LLM Pruner
1.0.0
LLM-Pruner: О структурной обрезке больших языковых моделей [arxiv]
Синьин М.А., Гонгфан Фанг, Синчао Ван
Национальный университет Сингапура
.from_pretrained() для загрузки модели. Присоединяйтесь к нашей группе WeChat для чата:
pip install -r requirement.txt
bash script/llama_prune.sh
Этот сценарий сжал бы модель Llama-7B с обрезанными параметрами ~ 20%. Все предварительно обученные модели и набор данных будут автоматически загружены, поэтому вам не нужно вручную загружать ресурс. При запуске этого сценария в первый раз потребуется некоторое время для загрузки модели и набора данных.
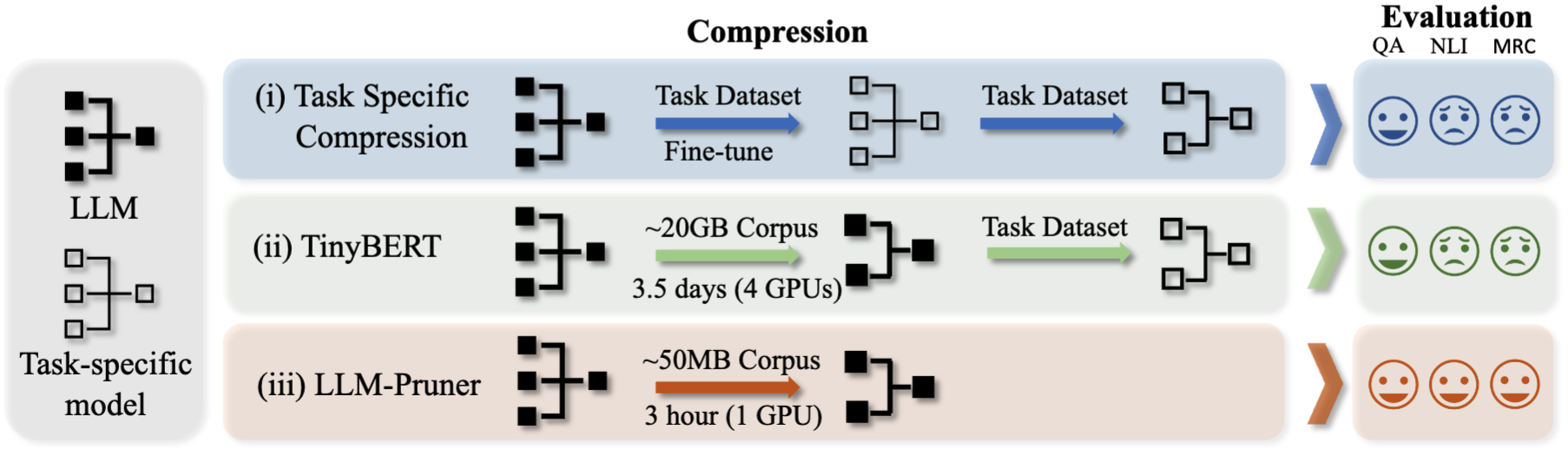
Требуется три шага, чтобы обрезать LLM:
После обрезки и после тренировки мы следуем за LM-оценкой для оценки.
? Llama/Llama-2 обрезка с ~ 20% параметров обрезается:
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
Аргументы:
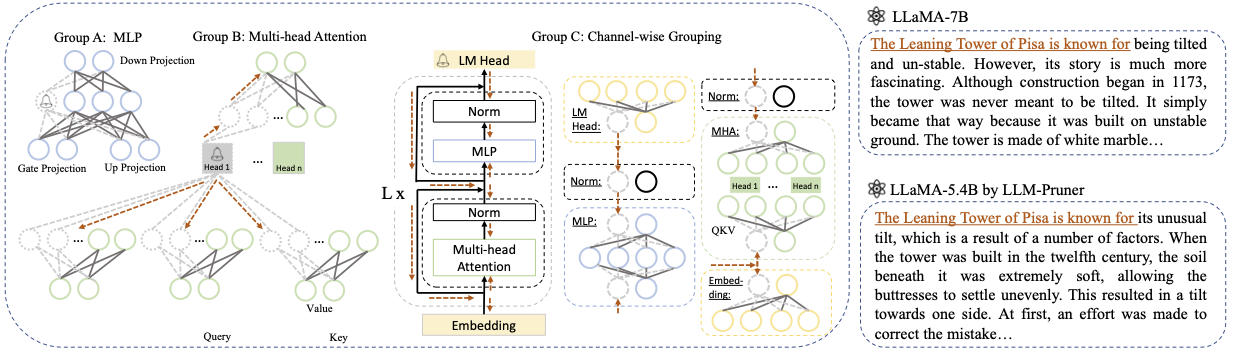
Base model : выберите базовую модель из Llama или Llama-2 и передайте pretrained_model_name_or_path to --base_model . Имя модели используется для AutoModel.from_pretrained для загрузки предварительно обученного LLM. Например, если вы хотите использовать Llama-2 с 13 миллиардами параметров, то пройдите meta-llama/Llama-2-13b-hf to --base_model .Pruning Strategy : выберите между блоками, по каналу или обрезки по слону, используя соответствующие параметры команды: {-block_wise}, {--manknel_wise}, {-layer_wise-layer number_of_layers}. Для блок-обрезки укажите начальные и конечные слои, которые будут обрезаны. Обрезка канала не требует дополнительных аргументов. Для обрезки слоя используйте -layer number_of_layers, чтобы указать желаемое количество слоев, которые будут сохранены после обрезки.Importance Criterion : выберите из L1, L2, случайного или Тейлора, используя аргумент - -pruner_type. Для Taylor Spruner выберите один из следующих параметров: Vectorize, param_second, param_first, param_mix. По умолчанию используется Param_mix, который объединяет аппроксимированный градиент Hessian и первого порядка второго порядка. При использовании L1, L2 или случайных, никаких дополнительных аргументов не требуется.Pruning Ratio : указывает соотношение обрезки групп. Он отличается от скорости обрезки параметров, поскольку группы удаляются в качестве минимальных единиц.Device и Eval_device : обрезка и оценка могут быть выполнены на разных устройствах. Методы на основе Тейлора требуют обратных вычислений во время обрезки, что может потребовать значительного оперативного памяти GPU. Наша реализация использует ЦП для оценки важности (также поддерживает графический процессор, просто используйте -Device CUDA). eval_device используется для тестирования модели с обрезкой. Если вы хотите попробовать Vicuna, укажите аргумент --base_model на путь к весу викана. Пожалуйста, следите за https://github.com/lm-sys/fastchat, чтобы получить вес-викуна.
python hf_prune.py --pruning_ratio 0.25
--block_wise
--block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--pruner_type taylor
--test_after_train
--device cpu --eval_device cuda
--save_ckpt_log_name llama_prune
--base_model PATH_TO_VICUNA_WEIGHTS
Пожалуйста, обратитесь к примеру/Baichuan для получения более подробной информации
python llama3.py --pruning_ratio 0.25
--device cuda --eval_device cuda
--base_model meta-llama/Meta-Llama-3-8B-Instruct
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30
--block_attention_layer_start 4 --block_attention_layer_end 30
--save_ckpt_log_name llama3_prune
--pruner_type taylor --taylor param_first
--max_seq_len 2048
--test_after_train --test_before_train --save_model
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path yahma/alpaca-cleaned
--lora_r 8
--num_epochs 2
--learning_rate 1e-4
--batch_size 64
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--wandb_project llama_tune
Обязательно замените PATH_TO_PRUNE_MODEL путем к модели с обрезкой на шаге 1 и замените PATH_TO_SAVE_TUNE_MODEL на желаемое местоположение, где вы хотите сохранить настроенную модель.
Совет : обучение Llama-2 в Float16 не рекомендуется и, как известно, производит NAN; Таким образом, модель должна быть обучена BFLOAT16.
deepspeed --include=localhost:1,2,3,4 post_training.py
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin
--data_path MBZUAI/LaMini-instruction
--lora_r 8
--num_epochs 3
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL
--extra_val_dataset wikitext2,ptb
--wandb_project llmpruner_lamini_tune
--learning_rate 5e-5
--cache_dataset
Для модели обрезки просто используйте следующую команду для загрузки вашей модели.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
Из -за различных конфигураций между модулями в обрезенной модели, где определенные слои могут иметь большую ширину, в то время как другие подвергаются большей обрезке, становится нецелесообразно загружать модель с использованием .from_pretrained() как это предусмотрено, обнимая лицо. В настоящее время мы используем torch.save для хранения модели с обрезкой.
Поскольку в каждом слое есть различная конфигурация, как и некоторые слои могут быть шире, но некоторые слои были обрезаны больше, модель не может быть загружена .from_pretrained() В настоящее время мы просто используем torch.save , чтобы сохранить модель обрезки и torch.load для загрузки модели с обрезкой.
Мы предоставляем простой сценарий текстам Geneate, используя предварительно обученные / обрезанные модели / модели с обрезкой с пост-тренировкой.
python generate.py --model_type pretrain
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
Приведенные выше инструкции будут развернуть ваши LLM на местном уровне.
Для оценки производительности модели с обрезкой мы следуем за LM-оценкой, чтобы оценить модель:
lm-evaluation-harness . Настраиваемая контрольная точка с шага после тренировки будет сохранена в следующем формате: - PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
Расположить файлы по следующим командам:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
Если вы хотите оценить checkpoint-200 , установите эпоху, равную 200 по export epoch=200 .
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq
--device cuda:0 --no_cache
--output_path PATH_TO_SAVE_EVALUATION_LOG
Здесь замените PATH_TO_PRUNE_MODEL и PATH_TO_SAVE_TUNE_MODEL на путь, который вы сохраняете модель обрезки и настроенной модели, и PATH_OR_NAME_TO_BASE_MODEL для загрузки файла конфигурации базовой модели.
[Обновление]: Мы загружаем скрипт в процесс оценки, если вы хотите оценить обрезку модель с помощью настроенной контрольной точки. Просто используйте следующую команду:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
Замените необходимую информацию вашей модели в команде. Последний используется для итерации в разные эпохи, если вы хотите оценить несколько контрольных точек в одной команде. Например:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
python test_speedup.py --model_type pretrain
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
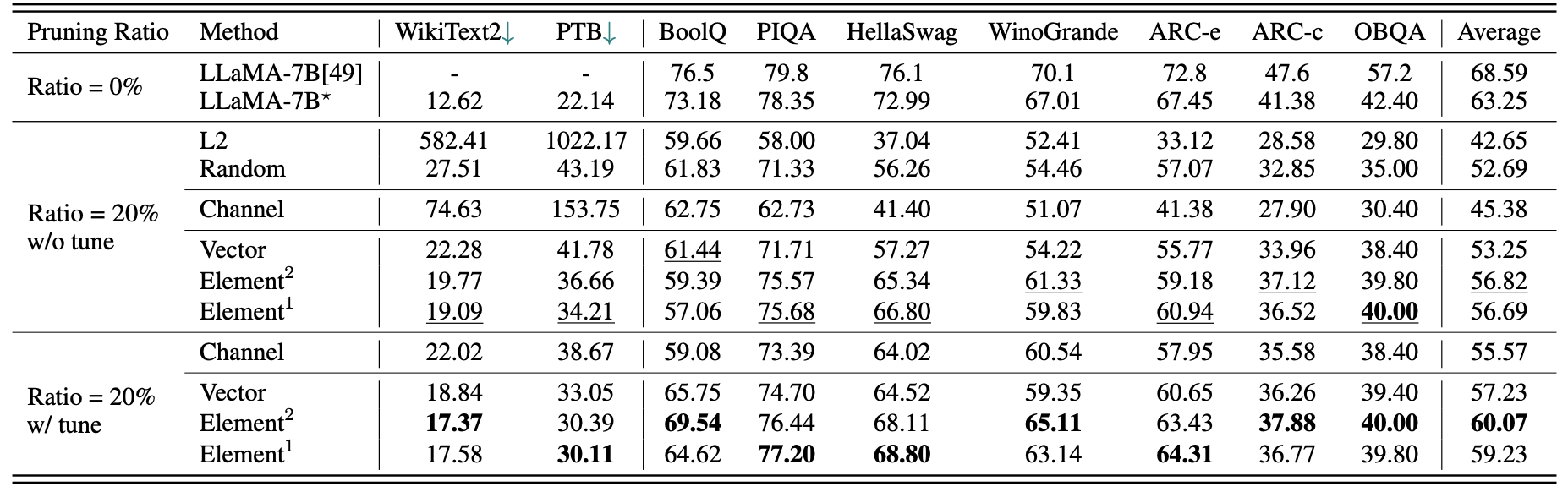
Краткие количественные результаты для Llama-7B:
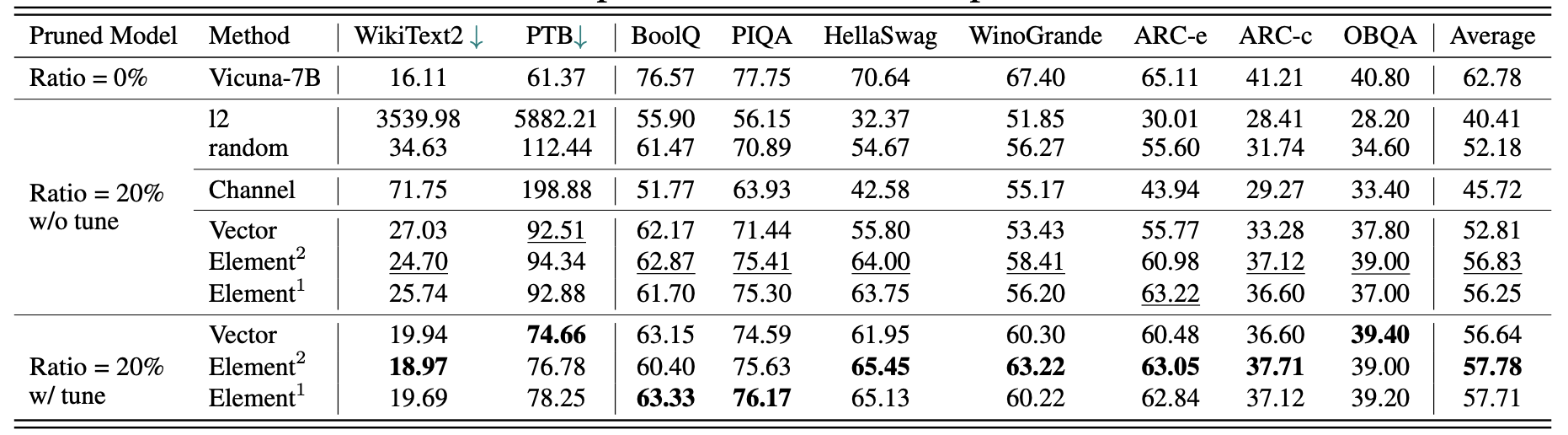
Результаты для Vicuna-7B:
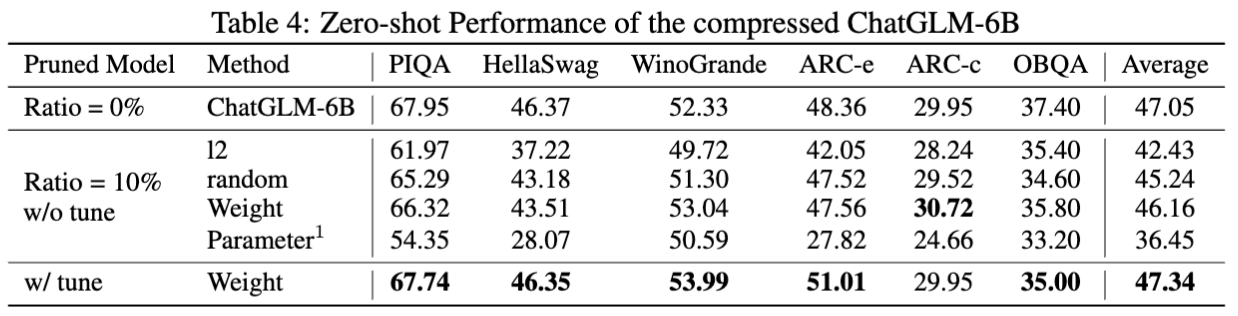
Результаты для Chatglm-6B:
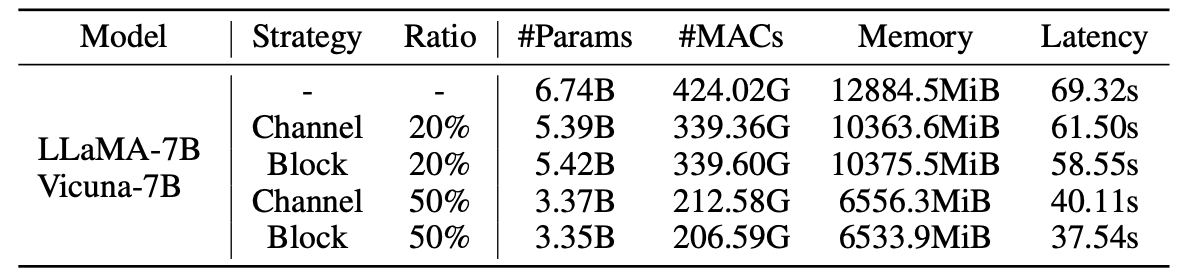
Статистика для обрезанных моделей:
Результаты LLM-Pruner с образцами 2,59 м:
| Коэффициент обрезки | #Param | Память | Задержка | Ускорение | Бульк | Пика | Hellaswag | Winogrande | Арк-э | Дуговой | Obqa | Средний |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Лама-7B | 6,74b | 12884,5mib | 69,32 с | 1x | 73,18 | 78.35 | 72,99 | 67.01 | 67.45 | 41.38 | 42,40 | 63,25 |
| Llama-5,4b с альпакой (50K) | 5.47b | 10488.4mib | 58,55 с | 1.18x | 64,62 | 77.20 | 68,80 | 63.14 | 64,31 | 36.77 | 39,80 | 59,23 |
| Llama-5,4b с ламини (2,59 м) | 5.47b | 10488.4mib | 58,55 с | 1.18x | 76.57 | 77.37 | 66.60 | 65,82 | 70.62 | 40,70 | 38,80 | 62,36 |
Больше результатов можно найти в статье.
| Оригинальная модель | Выход | Обрезка модель | Выход |
|---|---|---|---|
| Лама-7B | Вселенная - это все пространство, время, материя и энергия, которая существует. Он включает в себя все материи и энергию, видимым или нет, и на самом деле вся вселенная невидима. Есть много теорий, касающихся его происхождения и конечной судьбы ... | Лама-5,4b | Вселенная - это все пространство, время, материя и энергия, которая существует. Законы, которые составляют физику - электроны, вращающиеся вращающимися атомами, магниты, привлекающие другие предметы, планеты, вращающиеся на солнце, были последовательны ... |
| Vicuna-7b | 10 шагов по созданию приложения для iOS: 1. Исследование и разработка идеи. 2. Определите платформу, которую вы хотите использовать (iOS, Android или оба). 3. Создайте план и бюджет. 4. Наймите команду разработчиков. 5. Создайте пользовательский интерфейс (пользовательский интерфейс). 6. Разработать пользовательский интерфейс (пользовательский интерфейс). 7. Проверьте и итерацию в приложении. 8. Отправьте приложение в App Store. 9. Оптимизируйте приложение для производительности и пользовательского опыта (UX). 10. Рынок и продвигать приложение. | Vicuna-5,4b | 10 шагов для создания приложения для iOS: 1. Спланируйте приложение: решайте, что оно должно делать, как оно будет выглядеть, и сколько это будет стоить для его создания. 2. Наймите разработчика: хороший разработчик iOS поможет вам разработать пользовательский интерфейс, создать приложение и убедиться, что оно не является ошибочным. 3. Создайте пользовательский интерфейс: вот где происходит магия. Пользовательский интерфейс вашего приложения будет спроектировано и издевается на этом этапе ... |
| Чатглм-6B | Напишите поэзию о любви и мире. В разгар жизни и суеты жизни я нахожу вашу любовь успокаивающим миром. Это чувство, которое нельзя передать, связь, которую нельзя дистанцировать. С твоей улыбкой, твоими глазами, твоими объятиями я чувствую принадлежность, которое только ты можешь дать. Это любовь, которая длится вечно, любовь, которая не может быть поражена ... | Чатглм-5,6B | Напишите поэзию о любви и мире. Любовь и мир, две такие замечательные вещи Чистое и бесконечное желание в моем сердце И оба они должны искать долгое, долгое время, я знаю ... Я знаю, что я чувствую себя идеальным партнером, во всех смыслах и мира, мне так нужно, однажды долгий, долгий путь, мое сердце пойдет ... |
Из -за изменений в версиях моделей и репо, использованных в этом проекте, мы перечислили некоторые известные проблемы версий и конкретные версии, необходимые для воспроизведения нашего метода:
Если вы найдете этот проект полезным, пожалуйста, процитируйте
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}


