LLM Pruner
1.0.0
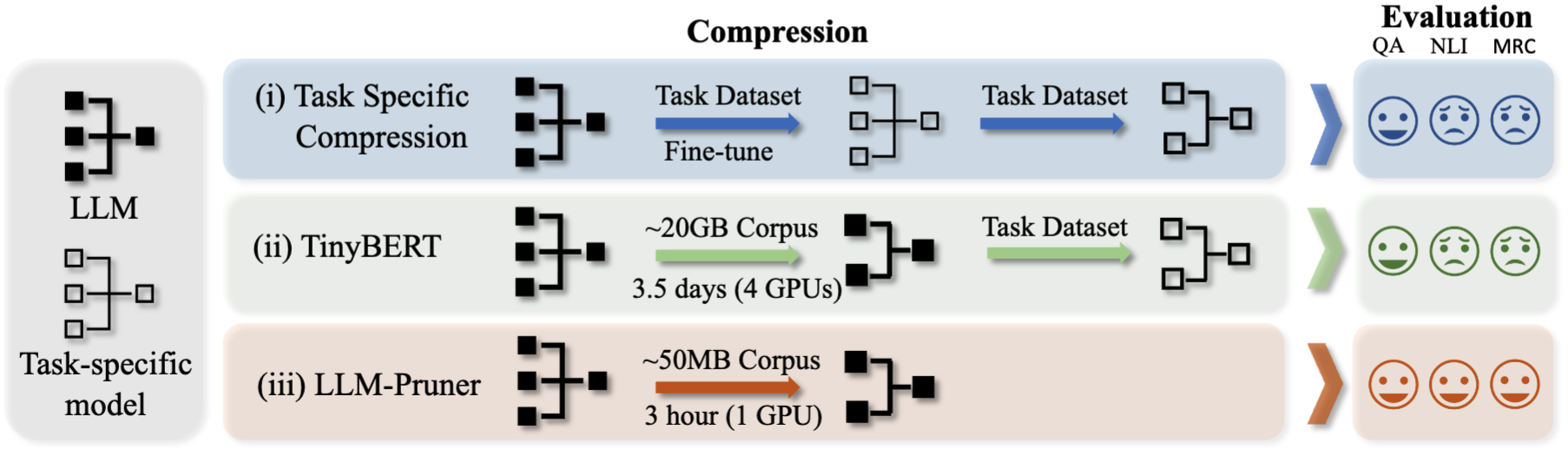
LLM-PRIMER: Sobre la poda estructural de modelos de idiomas grandes [ARXIV]
Xinyin MA, Gongfan Fang, Xinchao Wang
Universidad Nacional de Singapur
.from_pretrained() para cargar el modelo. Únase a nuestro grupo WeChat para charlar:
pip install -r requirement.txt
bash script/llama_prune.sh
Este script comprimiría el modelo LLAMA-7B con ~ 20% de parámetros podados. Todos los modelos previamente capacitados y el conjunto de datos se descargarían automáticamente, por lo que no necesita descargar manualmente el recurso. Al ejecutar este script por primera vez, requerirá algo de tiempo para descargar el modelo y el conjunto de datos.
Se necesitan tres pasos para podar un LLM:
Después de la poda y el post-entrenamiento, seguimos a la evaluación de LM-Evaluation para la evaluación.
? Llama/Llama-2 poda con ~ 20% de parámetros podados:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
Argumentos:
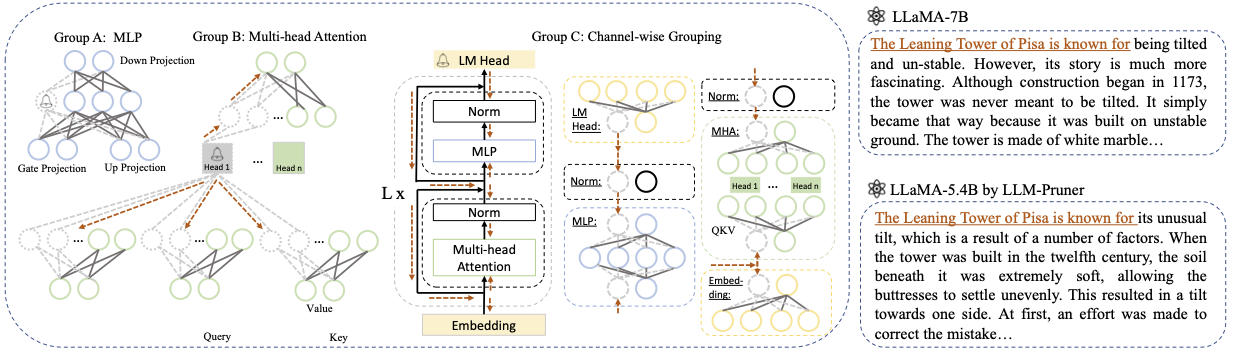
Base model : elija el modelo base de Llama o LLAMA-2 y pase el pretrained_model_name_or_path a --base_model . El nombre del modelo se utiliza para AutoModel.from_pretrained . Por ejemplo, si desea usar el LLAMA-2 con 13 mil millones de parámetros, luego pase meta-llama/Llama-2-13b-hf a-- --base_model .Pruning Strategy : elija entre la poda de bloqueo, canal o en cuanto a la capa utilizando las opciones de comando respectivas: {--BLOCK_WISE}, {--channel_wise}, {-layer_wise -layer number_of_layers}. Para la poda de bloques, especifique las capas de inicio y finalización para ser podadas. La poda de canal no requiere argumentos adicionales. Para la poda de capas, use --layer number_of_layers para especificar el número deseado de capas que se mantendrán después de la poda.Importance Criterion : Seleccione de L1, L2, Random o Taylor usando el argumento --pruner_type. Para Taylor Pruner, elija una de las siguientes opciones: Vectorize, Param_Second, Param_First, Param_Mix. Por defecto, se usa Param_Mix, que combina gradiente de hessian y de primer orden aproximado. Si usa L1, L2 o aleatorio, no se requieren argumentos adicionales.Pruning Ratio : especifica la relación de poda de grupos. Se diferencia de la velocidad de poda de los parámetros, ya que los grupos se eliminan como las unidades mínimas.Device y Eval_device : la poda y la evaluación se pueden realizar en diferentes dispositivos. Los métodos basados en Taylor requieren un cálculo hacia atrás durante la poda, lo que puede requerir una RAM significativa de GPU. Nuestra implementación utiliza la CPU para la estimación de importancia (también admite GPU, simplemente use --Device CUDA). Eval_device se usa para probar el modelo podado. Si desea probar Vicuna, especifique el argumento --base_model a la ruta al peso de Vicuna. Siga https://github.com/lm-sys/fastchat para obtener pesos de vicuna.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
Consulte el ejemplo/Baichuan para más detalles
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
Asegúrese de reemplazar PATH_TO_PRUNE_MODEL con la ruta al modelo podado en el paso 1 y reemplazar PATH_TO_SAVE_TUNE_MODEL con la ubicación deseada donde desea guardar el modelo sintonizado.
Consejo : el entrenamiento Llama-2 en Float16 no se recomienda y se sabe que produce Nan; Como tal, el modelo debe ser entrenado en BFLOAT16.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
Para el modelo podado, simplemente use el siguiente comando para cargar su modelo.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
Debido a las diferentes configuraciones entre los módulos en el modelo podado, donde ciertas capas pueden tener un ancho más grande, mientras que otras han sufrido más poda, no se vuelve práctico cargar el modelo utilizando el .from_pretrained() según lo dispuesto por la cara abrazada. Actualmente, empleamos la torch.save para almacenar el modelo podado.
Dado que el modelo podado tiene una configuración diferente en cada capa, como algunas capas pueden ser más anchas, pero algunas capas se han podado más, el modelo no se puede cargar con el .from_pretrained() en la cara abrazada. Actualmente, simplemente usamos el torch.save para guardar el modelo podado y la torch.load .
Proporcionamos un script simple para generar textos utilizando modelos previamente capacitados / podados / modelos podados con post-entrenamiento.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
Las instrucciones anteriores implementarán sus LLM localmente.
Para evaluar el desempeño del modelo podado, seguimos la sede de evaluación LM para evaluar el modelo:
lm-evaluation-harness . El punto de control sintonizado desde el paso posterior a la capacitación se guardaría en el siguiente formato: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
Organice los archivos mediante los siguientes comandos:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
Si desea evaluar el checkpoint-200 , establezca la época igual a 200 por export epoch=200 .
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
Aquí, reemplace PATH_TO_PRUNE_MODEL y PATH_TO_SAVE_TUNE_MODEL con la ruta que guarde el modelo podado y el modelo sintonizado, y PATH_OR_NAME_TO_BASE_MODEL es para cargar el archivo de configuración del modelo base.
[Actualización]: Cargamos un script para simplemente el proceso de evaluación si desea evaluar el modelo podado con el punto de control sintonizado. Simplemente use el siguiente comando:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
Reemplace la información necesaria de su modelo en el comando. El último se usa para iterar sobre diferentes épocas si desea evaluar varios puntos de control en un comando. Por ejemplo:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
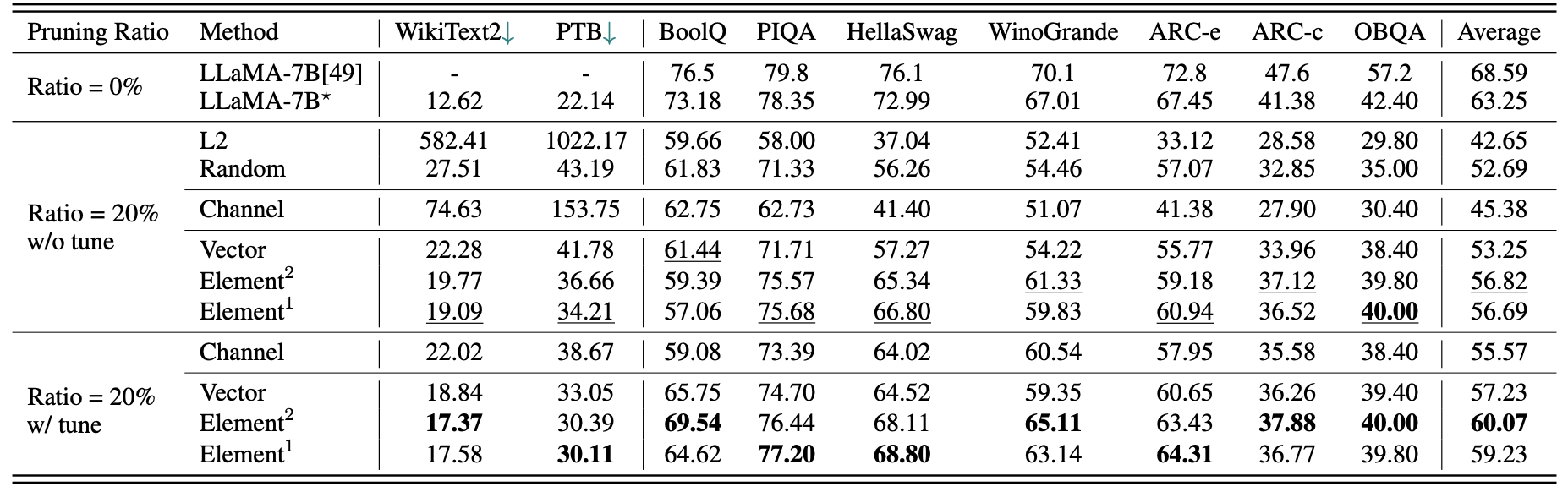
Un breve resultados cuantitativos para Llama-7B:
Los resultados para Vicuna-7b:
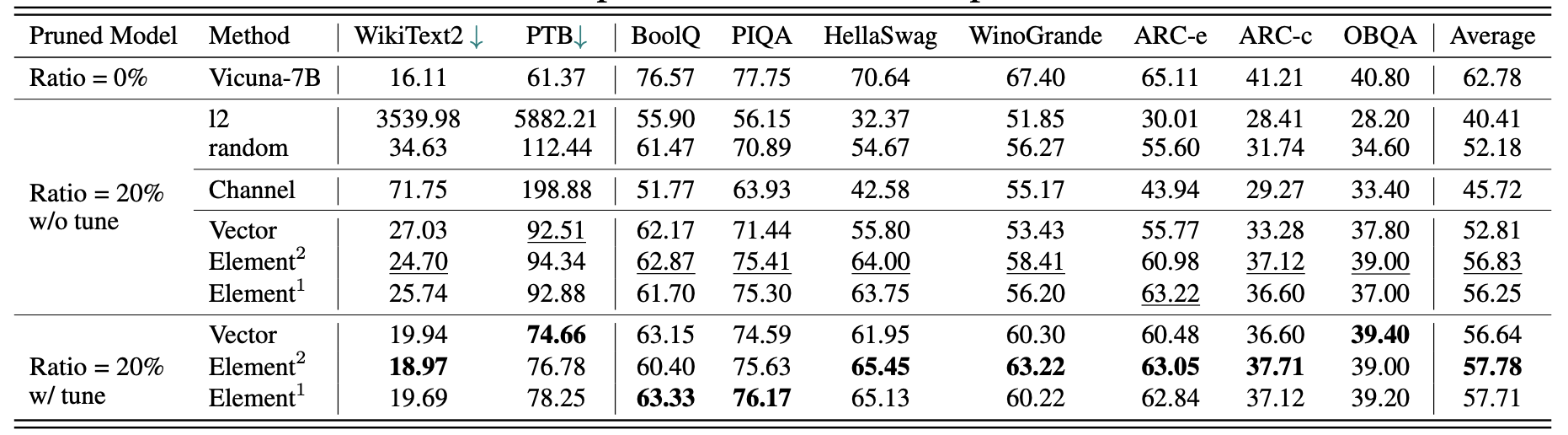
Los resultados para chatglm-6b:
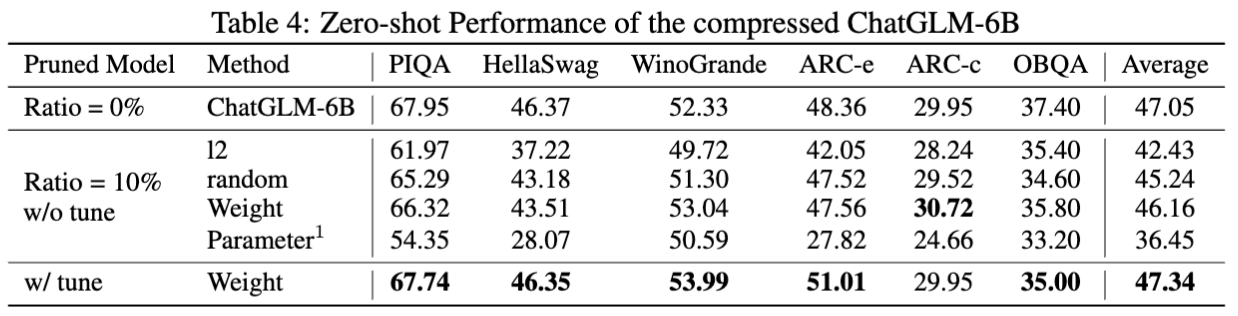
Estadísticas para modelos podados:
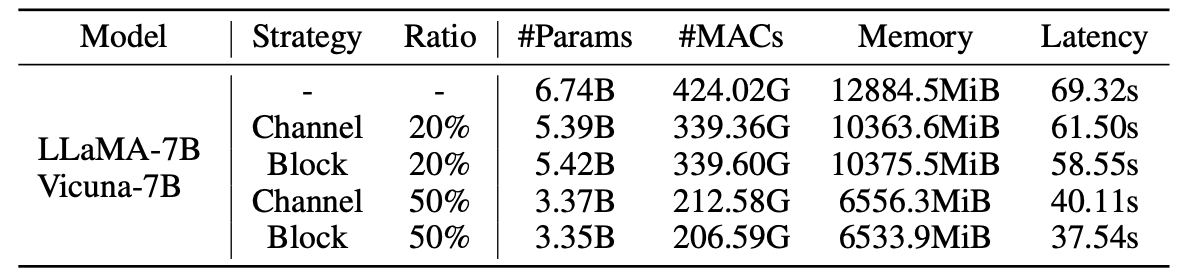
Resultados de LLM-liber con muestras de 2.59m:
| Relación de poda | #Param | Memoria | Estado latente | Aceleración | Boolq | Piqa | Helaswag | Winogrande | Arc-E | Arc-c | Obqa | Promedio |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama-7b | 6.74b | 12884.5MiB | 69.32s | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| Llama-5.4b con alpaca (50k) | 5.47b | 10488.4MiB | 58.55s | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| Llama-5.4b con Lamini (2.59m) | 5.47b | 10488.4MiB | 58.55s | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
Se pueden encontrar más resultados en el documento.
| Modelo original | Producción | Modelo podado | Producción |
|---|---|---|---|
| Llama-7b | El universo es la totalidad del espacio, el tiempo, la materia y la energía que existe. Incluye toda la materia y la energía, ya sea visible o no, y de hecho todo el universo es invisible. Hay muchas teorías con respecto a su origen y su destino final ... | LLAMA-5.4B | El universo es la totalidad del espacio, el tiempo, la materia y la energía que existe. Las leyes que conforman la física (electrones que orbitan átomos, imanes que atraen a otros objetos, planetas que orbitan el sol) han sido consistentes por ... |
| Vicuna-7b | 10 pasos para crear una aplicación iOS: 1. Investigue y desarrolle la idea. 2. Decida la plataforma que desea usar (iOS, Android o ambos). 3. Cree un plan y un presupuesto. 4. Contrata a un equipo de desarrolladores. 5. Diseñe la interfaz de usuario (UI). 6. Desarrolle la interfaz de usuario (UI). 7. Prueba e itera en la aplicación. 8. Envíe la aplicación a la App Store. 9. Optimice la aplicación para el rendimiento y la experiencia del usuario (UX). 10. Mercado y promover la aplicación. | Vicuna-5.4b | 10 pasos para crear una aplicación iOS: 1. Planifique su aplicación: decida cómo debe hacer, cómo se verá y qué costará construirla. 2. Contrata a un desarrollador: un buen desarrollador de iOS lo ayudará a diseñar la interfaz de usuario, crear la aplicación y asegurarse de que esté libre de errores. 3. Cree una interfaz de usuario: aquí es donde ocurre la magia. La interfaz de usuario de su aplicación será diseñada y burlada en este punto ... |
| Chatglm-6b | Escribe una poesía sobre el amor y la paz. En medio del ajetreo y el bullicio de la vida, encuentro que tu amor es una paz relajante. Es un sentimiento que no se puede transmitir, una conexión que no puede distanciarse. Con tu sonrisa, tus ojos, tu abrazo, siento un sentido de pertenencia que solo tú puedes dar. Es un amor que dura para siempre, un amor que no puede ser derrota ... | Chatglm-5.6b | Escribe una poesía sobre el amor y la paz. Amor y paz, dos cosas tan maravillosas Un deseo puro e interminable en mi corazón Y ambos, debo buscar mucho, mucho tiempo, lo sé ... Amor, lo sé, es una sensación de ser una pareja perfecta, en todos los sentidos y paz, lo necesito, tanto, un día a largo plazo, mi corazón irá. |
Debido a los cambios en las versiones de los modelos y los repositorios utilizados en este proyecto, enumeramos algunos problemas de versión conocidos y las versiones específicas necesarias para reproducir nuestro método:
Si encuentra útil este proyecto, cite
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


