les versions spécifiques nécessaires pour reproduire notre méthode:
Si vous trouvez ce projet utile, veuillez citer
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


